문자열 인코딩 이야기
이 포스팅은 2024.12.13에 작성되었습니다.
- 24.12.14 유니코드 다국어 평면 관련 내용 추가
서론
인코딩 관련해서 한 번은 꼭 확실하게 공부하고 정리해야겠다고 생각했는데, 늘 우선순위에서 밀려서 항상 찝찝한 기분으로 개발을 해왔다. 이제는 조금 여유가 생겼고, 이 찝찝함을 얼른 덜어내고 싶어서 이번 블로그에 제대로 정리해보려고 한다.
웹 개발을 조금이라도 해봤다면 인코딩을 안들어볼 수가 없다. html을 띄울 때도, 인텔리제이에서 테스트코드를 실행할 때도, 데이터베이스 테이블을 만들 때도 항상 글자가 깨질 때가 있고, 에러를 고치는 과정에서 인코딩이라는 단어를 접할 수 있다. 그냥 인코딩 방식을 utf-8로 변경하면 대부분의 문제가 해결되지만, 이유도 모르고 사용하는 건 굉장히 찝찝한 일이다. 진정한 웹 개발자라면 재미없고 어려워보인다는 이유로 인코딩 공부를 미뤄서는 안된다. 이번에 이유를 확실하게 알아가보자!
https://www.youtube.com/watch?v=6hvJr0-adtg&t=809s
인코딩 관련해 싹 정리해준 너무 좋은 유튜브 영상이 있어서 링크를 첨부한다. 널널한 개발자님은 많은 설명을 덧붙여서 개념을 정리해주시는데, 인코딩 영상도 보면서 너무 감동을 받았다. 조금 영상이 길지만 최고의 정리 영상이라고 생각한다.
문자표의 필요성
컴퓨터는 모든 정보를 0과 1로 표현한다. 데이터를 저장할 때도, 웹을 통해 전송할 때도 모든 것은 0과 1로 표현된다. 문자열도 마찬가지로 0과 1로 표현을 해야한다. 그래서 문자를 이진수에 대응하는 문자표가 등장하였다.
예를 들어, 문자표의 대표적인 예시인 ASCII코드에서는 A의 경우 65로 대응시키고, a은 97에 대응시키는 식으로 문자를 표현한다.
ASCII
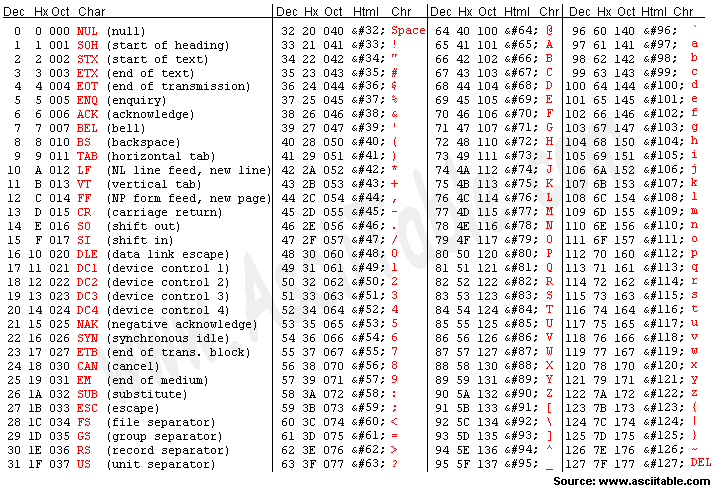
ASCII(American Standard Code for Information Interchange)코드는 가장 널리 사용된 초기 표준 문자체계이다. 1963년 미국 ANSI에서 표준화한 정보 교환용 7비트 부호 체계로, 오늘날 문자 인코딩의 근간을 이루게 된다.
ASCII코드 표는 7bit가 만들어낼 수 있는 이진수 조합을 문자와 대응한 표이다. 사진을 보면 2^7개의 영문자 및 제어문자가 숫자로 매핑되어있는 것을 볼 수 있다.
+) 8비트 중에서도 7비트만 쓰도록 제정된 이유는, 나머지 1비트는 통신 에러 검출을 위한 패리티비트로 사용하기 위해서이다.
