
이번 게시글에서는 MySQL과 PostgreSQL을 공부하며 흥미롭게 접한 내용을 정리하고자 한다. 흔히 볼 수 있는 내용보다는 흥미로운 사실들만 모아 작성했으므로, 다소 가독성이 떨어질 수 있다.
1. 아키텍처
MySQL
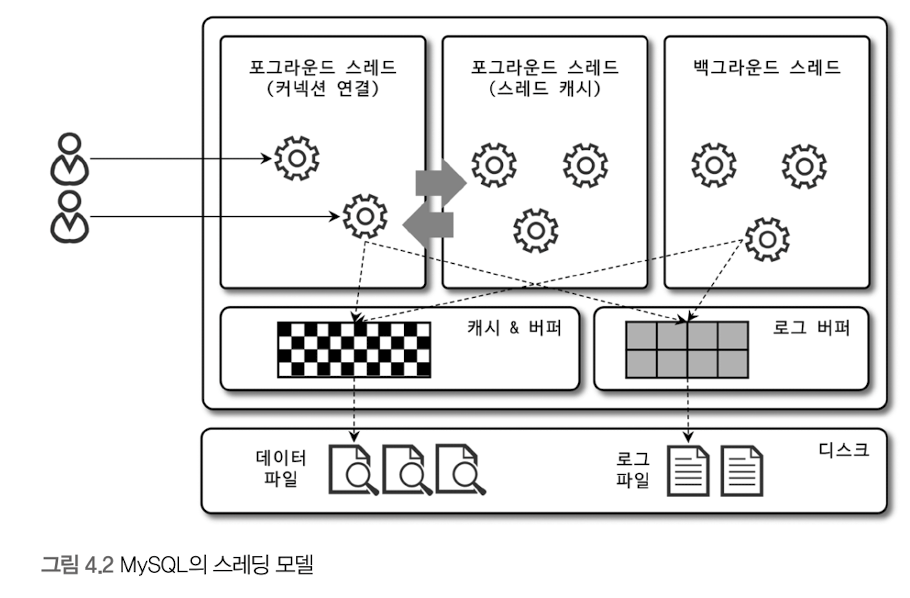
MySQL 서버는 스레드 기반으로 동작하며, 포그라운드 스레드와 백그라운드 스레드로 나뉜다.
- 포그라운드 스레드는 접속된 클라이언트 수만큼 존재하며, 스레드 풀과 유사한 방식으로 동작한다. 클라이언트 요청이 들어오면 기존 스레드를 재사용해 성능을 최적화하며, 요청 처리에 유연하게 대처할 수 있다.
- 백그라운드 스레드는 버퍼에서 데이터를 읽고 디스크에 기록하는 작업을 수행한다. 이때 성능 향상을 위해 데이터는 먼저 버퍼에 저장되고, 이후 디스크에 쓰여진다. 이는 데이터의 입출력 성능을 높이기 위한 중요한 설계이다.
