Feature Pyramid Networks for Object Detection
Face Detection의 모델을 이해하기 위해선 3가지를 알아야 한다.
- Resnet, mobilenet
- FPN (Feature Pyramid Networks)
- SSH (Single Stage Headless Face Detector)
Resnet과 mobilenet은 기존에 다뤘던 내용이니 패스하고 FPN, SSH 순서대로 논문을 리뷰할 생각이다. 두 개의 idea의 코드는 매우 짧지만 내용은 매우 임펙트하고 이 모두 Face Detection, 연산량에 필요하고 또 필요하다. 특히, FPN은 기존의 방식과 비교하면 모바일, 임베디드에서 사용할 수 있도록 연산량을 획기적으로 줄였고(mobilenet도 한 몫하였음.) 성능 또한 기존 모델과 차이가 없도록 설계되었다.
Abstract
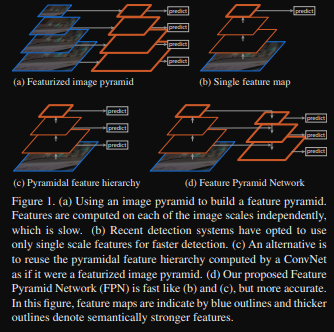
Feature Pyramid는 기존에 존재했던 내용이다. 기존에는 input이 여러 개가 필요했고 이 input의 size에 따라 feature를 뽑아내어 학습에 이용했다. 이말인 즉슨,
640 * 640 이미지가 있다고 가정할때, 4개의 feature를 뽑는다면
- 320 * 320
- 160 * 160
- 80 * 80
- 40 * 40
의 input size가 필요했으며 해당 size에 맞게 feature를 뽑아내는 과정이 필요했다. 학습하기 위해서 하나의 데이터당 총 4,5가지의 image size가 필요했다는 것. 이에 따라 늘어나는 연산량과 메모리가 거대했다. 학습 데이터가 많을수록 성능은 좋을 수 밖에 없었으나 연산량과 메모리가 너무 컸다는 단점이 존재했었다.
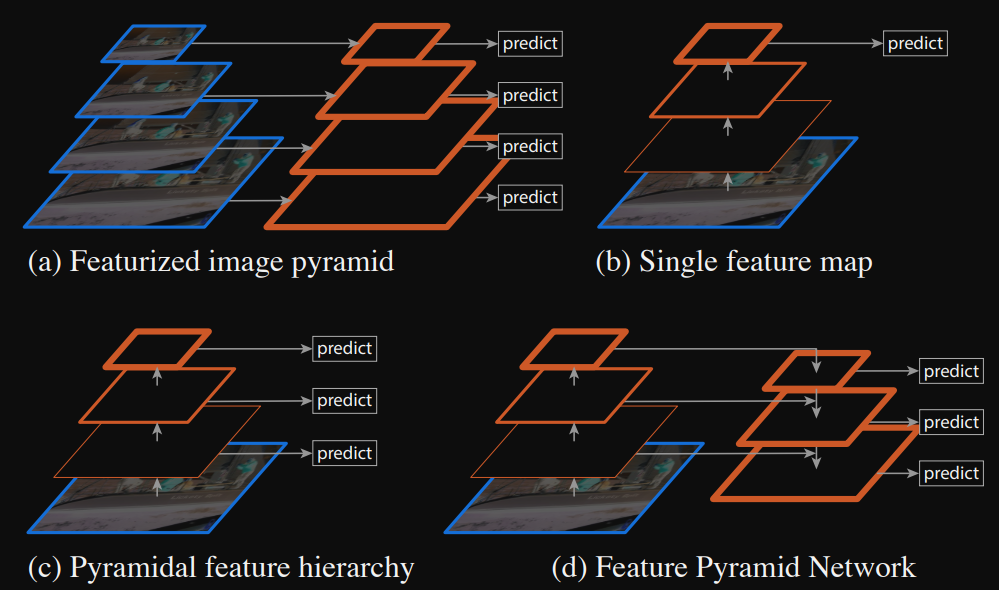
기존 방식이 A방식이었고 논문에서 제안한 방식은 D에 해당한다.
