프로그래머스 과제관 : 채용 공고 추천
Programmers 채용 공고 페이지를 방문한 개발자들의 방문/지원 기록을 바탕으로 추천 모델을 만들어야 합니다. 구체적으로 개발자와 채용 공고를 보고, 개발자가 해당 채용 공고에 지원할지 안 할지를 예측하는 Binary Classifier를 만들어주세요.
('2019 머신러닝 온라인 잡페어' 기출 문제입니다.)
데이터셋 정보
1. train.csv
userID : 개발자의 ID
jobID : 구직공고의 ID
applied : 지원 여부
2. job_tags.csv
jobID : 구직공고의 ID
tagID : 직업에 해당하는 키워드
3. user_tags.csv
user_ID : 개발자의 ID
tagID: 각 개발자가 관심사로 등록한 키워드
4. tags.csv
tagID : 키워드
keyword : 키워드가 실제로 무엇을 의미하는지
5. job_companies.csv
companyID : 회사
jobID : 회사의 구직공고
companySize : 회사의 규모
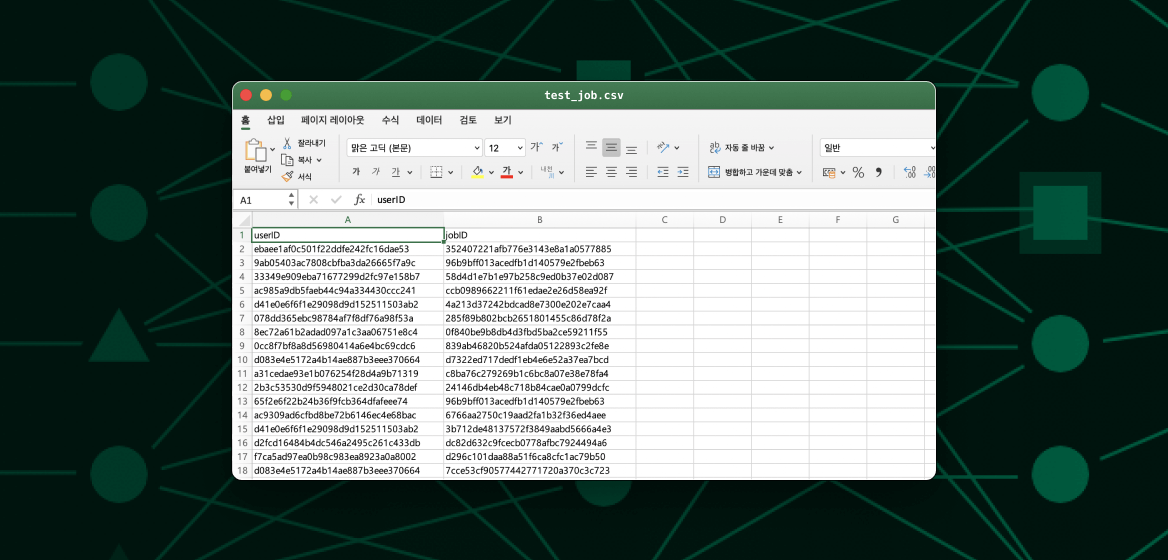
6. test_job.csv
userID : 개발자의 ID
jobID : 구직공고의 ID데이터 가져오기 / 데이터 확인
import pandas as pd
pd.set_option('mode.chained_assignment', None)
from matplotlib import pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
import missingno
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
train = pd.read_csv("train.csv")
job_tags = pd.read_csv("job_tags.csv")
user_tags = pd.read_csv("user_tags.csv")
tags = pd.read_csv("tags.csv")
job_companies = pd.read_csv("job_companies.csv")
test_job = pd.read_csv("test_job.csv")
train.head()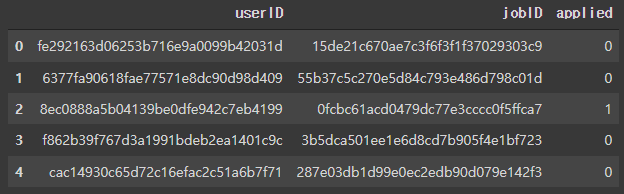
ID는 비식별화 처리가 되어있어서 보기 힘들기 때문에 딕셔너리와 replace를 이용하여 짧게 변환해 주었다.
user_ids = pd.Series([x+1 for x in range(len(train["userID"].unique()))])
user_ids.index = train["userID"].unique()
user_id_dict = user_ids.to_dict()
str(user_id_dict)[:300]
job_ids = pd.Series([x+1 for x in range(len(job_tags["jobID"].unique()))])
job_ids.index = job_tags["jobID"].unique()
job_id_dict = job_ids.to_dict()
str(job_id_dict)[:300]
train["userID"].replace(user_id_dict, inplace=True)
train["jobID"].replace(job_id_dict, inplace=True)
job_tags["jobID"].replace(job_id_dict, inplace=True)
user_tags["userID"].replace(user_id_dict, inplace=True)
job_companies["jobID"].replace(job_id_dict, inplace=True)
job_companies["companyID"].replace(company_id_dict, inplace=True)
test_job["userID"].replace(user_id_dict, inplace=True)
test_job["jobID"].replace(job_id_dict, inplace=True)
str(job_id_dict)[:300]{'320722549d1751cf3f247855f937b982': 1, 'e744f91c29ec99f0e662c9177946c627': 2, 'e820a45f1dfc7b95282d10b6087e11c0': 3, '53c3bce66e43be4f209556518c2fcb54': 4, 'fd06b8ea02fe5b1c2496fe1700e9d16c': 5, '6e7d2da6d3953058db75714ac400b584': 6, '818f4654ed39a1c147d1e51a00ffb4cb': 7, '019d385eb67632a7e958e23f2- 전체 학습 데이터 중
applied = 1인 데이터와applied = 0인 데이터의 수를 살펴보았다.