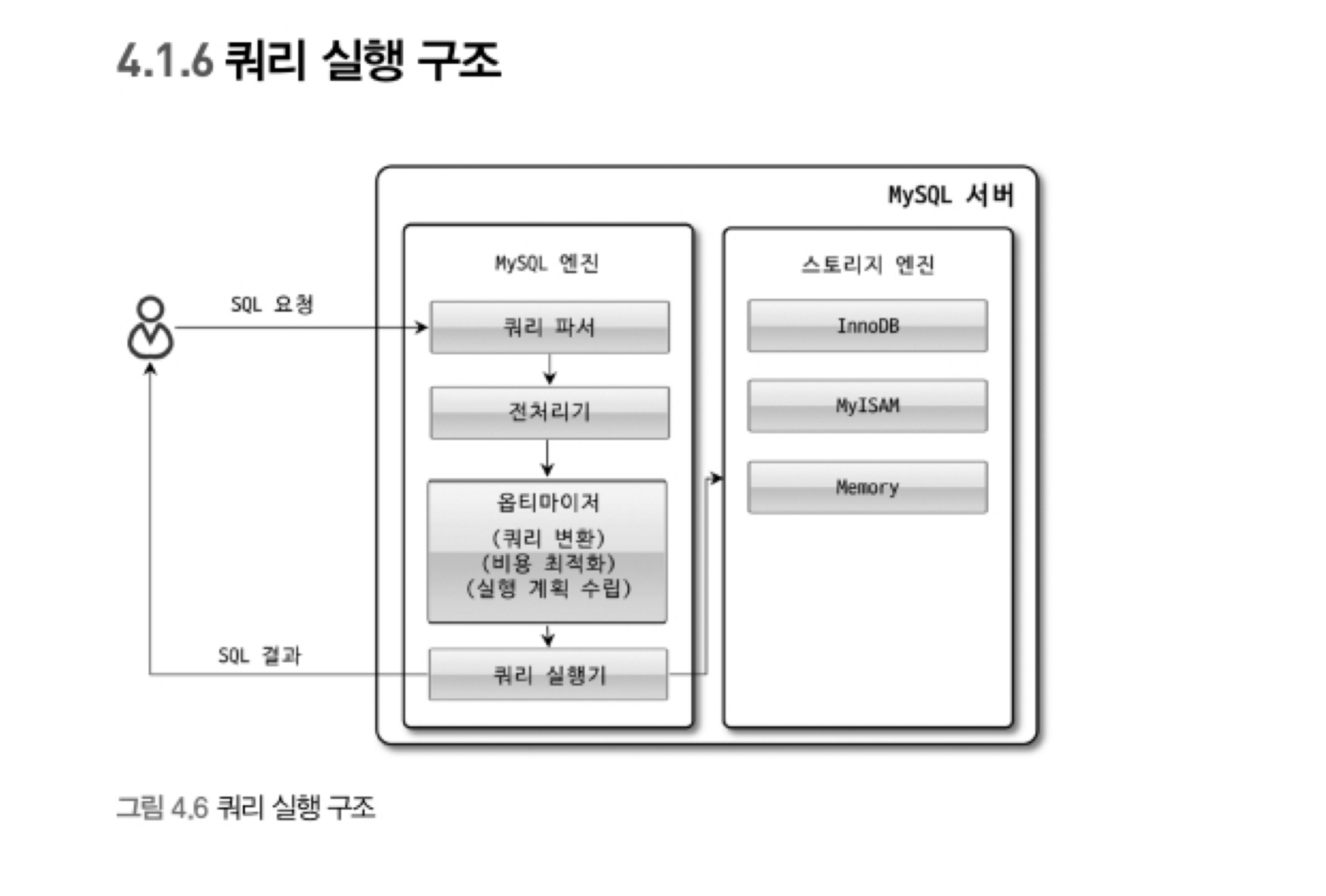
쿼리 파서, 전처리기, 옵티마이저, 쿼리 실행기는 MySQL 엔진 영역에서 수행되고, 데이터의 읽기/쓰기 작업은 스토리지 엔진에서 수행된다.
- 쿼리 파서는 SQL 문을 파싱하여 구문을 분석하고, 전처리기는 쿼리의 정확성을 검증하며, 옵티마이저는 효율적인 실행 계획을 수립한다. 이후 쿼리 실행기는 스토리지 엔진에 명령을 전달하여 데이터를 처리한다.
- 이러한 구조 덕분에 MySQL 엔진은 다양한 스토리지 엔진(InnoDB, MyISAM 등)과 호환되며, 각 스토리지 엔진의 특성에 따라 데이터 처리 방식만 다를 뿐, MySQL 엔진의 기본적인 동작 방식은 동일하게 유지된다.
