ADAS를 구현하기에 앞서 필요한 내용들이 있다.
object detection, Face Detection, Face landmark, Face Recognition 등등 알아야할 내용이 정말 많다.차량의 경우 2-stage보단 1-stage를 많이 사용할 수 밖에 없고, 그렇다보니 yolo 형식이 많이 채택되고 있는 것으로 알고 있다.
오늘은 Face landmark인 PFLD 논문에 사용된 MobileNet v2의 기원인 MobileNet v1에 대해서 설명해보려고한다.MobileNet v1의 경우 상세히 설명한 내용이 정말 많기 때문에, 해당 내용은 아래의 링크에서 이해하면 좋을 것 같다.
https://velog.io/@pre_f_86/MobileNet-V1-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0#pytorch
https://greeksharifa.github.io/computer%20vision/2022/02/01/MobileNetV1/
MobileNet에서 가장 중요한 것은 Depthwise Convolution이다. 기존의 Convolution은 하나의 kernel이 모든 채널을 순회하면서 계산을 한다.

위의 이미지처럼 하나의 채널에 같은 kernel이 계속 계산되고 다음 채널에도 같은 kernel을 사용하여 출력하게 되는데, 이렇다 보니 기존의 CNN의 Flops(연산량)은 어마어마하게 늘어나게 된다.
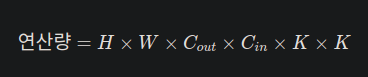
일반적인 Convolution은 위와 같은 연산량을 가지는데, output 채널에도 영향이 미치게 되므로 output channel이 배수로 늘어날수록 연산량도 기하급수적으로 늘어나게 된다.
따라서 Depthwise Convolution이 이러한 문제를 해결하는데 많은 도움을 줬다.
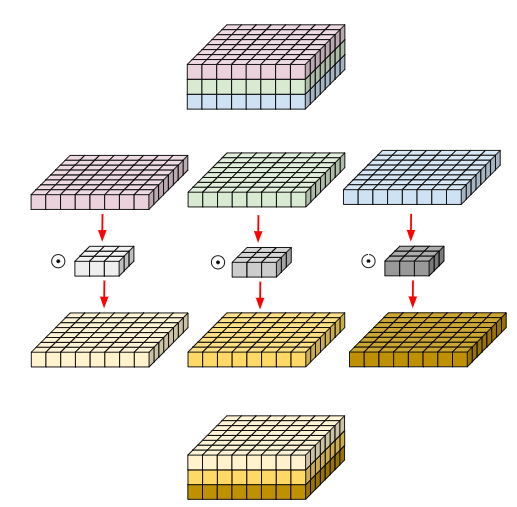
Depthwise의 핵심 내용은 입력 채널에 각각 kernel을 부여하여 연산량을 줄이는데에 있다. 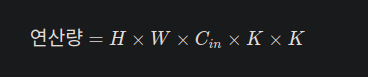
Cout이 곱해지지 않으니 연산량은 더욱 줄어들게 된다. 또한 공간이라는 정보에 특화되어 있다.
Depthwise의 핵심은 공간 정보에 매우 특화되어 있다는 것이다!!
공간 정보란 채널의 가로, 세로에 담긴 정보이다.
기존의 convolution에는 여러 개의 채널에 하나의 kernel만 사용하게 되고 가중합을 통해 하나의 출력맵을 나타나게 되는데, 이렇게 되면 각 채널이 담는 정보가 뒤섞이고 뒤섞여 원래 기존 채널이 갖고 있던 정보가 사라지거나 그 채널만이 갖고 있던 정보가 무시될 가능성도 생기게 된다.
하지만 각 채널마다 각각 kernel을 부여하고 각 채널마다 독립적으로 학습할 수 있다면 어떻게 될까? 그렇게 되면 R,G,B 채널은 각각 그들에게 특화된 feature를 뽑아내기 수월해질 가능성이 높아진다.
Depthwise를 진행하고 PointWise를 통해 깊이 즉, 채널에 대한 정보도 강화한다.
각 공간정보를 하나씩 뽑아낸 다음 논문에 설명한 Pointwise convolution을 사용하면 깊이축 즉, 채널에 대한 정보도 가져올 수 있게된다.여기서 말하는 Pointwise는 1*1 Convolution인데, Depthwise로 나온 출력 채널에 1x1 kernel이 순회하면서 R,G,B의 모든 특성을 갖는 최적의 feature를 빼오게 되는 과정을 수행한다.
따라서 MobileNet은 적은양의 연산량으로 높은 성능을 이끌었다는데에 의의가 있다.
Pytorch로 구현한 MobileNet은 다음과 같다.
