yolov4 model architecture에 대해서 설명하기에 앞서 우리는 CSPnet에 대한 충분한 이해를 하고 넘어가야 한다. 해당 네트워크에 대한 논문의 자세한 내용은 아래의 블로그에서 상세하게 설명을 해두었다.
https://dlgari33.tistory.com/9
CSPnet은 다음과 같은 network를 보인다.
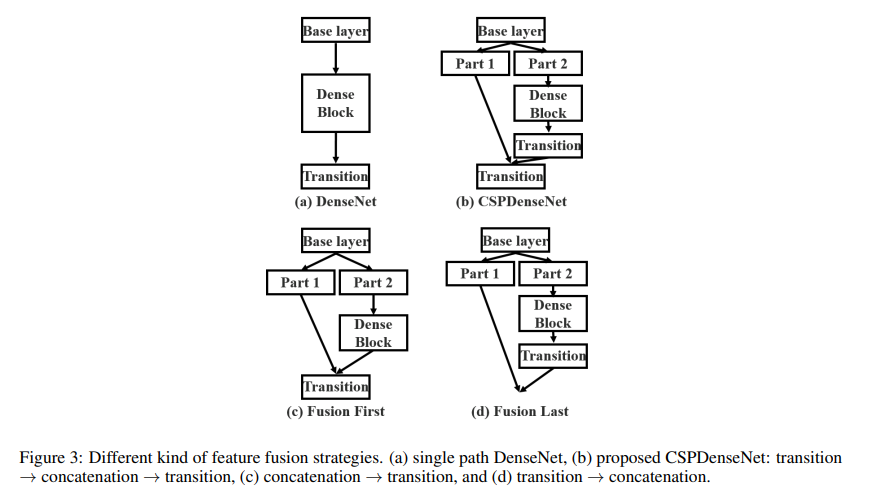
CSPnet의 사용 이유
- feature map 분할 및 병합
- 연산 효율성 향상
- 메모리 사용량 감소
- 경량화
- 다양한 아키텍처에 적용 가능
이 4가지에 대해서 하나씩 살펴보자.
1. Feature map 분할 및 병합
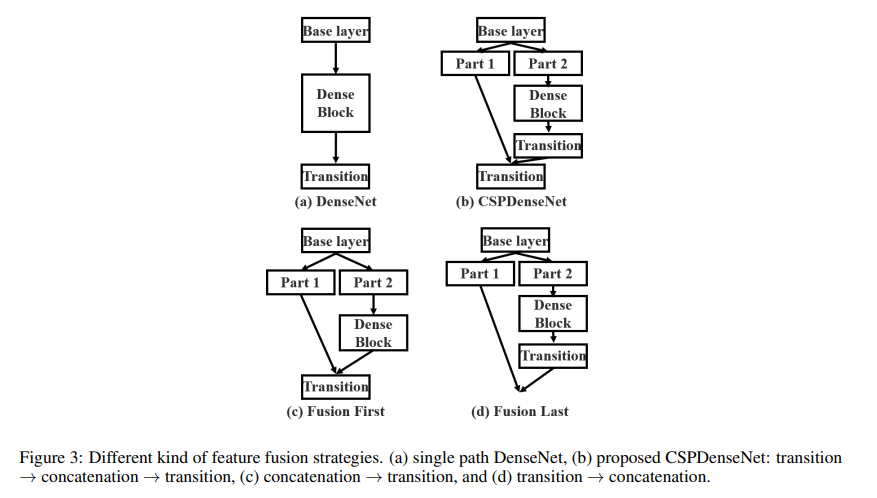
위의 이미지에서 보았듯이, CSPnet은 base layer의 featuer map을 두 부분으로 분할한다. part1은 그대로 두고 part2는 채널을 줄이고 채널을 다시 복귀하는 Bottleneck Layer를 사용하여 연산을 줄이며 더 많은 정보의 feature를 가져올 수 있도록 한다.
