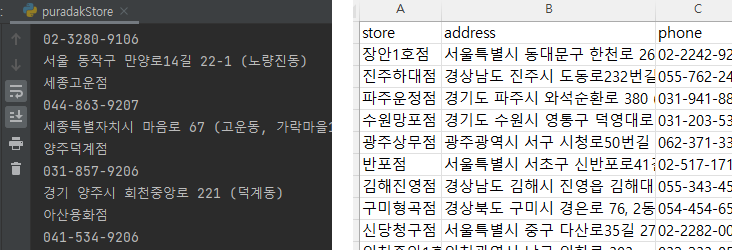
포트폴리오 정리 중에 기억을 더듬어볼 겸 작년에 만든 푸라닭 크롤링 프로그램에 대해 작성하려고 합니다.
왜 푸라닭 사이트를 크롤링 했냐고 물으신다면, 제가 제일 좋아하는 치킨 브랜드이기 때문입니다. (고추마요 최애)
홈페이지 구성
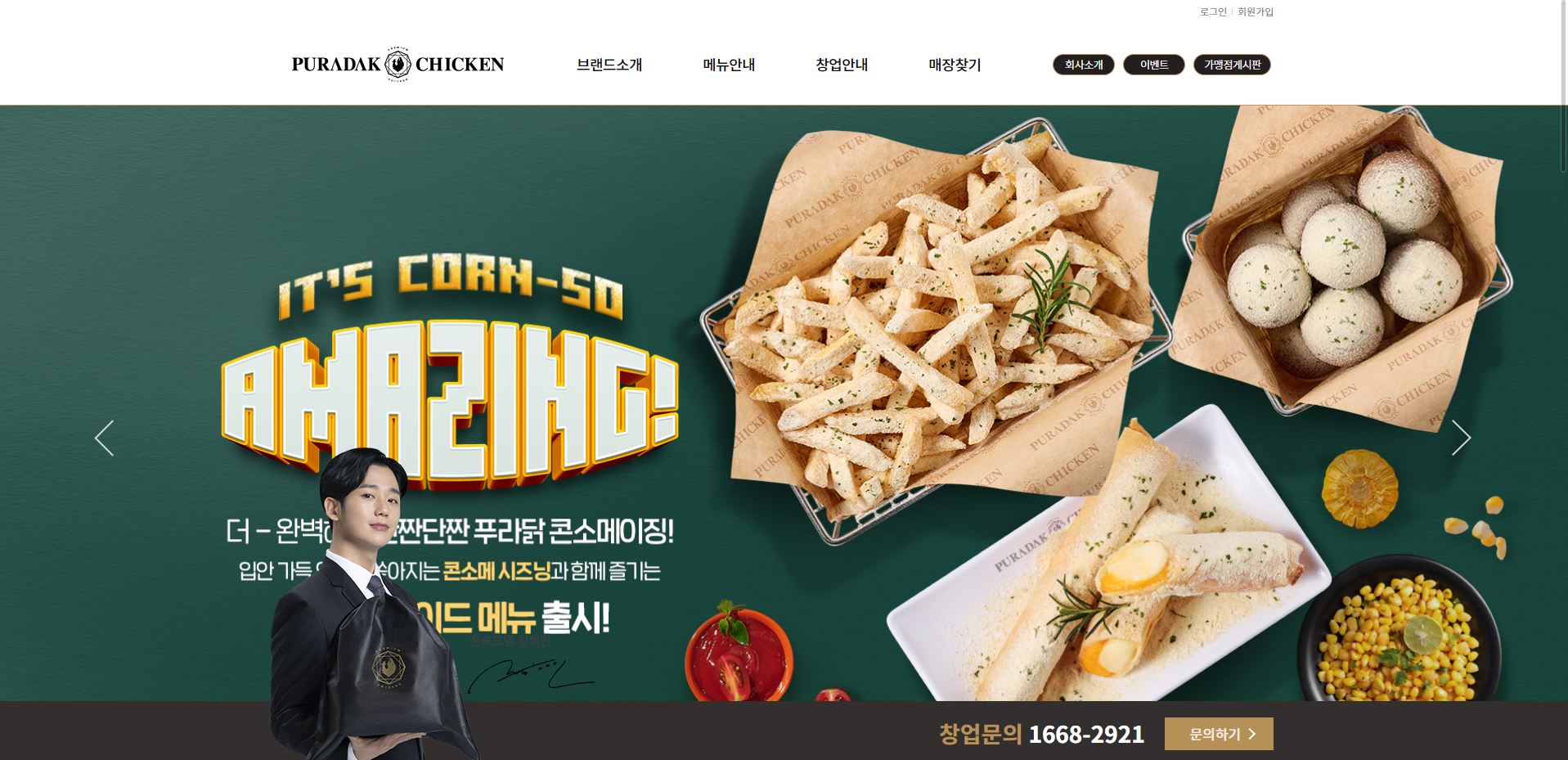
현재 푸라닭 공식 홈페이지 메인은 이렇게 생겼습니다. (콘소메이징도 맛있더라구요.)
