FaceDetection에서 유명한 모델인 RetinaFace에 대한 모델을 설계해보려고 한다.
기존의 RetinaFace model은 Mobilenetv1을 활용하여 코드를 구성하였으나 내가 작성할 코드는 Mobilenetv2를 활용하여 모델의 Backbone을 구성할 예정이다.
RetinaFace의 model의 구조는 다음과 같다.
Backbone - neck - head 순서로 구성되어 있는데, 좀더 상세히 작성한다면
Backbone(Mobilenet V2) - neck(Feature Pyramid) - head(SSH)로 구성되어 있다.
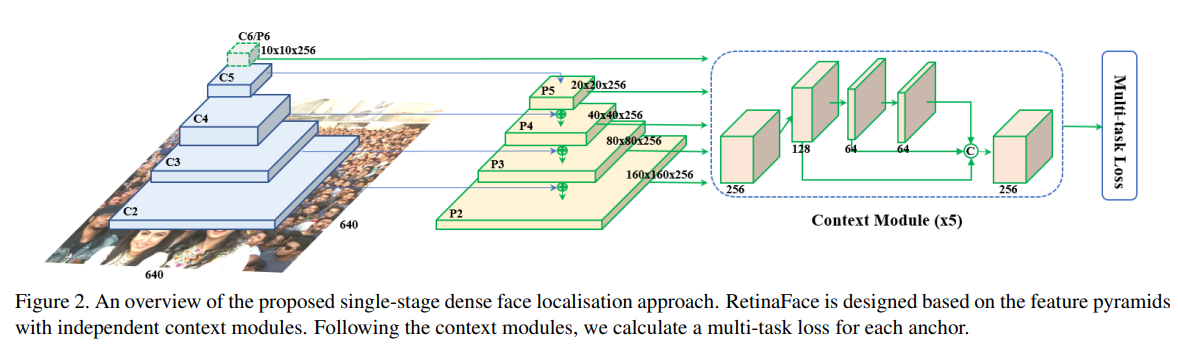
모델의 구조는 논문에서 잘 설명하고 있으니 좀더 상세한 정보는 RetinaFace paper을 참고하면 좋다.
import logging
import torch
from torch import nn
class CNNBlock(nn.Module):
'''
This class Original CNNblock.
Activation function is ReLU() Not ReLU6.
ReLU6 will behave the same way as ReLU if the input does not exceed 1.
'''
def __init__(self, in_channels, out_channels, **kwargs):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU()
def forward(self, x) -> torch.Tensor:
'''
forward pass
Returns : output tensor of shape : (-1, channel, width, height)
'''
return self.act(self.bn(self.conv(x)))
class PointWiseBlock(nn.Module):
'''
This class is 1 * 1 Convolution Block.
1*1 convolution reduces the amount of computation
and helps you learn various characteristics by growing channels.
'''
def __init__(self, in_channels, out_channels):
super().__init__()
self.layer = CNNBlock(in_channels, out_channels,
kernel_size=1, stride=1, padding=0)
def forward(self, x) -> torch.Tensor:
return self.layer(x)
class DepthWiseBlock(nn.Module):
'''
This class is Depthwise Convolution Block.
Depthwise Convolution is independent and has the advantage
of enriching the expression of each channel.
It also has low computational power and easy real-time processing.
'''
def __init__(self, in_channels, out_channels, stride):
super().__init__()
self.layers = CNNBlock(in_channels, out_channels,
kernel_size=3, stride=stride,
padding=1, groups=in_channels)
def forward(self, x) -> torch.Tensor:
return self.layers(x)
class InvertedResidualBlock(nn.Module):
'''
This class Inverted Residual Block.
It is consist of [PointwiseBlock + DepthWiseBlock + PointwiseBlock].
'''
expansion = 6
def __init__(self, in_channels, out_channels, stride, use_residual):
super().__init__()
self.block = nn.Sequential(
PointWiseBlock(in_channels, in_channels * InvertedResidualBlock.expansion),
DepthWiseBlock(in_channels * InvertedResidualBlock.expansion, in_channels * InvertedResidualBlock.expansion, stride),
nn.Conv2d(in_channels * InvertedResidualBlock.expansion, out_channels,
kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels)
)
self.use_residual = use_residual
def forward(self, x) -> torch.Tensor:
shortcut = self.block(x)
if self.use_residual:
output = x + shortcut
else:
output = shortcut
return output
@classmethod
def change_exp(cls, exp):
cls.exp = exp
if cls.exp == cls.expansion:
print('Not change InvertedResidualBlock expansion. please check again')
else:
pass
class RetinaFace(nn.Module):
def __init__(self):
super().__init__()
self.layers1 = CNNBlock(in_channels=3, out_channels=64, kernel_size=3, stride=2, padding=1)
self.layers2 = CNNBlock(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.block1 = self._create_block(64, 2, 64, 5, 2)
self.block2 = self._create_block(64, 2, 128, 1, 2)
self.block3 = self._create_block(128, 4, 128, 6, 2)
self.block4 = self._create_block(128, 2, 256, 1, 2)
def forward(self, x):
x = self.layers1(x)
x = self.layers2(x)
c3 = self.block1(x)
c4 = self.block2(c3)
c5 = self.block3(c4)
x = self.block4(c5)
return x, [c3, c4, c5]
def _create_block(self, in_channels, expansion, out_channels, num_repeat, stride):
layers = []
use_residual = None
InvertedResidualBlock.change_exp(expansion)
for idx, _ in enumerate(range(num_repeat)):
if idx == 0:
stride = stride
use_residual = False
else:
stride = 1
use_residual = True
layers.append(InvertedResidualBlock(in_channels, out_channels, stride, use_residual))
return nn.Sequential(*layers)
a = torch.randn(1, 3, 640, 640)
model = RetinaFace()
print(model(a)[0].shape)
print(model(a)[1][0].shape)
for i in range(3):
print(model(a)[1][i].shape)
Backbone자체는 간단하다. Feature pyramid에 사용할 각기 다른 사이즈를 갖는 feature map의 정보를 하나의 리스트에 넣고 총 3가지씩 할당한다. 현재 backbone은 매우 간략한데, 이는 우선 학습을 해보고 ap성능이 매우 떨어진다면 해당 layer들의 채널을 늘려서 학습을 할 예정이다.
또한, 이번 RetinaFace model을 학습하는데에 기존과 다른 차이점은 Face landmark를 따로 구하진 않을 예정이고 오직 Face detection을 통해 [x1, y1, x2, y2, confidence]만 출력할 수 있도록 하려고 한다. 어짜피 Face landmark detection인 PFLD model을 통해 따로 landmark를 출력하여 따로 계산할테니 굳이 Retina Face model에서 Face landmark를 위해 추가적인 학습이 필요가 없으며 Face landmark로 인한 불필요한 연산량을 줄이이 위함이다. 따라서 Wider Dataset도 필요한 내용만 추출할 것이므로 Dataset의 전처리도 필요해 보인다.
*object detection에서 feature Pyramid에 대한 내용이 계속 나오는데, 이 논문은 오늘 리뷰하여 따로 작성하려 한다. 이미 아는 내용인데, 정확히 아는 것이 중요하다 생각하여 리뷰를 통해 복기 해보려 한다.
*SSH도 같이 리뷰를 해보려고 한다. 논문도 계속 읽어보는 것이 중요하고 Retina Face의 head 부분을 정확히 이해하기 위해선 꼭 필요한 과정이라 생각하기 때문.