이렇게 하면 중복된 연산을 줄이고 중요한 특징을 그대로 보존할 수 있게 된다.
*여기서 말하는 중복된 연산이란?
-> CNN은 깊숙하게 layer을 설계할수록 중복된 연산이 반복되는 경향이 있다. 예를 들어, 하나의 layer에서 에지에 대한 feature를 추출했고 그 다음 layer가 texture에 대한 feature를 추출했다고 가정하자. 그 다음의 layer에서 똑같은 에지에 대한 feature를 추출하고 또 그 다음 layer가 texture를 추출한다면 어떻게 되는가? 물론, 이는 과장하긴 했지만 학습과정에서 충분히 일어날 수 있는 상황이다. 이 같은 과정이 계속 반복된다면 gradient는 어느 순간 local minimum에 빠질 가능성이 크다. 더 가파른 골짜기를 찾아가지 못하고 일반 골짜기에 빠져버리게 되는 것이다.
또한, 이런 반복적인 연산이 많아지면 학습에도 영향을 미치겠지만 불필요한 연산량과 메모리 사용량이 같이 늘어나게 되므로 되도록이면 중복된 연산은 피하는 것이 좋다.
2. 연산 효율성 향상
위에서 말했듯이 중복된 연산을 피함으로써 깊게 쌓지 않아도 깊게 쌓은 모델보다 성능이 좋게 나온다. 논문에서는 해당 구조를 통해 연산량을 약 20% 감소시키면서 더 나은 정확도를 이끌어냈다고 표현하고 있다.
3. 메모리 사용량 감소
PeleeNet에서는 메모리 사용량을 줄이기 위해 Cross-Channel Pooling 방식을 적용했다.
*Cross Channel Pooling이란?
-> cross channel pooling이란 채널 간의 특징을 결합하여 메모리 사용량을 줄이는 방법이다.
-> 각 채널이 독릭접으로 특징을 추출하고 여러 채널의 정보를 효율적으로 결합하여 필요한 채널 수를 줄이고 메모리 사용량을 감소시킨다.
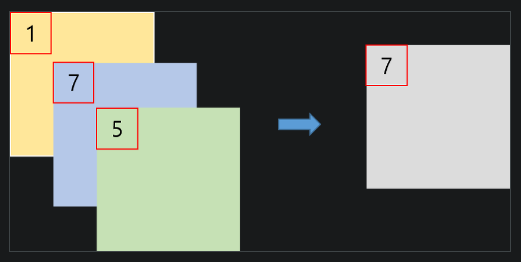 출처 : https://light-tree.tistory.com/147
출처 : https://light-tree.tistory.com/147
하지만 해당 방식은 가중치 학습으로 이뤄지는 방식도 아니고 채널 간 상호작용도 없다보니 성능 향상이라기 보단 메모리 감소에 초점을 둔 방식이다. 이보다 효율적인 방식은 1*1 convolution 방식이다.
1*1 convolution 방식은 학습된 가중치를 통해 채널 간의 상호 작용을 학습하여 정보 손실이 적고 더 복잡한 채널간 결합이 가능하다. 또한, 채널을 줄여 메모리 사용량 감소시킬 수도 있다.
CSPnet에서 cross channel pooling을 사용하지 않고 1*1convolution을 사용하여 메모리 사용량을 줄인 이유가 여기에 있는 것 같다.
-> 성능 향상, 메모리 사용량 감소
4. 경량화
최근 경량화는 중요한 task 중의 하나이다. on-device에서 사용하거나 아두이노 혹은 라즈베리파이, jetson과 같은 장비에서 돌리려면 해당 과정은 필연적이기 때문이다. 무거운 모델이 해당 장치에서 돌아갈 이유가 없기 때문에, 경량화를 해야하는데 기존 모델에서는 불가능했기 때문이다.
경량화는 주로 아래와 같은 과정이 일반적이다.
