- 데이터 출처: MovieLens Dataset
목표
Collaborative Filtering 기반, Matrix Factorization 기반 추천 모델을 이해 및 구현
훈련된 모델의 결과를 해석하고 결과를 평가
데이터 불러오기
import pandas as pd
rating_url = 'https://raw.githubusercontent.com/yoonkt200/python-data-analysis/master/data/ml-1m/ratings.dat'
rating_df = pd.io.parsers.read_csv(rating_url, names=['user_id', 'movie_id', 'rating', 'time'], delimiter='::', engine ='python')
rating_df.head()
movie_url = 'https://raw.githubusercontent.com/yoonkt200/python-data-analysis/master/data/ml-1m/movies.dat'
movie_df = pd.io.parsers.read_csv(movie_url, names=['movie_id', 'title', 'genre'], delimiter='::', engine ='python', encoding='ISO-8859-1')
movie_df.head()
각 데이터프레임은 다음과 같은 정보를 담고 있다.
-
rating_df
user_id : 영화를 시청한 사용자 아이디
movie_id : 영화의 아이디
rating : 사용자가 영화를 평가한 점수
time : 사용자가 영화를 시청한 시간 -
movie_df
movie_id : 영화의 아이디
title : 영화 제목
genre : 영화 장르
EDA
- 유저의 수와 영화의 개수 파악
print("고유 아이디 수:", len(rating_df["user_id"].unique()))
print("영화의 개수:", len(rating_df["movie_id"].unique()))>>> 고유 아이디 수: 6040
>>> 영화의 개수: 3706- 영화 점수 분포 시각화
import seaborn as sns
sns.countplot(rating_df["rating"])
object_cnt = rating_df["rating"].value_counts()
for x,y,z in zip(object_cnt.index, object_cnt.values, object_cnt.values/object_cnt.sum()*100):
plt.annotate(f"{y}\n({round(z,2)}%)", xy=(x-1,y+70), textcoords="data", ha="center")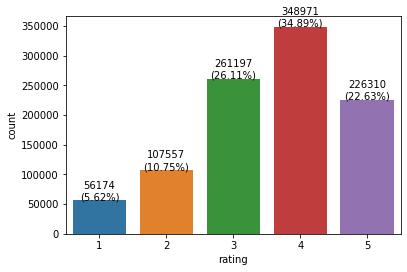
4점을 준 경우가 348,971로 가장 많고 1점을 준 경우가 56,174개로 가장 적다.
Rating Matrix
Rating Matrix란 User를 row, Item을 Column으로 하며 Value를 Rating으로 하는 행렬이다.
Rating의 종류에는 Explicit Feedback과 Implicit Feedback이 의미한다. Explicit Feedback은 영화 점수, 리뷰 점수, 좋아요와 같이 직접적으로 유저가 명확하게 좋고 싫음을 평가한 데이터를 의미하고 Implicit Feedback은 조회, 시청, 구매, 찜 표시와 같이 유저가 단순한 클릭이나 사용한 데이터를 의미한다.
Rating Matrix를 추천 모델로 사용하는 방법에는 대표적으로 Collaborative Filtering(CF)과 Matrix Factorization(MF)이 있다.
Colaborative Filtering Modeling
고객들의 선호도와 관심 표현을 바탕으로 선호도, 관심에서 비슷한 패턴을 가진 고객을 식별해내는 기법으로, 비슷한 취향을 가진 고객에게 서로 아직 구매하지 않은 상품들은 교차 추천하거나 분류된 고객의 취향이나 생활 형태에 따라 관련 상품을 추천하는 형태의 서비스를 제공하기 위해 사용된다.
User-based CF / Item-based CF
User-based CF : 비슷한 취향을 가진 고객이 평가한 점수를 바탕으로 어떤 상품을 추천할 지 예측. 일반적으로 사용되는 방식
Item-based CF : 상품과 상품 사이의 유사도를 기준으로 추천. 새로 등장한 상품에는 적용하기 어려운 단점이 있다.
