- 2025년 1월 26일 작성
- 2025년 3월 2일 유의할 점에 메모리 관련 내용 추가
서론
Redis는 단일 CPU코에서 초당 최대 500,000개의 SET 및 GET Operation을 처리할 수 있는 빠른 데이터베이스이다. Redis가 빠른 이유는 인메모리 데이터베이스인 이유도 있지만, 싱글스레드 아키텍처를 가지기 때문이기도 하다. 이 덕분에 Atomic을 보장하는 특징도 있다.
하지만 인터넷을 찾아보면 Redis가 멀티스레드라는 말도 있고, 실제로 돌려봤을 때 완전한 단일 스레드로 실행되지 않는 것을 확인할 수 있었다. Redis에 대해 정리할 겸 관련해서 찾아본 내용을 정리하고자 글을 쓴다!
미리 결론부터 말하면..
Redis는 완전한 싱글 스레드로 동작하지 않는다. 하지만 클라이언트의 요청을 처리하는(명령을 처리하는) 부분은 단일 스레드로 처리된다.
사용자 요청 처리 부분이 단일 스레드로 처리되기 때문에 Atomic이 보장된다.
Redis란
인메모리에서 빠르게 동작하고, 자료형과 기능이 다양한 오픈소스 비관계형 데이터베이스
Redis는 BSD 라이선스의 오픈소스 소프트웨어로, 빠른 속도와 다양한 자료형을 제공한다는 특징이 있다. ANSI C로 작성되었고, 아주 작은 메모리로도 데이터를 유지할 수 있다고 한다.
캐시, 메시지 브로커, 데이터 구조 저장소 등 다양한 용도로 널리 사용되는 인기있는 데이터베이스이다.
Redis를 사용하는 이유
Redis를 사용하는 이유들을 정리해보면 다음과 같다
- 인메모리이면서 싱글스레드 구조를 채택하고 있기 때문에
속도가 굉장히 빠름 자료형이 풍부해서 다양한 곳에서 사용가능- 간단하고 유연한 데이터베이스 기능
- 설정이 간편
Redis 사용시 유의할 점
인메모리 데이터베이스는 비용이 비싸다
Redis는 모든 데이터를 RAM(메모리)에 저장함으로써 기존 디스크 기반의 데이터베이스보다 훨씬 빠르게 데이터를 처리할 수 있는 장점이 있다. 하지만 메모리는 디스크에 비해 비용이 비싸다는 단점이 존재한다. 간편하고 속도가 빠르다고 무작정 모든 데이터를 저장하면 안된다는 거다. 적절한 용량을 잡고 필요한 만큼 쓰는 게 좋다.
(RAM의 대기시간은 100~120 나노초, SSD는 50~150 마이크로초, HDD는 1~10 밀리초)
SQL처럼 표현력이 뛰어난 수단이 없음
일부 트랜잭션 기능을 지원하지 않음
RDBMS에서 제공하는 ACID를 완전하게 보장하지 않는다. Redis가 싱글스레드 기반으로 데이터 접근을 수행하기 때문에 격리성은 보장되지만, 다른 부분은 완전하게 보장되지 않는다.
또한 RDBMS의 경우 트랜잭션 실패 시 다양한 방법(언두로그 등)으로 롤백하는 방법을 제공하지만 Redis는 트랜잭션 실패 시 롤백하는 기능을 지원하지 않는다. 명령어를 실패하더라도 그대로 나머지 처리를 계속해서 수행하는 패턴으로 되어있다. (Redis에 신뢰성과 일관성이 중요한 데이터를 보관할 생각은 하지 않는 게 좋겠다)
이렇게 RDBMS에 비해 제한되는 부분이 있기때문에 Redis는 RDBMS와 함께 보조수단으로 사용되는 경우가 많다. 프로젝트를 진행하는 경우에도 Redis는 JWT 토큰 저장소나 캐시로 이용하고, 마스터 데이터베이스는 MySQL을 사용하는 경우가 많다. (굉장히 빠르고, 자료형이 풍부하다는 장점을 살려 RDBMS의 성능저하 문제를 개선하는 캐시서버로 자주 사용된다)
Redis는 싱글 스레드 기반이다
(Redis의 구조와 영속성관련한 이야기를 더 적고싶지만, 이번 블로그는 주제에 맞게 싱글스레드 관련 이야기에 초점을 맞추겠다)
대부분의 멀티스레드 애플리케이션에서 각 스레드는 일반적으로 단일 I/O스트림과 연결된다. 하지만 이 경우 메모리, 스레드 동기화, 컨텍스트 스위칭에 대한 오버헤드와 같은 여러가지 단점이 존재한다.
