Kaggle : https://www.kaggle.com/
1. Kaggle 사용법
Kaggle은 대회로 아는 사람도 있고 dataset을 모아두는 사이트로 알아두는 사람들도 많다. 우선 kaggle로 Dataset을 사용하는 방법부터 알아보자.
 kaggle을 처음 들어가면 위의 그림과 같은 화면이 나온다. 로그인이 되어있지않다면 오른쪽 상단에 나와 같은 그림이 나와있지 않을텐데, 로그인을 해주길 바란다.
kaggle을 처음 들어가면 위의 그림과 같은 화면이 나온다. 로그인이 되어있지않다면 오른쪽 상단에 나와 같은 그림이 나와있지 않을텐데, 로그인을 해주길 바란다.
검색창에 london bike sharing dataset이라고 입력하자.
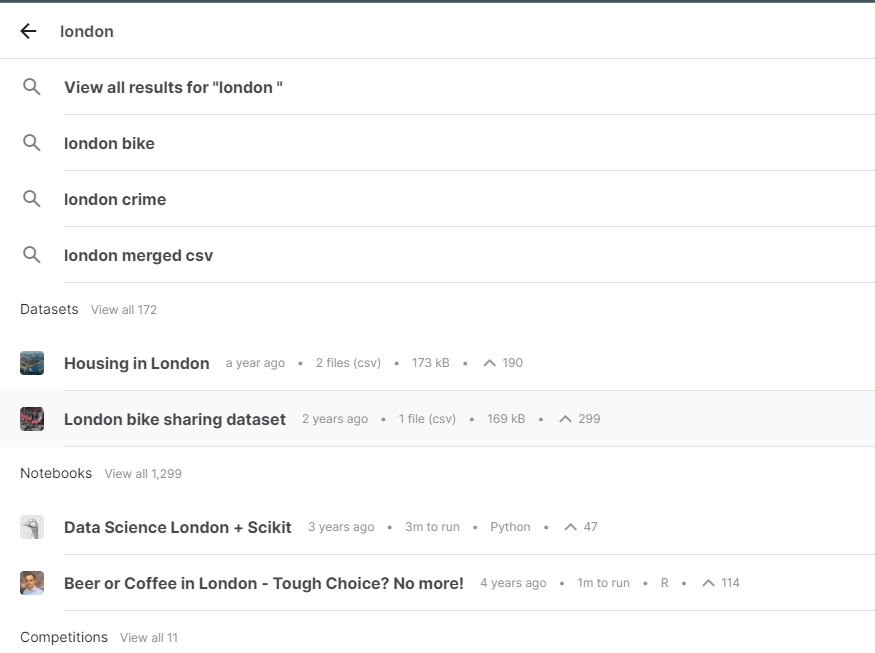 클릭한다.
클릭한다.
2. Kaggle dataset 불러오기
kaggle안에 kernel을 이용하여 notebook을 만드는 사람이 있는데, 나는 코랩을 이용하여 코드를 작성하려고 한다. 코랩 사용방법과 import os를 사용하여 적절한 공간에 dataset을 두고 작성하도록 한다. 방법은 아래의 그림을 참고한다.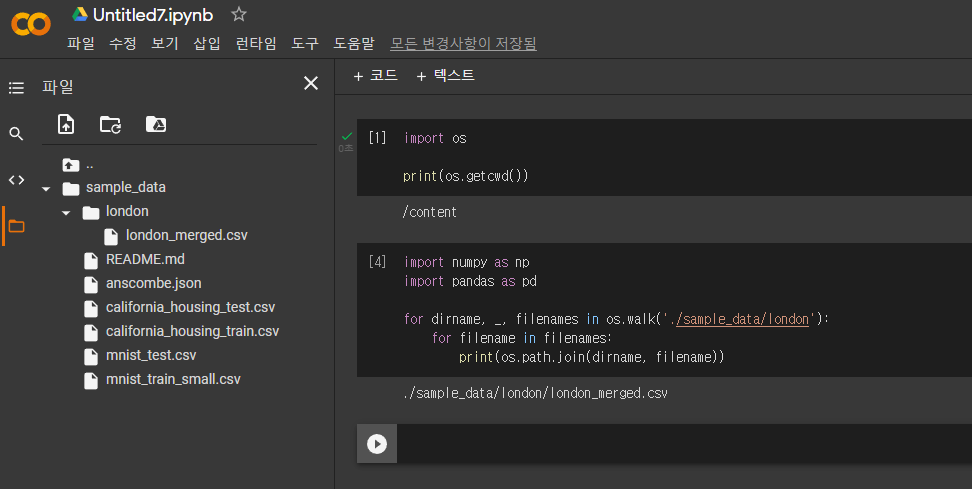 설명을 하자면,
설명을 하자면, import os를 사용하여 기본 경로가 어딘지 파악한다. 그 후에 적절한 장소에 파일을 만들고 그 파일안에 csv파일을 넣어두면 된다.