sns.countplot(train["applied"])
object_cnt = train["applied"].value_counts()
for x,y,z in zip(object_cnt.index, object_cnt.values, object_cnt.values/object_cnt.sum()*100):
plt.annotate(f"{y}\n({round(z,2)}%)", xy=(x,y+70), textcoords="data", ha="center")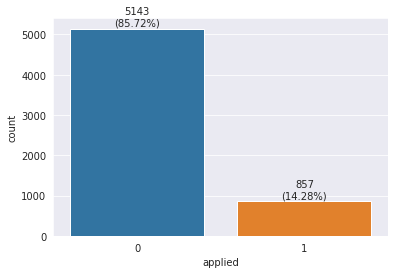
지원하지 않은 경우(label=0)가 데이터의 약 86퍼센트를 차지하는 불균형한 데이터로 보인다.
중복 제거
유저 태그만 데이터 수가 많아서 중복을 확인해 보았다.
print("user_tags 중복 개수:", user_tags.duplicated().sum())
print("job_tags 중복 개수:", job_tags.duplicated().sum())
print("job_companies 중복 개수:", job_companies.duplicated().sum())
print("train 중복 개수:", train.duplicated().sum())user_tags 중복 개수: 14612
job_tags 중복 개수: 0
job_companies 중복 개수: 0
train 중복 개수: 0중복이 무려 14612개나 된다. drop_duplicates를 이용해서 제거해주고 다시 한 번 중복을 확인하였다..
user_tags = user_tags.drop_duplicates().reset_index(drop=True)
print("user_tags 중복 개수:", user_tags.duplicated().sum())
user_tagsuser_tags 중복 개수: 0
중복을 제거하니 데이터의 개수가 17194개에서 2582개로 줄었다.
아이디 수와 채용 공고의 수 확인
print(f"고유 아이디 수: {len(train.userID.unique())}")
print(f"고유 채용 공고 수: {len(train.jobID.unique())}")고유 아이디 수: 196
고유 채용 공고 수: 708데이터는 196명의 고유 아이디, 708개의 채용 공고로 이루어져 있다.
유저들이 가장 많이 지원한 채용 공고는 무엇일까?
- 고유 아이디 별 지원한 공고 그루핑
하나의 유저가 지원한 공고만 그루핑 하기 위해 함수를 만들어 apply로 적용해 주었다.
def applied_job_list(x):
return x.loc[x["applied"]==1, "jobID"].tolist()applied_list = train.groupby(["userID"])[["userID","jobID", "applied"]].apply(lambda x: applied_job_list(x))
applied_listuserID
1 [357, 378, 171, 122, 155, 126, 47, 434]
2 []
3 [527, 730, 134]
4 [138, 183, 10, 134, 654]
5 [45, 320, 52, 303]
...
192 [171, 378, 126, 122]
193 [713, 378, 518]
194 [122, 717, 19]
195 [134]
196 [514, 125, 19, 371, 2]
Length: 196, dtype: object- bar chart를 이용한 시각화
366번 채용 공고가 18명으로 가장 많은 사람이 지원하였고 약 2.1%를 차지한다.
applied_sum = train[train["applied"]==1].count()[0] # 지원한 전체 공고 수
train.loc[train["applied"]==1, "jobID"].value_counts()[:10].plot(kind="bar", ylim=[5,20])
object_cnt = train.loc[train["applied"]==1, "jobID"].value_counts()[:10]
for x,y,z in zip(range(10), object_cnt.values, object_cnt.values/applied_sum*100):
plt.annotate(f"{y}\n({round(z,1)}%)", xy=(x,y), textcoords="data", ha="center")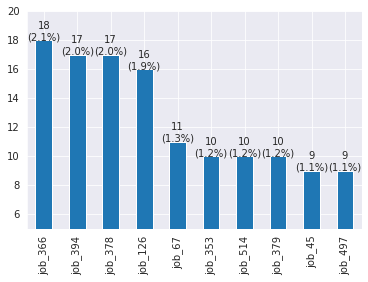
- 그렇다면 이 10곳의 회사의 규모는 어떨까?
job_companies[job_companies["jobID"].isin([366, 394, 378, 126, 67, 353, 514, 379, 45, 497])]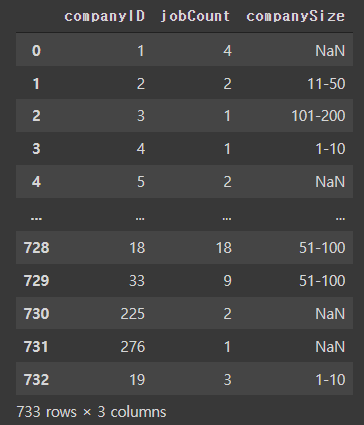
지원자가 많을수록 규모도 클 것이라고 생각했는데 작은 규모의 기업에도 많은 지원자가 있음을 알 수 있다.