매장찾기 페이지를 접속하면 자동으로 현재 지역이 선택되고 선택된 지역에 있는 매장 정보가 왼쪽에 출력됩니다.
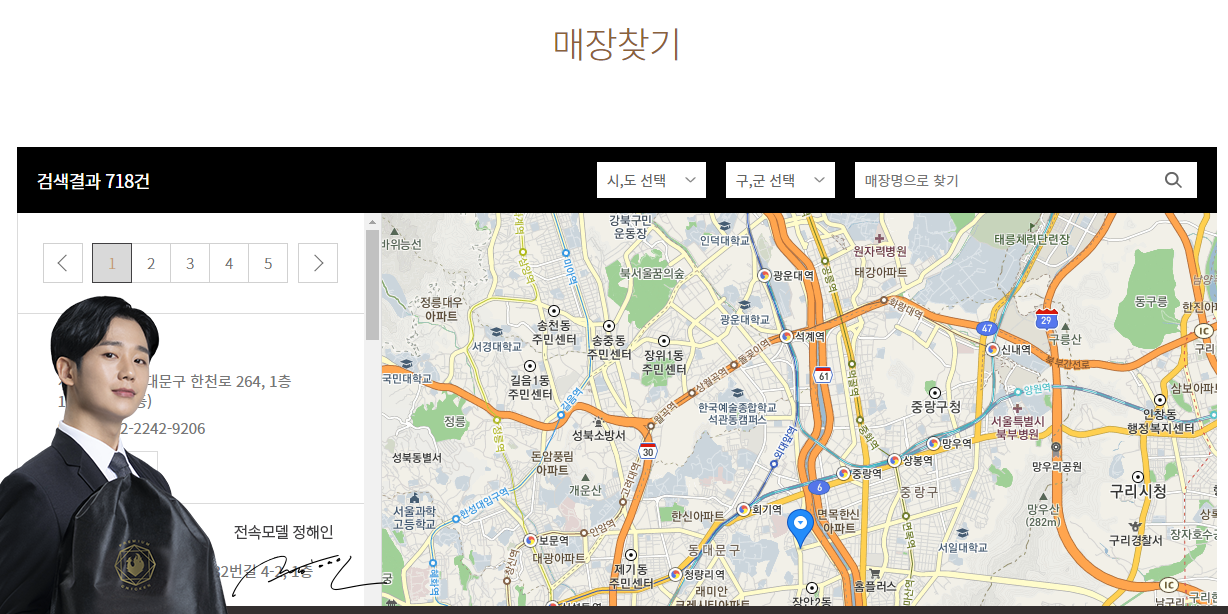
지역을 바꿀 때 마다 매장의 개수가 바뀌게 되는데, 아무런 지역도 선택하지 않을 경우 (시,도 선택) 작성일 기준 718건의 모든 매장의 정보가 1 ~ 36 페이지에 걸쳐 출력이 됩니다.