CF-based (KNN) 모델 학습
from surprise import Dataset, Reader
from surprise.model_selection import train_test_split
# Reader, Dataset 오브젝트로 학습용 데이터셋 생성 및 분리
reader = Reader(rating_scale=(1,5)) #1~5점 사이의 rating점수가 있다는 것을 알려줌
data = Dataset.load_from_df(rating_df[["user_id", "movie_id", "rating"]], reader)
trainset, testset = train_test_split(data, test_size=0.25)
# KNNBasic 모델 학습
from surprise import KNNBasic
# k: 주변 샘플을 몇 개까지 참조할 것인지, cosine: 가장 일반적인 유사도 계산 방식
algo = KNNBasic(k=40, min_k=1, sim_options={"user_based":True, "name":"cosine"})
algo.fit(trainset)
predictions = algo.test(testset)
# 모델 평가
from surprise import accuracy
acc = accuracy.rmse(predictions)
accRMSE: 0.9591
0.9591293463391027test 결과 확인
prediction[:5][Prediction(uid=2691, iid=912, r_ui=5.0, est=5, details={'was_impossible': False}),
Prediction(uid=3648, iid=2166, r_ui=2.0, est=2.9331766731573703, details={'was_impossible': False}),
Prediction(uid=4279, iid=1974, r_ui=4.0, est=3.7635448815576646, details={'was_impossible': False}),
Prediction(uid=5767, iid=2288, r_ui=5.0, est=3.7394892080225373, details={'was_impossible': False}),
Prediction(uid=5767, iid=2144, r_ui=4.0, est=4.01071767527927, details={'was_impossible': False})]uid: 유저 아이디, iid: 영화 아이디, r_ui: 실제 평가 점수, est: 예측한 평가 점수
Matrix Factorization Modeling
MF-based (SVD) 모델 학습
from surprise import SVD
param_list = [10, 50, 100, 150, 200]
rmse_list_by_factors = []
ttime_list_by_factors = []
# n_factor depth에 따른 RMSE 확인
for n in param_list:
train_start = time.time()
algo = SVD(n_factors=n)
algo.fit(trainset)
train_end = time.time()
print("training time of model: %.2f seconds" % (train_end-train_start))
print(f"RMSE of test dataset in SVD model, n_factors={n}")
predictions = algo.test(testset)
rmse_list_by_factors.append(accuracy.mse(predictions))
ttime_list_by_factors.append(train_end-train_start)
print("-"*20)
print("searching n_factors is finish.")n_factor에 따른 RMSE 시각화
# plt의 plot 함수로 결과 시각화
import matplotlib.pyplot as plt
plt.plot(param_list, rmse_list_by_factors)
plt.title("RMSE by n_factors of SVD", fontsize=14)
plt.xticks(param_list)
plt.xlabel("n_factors", fontsize=12)
plt.ylabel("RMSE", fontsize=12)
for x, y in zip(param_list, rmse_list_by_factors):
plt.annotate(f'{round(y,4)}', xy=(x+15,y), textcoords="data", ha="center")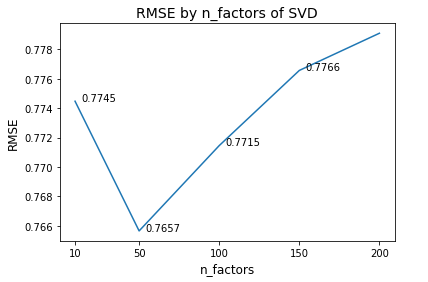
n_factor=50 일 때 RMSE 최소가 되고, 더 늘릴 경우 과적합으로 RMSE가 상승함을 알 수 있다.
최종 RMSE 평가
algo = SVD(n_factors=50)
algo.fit(trainset)
predictions = algo.test(testset)
acc = accuracy.rmse(predictions)
accRMSE: 0.8737
0.873735086939124평가에 시간 고려해보기
CF, MF기반 추천 시스템의 한계(가정)
- 사용자의 과거 선호는 미래에도 동일하다는 가정
- Time Series로 추정된 선호도가 아닌, Estimate 되거나 Factorized 된 점수
- A시점에 평가한 선호도와, B시점에 평가한 선호도가 동일 선에서 학습됨
- Test 데이터에 대한 평가 역시, 시간이 고려되지 않은 "랜덤한 빈공간 찾기" 식으로 평가
따라서, 현재 고객의 preference에 적합하도록 시간을 고려하여 테스트 데이터를 분리한다.