결측치 확인
missingno.matrix(job_companies, figsize=(10,5))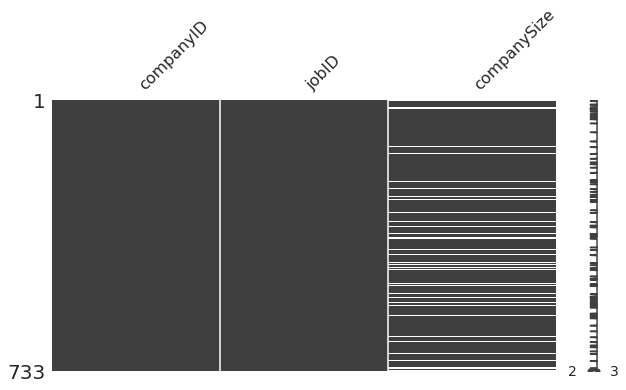
print("결측치의 개수: ",job_companies["companySize"].isna().sum())결측치의 개수: 90결측치 처리
- 채용 공고의 개수로 회사 규모를 알 수 있을까?
cross table을 이용해서 규모에 따른 채용 공고의 수를 확인해 보았다
nullSize_companies = job_companies[job_companies["companySize"].isna()].jobID.tolist()
company_by_jobCount_df = job_info.reset_index().groupby("companyID")[["jobID"]].count().reset_index()
company_by_jobCount_df.rename(columns={"jobID":"jobCount"},inplace=True)
company_by_jobCount_df = pd.merge(company_by_jobCount_df, job_companies[["companyID", "companySize"]], on="companyID", how="right")
crosstable = pd.crosstab(company_by_jobCount_df["jobCount"], company_by_jobCount_df["companySize"].fillna("NaN"))
crosstable[['NaN', '1-10', '11-50','51-100', '101-200', '201-500', '501-1000', '1000 이상']]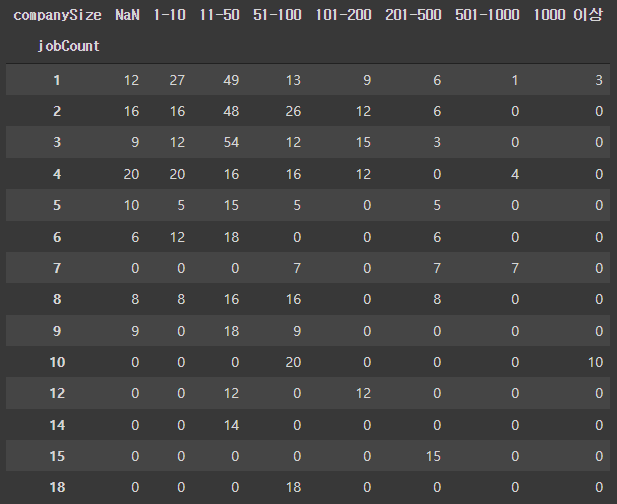
회사 규모가 결측치인 곳은 대부분 1~6개, 최대 9개까지 채용 공고를 냈으며 규모가 200이하인 기업들도 대체로 1 ~ 10개의 채용 공고가 있다.
회사 규모가 나오지 않는다는 것은 신생 기업이거나 소규모 기업일 가능성이 높다고 생각해서 1-10 으로 결측치를 대체하기로 하였다.
job_companies_fillna = job_companies.fillna("1-10")태그ID 변환 및 탐색
태그ID도 tags의 정보를 이용하여 replace로 보기 좋게 바꾸어 주었다.
tags.index = tags["tagID"]
tags_to_dict = tags["keyword"].to_dict()
user_tags["tagID"].replace(tags_to_dict, inplace=True)
user_tags
- 유저들은 어떤 태그를 주로 사용했을까?
groupby와 count를 이용하여 태그의 등장 횟수를 세고 상위 10개의 태그와 그 외 태그 수를 확인해 보았다.