아스키 코드표의 문제
영어 알파벳을 표현하기 위해서 7비트면 충분하지만, 세계 각국의 문자들을 모두 표현하기에는 7비트로는 부족하다. 한국어만 생각해도 개수가 1000개가 넘고, 한자는 10만개가 넘는다.
그래서 인터넷을 이용하는 국가들은 자신들의 문자체계에 맞는 문자표를 만들게 된다. 한국도 할글 표기를 위한 한글 코드체계를 만들게 되었다.
한글의 문자표
한글은 자음과 모음이 결합된 글자로 이루어져있다. 그래서 저장을 할 때 두 가지 방법으로 저장할 수 있다. 첫 번째는 자음과 모음에 대한 코드를 정의하고 이를 조합하는 방법(조합형)이고, 두 번째는 하나의 글자 자체를 코드에 대응하는 방법(완성형)이다.
두 방법에 대한 논쟁이 있었지만, 결국 완성형으로 통합하기로 결정이 났다.
unicode의 등장
전세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계한 산업 표준
아스키코드로는 영문자외에 다른 국가들의 문자를 표현할 수 없다고 했었다. 그래서 각국의 문자를 모두 담을 수 있는 체계인 unicode가 만들어진다. unicode는 현존하는 문자열 셋을 모두 유니코드로 교체하는 것을 목적으로 하여 만들어졌다.
초기 unicode는 글자 하나를 16비트로 표현하여 65536가지의 글자를 표현하였다. 하지만 모든 문자를 넣기에 부족하다는 사실이 밝혀졌고, 공간을 4바이트로 늘리면서 세상의 모든 문자를 할당할 수 있게 되었다.
+) unicode가 16비트로 문자를 표현한다고 알고있었는데, 옛날이야기라고 한다.
유니코드는 공식적으로 31비트 문자 집합이지만 2024년 9월 12일 기준 11,172개가 존재하므로, 현재까지는 21비트 이내로 모두 표현이 가능하다. 유니코드는 논리적으로 평면(plane)이라는 개념을 이용하여 구획을 나누며, 평면 개수는 0번 평면인 기본 다국어 평면(BMP)에서 16번 평면까지 모두 17개이다.
- 대부분의 문자는
U+0000~U+FFFF범위에 있는 BMP에 속하며, - 일부 한자는 보조 다국어 평면(SMP, Supplementary Multilingual Plane)인
U+10000~U+1FFFF범위에 속한다. - 이 중 한글은
U+1100~U+11FF사이에 한글 자모 영역,U+AC00~U+D7AF사이의 한글 소리 마디 영역에 포함된다
unicode.org 사이트에 들어가면 코드차트를 확인할 수 있다.
유니코드는 다양한 문자 집합들을 통합하는 데 성공하면서 컴퓨터 소프트웨어의 국제화, 지역화에 널리 사용되게 된다.
인코딩
문자는 unicode에 대응시킬 수 있는데, 이를 저장할 자릿수를 얼마나 할당하느냐에 따라 표현방식이 달라진다. 이렇게 한 문자를 표현하는 방식을 인코딩이라고 한다.
예를 들이, A는 1000001이라는 유니코드에 대응된다. 이제 이 이진수를 표현할 비트수를 지정할 수 있다. 단순히 7비트 1000001로 표현할 수도 있고, 8비트로 01000001로 표현하거나 16비트 00000000 01000001 로도 표현도 가능하다. 비트 수가 늘어날 수록 표현할 수 있는 문자도 다양해질 수 있다.
EUC-KR의 경우, 완성형 한글 표를 읽는 8비트 인코딩 방식이고, 이후 MS사에서 EUC-KR의 확장형인 CP949라는 인코딩 방식을 정의하였다. unicode의 경우에는 2가지의 인코딩 방식이 존재한다.
- 유니코드 변환 방식(Unicode Transformation Format, UTF) 인코딩
- 국제 문자 세트(Universal Coded Character Set, UCS) 인코딩
유니코드 변환 방식 인코딩 방식은 다음과 같은 것들이 있다.