3. Kaggle dataset을 사용하기
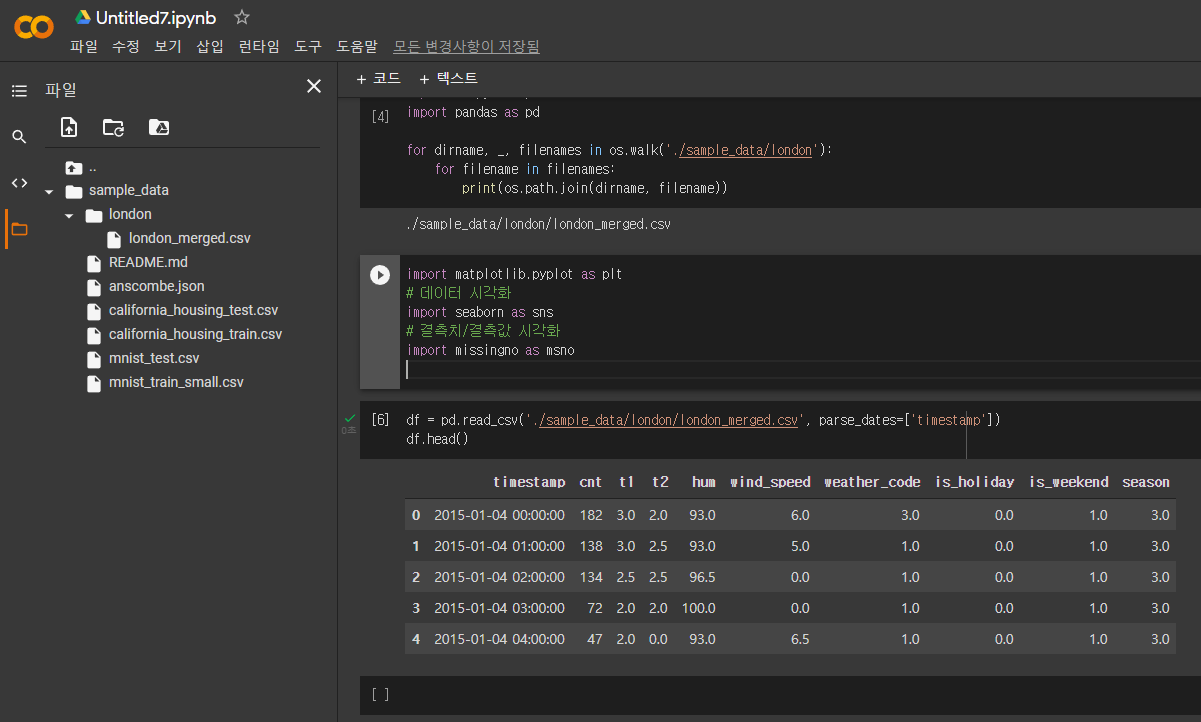 자 그럼 분석을 해보자.
자 그럼 분석을 해보자.
df = pd.read_csv('./sample_data/london/london_merged.csv', parse_dates = ['timestamp'])의 역할은 무엇인가? 뭐 다들 알다시피 pd.read_csv()는 csv파일을 pandas로 읽어들일때 사용한다. 이 함수의 매개변수인 parse_dates의 역할은 무엇일까?
parse_dates
어떤 유형의 데이터 타입은 계산하기 어려운데 이를 계산할 수 있는 데이터 타입으로 변환해준다.