Redis는 싱글 스레드 주도 처리 모델을 채택하고 있다. (ae라는 고유 이벤트 주도 라이브러리를 사용함) 이를 통해 멀티스레드를 사용할 때의 오버헤드와 복잡성을 방지할 수 있었다.
싱글 스레드로 처리하면 한 요청이 다른 요청을 기다리는 blocking이 발생하거나 성능이 저하되는 문제를 떠올릴 수 있지만, Redis는 Multiplexing 기법과 이벤트 루프를 형성하는 방법을 사용하여 많은 요청을 처리할 수 있도록 설계되어있다.
하지만 완벽한 싱글 스레드는 아니다. Redis는 6.0버전부터 성능을 위해 부분 멀티스레드를 도입하였다. Redis에서 멀티스레드가 적용되는 부분은 다음과 같다.
- 클라이언트가 전송한 명령을 네트워크로 읽어서 파싱하는 부분
- 명령이 처리된 결과 메시지를 클라이언트에게 네트워크로 전달하는 부분
멀티스레드가 도입되었지만 데이터 접근 부분은 여전히 싱글 스레드로 작동하기 때문에 Atomic을 보장한다.
Multiplexing
multiplexing 기법은 하나의 통신채널을 통해 다량의 데이터를 전송하는 데 사용되는 기술
Redis는 싱글스레드이지만, I/O Multiplexing을 통해 하나의 프로세스/스레드가 여러 개의 요청을 동시에 blocking없이 처리할 수 있다.
구조는 다음과 같다.
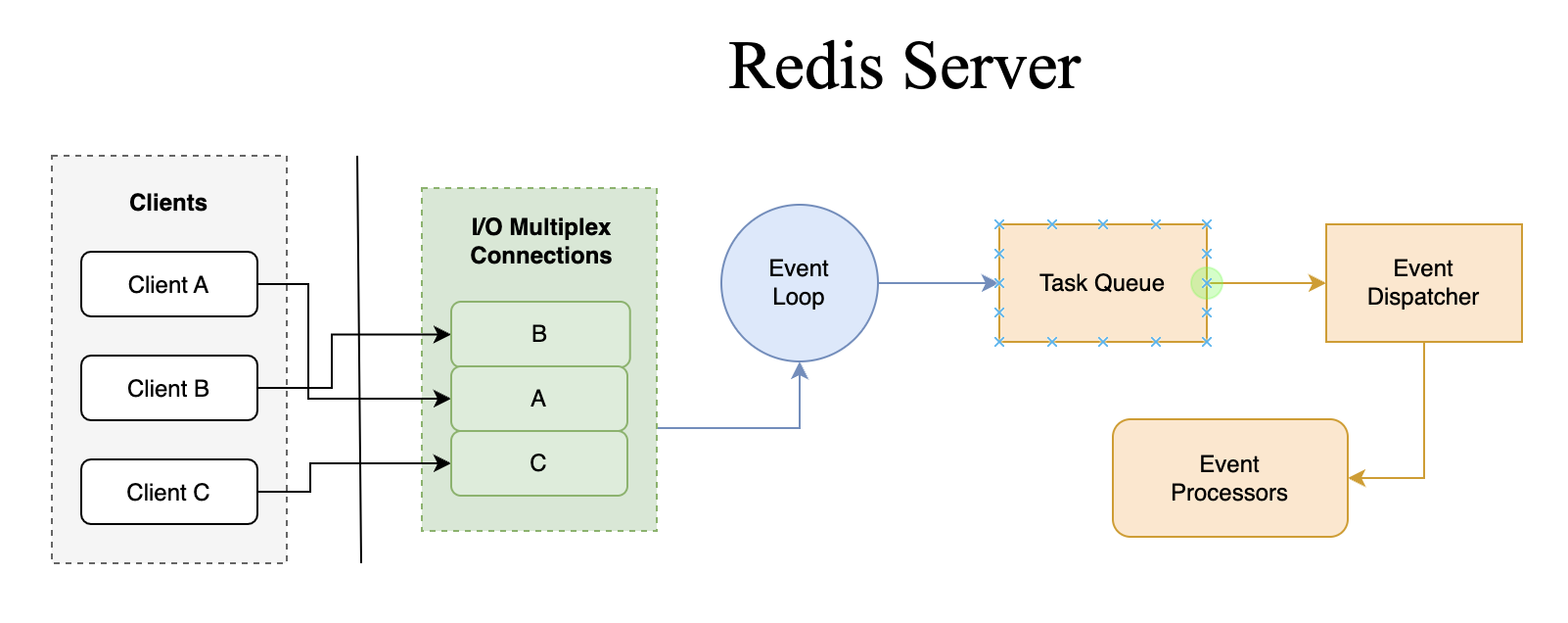
(사진출처 : https://www.linkedin.com/pulse/why-heck-single-threaded-redis-lightning-fast-beyond-in-memory-kapur/)
모든 작업 처리는 단일 콜스택에서 이루어지고, 비동기 처리는 Queue를 통해 이벤트 루프 방식으로 동작한다. 동작 방식은 다음과 같다.