temp = user_tags.groupby(["tagID"])["tagID"].count()
user_tags_grouped_df = pd.DataFrame({"tag":temp.index, "count":temp})
user_tags_grouped_df.reset_index(drop=True, inplace=True)
other_row = pd.DataFrame({"tag":['others'],
"count": [user_tags_grouped_df.sort_values(by="count")["count"].iloc[:-10].sum()]})
user_tags_grouped_df = pd.concat([user_tags_grouped_df, other_row], axis=0, ignore_index=True)
user_tags_grouped_df.sort_values(by="count", ascending=False).iloc[:11]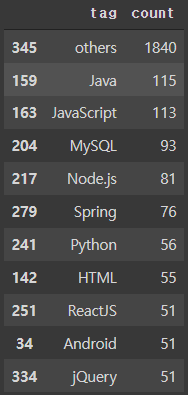
user_tags_grouped_df.sort_values(by="count", ascending=False).iloc[1:11].set_index('tag').T.plot(kind='bar')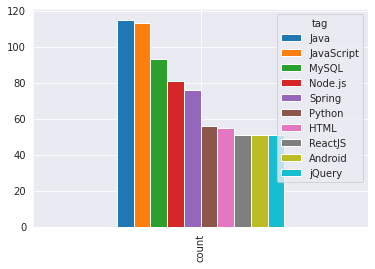
- 마찬가지로 채용공고에 쓰인 태그를 살펴보았다. 이번엔 15개의 태그를 확인했다.
job_tags["tagID"].replace(tags_to_dict, inplace=True)
temp = job_tags.groupby(["tagID"])["tagID"].count()
job_tags_grouped_df = pd.DataFrame({"tag":temp.index, "count":temp})
job_tags_grouped_df.reset_index(drop=True, inplace=True)
other_row = pd.DataFrame({"tag":['others'],
"count": [job_tags_grouped_df.sort_values(by="count")["count"].iloc[:-15].sum()]})
job_tags_grouped_df = pd.concat([job_tags_grouped_df, other_row], axis=0, ignore_index=True)
job_tags_grouped_df.sort_values(by="count", ascending=False).iloc[:16]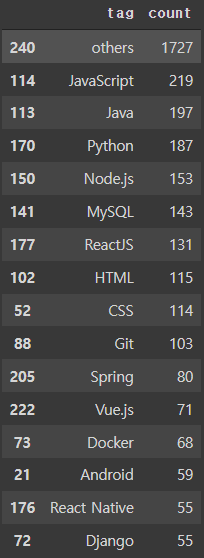
job_tags_grouped_df.sort_values(by="count", ascending=False).iloc[1:11].set_index('tag').T.plot(kind='bar')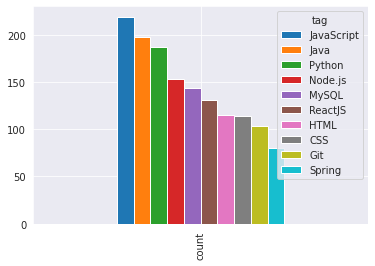
사용 빈도가 높은 태그 순으로 top3 태그 추출
유저 한 사람 당 평균 13개의 태그를, 채용 공고 당 약 5개의 태그를 사용하고 있다.
그 중 단 한번만 사용되는 태그도 있기 때문에 태그를 사용 빈도순으로 정렬하여 top3의 태그를 feature로 만들어 보았다.
job_tags_count_df["tag"] = job_tags_count_df["tagID"] + "," + job_tags_count_df["tag_counts"].astype(str)
job_tags_count_df["tag"] = job_tags_count_df["tag"].apply(lambda x: (int(x.split(",")[1]), x.split(",")[0]))
job_tag_lists = job_tags_count_df.groupby("jobID")[["tag"]].apply(lambda x: x["tag"].tolist()).rename("jobTag").reindex()
job_tag_lists = pd.DataFrame({"jobTag": job_tag_lists})
job_tag_lists
job_info = job_info.set_index('jobID')
jobTag1 = job_info["jobTag"].apply(lambda x: x[0][1]).reset_index(inplace=True)
jobTag2 = job_info[job_info["jobTag"].apply(lambda x: len(x))>1]["jobTag"].apply(lambda x: x[1][1]).reset_index(inplace=True)
jobTag3 = job_info[job_info["jobTag"].apply(lambda x: len(x))>2]["jobTag"].apply(lambda x: x[2][1]).reset_index(inplace=True)태그를 1~2개만 사용하는 유저/공고도 있기 때문에 따로 작업해서 합쳐주었다.
job_info["jobTag1"] = jobTag1
job_info["jobTag2"] = jobTag2
job_info["jobTag3"] = jobTag3
job_info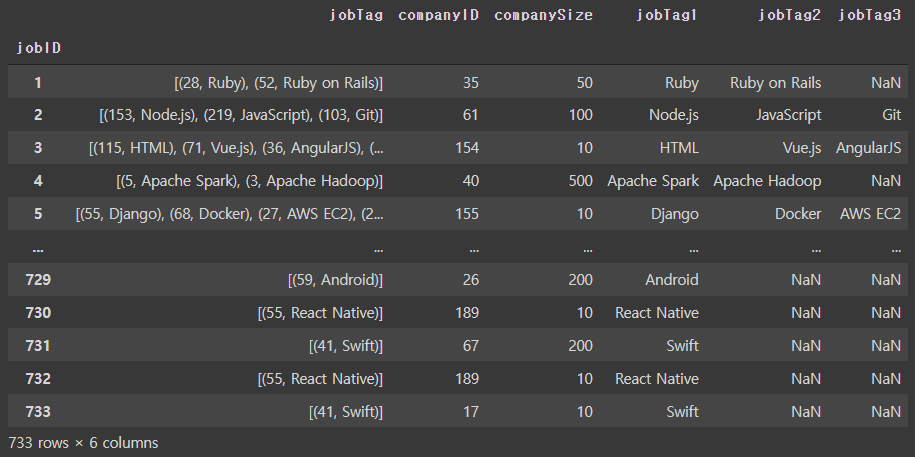
(테스트) word2vec
- word2vec을 이용한 추천 리스트를 만들어보고 싶어서 테스트 해봤다.