아래의 예시를 보며 이해해 보자.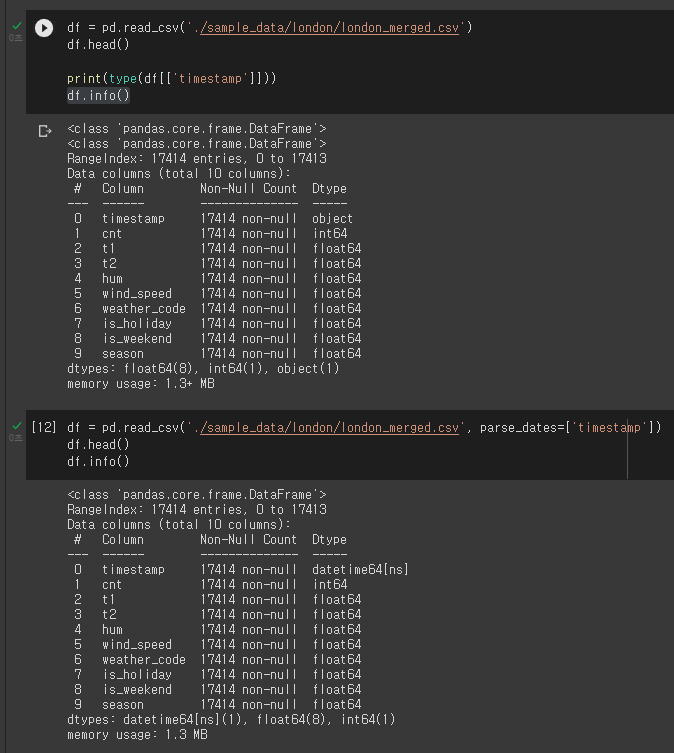 띠용... 이건 뭐지라고 생각할지도 몰라. 하지만 자세히 봐보자.
띠용... 이건 뭐지라고 생각할지도 몰라. 하지만 자세히 봐보자. timestamp의 Dtype가 달라진 것을 볼 수 있다. 위의 code는 parse_date를 사용하지 않은 것이고 아래의 code는 parse_date를 사용한 것이다.
근데 왜 굳이 이렇게 Dtype를 바꿔야 하는가에 대한 의문이 남을 수 있다. object형식으로 되어 있을 경우, 시간의 차이를 계산하고 싶을 때 번거로울 수 있다. 하지만, datatime으로 Dtype가 설정되면 시간 계산에 엄청난 이점이 있을 수 있다. user가 어떤 dataset을 두고 어떤 식으로 사용하느냐에 따라 안사용할 수도 있지만, 그 용도에 맞게 잘 설정하여 작성하도록 한다.
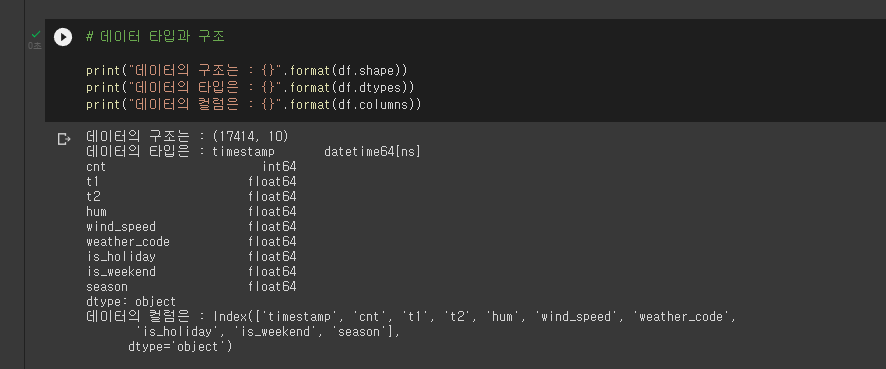 데이터를 다루기 전에 가장 중요한 것은 우선 이 데이터가 어떻게 구성되어 있는지 파악하는 것이 중요하다. 데이터 타입같은 경우에는
데이터를 다루기 전에 가장 중요한 것은 우선 이 데이터가 어떻게 구성되어 있는지 파악하는 것이 중요하다. 데이터 타입같은 경우에는 df.info()를 통해 잠시나마 파악할 수 있긴 하지만, print()를 사용하여 출력하는 경우도 있느니 확인바란다.