- UCS-2
- UCS-4
- UTF-32
- UTF-16
- UTF-8
UCS-2
UCS-2는 유니코드를 이용하여
16비트 고정폭으로 문자를 표현하는 인코딩방식
UCS-2를 사용하면 2^16가지, 즉 65536가지의 문자 표현이 가능하다.
하지만 전세계 문자를 담기에는 한계가 있었고, 그렇다고 32비트로 문자 하나를 표현하는 건 너무 낭비가 심했다. 그래서 UTF-16이 등장하게 된다.
UTF-16
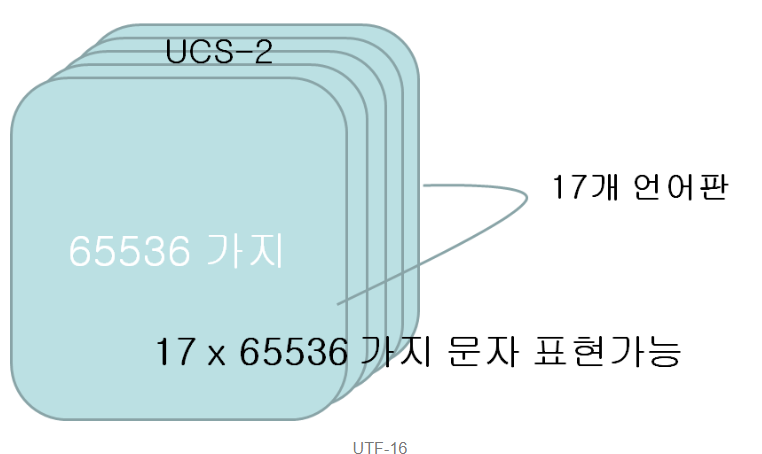
UTF-16은 문자표가 수용하지 못하는 문자를 수용하되, 16비트를 유지하기 위해 언어판을 늘리도록 시도한다. UTF-16은 언어판을 17개까지 늘려 17 * 65536가지의 문자가 표현이 가능하다.
사진에서 가장 맨 앞에 있는 언어판은 가장 자주 사용되는 기본 언어판인 BMP이다. BMP에는 한글도 포함되며, BMP에 있는 문자들은 16비트로 표현이 가능하다.
하지만 BMP에 없는 문자의 경우에는 다른 언어판에서 찾아야하고, 다른 언어판을 가리키는 메타데이터도 함께 포함되어야한다. 그래서 데이터 길이를 32비트로 표현한다.
즉, BMP에 속한 기본 문자들은 UCS-2 문자표를 활용하여 16bit로 표현하고, 그 외 문자는 32비트으로 표현하는 것이 UTF-16 인코딩 방식이다.
Big-endian과 Little-endian
utf-16의 경우 Big-endian으로 표현할 것인지, Little-endian으로 표현할 것인지 지정해줘야한다.
- Big-endian(BE): 높은 자릿수부터 메모리에 저장하는 방식
- Little-endian(LE): 낮은 자릿수부터 메모리에 저장하는 방식. windows 같은 pc들이 Little-endian을 사용한다.
+) 또한 UTF-16은 문서 시작에 BOM(Byte Order Mark)을 추가하여 인코딩 방식을 표시할 수 있다.
- Big Endian:
FE FF - Little Endian:
FF FE
utf-16의 단점
하지만 UTF-16은 영어와 숫자 표현하는데도 16비트를 사용한다. ASCII를 사용하여 1바이트로 충분히 표현이 가능한데, 굳이 2바이트나 써야한다. 게다가 컴퓨터에서 사용되는 대부분의 언어는 영어와 숫자이므로, 이는 공간의 비효율을 초래할 수 있다. 그래서 이를 보완하기 위한 UTF-8이 등장하게 된다!
utf-8
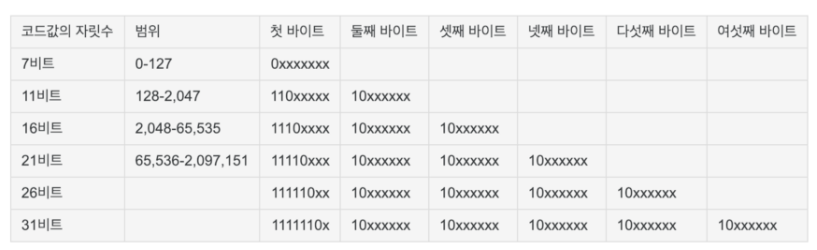
utf-8은 ucs-2 문자표를 토대로 데이터를 재가공하여 UTF-16의 한계를 보완하였다. 각 문자를 1~4바이트로 표현이 가능하며, ASCII와 역호환이 가능하다.
utf-8의 특징은 영문의 경우 1바이트 ASCII로 표현하고, 다른 문자의 경우 3바이트로 표현하는 것이다.