저자들은 해당 논문이 다중 scale, 피라미드 구조의 심층 합성곱 신경망의 본질적 계층 구조를 활용하여 추가 비용을 거의 들지 않고 pyramid feature를 구성하는 방법을 제안했다. 여기서 추가 비용이란 위의 기존 방식처럼 연산량과 메모리를 대폭 줄였다는 것을 의미한다.
1. Introduction
해당 sector에서는 pyramid 구조에 대해 중점적으로 설명한다. 여기서 말하는 pyramid는 기존 방식의 pyramid 구조를 말한다.
이 구조는 DPM에서 사용했었는데, 잠시 DPM이 뭔지 알아보자.
DPM은 HOG(Histogram of Oriented Gradients)와 같은 수작업 피처를 기반으로 동작했다. 객체를 여러개의 part로 나누어 모델링하고 각 part가 변형될 수 있다는 점에서 유연성을 가졌다. 여기서 객체를 여러개의 part로 나눈다는 것이 pyramid 구조이다.
DPM object detection은 10개 이상의 스케이 필요했고 이에 따라 여러가지의 scale data sample이 필요로 했다. 이 이후에 CNN이 나오게 되면서 DPM이 묻히긴 했지만 CNN의 성능을 높이기 위해선 DPM에서 사용한 Pyramid 구조를 사용해야 했다.
하지만 계산량과 메모리 사용량이 매우 높아졌고 추론시간이 4배 이상 증가하고 실용성이 떨어졌다. (2 stage detection에서는 더더욱 사용할 수 없게 됨.) -> 따라서 기존 방식의 Pyramid 구조인 Image Pyramid는 사용할 수 없다.
2. Feature Pyramid Networks
CNN의 pyramid feature 계층 구조를 활용한다.

일반적인 pyramid 구조인데, low-level feature에서 high-level feature까지 의미론적 정보를 포함하여 계층 구조를 통해 high-level feature의 정보를 모든 level에서 포함하는 feature pyramid를 구축한다.
이 방법은 Backbone인 resnet, mobilenet가 독립적으로 동작하며 총 3가지로 구성되어 있다.
- bottom-up 경로
- top-down 경로
- lateral 연결
1. bottom-up path
Bottom-up path는 Backbone인 resnet, mobilenet의 forward pass로 다양한 size의 pyramid 계층 구조를 만든다.

resnet과 mobilenet의 모델 구조를 보면 feature map size를 줄이기 전과 후로 layer들이 나눠진 것을 볼 수 있는데, 각 layer들의 마지막 stage인 feature map을 사용한다.
논문에서 언급한 resnet의 경우, 각 stage의 마지막 잔차 block의 output feature map을 사용한다. [C2, C3, C4, C5]로 나타내며 conv2, conv3, conv4, conv5의 출력을 의미한다. original image에 대해 stride는 각각 [4, 8, 16, 32]이다. conv1을 사용하지 않는 이유는 이미지 사이즈가 너무 크면 메모리 저장량이 큰 문제가 발생. 사용하면 성능은 좋아질 가능성이 높지만 메모리와 연산량을 생각하면 사용하지 않는 것이 좋음. 실시간 처리인 Inference에서도 정상적으로 동작해야 하기 때문에, 많은 연산량이 필요로 한다면 불필요함.
2. Top-down path, 3. Lateral connections
Top-down path는 high feature pyramid level에서 더 강력한 의미론적 feature를 공간적으로 보완하여 high-level feature를 생성한다. 이러한 feature는 Bottom-up 경로에서 나온 feature와 lateral 연결로 병합된다.
lateral connections은 두 경로에서 동일한 공간의 크기의 feature map을 결합하지만 Bottom-up 경로의 활성화는 더 세밀하고 Top-down 경로의 활성화는 더 높은 의미론적 수준을 보이게 된다.