job_meta_dict = job_info[["jobTag1","companySize"]].to_dict()
job2vec_dataset = []
for job_list in applied_list:
meta_list = []
for job_id in job_list:
job_meta_1 = "jobID:" + str(job_id)
job_meta_2 = "Tag1:" + job_meta_dict["jobTag1"][job_id]
job_meta_3 = "companySize:" + job_meta_dict["companySize"][job_id]
meta_list.append(job_meta_1)
meta_list.append(job_meta_2)
meta_list.append(job_meta_3)
job2vec_dataset.append(meta_list)from gensim.models import Word2Vec
model = Word2Vec(job2vec_dataset,
size=200,
window=6,
sg=1,
hs=0,
negative=20,
min_count=1,
iter=20)
model.wv.most_similar("jobID:2", topn=10)학습 후 2번 공고와 가장 비슷한 단어를 확인
[('jobTag:Node.js JavaScript Git', 0.9988400340080261),
('jobTag:JavaScript PHP AWS RDS', 0.9972418546676636),
('jobID:400', 0.997045636177063),
('jobID:131', 0.9969872236251831),
('jobTag:Redis Docker JavaScript', 0.9968918561935425),
('jobID:369', 0.9966638088226318),
('jobTag:JavaScript C++ WebGL', 0.9966627359390259),
('jobID:469', 0.9966592788696289),
('jobID:17', 0.9966198205947876),
('jobTag:JavaScript ReactJS React Native', 0.996611475944519)]2번 채용 공고와 비슷한 공고들의 정보
job_info[job_info.index.isin([2, 514, 400, 131, 206, 302, 494, 54, 17, 369, 368])][["companySize", "jobTag1", "jobTag2", "jobTag3"]]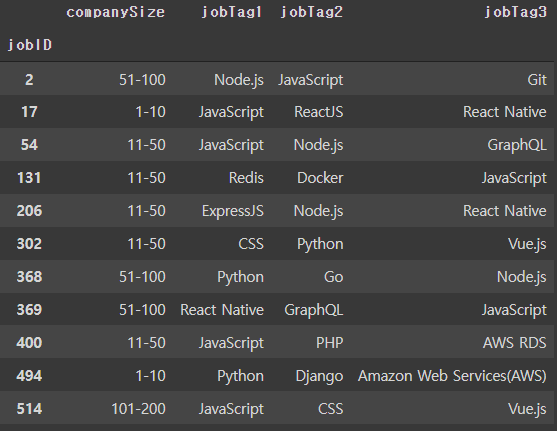
- 이번엔 3개의 태그를 합쳐서 하나의 태그로 넣어보았다.
job_info_copy = job_info.fillna('')
job_info_copy["jobTag"] = job_info_copy["jobTag1"].astype(str) +' '+ job_info_copy["jobTag2"].astype(str) +' '+ job_info_copy["jobTag3"].astype(str)
job_info_copy["jobTag"]
model.wv.most_similar("jobID:2", topn=10)[('jobTag:Node.js JavaScript Git', 0.9981424808502197),
('jobTag:JavaScript C++ WebGL', 0.9533897638320923),
('jobID:469', 0.9520018100738525),
('jobID:407', 0.9509000778198242),
('jobTag:.NET Linux Amazon Web Services(AWS)', 0.9458498954772949),
('jobID:369', 0.9378077983856201),
('jobTag:React Native GraphQL JavaScript', 0.9353669881820679),
('jobTag:JavaScript ReactJS React Native', 0.9320909976959229),
('jobTag:Python Docker CSS', 0.9194403886795044),
('jobID:17', 0.9187346696853638)]job_info_copy[job_info_copy.index.isin([2, 469, 407, 369, 17, 418, 400, 131, 125, 558])][["companySize", "jobTag"]]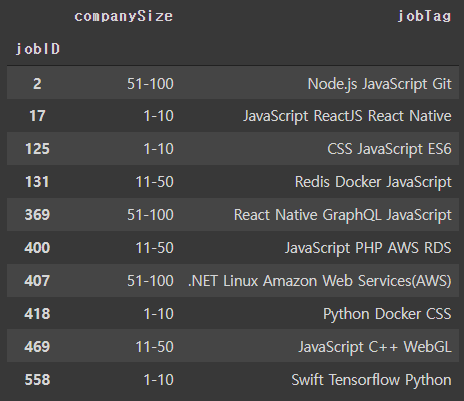
모델은 좀 더 고민을 해봐야겠다.!
유저와 채용공고의 태그의 관계
유저가 사용한 태그와 채용 공고의 태그가 많이 겹칠 수록 지원할 가능성이 높을 것이다.
