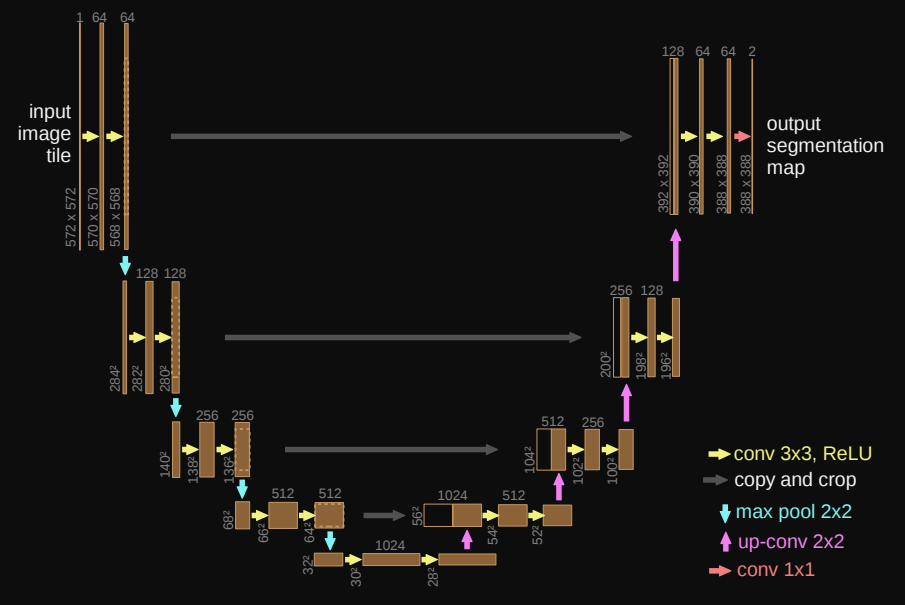
UNet paper : https://arxiv.org/pdf/1505.04597.pdf
Unet의 구조와 설명에 대한 내용이 아닌 one_hot_encode 방식을 살펴보려 한다.
우선 아래의 그림부터 살펴보자.
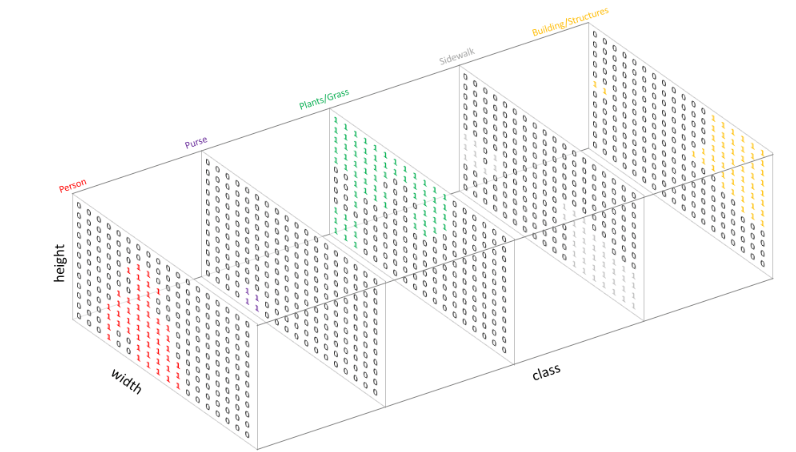
출처 : https://gaussian37.github.io/vision-segmentation-one_hot_label/
one hot encode 방식을 사용하는 이유부터 살펴보자.
1. 명확한 class 식별
: 각 pixel에 대한 class 소속이 명확하게 표현된다.
2. multi class 문제 해결
: segmentation의 pixel 단위의 mulit class classfication 문제이다.
3. loss 계산
: 주로 cross entropy, Diceloss 등과 같은 loss function을 사용한다.
4. 학습 효율성 향상
: model이 각 class에 대해 independent하게 확률을 출력할 수 있다.
이 같은 이유로 인해 one hot encode를 사용한다.
One hot encode 코드를 살펴보자.
def one_hot_encode(label, label_value):
sematic_map = []
for pixel in label_value:
equality = np.equal(label, pixel)
class_map = np.all(equality, axis=-1)
sematic_map.append(class_map)
sematic_map = np.stack(sematic_map, axis=-1)
return sematic_map
one_hot_encode에서 중요한 건 각 채널 마다의 class의 존재 유무이다.
우선 가정을 해보자.
- images_shape = (800, 600, 3), label_shape = (800, 600, 3)
- class = ('background', 'person') 총 2가지의 class
- 위 코드의 label_value = [[0, 0, 0], [255, 255, 255]]