이후 단계에서는 각 단계의 feature map은 high dimension으로 upsampling되고 최종 pyramid feature map을 생성한다.
===> 도대체 이게 무슨말이냐?????
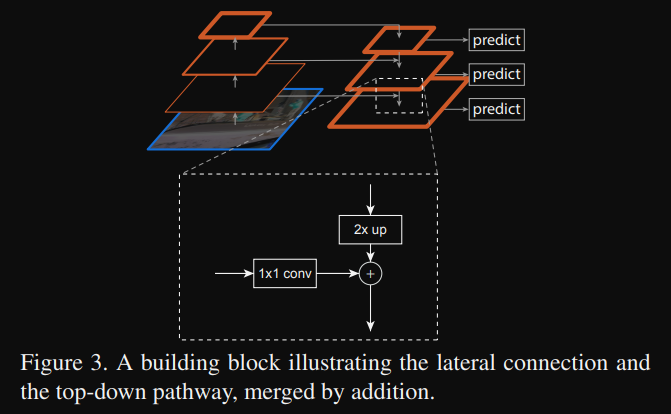
-
Bottom-up path : 우리가 일반적으로 CNN을 학습했을때, image size가 점점 작아지고 high-level feature map을 뽑아내는 것을 알 수 있는데, 이를 Bottom-up 방식이라고 한다. (Pyramid 구조이기도 함.) 이 Bottom-up path에서 image size를 pooling을 사용하거나 stride=2를 통해서 절반으로 줄이는데, 절반으로 줄이기 전의 feature map 정보를 list에 저장해두면 된다. 위에서 말한 것처럼 FPN은 Backbone과는 독립적으로 동작하기 때문에, 해당 feature 정보만 저장해두고 FPN을 사용할때 해당 list를 가져오면 된다.
-
Top-down path : list에 저장된 feature map이 3개라고 가정할때, [low-level feature, medium-level feature, high-level feature]가 3가지가 저장되어 있을텐데, high-level feature를 medium-levle feature가 결합하기 위해서는 feature map size가 동일해야 하므로 high-level feature를 upsampling하여 2배로 키운다. 이런 방식으로 Top-down 방식이라 하고 reverse pyramid 구조이기도 하다.
-
lateral connections : Bottom-up path로 뽑은 high-level feature를 2배로 upsampling한 것과 medium-level feature를 서로 더한다. 이때, 단순히 element wise로 원소끼리의 합이므로 채널의 갯수는 늘어나지 않는다. 그러나 일반적으로 high-level feature map이 갖는 channel의 갯수가 더 많으므로 add를 하게 되면 오류가 나는데, 이러한 오류를 피하기 위해 11 Conv을 사용하여 서로 같은 channel의 갯수를 갖게 만들어준다.
예를 들어, high-level feature map을 2배 upsampling한 tensor의 형태가 (-1, 512, 40, 40)이고 medium-level feature map의 tensor의 형태가 (-1, 256, 40, 40)이라면 정상적으로 element-wise가 일어나지 않는다. 따라서 nn.Conv2d(256, 512, kernel_size=1, stride=1, padding=0)을 medium-level feature map channel의 갯수를 high-level feature map channel의 갯수에 맞추어 element-wise를 할 수 있도록 해준다.
(여기서 element-wise는 두 원소간의 합을 의미한다.)
서로 다른 2*2 형태를 갖는 tensor A, B가 있다고 했을때, A(0, 0) + B(0, 0) = C(0, 0) 처럼 계산되는 것을 element-wise라고 한다. Depthwise로 유명한 mobilenet을 보면 독립적으로 계산된 channel을 depth 축으로 쌓아서 계산하는 것처럼 말이다.
논문의 나머지 내용은 Faster RCNN과 연결하여 설명하고 있기 때문에, 지금은 이 정도만 알아둬도 될 것 같다.