위와 같은 가설을 세우고 유저 태그와 공고 태그의 비율 tag_ratio을 구해보았다.
train = pd.merge(train, job_tags_count_df.groupby("jobID")[["tagID"]].apply(lambda x: x["tagID"].tolist()).rename("jobTags"), left_on="jobID", right_on="jobID")
train = pd.merge(train, user_tags_count_df.groupby("userID")[["tag"]].apply(lambda x: x["tag"].tolist()).rename("userTags"), left_on="userID", right_on="userID")
train["union"] = train["jobTags"] + train["userTags"]
train["tag_ratio"] = (train["union"].apply(lambda x: len(x)) - train["union"].apply(lambda x: len(set(x))))/ train["userTags"].apply(lambda x: len(x))
train["tag_ratio"].describe()count 6000.000000
mean 0.120155
std 0.131489
min 0.000000
25% 0.000000
50% 0.090909
75% 0.166667
max 1.000000
Name: tag_ratio, dtype: float64plt.figure(figsize=(10,5))
sns.histplot(train, x="tag_ratio", hue="applied", kde=True, legend=True)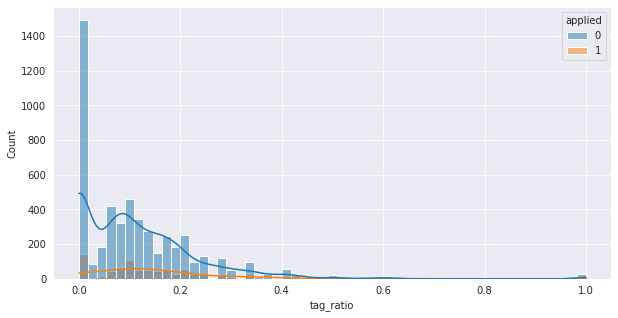
sns.heatmap(train[["jobID", "tag_ratio", "companyID", "companySize", "applied"]].corr(), annot=True, cbar=True)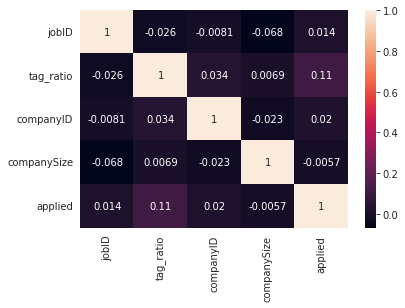
companySize보다는 applied와 상관관계가 있는 편이다.
태그에 해당하는 채용공고 임베딩
유저가 지원한 채용공고를 기준으로 할 경우, 지원하지 않은 채용공고가 반 이상이어서 정보가 없는 경우가 많았다. 그래서 이번엔 태그를 기준으로 비슷한 채용공고가 나오도록 모델을 만들어 보았다.
job_by_tags_list = job_tags.groupby("tagID")[["jobID"]].apply(lambda x: x["jobID"].tolist()).rename("jobID")tagID
1 [36, 60, 63, 76, 152, 209, 210, 245, 252, 285,...
2 [20, 143, 193, 457, 472, 539, 558, 565, 574, 6...
3 [5, 25, 58, 85, 117, 131, 141, 176, 183, 190, ...
4 [7, 16, 38, 52, 53, 68, 89, 93, 103, 104, 150,...
5 [8, 18, 36, 40, 49, 51, 72, 73, 82, 84, 95, 11...
...
249 [383]
250 [406]
251 [406]
252 [594]
253 [188]
Name: jobID, Length: 240, dtype: objecttagID를 기준으로 groupby를 한 후 이번엔 jobID, jobTag만 메타정보로 넣어 모델을 학습 시키고 jobID=1과 유사한 채용공고를 살펴보았다.
model.wv.most_similar("jobID:1", topn=10)[('jobTag:Ruby, Ruby on Rails, ', 0.9121835827827454),
('jobID:691', 0.8171674609184265),
('jobID:37', 0.8109441995620728),
('jobTag:Redis, Ruby, Elasticsearch', 0.8029480576515198),
('jobID:137', 0.7926441431045532),
('jobID:35', 0.7921372652053833),
('jobTag:Ruby, JavaScript, Ruby on Rails', 0.7874622344970703),
('jobTag:JavaScript, HTML, Ruby on Rails', 0.7853167653083801),
('jobTag:Ruby on Rails, Ruby, ', 0.7090970277786255),
('jobID:53', 0.6957418918609619)] 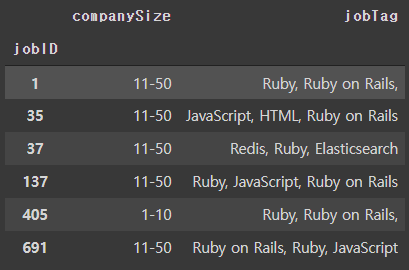
유사한 태그를 가진 jobID가 출력되는 것을 확인할 수 있다.