- 7bit로 표현가능한 문자(영어, 숫자 등)를
7bit로 표현 - 나머지 문자는
8비트+a로 가변적으로 변함
UTF-8의 가변 길이 특성은 다음과 같다.
- 1바이트: ASCII 문자 (0x00-0x7F)
- 2바이트: 대부분의 라틴 문자 및 키릴 문자
- 3바이트: 한글을 포함한 대부분의 현대 문자
- 4바이트: 이모지 등의 특수 문자
utf-8의 인코딩 방식 예시
예를 들어, 강아지123라는 문자를 표현하고자 한다.
- unicode 표에서
강(AC15),아(C544),지(C9C0),1(31),2(32),3(33)글자를 찾음 - 유니코드를 utf8로 인코딩한다(표를 참고)
강의 경우 다음과 같이 인코딩된다234, 176, 149 - 각 숫자를 16진수로 표현한다. 강의 경우
EA, B0, 95으로 표현된다 - 그대로 나열한다
EAB095 EC9584 ECA780 31 32 33
이 예시에서 숫자(1,2,3)와 한글은 표시되는 개수가 다른 걸 확인할 수 있다. 한글의 경우 3바이트, 숫자의 경우 1바이트로 표현한다. 영문자도 숫자와 같이 1바이트로 표현된다.
utf-8은 코드의 범위를 보고 아스키일 경우 1바이트로 표현하고, 아스키가 아니라면 코드페이지 규정에 따라 다른 글자로 해석하고 3바이트로 표현한다.
한글은 UTF-16에서 2byte지만 UTF-8에서는 3byte를 차지한다. 그렇기 때문에 아스키코드 내의 문자가 주로 사용되면 UTF-8인코딩 방식이 유리하고, 반면 아스키 벗어나는 문자 사용 시 UTF-16이 유리하다는 걸 알 수 있다.
+) utf-8 BOM
utf-8임을 확실히하기 위해 문서 앞머리에 BOM(byte order mark?)을 달아주는 인코딩 방식이다.
EF BB BF (이후 utf-8문서...)이런식으로 문서 앞머리에 BOM 표시를 살짝 한다.
utf-8로의 통일
utf-8은 기존의 HTML 태그나 자바스크립트 등 아스키로 구축된 사이트를 별다른 변환 처리 없이 그대로 쓸 수 있는 엄청난 장점이 존재했다. 또한 utf-16과 달리 앤디안에 상관없이 똑같이 읽는 단일 인코딩 방식이었기 때문에 크로스플랫폼 호환성도 뛰어났다.
그래서 세계적으로 utf-8 인코딩이 가장 널리 쓰이게 되었다.
url 인코딩
웹사이트 주소 뒤에 URL 파라미터를 넣어 서버에 인자를 보낼 때 url 인코딩이 발생한다.
URL에는 아스키 코드의 문자 집합만 사용할 수 있게 되어있어서 스페이스나 한글을 포함한 문자열을 약속된 방식의 아스키로 치환해서 서버에 전송하도록 하는 방식을 url 인코딩이라고 부른다. 그리고 url인코딩은 기본적으로 utf-8방식을 사용한다.
마치며..
인코딩과 관련해서 어느정도의 정리가 된 것 같다. BASE64나 JVM에서 utf-16을 사용하는 이유 등 궁금한 점이 더 있어서 찾아보고 공부해보려고 한다.
참고자료
나무위키 아스키코드 표


1학기 강사님이랑 이걸로 점심시간 20분동안 붙잡고 얘기했는데 기억이 새록새록하네요
인코딩이랑 디코딩되는 과정도 재밌었던 걸로 기억해요