시간을 고려해서 SVD 모델 학습
rating_df['time'].quantile(q=0.8, interpolation='nearest') # 8:2로 나눌 수 있는 시간 기준탐색 --> 975768738
train_df = rating_df[rating_df["time"]< 975768738][["user_id", "movie_id", "rating"]]
test_df = rating_df[rating_df["time"]>= 975768738][["user_id", "movie_id", "rating"]]
# 추출한 학습 데이터셋으로 SVD 모델 학습
data = Dataset.load_from_df(train_df, reader=reader)
train_data = data.build_full_trainset()
algo = SVD(n_factors=50)
algo.fit(train_data)
- 기준 시간 이전 train_data를 이용하여 다시 한 번 SVD 모델 학습
테스트 및 평가
추천 시스템에서의 평가
CF, MF 기반 추천시스템에서는 일반적으로 MAP를 사용.
추천 시스템에서는 각 유저마다의 Precision을 계산한 뒤, 이것을 모든 추천 대상 유저로 확장하여 평균적인 지표를 계산한 것이라고 볼 수 있음.
# 예측할 부분 (rating이 없는) 데이터만 추출
test_data = train_data.build_anti_testset()
# test
predictions = algo.test(testset)
predictions = algo.test(test_data)
# test 평가를 위해 시청하지 않은 영화의 예상 점수를 dictionary 형태로 추출
estimated_unwatched_dict = {}
for uid, iid, _, predicted_rating, _ in predictions:
if uid in estimated_unwatched_dict:
estimated_unwatched_dict[uid].append((iid, predicted_rating))
else:
estimated_unwatched_dict[uid] = [(iid, predicted_rating)]build_anti_testset을 이용하면 rating이 없는 데이터를 테스트 데이터로 추출할 수 있다.- 테스트 결과 중 movie_id와 예측 점수를 user_id를 key로 하는
estimated_unwatched_dict딕셔너리에 저장한다.
k파라미터 별 추천 결과 평가 및 시각화
def get_map_topk(k):
user_metric = []
for user in estimated_unwatched_dict:
estimated_list = estimated_unwatched_dict[user].copy()
estimated_list.sort(key=lambda tup: tup[1], reverse=True)
try:
top_k_prefer_list = [movie[0] for movie in estimated_list[:k]]
actual_watch_list = user_watch_dict_list_test[user_watch_dict_list_test.index==user].values.tolist()[0]
user_metric.append((user, top_k_prefer_list, actual_watch_list))
except:
pass
# MAP: 유저들의 precision 평균으로 구함
precision_list = []
for user in user_metric:
predictive_values = user[1]
actual_values = set(user[2])
tp = [pv for pv in predictive_values if pv in actual_values]
precision = len(tp) / len(predictive_values)
precision_list.append(precision)
return sum(precision_list) / len(precision_list)- k개의 영화를 추천했을 때의 결과를 MAP로 평가한다.
- 유저 당 영화를 k개 미만으로 추천할 경우도 있으므로 try-except문을 사용
k_param_list = range(1,30)
map_list = []
for k in k_param_list:
map_list.append(get_map_topk(k))
plt.plot(k_param_list, map_list)
plt.title('MAP by top k recommendation')
plt.ylabel('MAP', fontsize=12)
plt.xlabel('k', fontsize=12)
plt.show()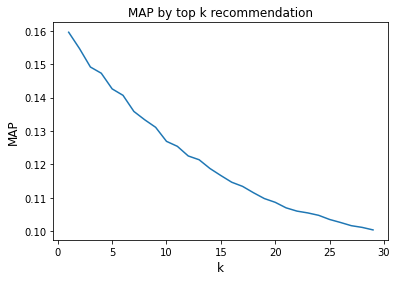
- k가 증가할 수록 MAP는 감소하는 것을 볼 수 있다. 즉, 더 많은 영화를 추천할 수록 정확도가 떨어진다는 의미이다.
- 대부분 추천 시스템의 MAP는 0.1~0.2 사이라고 한다.
