컴퓨터가 내부에서 CPU와 메모리를 어떻게 사용하는지 알아야 쉽게 포인터를 이해할 수 있을 거라 생각한다. 그렇다면 스택과 힙을 이해해보자.
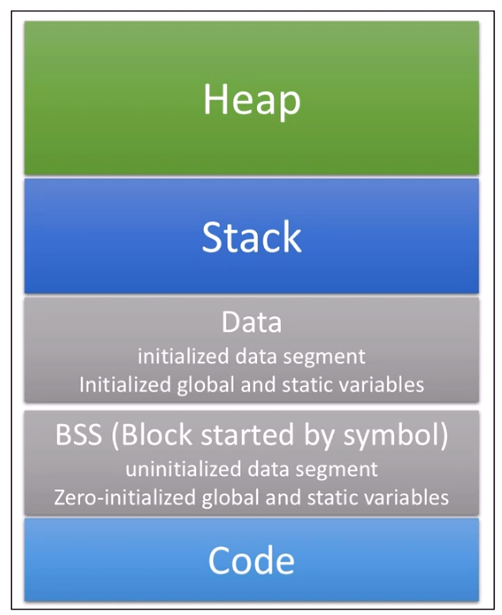
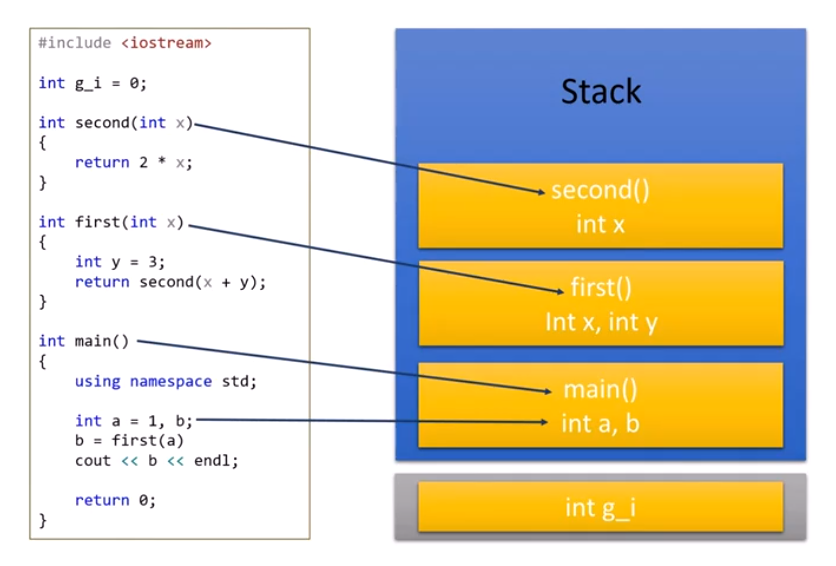 기본적으로 우리가 stack에 데이터가 쌓이는 구조를 보면 다음과 같다. 전역변수가 이미 DATA 구간에 정보를 먼저 저장이 되고 그 뒤로 stack에 main문부터 시작해서 차례대로 쌓여가는 것을 볼 수 있다. 이렇게 다 실행이 되면 맨 윗부분 부터 저장한 것을 없애기 시작한다. 왜 그럴까? 그걸 쉽게 이해하기 위해서 회전초밥집을 예로 들면 이해하기 쉽다.
기본적으로 우리가 stack에 데이터가 쌓이는 구조를 보면 다음과 같다. 전역변수가 이미 DATA 구간에 정보를 먼저 저장이 되고 그 뒤로 stack에 main문부터 시작해서 차례대로 쌓여가는 것을 볼 수 있다. 이렇게 다 실행이 되면 맨 윗부분 부터 저장한 것을 없애기 시작한다. 왜 그럴까? 그걸 쉽게 이해하기 위해서 회전초밥집을 예로 들면 이해하기 쉽다.