한 유저가 지원한 공고와 job_tags
applied_list.head()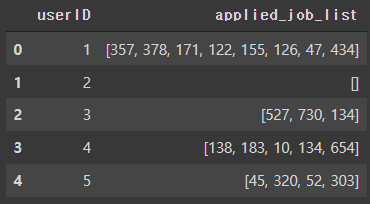
applied_list["applied_job_list"].apply(lambda x: len(x)).describe()count 196.000000
mean 4.372449
std 2.690736
min 0.000000
25% 3.000000
50% 4.000000
75% 5.000000
max 16.000000
Name: applied_job_list, dtype: float64한 번도 지원하지 않은 지원자는 5명이고 가장 많이 지원한 횟수는 16번이다.
- 1번 유저가 지원한/ 지원하지 않은 채원공고의 정보 확인
train[(train["applied"]==0)& (train["userID"]==1)].groupby("userID")[["jobID"]].apply(lambda x: x["jobID"].tolist()).valuesarray([list([372, 730, 413, 464, 59, 228, 381, 467, 324, 134, 431, 501, 152, 511, 465, 673, 60, 507, 529])],
dtype=object)job_info_copy[job_info_copy.index.isin([357, 378, 171, 122, 155, 126, 47, 434])][["companySize", "jobTag"]]
job_info_copy[job_info_copy.index.isin([372, 730, 413, 464, 59, 228, 381, 467, 324, 134, 431, 501, 152, 511, 465, 673, 60, 507, 529])][["companySize", "jobTag"]]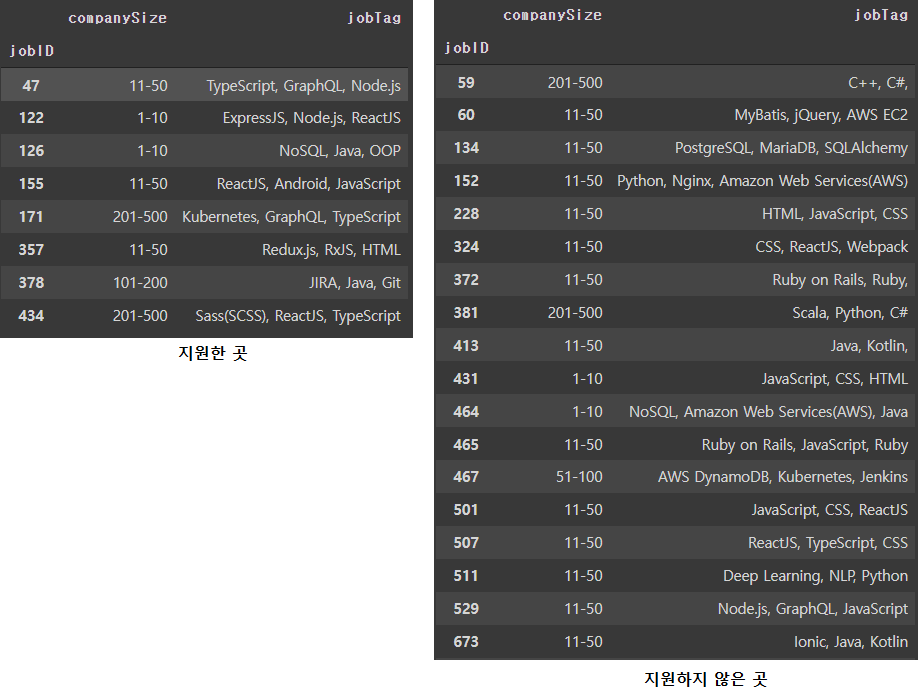
- 1번 유저가 체크한 태그 리스트
user_tags.loc[user_tags["userID"]==1, "tagID"].valuesarray(['MongoDB', 'Docker', 'Java', 'Jenkins', 'ExpressJS', 'OpenCV',
'SQLite', 'ReactJS', 'Machine Learning', 'Android', 'Linux',
'Node.js', 'Python'], dtype=object)유저의 중복 태그
태그의 중복이 왜 발생했는지가 중요할 것 같다.
만약 열람할 때마다 태그가 중복됐다면 중복된 태그의 갯수가 모두 동일해야 하는데 그렇지 않다.
따라서 중복된 태그의 갯수를 유저가 단순히 중복해서 채크 했다고 가정하고 중복된 갯수만큼 태그에 점수를 주었다.
from collections import Counter
train = pd.merge(train, user_tags.groupby("userID")[["tagID"]].apply(lambda x: Counter(x["tagID"])).rename("user_tags_count").reset_index(), left_on="userID", right_on="userID")
user_tags.groupby("userID")[["tagID"]].apply(lambda x: Counter(x["tagID"])).reset_index()
def cal_tag_score(df):
tag_scores= []
for i in df.index:
tag_score = [0]*len(df["jobTag"][i])
for j, tag in enumerate(df["jobTag"][i]):
try:
tag_score[j] = df["user_tags_count"][i][tag]
except:
tag_score[j]=0
tag_scores.append(tag_score)
return tag_scores
train["tag_scores"] = cal_tag_score(train)
train["tag_scores_sum"] = train.tag_scores.apply(lambda x: sum(x))
sns.boxplot(data = train[["applied", "tag_scores_sum"]], x="applied", y = "tag_scores_sum")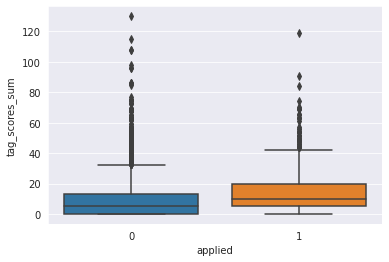
이렇게 봐서는 유의한 차이가 있는건지 잘 모르겠다. 때문에 카이제곱검정을 해보았다.
