동적할당 메모리를 직접 관리하는 것보다 std::vector를 사용하는 것이 훨씬 간편하다.
우리가 동적할당을 할때, new와 delete를 사용하여 구현을 하였는데, std::vector로 구현을 해보자는 것이다. 하지만, 우리가 vector을 사용할때 생각하며 구현을 해야하는데, 그것은 바로 내부적으로 new와 delete를 적게 사용하도록 해야 한다는 것이다.
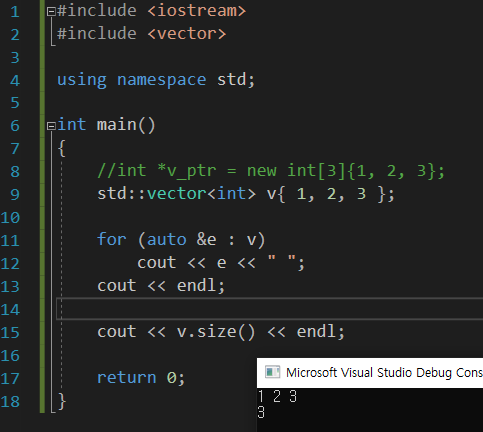 저번에 배웠지만 for - each문을 사용하기 위해서는 배열은 사용할 수 없다고 하였으나 그의 대체용으로 vector는 가능하다고 하였다. 이참에 제대로 이해하자.
저번에 배웠지만 for - each문을 사용하기 위해서는 배열은 사용할 수 없다고 하였으나 그의 대체용으로 vector는 가능하다고 하였다. 이참에 제대로 이해하자.
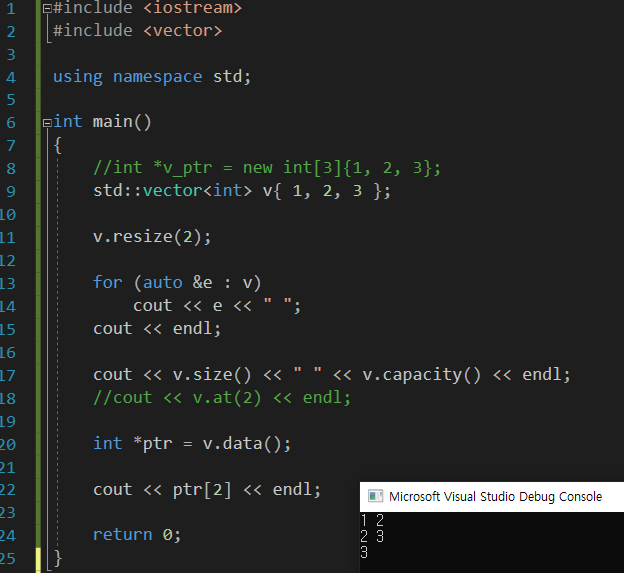
이 v.size()와 v.capacity()는 조금 다른 성격을 갖는다. v.size()의 경우에는 현재 사용할 데이터의 크기를 나타내고, v.capacity()는 v가 갖고 있는 전체 데이터의 크기를 말한다.
코드를 보면 2의 크기로 resize를 하는데, 꾸역꾸역 출력을 해보면 resize를 해도 정보를 삭제하는 것이 아니라 갖고 있는데, 내보내지 않는 것 뿐이다.
vector를 stack처럼 사용하는 방법에 대해 알아보자.
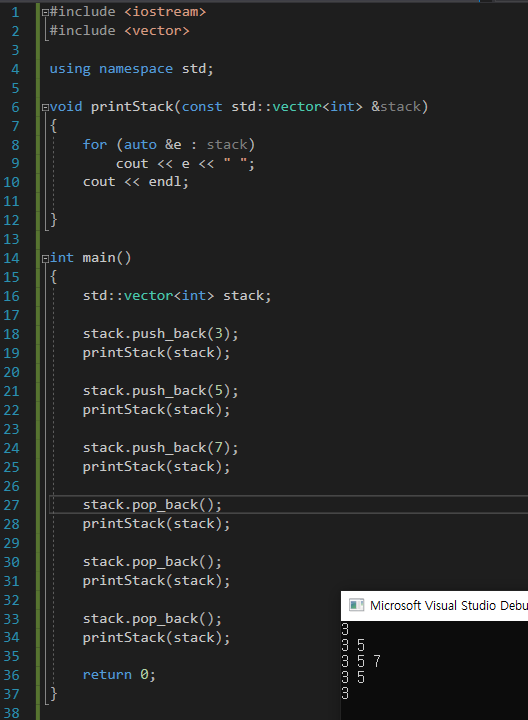 우리가 stack에 대해 배웠을 때, 처음들어온 것이 맨 마지막에 사라지고 마지막에 들어온 것이 처음부터 사라지는 것으로 배웠는데, 실제로 vector을 사용하여 출력을 해보면 다음과 같은 출력이 나오게 된다.
우리가 stack에 대해 배웠을 때, 처음들어온 것이 맨 마지막에 사라지고 마지막에 들어온 것이 처음부터 사라지는 것으로 배웠는데, 실제로 vector을 사용하여 출력을 해보면 다음과 같은 출력이 나오게 된다.
근데 왜 하필 vector로 stack을 구현을 해야하는가? 에 대한 의문이 들 수 있다.
vector에서 reserve를 하게 되면 push_back을 할때 capcity를 늘릴 필요가 없어서 new하고 delete를 호출할 필요가 없다.
하지만 단점은 reserve를 너무 크게 하면 낭비가 될 수 있지만, 요즘은 메모리가 커서 상관은 없을 듯 싶다. 빅데이터를 다룬다는 점을 제외하면 말이다.