우리가 회전초밥집에서 초밥을 먹고 차곡차곡 쌓아놓고 계산을 한다고 가정하자. 그럼 계산을 하기 위해 종업원은 위에서부터 정리하며 가격을 매긴다. 그런 느낌이라고 생각하면 좀더 다가올 것이다.
stack은 빠르게 움직이는 대신 단점이 있다. size가 작다는 점이다.
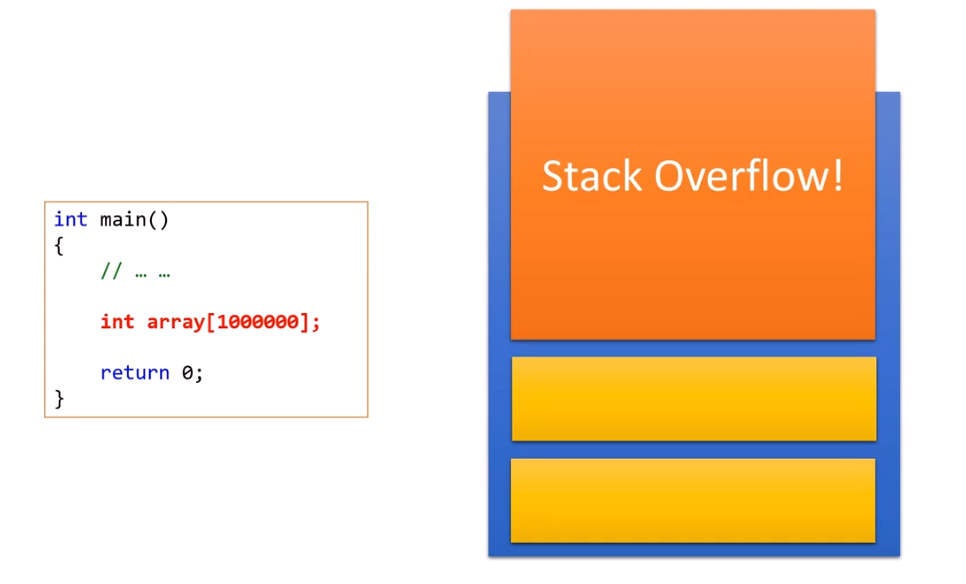 이 그림과 같이 stack을 넘어버려 overflow가 나는 경우가 있다. 재귀적 호출 같은 경우 stack overflow가 자주 일어나는데, 이는 뒷 부분에서 설명하겠다.
이 그림과 같이 stack을 넘어버려 overflow가 나는 경우가 있다. 재귀적 호출 같은 경우 stack overflow가 자주 일어나는데, 이는 뒷 부분에서 설명하겠다.
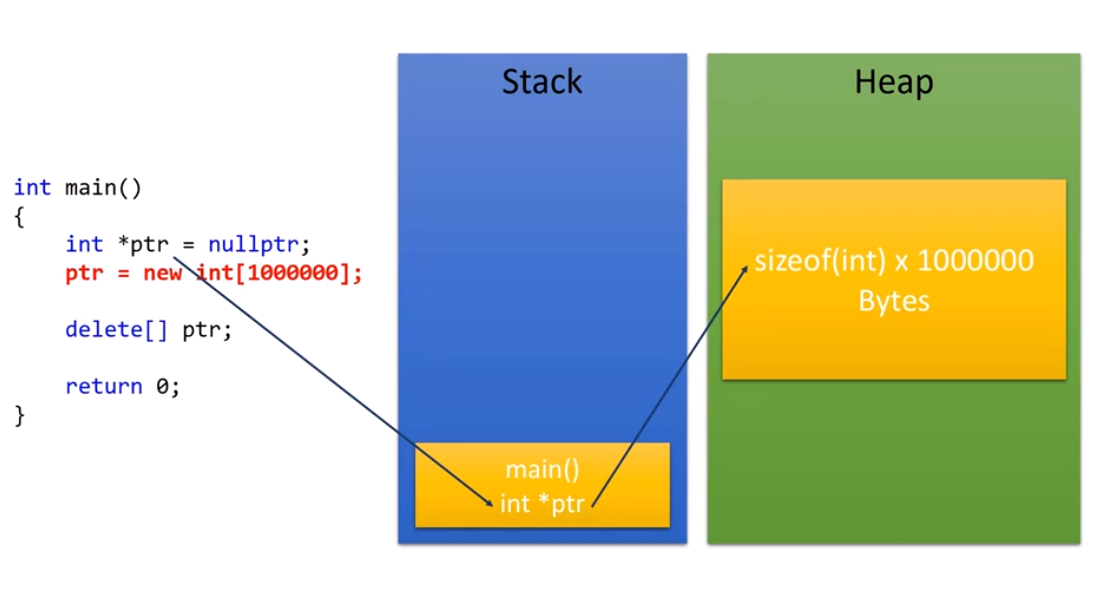 동적할당 new를 사용하면 Heap에 저장이 된다. Heap같은 경우에는 큰 데이터도 담을 수 있기 때문에 장점이지만, 어디에 저장되는지 모른다는 단점 또한 존재한다.그런데, 이처럼 코드를 작성하면 문제가 생긴다.