PostgreSQL
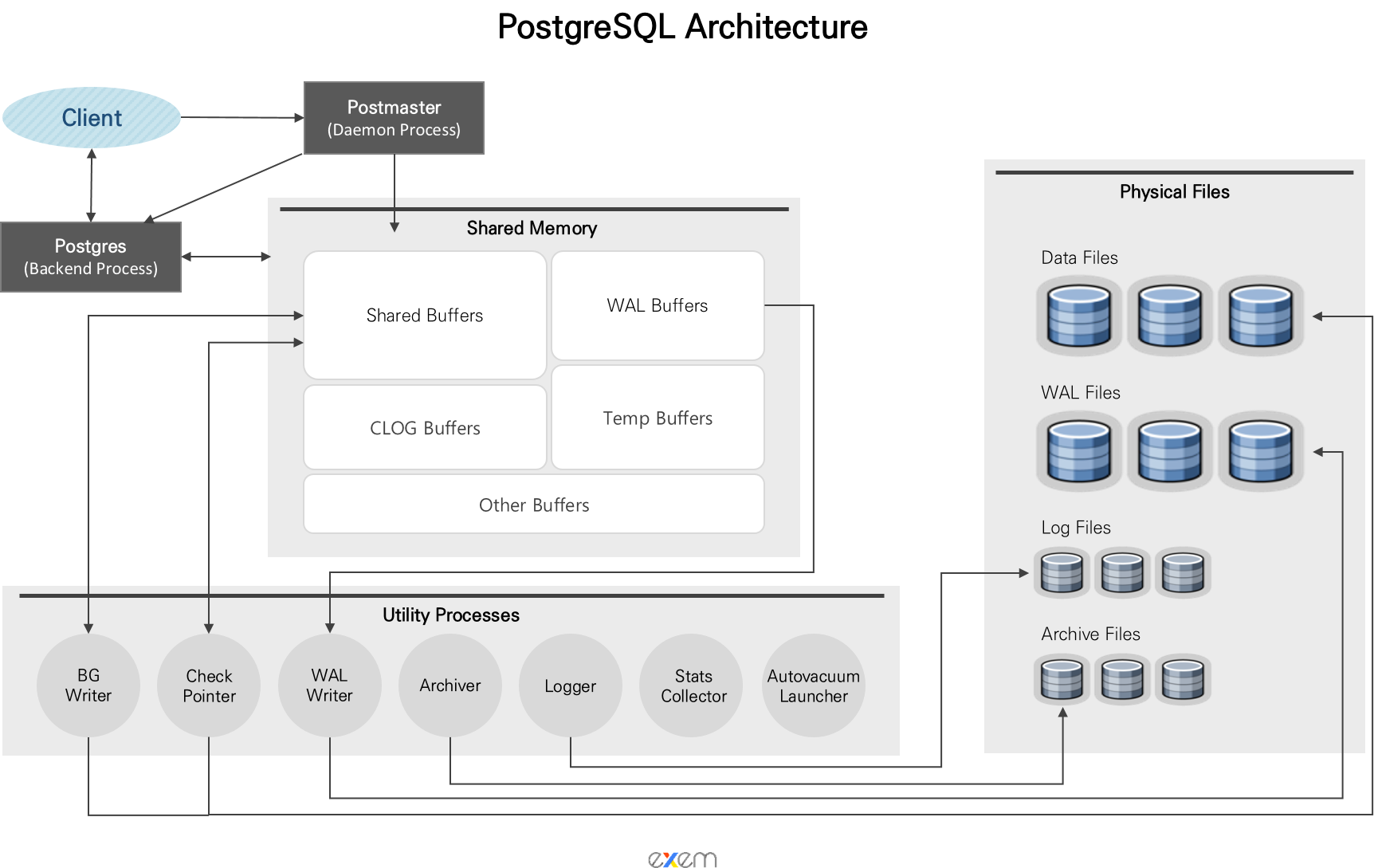
PostgreSQL은 프로세스 기반으로 동작하며, PostMaster라는 데몬이 실행되어 있다가 사용자의 요청이 들어오면 Backend Process라는 프로세스를 생성한다.
- PostMaster는 PostgreSQL 서버의 메인 프로세스로, 클라이언트 연결을 관리하고 새로운 클라이언트 요청이 들어올 때마다 Backend Process를 생성한다. 이 프로세스는 클라이언트와의 세션을 유지하며, SQL 쿼리 처리, 데이터 읽기 및 쓰기를 수행한다.