- channel 수 감소
- layer 제거
- network 깊이 축소
그러나 기존 model들(resnet)과 같은 깊은 모델들은 위에서 설명한 것과 같이 중복된 연산이 여러번 반복되는 경향들이 있다. 이때 경량화를 해버린다면 중복되지 않은 layer를 제거하여 성능이 크게 하락하는 상황이 발생할 수도 있다. 또한 channel 수도 같이 감소하므로 여러 feature들이 소멸하여 성능이 크게 하락하게 된다.
5. 다양한 아키텍처에 적용 가능
CSPnet은 ResNet, DenseNet 등 다양한 기존 아키텍쳐에 적응이 가능하다.
Yolo3, 4에서 사용한 CSPnet
yolov4에서 사용한 CSPBlock은 다음과 같다.

이걸 pytorch로 구현해 보자.
# CSPDarknet53.yaml
model_architecture : [
# num_of_out_filter, kernel_size, stride, padding
# CSP Residual block, num_of_repeat
[32, 3, 1, 1],
[64, 3, 2, 1],
["B", 1],
[128, 3, 2, 1],
["B", 2],
[256, 3, 2, 1],
["B", 8],
[512, 3, 2, 1],
["B", 8],
[1024, 3, 2, 1],
["B", 4]
]
# model.py
import yaml
import torch
from torch import nn
path = './config/CSPdarknet.yaml'
def load_model(path):
with open(path, 'r') as f:
config = yaml.safe_load(f)
model = config['model_architecture']
return model
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.Mish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class CSPBlock(nn.Module):
def __init__(self, in_channels, num_repeat, **kwargs):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels // 2 , kernel_size=1, stride=1, padding=0)
self.conv2 = nn.Conv2d(in_channels, in_channels // 2, kernel_size=1, stride=1, padding=0)
self.residual = ResidualBlock(in_channels // 2, num_repeat)
self.conv3 = nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
self.act = nn.Mish()
def forward(self, x):
x1 = self.act(self.conv1(x))
x2 = self.act(self.residual(self.conv2(x)))
output = torch.cat([x1, x2], dim=1)
return output
class ResidualBlock(nn.Module):
def __init__(self, in_channels, num_repeat):
super().__init__()
self.layers = nn.ModuleList([
nn.Sequential(
CNNBlock(in_channels, in_channels // 2, kernel_size=1, stride=1, padding=0),
CNNBlock(in_channels // 2, in_channels, kernel_size=3, stride=1, padding=1),
)
for _ in range(num_repeat)
])
def forward(self, x):
for layer in self.layers:
output = x + layer(x)
return output
class CSPDarknet(nn.Module):
def __init__(self, in_channels=3, **kwargs):
super(CSPDarknet, self).__init__()
self.in_channels = in_channels
self.architecture = load_model(path)
self.module = self._create_block(self.architecture)
def forward(self, x):
x = self.module(x)
return x
def _create_block(self, architecture):
layers = []
in_channels = self.in_channels
for layer in architecture:
if isinstance(layer, list) and len(layer) == 4:
n_filter, kernel, stride, padding = layer
layers.append(CNNBlock(in_channels, n_filter, kernel_size=kernel, stride=stride, padding=padding))
in_channels = n_filter
elif isinstance(layer, list) and len(layer) == 2:
n_repeat = layer[1]
layers.append(CSPBlock(in_channels, n_repeat))
in_channels = in_channels
return nn.Sequential(*layers)
a = torch.randn(1, 3, 416, 416)
model = CSPDarknet(in_channels=3)
print(model(a).shape)
yolo에서 CSPBlock은 backbone에 해당한다. pytorch로 구성하면 알다시피 backbone 자체는 그리 어렵지 않다. 이 구성에서 neck(SPP, PAN), head까지 연결하면 조금씩 난이도가 있는 모델이 형성되긴 하지만 backbone이 feature를 추출하는데에 있어 매우 중요한 역할을 함으로 구현하는데 많은 노력을 쏟는 것이 중요하다.