동적할당 new를 사용하면 Heap에 저장이 된다. Heap같은 경우에는 큰 데이터도 담을 수 있기 때문에 장점이지만, 어디에 저장되는지 모른다는 단점 또한 존재한다.그런데, 이처럼 코드를 작성하면 문제가 생긴다. 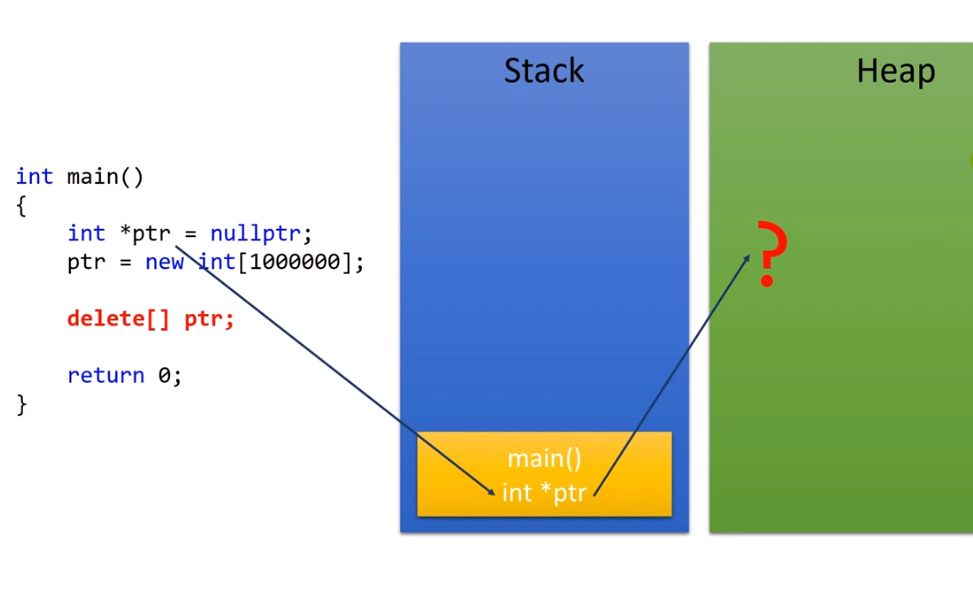 뭐 이렇게만 작성하면 딱히 문제가 생기진 않겠지만, 나중에 dereferencing을 사용하여 ptr을 참조하게 된다면 문제가 생길 것이다. 그 이유는 동적할당을 부여한다음 그 내용을 삭제 했지만, stack의 *ptr같은 경우는 값을 갖고 있는데, 그 안의 값이 무엇을 가리키고 있는지 모르는 상황이 발생하기 때문이다.
뭐 이렇게만 작성하면 딱히 문제가 생기진 않겠지만, 나중에 dereferencing을 사용하여 ptr을 참조하게 된다면 문제가 생길 것이다. 그 이유는 동적할당을 부여한다음 그 내용을 삭제 했지만, stack의 *ptr같은 경우는 값을 갖고 있는데, 그 안의 값이 무엇을 가리키고 있는지 모르는 상황이 발생하기 때문이다.