- PostgreSQL이 MySQL과 다르게 프로세스 기반으로 동작하는 이유는 안전성을 중시하는 설계 때문이라고 생각한다. 각 연결이 독립적인 프로세스로 동작하므로, 특정 프로세스에서 오류가 발생해도 다른 연결에는 영향을 미치지 않는다.
2. Undo와 Redo
MVCC를 이해하기 위해 Undo와 Redo에 대해 간략히 정리해보자.
Undo
트랜잭션과 격리 수준을 보장하기 위해 DML(Select 제외)로 변경되기 이전 데이터를 백업한 것을 Undo 로그라고 한다. 이를 통해 두 가지 작업을 수행한다.
- 트랜잭션이 롤백될 때 Undo 로그를 사용해 데이터를 복구한다.
- 격리 수준에 따라 Undo 로그의 데이터를 읽어 이전 상태를 재현할 수 있다. 이는 MVCC에서 중요한 역할을 한다.
- 참고로 트랜잭션이 오랜 시간 유지되면 Undo 로그 크기가 커질 수 있다. 이 자체는 큰 문제가 아니지만, Undo 로그가 커질수록 데이터 검색 시 Undo 로그를 탐색하는 시간이 늘어나 성능 이슈로 이어질 수 있다.
- 이러한 이유로 PostgreSQL은 Undo 로그와 비슷하지만 다른 방식으로 MVCC를 지원하며, 이 차이점은 뒤에서 다룬다.
Redo
프로그램 비정상 종료 시 데이터 변경 내용을 로그로 저장해 복구하는 것을 Redo 로그라고 한다.
- 데이터가 커밋되었지만 디스크에 기록되지 않은 상태에서 시스템이 종료될 경우, Redo 로그를 사용해 복구할 수 있다.
- 디스크에 직접 데이터를 저장하면 안전하지만, 데이터베이스는 랜덤 I/O를 꺼리기 때문에, 한번에 데이터를 저장하기 위해 버퍼에 기록하고 백그라운드 스레드가 이를 디스크에 저장한다. 이 과정에서 프로그램이 백그라운드 스레드가 작업하기 전에 종료될 가능성에 대비해 Redo 로그가 필요하다.
프로그램 종료 시 처리해야 할 상황은 두 가지가 있다.
- 커밋되었지만 디스크에 기록되지 않은 경우, Redo 로그를 사용해 데이터를 복구한다.
- 롤백되었지만 디스크에 기록된 경우에는 Redo 로그로 진행 상태를 확인하고, 롤백된 데이터를 Undo 로그를 사용해 복구한다.
참고로 Redo 로그는 변경된 내용만 기록하여 공간 사용을 최소화하고, 로그의 크기를 효율적으로 관리한다.
3. MVCC
MVCC는 다중 버전 동시성 제어의 약자로, 기존 Lock 기반 동시성 제어 방식에서 발생하는 문제를 해결하기 위해 고안된 기법이다. 여러 버전을 관리해 읽기 Lock에서 다른 쓰기가 가능하고, 쓰기 Lock에서 다른 읽기가 가능하게 한다.
MySQL
MySQL에서의 MVCC는 앞에서 설명한 대로 Undo 로그를 사용한다. 이와 관련해 궁금했던 몇 가지를 정리해보자.
-
READ COMMITTED와 REPEATABLE READ 둘다 MVCC를 사용하는데, 왜 READ COMMITTED에서만 NON-REPEATABLE READ가 발생할까?
이는 READ COMMITTED와 REPEATABLE READ가 참조하는 Undo 영역의 범위가 다르기 때문이다. READ COMMITTED는 다른 트랜잭션이 커밋한 최신 데이터를 읽는 반면, REPEATABLE READ는 트랜잭션 시작 시점에 백업된 레코드를 참조해 같은 데이터를 반복적으로 읽는다.
-
MVCC를 사용하는데도 REPEATABLE READ에서 PANTOM READ가 발생할 수 있는 이유는?