- Redis는 새로운 클라이언트 연결, 클라이언트에서 들어오는 데이터 또는 I/O 작업 완료와 같은 이벤트가 발생하기를 기다리는 단일 이벤트 루프를 사용
- 새 클라이언트가 Redis에 연결되면 이벤트 루프에 등록되고 이벤트 루프는 들어오는 데이터에 대한 연결을 모니터링함
- 클라이언트로부터 데이터가 도착하면 이벤트 루프는 이벤트 유형을 결정하고 그에 따라 처리함
- 클라이언트의 요청에 I/O작업이 필요한 경우, 이벤트 루프는 다른 클라이언트의 연결의 진행을 차단하지 않고 작업을
비동기적으로 수행 - 이벤트 루프가 여러 클라이언트의 이벤트를 처리할 때 각 클라이언트에 대해 보류 중인 작업 대기열을 유지 관리한다.
이를 통해 Redis는 실제 처리가 단일 스레드 내에서 발생하더라도 동시에 여러 클라이언트에 서비스를 제공할 수 있다.
Pipelining
클라이언트가 단일 네트워크 패킷으로 여러 요청을 보낼 수 있음
Redis는 파이프라이닝을 사용하여 성능을 개선한다.
파이프라이닝을 사용하여 클라이언트가 단일 네트워크 패킷으로 여러 요청을 보낼 수 있고, Redis는 각 요청 후 응답을 기다리지 않고 일관 처리한다. 이를 통해 네트워크 오버헤드를 줄이고 시스템의 전체 처리량을 개선한다.
Redis 사용 시 유의해야할 점
1. CPU 사용률 제한
Reids는 데이터 처리 부분을 메인스레드 하나에서 처리하기 때문에 요청이 느리게 처리되는 경우 다른 모든 클라이언트가 이 요청이 처리될 때까지 기다리는 경우가 발생할 수 있다.
그렇기 때문에 Redis 사용 시 명령어의 알고리즘 시간복잡도를 잘 고려해야한다.
2. 블로킹되는 명령어 존재
Redis는 Non-Blocking I/O Multiplexing 기법을 사용하기 때문에 I/O작업에서 스레드가 차단되지는 않는다. 하지만 BLPOP, PRPOP과 같은 일부 Redis 명령의 경우 완료될 때까지 전체 서버를 차단하는 경우가 존재한다. 그렇기 때문에 프로덕션 환경에서 blocking을 유발하는 명령여(KEYS)를 사용하지 않도록 유의해야한다.
3. Built-in Sharing 없음
Redis는 샤딩에 대한 기본 제공 지원이 없다. 그래서 수평 확장이 어려울 수 있다.
단일 스레드 아키텍처에서는 여러 샤드를 효과적으로 관리하기 어려울 수 있으니 유의해야한다.
4. 메모리 사용
모든 데이터를 메모리에 저장하는 특성상, Redis가 처리할 수 있는 데이터 세트의 크기가 제한될 수 있다는 점을 염두해둬야한다.
+) 추가 내용
실제로 데이터의 사이즈는 같은 내용이라도 메모리에 있을 때가 가장 크고, AOF, RDB 파일 순으로 작아진다고 한다. 읽기 성능을 위한 관리용 메모리(포인터) 오버헤드와 리눅스 메모리 할당방식에 따른 오버헤드(내부 단편화)도 존재한다고 한다. 이 블로그 글의 글 아래부분에 관련 내용이 자세하게 설명되어있다.
마치며..
Redis를 공부하며 간단하게 정리해봤다. 이전에는 대충 자료구조에 저장하듯이 Redis에 데이터를 저장하면 된다고 생각했는데 고려해야하는 부분도 꽤 있다는 걸 알게되었다. 장점이 많은 Redis를 잘 활용할 수 있게되면 좋겠다!
참고자료