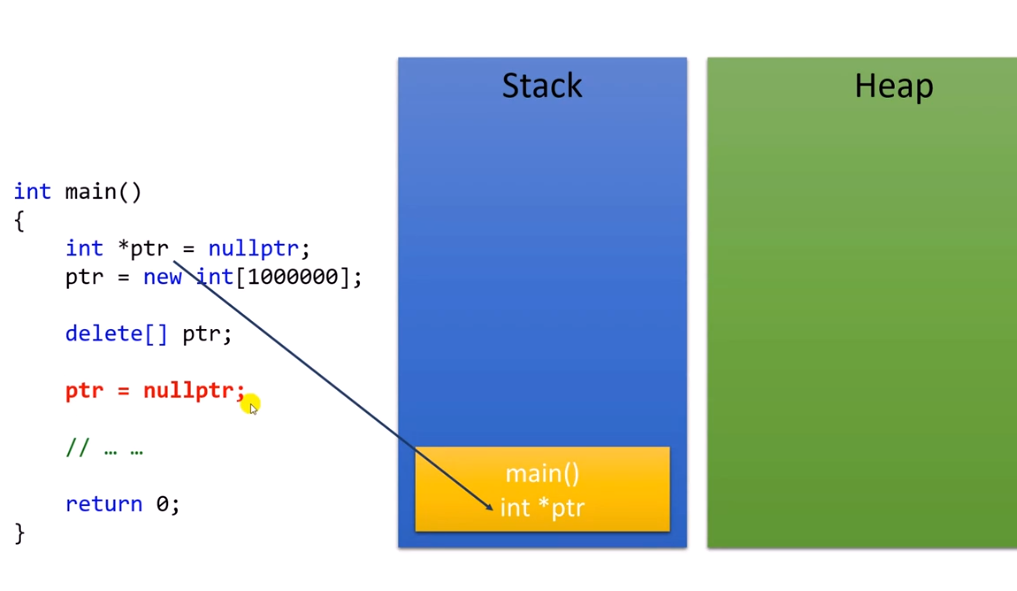 따라서 반드시 이와 같은 과정을 거쳐주자. 그래야 오류가 나지 않는다.
따라서 반드시 이와 같은 과정을 거쳐주자. 그래야 오류가 나지 않는다.
근데 우리가 항상 new를 사용할 때, delete를 꼭 써야 한다고 했는데, 왜 delete를 사용해야 하는걸까?
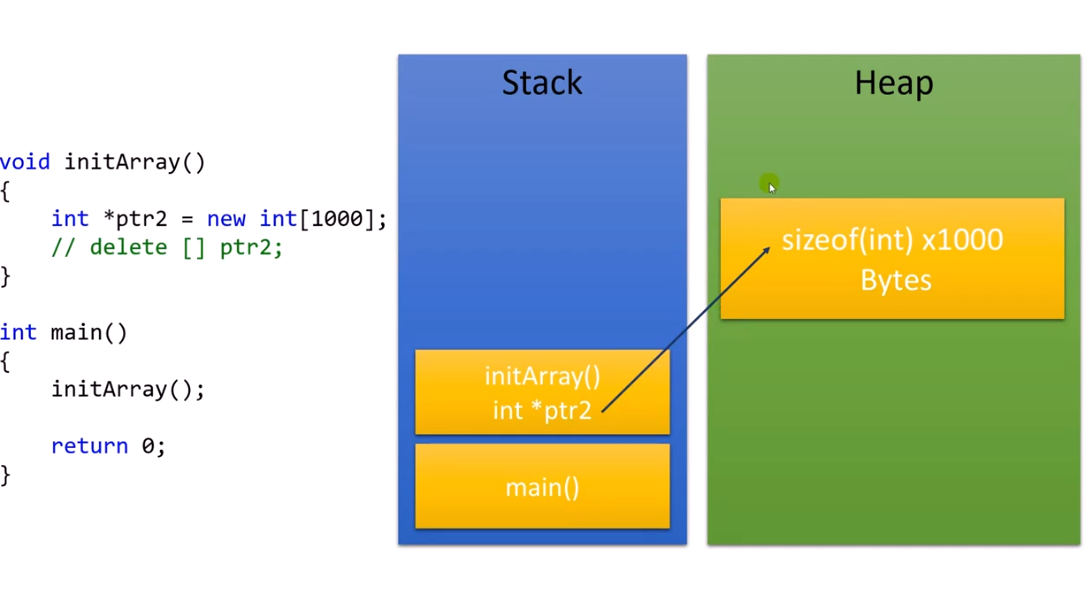 이런식으로 코드를 작성했다고 가정해보자. new를 사용하여 Heap에 동적할당으로 크기가 큰 데이터가 자리잡았는데, main문이 끝나게 되면
이런식으로 코드를 작성했다고 가정해보자. new를 사용하여 Heap에 동적할당으로 크기가 큰 데이터가 자리잡았는데, main문이 