일반적으로 MVCC를 사용하는 REPEATABLE READ에서는 PANTOM READ가 발생하지 않는다. 하지만 SELECT ... FOR UPDATE를 사용하는 경우에는 발생할 수 있다. SELECT ... FOR UPDATE는 쓰기 Lock을 설정해 현재 레코드에 Lock을 걸지만, Undo 영역에는 Lock을 설정할 수 없기 때문에 새로운 데이터 삽입이 가능해지는 경우다.
-
MySQL의 REPEATABLE READ에서는 PANTOM READ가 발생하지 않는다고 들었는데?
이는 InnoDB의 Next-Key Lock 덕분이다. Next-Key Lock은 SELECT ... FOR UPDATE로 가져오는 레코드뿐만 아니라 그 인접한 레코드에 대한 잠금을 설정해, 해당 범위에 새로운 데이터가 삽입되지 않도록 한다. 이로 인해 PANTOM READ를 방지할 수 있지만, 이러한 Locking 방식은 데드락 문제를 유발할 수 있어 현업에서는 REPEATABLE READ를 신중하게 사용하는 경우가 많다.
PostgreSQL
PostgreSQL의 MVCC는 Undo 로그를 사용하지 않고, 데이터를 직접 Page에 기록하며, 각 레코드는 xmin, xmax 값을 사용해 자신의 트랜잭션에 맞는 데이터를 읽는다. 이와 관련해 궁금했던 부분을 정리해보자.
-
용량 문제는 없을까?
물론 문제다. PostgreSQL은 Page 내에 이전 버전의 데이터가 남아 있게 되고, 이러한 Dead tuple들이 쌓이면서 디스크 공간을 차지한다. 이를 해결하기 위해 Java의 GC와 유사한 AutoVacuum 작업을 수행해 불필요한 데이터를 정리한다. AutoVacuum은 Dead tuple의 임계치에 도달했을 때 실행되지만, 이 작업만으로는 테이블 크기가 줄어들지는 않는다. 테이블 크기를 줄이려면 Exclusive Lock을 사용해 Fully Vacuum을 수행해야 하지만, 이는 해당 테이블에 DML 작업이 불가능하다는 단점이 있다.
-
왜 이렇게 구현했을까?
PostgreSQL의 MVCC 방식은 Undo 로그를 사용하는 MySQL과 비교해 성능상의 장단점이 있다. 장점은 각 트랜잭션이 필요한 데이터를 Page 내에서 직접 참조할 수 있어, Undo 로그를 IO 작업으로 읽는 것보다 빠르다는 점이다. 또한, 롤백 시 Undo 로그를 사용해 데이터를 복구할 필요가 없어서 롤백 처리 속도가 빠르다. 단점으로는 대량의 Dead tuple이 쌓이면서 디스크 공간을 많이 차지하고, 주기적으로 Vacuum 작업을 수행해야 한다는 점이 있다. 이러한 점으로 롤백이 많이 발생하는 상황이라는 전제에서는 이점이 있지만, 대부분의 시스템에서 이런 경우는 드물다.
4. Index
일반적인 내용은 생략하고, 공부하며 흥미로웠던 부분만 정리해보자.
-
인덱스를 저장하기 위해 B-Tree를 사용하는 이유는?
Binary Search Tree는 불균형 문제로 인해 성능이 좋지 않다. 예를 들어, 삽입 순서에 따라 한쪽으로 치우칠 수 있어, 검색 시 최악의 경우 선형 시간(O(N))이 걸릴 수 있다. Red-black Tree는 균형을 유지하지만, B-Tree는 노드 하나에 여러 개의 데이터를 저장할 수 있어 디스크 접근 횟수를 줄이고, 대량의 데이터를 저장할 때 더 효율적이다. 이로 인해 대용량 데이터베이스에서는 B-Tree가 선호된다.
-
Hash Index를 사용하면 되지 않나?