from scipy.stats import *
kstest(train[["applied"]].values, 'norm')
kstest(train[["tag_scores_sum"]].values, 'norm')>>> KstestResult(statistic=0.8413447460685429, pvalue=0.0)
KstestResult(statistic=1.0, pvalue=0.0)cross_table = pd.crosstab(train["applied"], train["tag_scores_sum"])
obs = cross_table.values
statistics, pvalue, dof, expected = chi2_contingency(obs)
print(pvalue < 0.05)>>> True두 변수는 정규분포를 따르고 pvalue가 0.05미만이므로 서로 종속적이라 할 수 있다.
- 태그가 높아도 지원하지 않은 이유는 무엇일까?
유저가 지원한 공고의 태그 점수 평균은 14이다. 박스플롯을 보면 태그의 점수가 매우 높아도 지원하지 않는것을 볼 수 있는데, 태그 점수가 14점 이상인데도 지원하지 않은 데이터는 약 20%(1,240개)가 있었다.
개인적인 경험으로는 경력 제한이 있어서 지원하지 못했다거나, 나중에 지원하기위해 지원을 보류한 경우 등이 있을 것으로 생각한다.
지원자의 성향 반영
성향에 따라 신중하게 지원하는 지원자가 있는 반면, 적극적으로 지원하는 지원자도 있음.
테스트할 데이터의 고유 userid가 같기 때문에 이를 현재까지 지원한 공고의 갯수로 나타냈다.
sorted(train.userID.unique()) == sorted(test_job.userID.unique()) >>> Truetrain = pd.merge(train, train.groupby("userID")[["applied"]].sum().reset_index(), left_on="userID", right_on="userID")
train.rename(columns={"applied_x":"applied", "applied_y":"applied_sum"}, inplace=True)feature 선정과 모델 학습 및 평가
sns.heatmap(train.corr(), annot=True, cbar=True)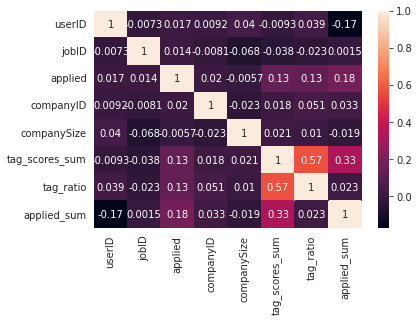
compaySize는 상관관계가 거의 없기 때문에 사용하지 않는다. tag_scores_sum과 tag_ratio의 상관관계가 거의 0.6에 가깝기 때문에 실험을 통해 어떤 feature를 선택할 지 결정해야 할 것 같다.
feature 수가 적기 때문에 간단히 Randomforest 모델을 사용하였다.
또한 데이터 양이 적기 때문에 KFold를 사용해서 과대적합을 막고 일반화 성능을 높인다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold, KFold
import numpy as np
kfold = KFold(n_splits=5).split(X_train, y_train)
scores = []
forest = RandomForestClassifier(n_estimators=500, random_state=2022)
for k, (tri, val) in enumerate(kfold):
forest.fit(X_train.iloc[tri], y_train.iloc[tri])
score = forest.score(X_train.iloc[val], y_train.iloc[val])
scores.append(score)
print(f'fold {k+1} 모델의 정확도: {score*100:.2f}%')
print(f"CV 정확도: {np.mean(scores):.3f} +/- {np.std(scores):.3f}")fold 1 모델의 정확도: 88.08%
fold 2 모델의 정확도: 83.08%
fold 3 모델의 정확도: 82.58%
fold 4 모델의 정확도: 79.50%
fold 5 모델의 정확도: 76.92%
CV 정확도: 0.820 +/- 0.038상관관계가 높았던 'tag_scores_sum'와 'tag_ratio' 중 하나를 뺀 결과를 확인한다.
- tag_ratio 사용 할 경우
fold 1 모델의 정확도: 85.75%
fold 2 모델의 정확도: 84.08%
fold 3 모델의 정확도: 83.00%
fold 4 모델의 정확도: 82.00%
fold 5 모델의 정확도: 77.92%
CV 정확도: 0.825 +/- 0.026- tag_scores_sum 사용할 경우
fold 1 모델의 정확도: 88.75%
fold 2 모델의 정확도: 83.75%
fold 3 모델의 정확도: 85.33%
fold 4 모델의 정확도: 82.42%
fold 5 모델의 정확도: 78.58%
CV 정확도: 0.838 +/- 0.033최종적으로 약 1.8%의 정확도 상승한 정확도 83.8%의 모델을 만들었다.