label이 총 3채널을 갖고 있으므로 우리는 위와 같은 그림이라고 생각할 수 있다. 그럼 저 코드 동작 방식에 대해 생각해보자.
equality = np.equal(label, pixel)우선 이 방식이 어떻게 동작하는지 파악하는 것이 매우 중요하다. 또한, one_hot_encode 그림을 다시한번 보고 해당 코드의 설명을 보길 바란다.
위의 one_hot_encode 그림을 보면 각 채널 별로 class가 무엇이고 어디에 위치해 있는지 파악하는 과정이라 볼 수 있다. 따라서 우리는 채널별로 class가 존재하는지 파악해야 한다.

위의 그림처럼 각 채널의 맨 첫번 째 행을 가져온다고 생각하자.
그럼 총 3개의 채널이 (600, 3) shape를 갖게 된다. 실행 결과를 한번 보자.
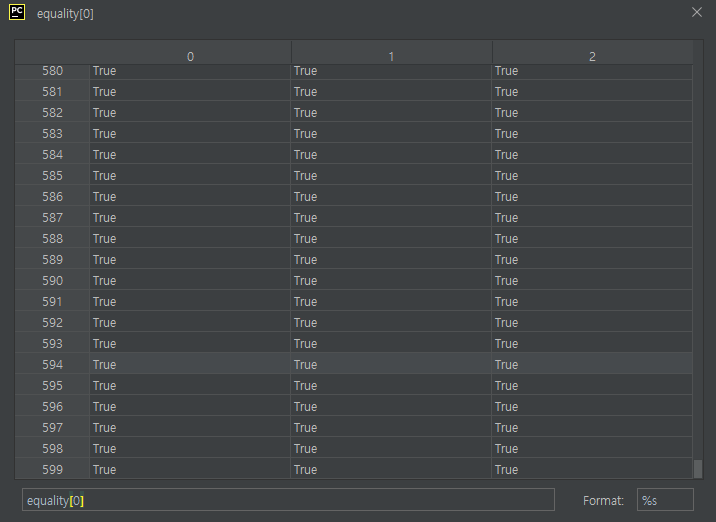
(600, 3)에 boolean 값이 가득 차있는 것을 볼 수 있다. RGB 순이라 가정할때, 0은 R, 1은 G, 2는 B로 보면 된다. equality[0]의 shape가 (600, 3)이므로 이것이 총 800개가 있어야 (800, 600, 3)을 다 훑어보게 된다. 한번 확인해보자.
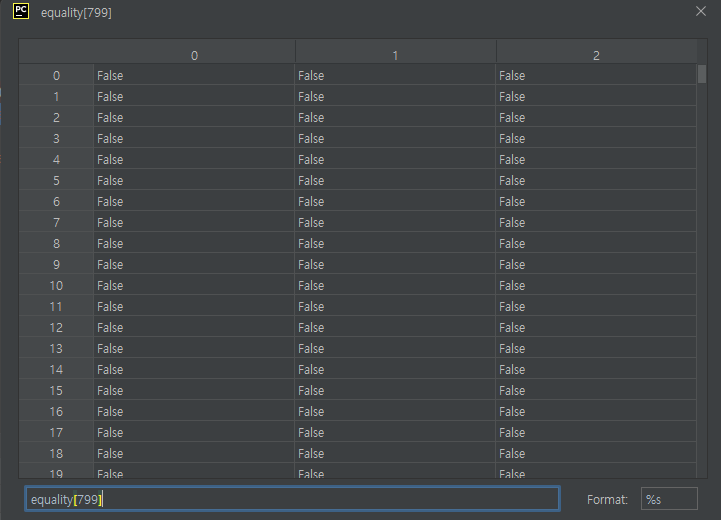

인덱스 799까지는 잘 출력되지만 800 이상부턴 출력이 안되는 것 까지 확인하자.
즉, one_hot_encode는 해당 라벨에 class가 어디에 있는지 채널별로 확인할 수 있게 만드는 거라고 생각하면 이해하기 쉽다. 이것들이 loss에 이용되어 계산되고 model이 최적화 된다.
one_hot_encode 방식이 제대로 이해가 안가는 경우에는 해당 코드를 뜯어보며 과정을 하나씩 알아가는 것이 지름길일 수 있다.