Hash Index는 특정 상황에서는 매우 빠르다. 삽입, 삭제, 조회의 시간 복잡도가 O(1)이기 때문에 동등 비교에 특화되어 있다. 그러나 범위 검색이 불가능하고, 데이터가 균일하게 분포하지 않는 경우 성능 저하가 발생할 수 있다. 이러한 한계 때문에 범위 검색이 빈번한 상황에서는 B-Tree가 더 유리하다.
-
B+ Tree는 어떤가?
B+ Tree는 B-Tree와 유사하지만, 리프 노드에만 데이터를 저장하고 리프 노드들이 순차적으로 연결되어 있어 범위 검색 시 매우 빠르다. 이러한 특성 덕분에 전체 조회와 범위 조회에서 B-Tree보다 빠르며, 리프 노드를 제외하고 데이터를 담아두지 않기 때문에 메모리를 더 확보함으로써 더 많은 key들을 수용할 수 있어 트리의 높이가 짧아진다. 이러한 이점 때문에 InnoDB에서는 B+ Tree를 사용한다.
MYSQL
Clustered Index (Primary Key)
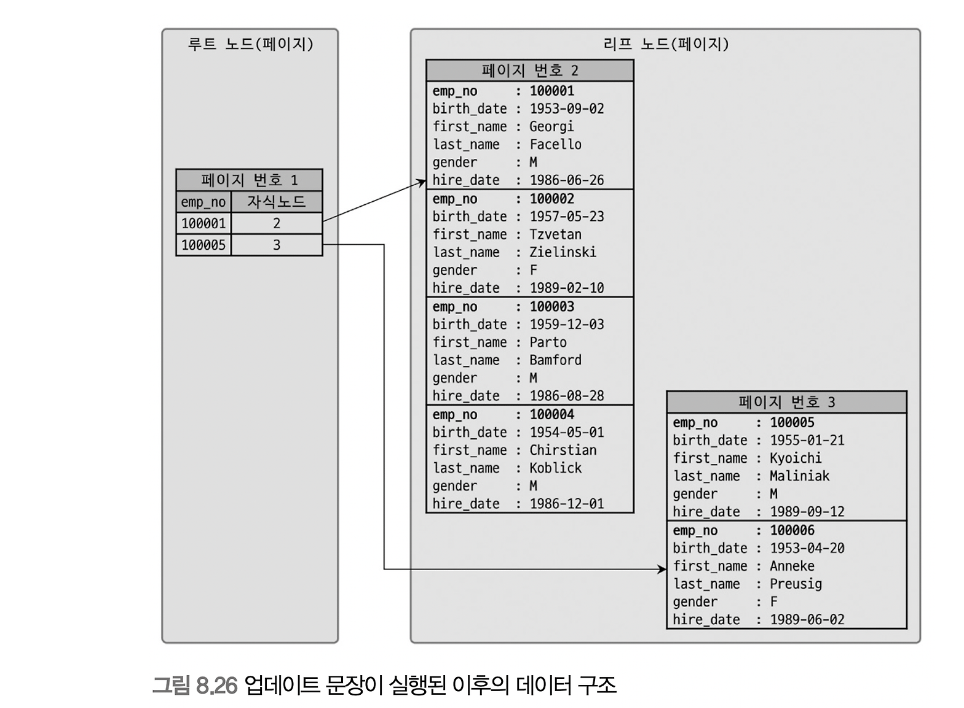
클러스터링 인덱스는 리프 노드에 레코드의 모든 컬럼이 저장되어 있다. 이로 인해 데이터 자체가 인덱스의 일부가 되므로, 인덱스를 사용해 데이터를 빠르게 검색할 수 있다. 다만, 클러스터링 인덱스는 테이블당 하나만 가질 수 있으며, 데이터 삽입 시 정렬된 상태를 유지해야 하므로 삽입/삭제 시 추가적인 오버헤드가 발생할 수 있다.
-
왜 이렇게 설계했을까?