이걸 이용해서 매장의 이름과 전화번호, 주소를 수집하는 웹크롤러를 구현하였습니다.
구현
먼저 필요한 모듈을 임포트 합니다.
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
import timepuradak_URL = "https://www.puradakchicken.com/startup/store.asp"
wd = webdriver.Chrome('./WebDriver/chromedriver.exe')
wd.get(puradak_URL)
time.sleep(1) # 웹페이지 연결할 동안 1초 대기webdriver를 이용해 푸라닭 홈페이지에 접속합니다.
로딩이 느릴수도 있으니 중간에 time.sleep(1)을 이용해서 1초간 대기하도록 합니다.
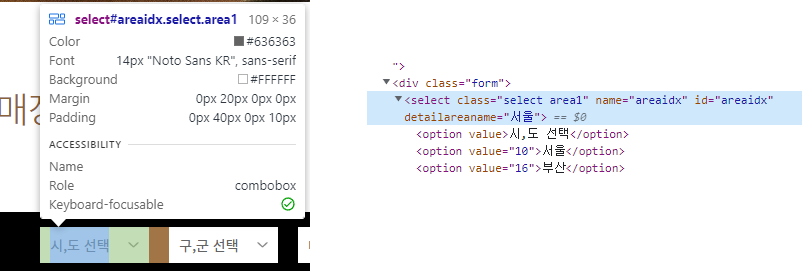
체크박스의 element를 확인해보니 id=areaidx 이고 시,도 선택에 해당하는 옵션은 (1)이므로 아래와 같이 CSS_SELECTOR를 이용하여 해당 옵션을 클릭하도록 합니다.
wd.find_element(By.CSS_SELECTOR, "#areaidx > option:nth-child(1)").click()한 페이지 당 20개의 매장 정보가 출력되는데, 처음 인덱스가 2로 시작하기 때문에 2부터 22까지 순회하면서 매장 정보를 가져옵니다.
연락처의 경우 앞의 연락처 : 는 제외한 숫자와 하이픈만 가져오도록 했습니다.
제일 마지막 페이지에 20개의 매장 정보가 전부 없을 수도 있기 때문에 try-except문을 이용하여 작성했습니다.
for i in range(2, 22): #1페이지당 20개의 매장이 노출됨.
try:
time.sleep(1) # 스크립트 실행 할 동안 1초 대기
html = wd.page_source
soupPRD = BeautifulSoup(html, 'html.parser')
store_name_h2 = soupPRD.select(f"#result_search > li:nth-of-type({i}) > span > p.name")
store_name = store_name_h2[0].string
print(store_name) # 매장 이름 출력
store_doro = soupPRD.select(f"#result_search > li:nth-of-type({i}) > span > p.juso > span.doro")[0].string #도로명 주소
store_phone = soupPRD.select(f"#result_search > li:nth-of-type({i}) > span > p.tel")[0].string #전화번호
store_phone = store_phone.split()[2] #연락처: 는 제외하고 전화번호만 가져오기
print(store_phone)
print(store_doro)
result.append([store_name] + [store_doro] + [store_phone])
except:
continue첫번째 페이지 이후부터는 크롤링이 끝나고 나면 다음 버튼을 찾아 클릭합니다.
if page > 1:
nextBtn = wd.find_element(By.CLASS_NAME, "next") # 다음 버튼
wd.execute_script('arguments[0].click()', nextBtn) # 다음 버튼 클릭크롤링이 끝나면 데이터 프레임으로 변환하고 csv로 저장합니다.
PRD_tbl = pd.DataFrame(result, columns=('store', 'address', 'phone'))
PRD_tbl.to_csv('./data/puradak_store.csv', encoding='cp949', mode='w', index=False)혹시나 해서 돌려봤는데 잘 동작하네요 :D