끝나게 되면 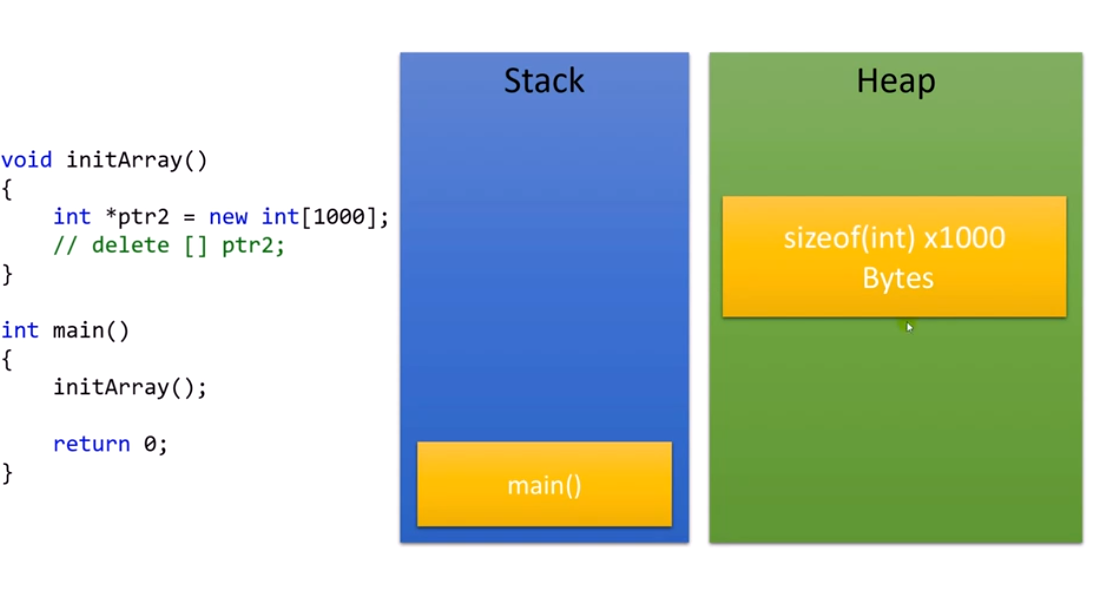 이와 같은 상황이 발생하는 것이다. 이러면 Heap에는 데이터가 잡혀있지만 접근할 수 없는 데이터가 되어 버리는 것이다. 이런 일이 반복이 되면 Heap같은 경우에는 메모리 누수가 발생하고 다른 프로그램이 사용할 메모리를 침범하는 문제가 생기므로 이와 같은 상황은 절대 만들면 안된다!
이와 같은 상황이 발생하는 것이다. 이러면 Heap에는 데이터가 잡혀있지만 접근할 수 없는 데이터가 되어 버리는 것이다. 이런 일이 반복이 되면 Heap같은 경우에는 메모리 누수가 발생하고 다른 프로그램이 사용할 메모리를 침범하는 문제가 생기므로 이와 같은 상황은 절대 만들면 안된다!