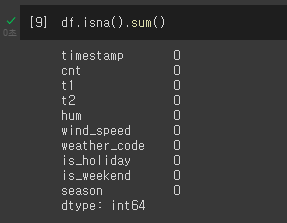 이건 또 무엇이냐 하면 결측치가 있냐 없냐를 판단하는 것이다.
이건 또 무엇이냐 하면 결측치가 있냐 없냐를 판단하는 것이다.
결측치
사전적 정의를 보면 데이터에 값이 없는 것을 뜻한다.
import missingno as msno를 사용한 이유가 이에 해당한다. dataset을 보면 데이터에 값이 없는 경우가 종종 발생한다. 따라서 이를 사용하여 data의 유무를 파악하는 것도 중요하다.
 이 결측치를 matplot을 이용해 보고 싶으면 위의 코드와 같이 작성하면 된다. 만약 결측값이 존재한다면 하얀색으로 표시가 된다. 지금은 아무것도 없어 검은색으로만 표시가 되고 있다.
이 결측치를 matplot을 이용해 보고 싶으면 위의 코드와 같이 작성하면 된다. 만약 결측값이 존재한다면 하얀색으로 표시가 된다. 지금은 아무것도 없어 검은색으로만 표시가 되고 있다.
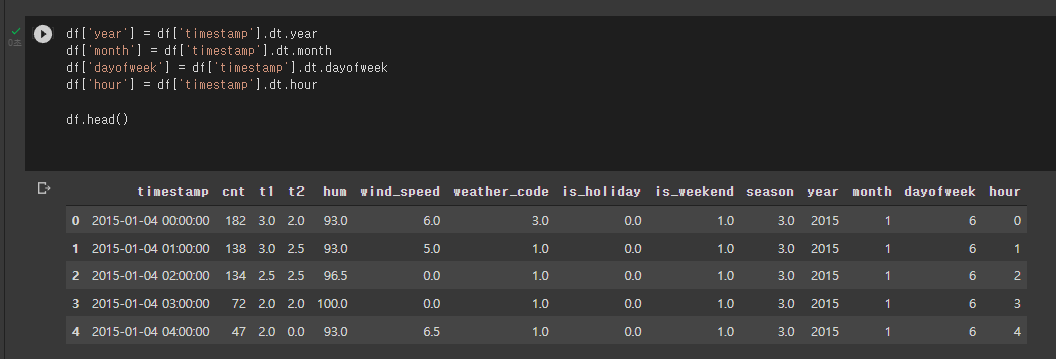 또한, timestamp에서 원하는 값들을 새로운 열을 만들어 값을 가져올 수도 있다. 우리가 원하는 데이터들을 분리하여 만들어 사용하는 것도 데이터 전처리 과정의 예이니 잘 알아두길 바란다.
또한, timestamp에서 원하는 값들을 새로운 열을 만들어 값을 가져올 수도 있다. 우리가 원하는 데이터들을 분리하여 만들어 사용하는 것도 데이터 전처리 과정의 예이니 잘 알아두길 바란다.
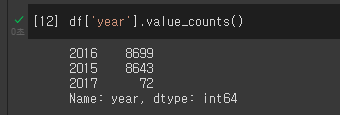 새로 만들어진 데이터가 몇 개를 갖고 있는지 확인할 때에는
새로 만들어진 데이터가 몇 개를 갖고 있는지 확인할 때에는 value_counts()를 사용하여 확인하는 방법도 있다.
오늘은 여기까지 해보려고 한다. 다음에는 그래프를 통해서 탐색적 분석을 해보자^_^