# mobilenetV1.yaml
# MobileNet V1 model architecture
# [num of out filter, kernel_size, stride]
model_architecture : [
[[32, 3, 1], [64, 1, 1]],
[[64, 3, 2], [128, 1, 1]],
[[128, 3, 1], [128, 1, 1]],
[[128, 3, 2], [256, 1, 1]],
[[256, 3, 1], [256, 1, 1]],
[[256, 3, 2], [512, 1, 1]],
[5, [512, 3, 1], [512, 1, 1]],
[[512, 3, 2], [1024, 1, 1]],
]
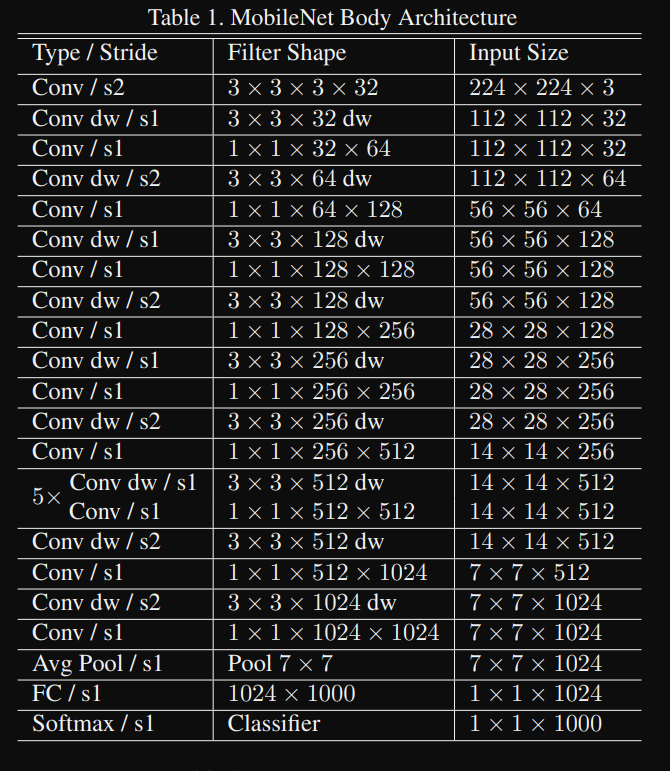
위의 yaml 파일은 MobileNetv1의 model architecture이다.
# Mobilenetv1.py
import os
import yaml
import torch
from torch import nn
from torchinfo import summary
# print(os.getcwd())
path = './landmark/config/mobilenetV1.yaml'
def load_model(path):
with open(path, 'r') as f:
config = yaml.safe_load(f)
model = config['model_architecture']
return model
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class DepthWiseBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.DW_conv = CNNBlock(in_channels,
out_channels,
kernel_size=3,
groups=in_channels,
padding=1,
)
def forward(self, x):
return self.DW_conv(x)
class PointWiseBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.PW_conv = CNNBlock(in_channels,
out_channels,
kernel_size=1,
stride=1,
padding=0,
)
def forward(self, x):
return self.PW_conv(x)
class MobileNetV1(nn.Module):
def __init__(self, in_channels, num_classes, **kwargs):
super().__init__()
self.architecture = load_model(path)
self.in_channels = 32
self.layers = self._create_block(self.architecture)
self.f_conv = nn.Conv2d(in_channels, 32, kernel_size=3, stride=2, padding=1)
self.bn = nn.BatchNorm2d(32)
self.act = nn.ReLU()
self.l_conv = nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0)
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.act(self.bn(self.f_conv(x)))
x = self.layers(x)
x = self.l_conv(x)
x = self.pool(x)
print("x.shape : ", x.shape) # (1, 1024, 1, 1)
x = x.view(x.size(0), -1)
print("x.shape : ", x.shape) # (1, 1024)
x = self.fc(x)
return x
def _create_block(self, architecture):
layers = []
in_channels = self.in_channels
for x in architecture:
if isinstance(x, list) and len(x) == 2:
layer1 = x[0]
layer2 = x[1]
layers += [
DepthWiseBlock(in_channels, layer1[0], kernel_size=layer1[1], stride=layer1[2]),
PointWiseBlock(layer1[0], layer2[0], kernel_size=layer2[1], stride=layer2[2]),
]
in_channels = layer2[0]
elif isinstance(x, list) and len(x) == 3:
num_repeat = x[0]
layer1 = x[1]
layer2 = x[2]
for _ in range(num_repeat):
layers += [
DepthWiseBlock(in_channels, layer1[0], kernel_size=layer1[1], stride=layer1[2]),
PointWiseBlock(layer1[0], layer2[0], kernel_size=layer2[1], stride=layer2[2])
]
in_channels = layer2[0]
return nn.Sequential(*layers)
a = torch.randn(1, 3, 224, 224)
model = MobileNetV1(in_channels=3, num_classes=1000)
print(model(a).shape)