PK 기반 검색의 성능을 극대화할 수 있기 때문이다. 클러스터드 인덱스 구조에서는 PK로 범위를 지정하면 연속된 페이지를 순차적으로 읽는 것만으로 결과를 얻을 수 있다. 또한, 모든 세컨더리 인덱스가 PK 값을 함께 저장하기 때문에 PK를 통해 실제 레코드에 빠르게 접근할 수 있고, 경우에 따라서는 인덱스만으로 쿼리를 처리할 수 있는 커버링 인덱스 효과도 얻을 수 있다.
-
문제점은 없을까?
물론 있다. 모든 세컨더리 인덱스가 PK를 포함하므로 PK 크기가 길면 전체 인덱스 크기도 커진다. 또한 세컨더리 인덱스를 통해 레코드를 찾을 때는 PK로 한 번 더 클러스터드 인덱스를 탐색해야 하므로 검색 비용이 추가된다. 삽입 시에도 레코드 저장 위치가 PK 값에 의해 결정되므로, PK가 랜덤하면 페이지 분할이 자주 발생해 성능이 저하된다. 마지막으로 PK 값을 변경할 경우, 내부적으로 DELETE와 INSERT 작업을 수행해야 하므로 처리 비용이 크다.
Non-Clustered Index (Secondary Index)
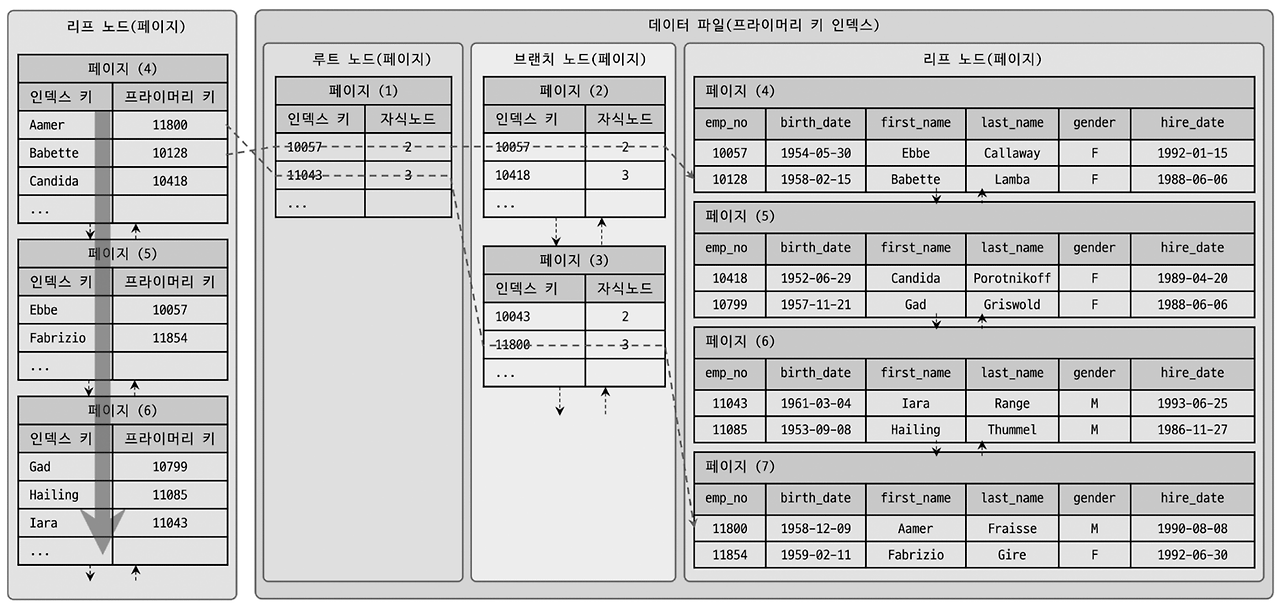
논 클러스터링 인덱스는 리프 노드에 물리적 주소 대신 PK를 저장하므로, 클러스터링 인덱스를 통해 실제 레코드에 접근한다. 즉, 인덱스를 이용해 검색한 후, 해당 PK를 사용해 클러스터링 인덱스를 통해 데이터를 가져오는 방식이다. 이로 인해 추가적인 I/O가 발생할 수 있지만, 검색 시 필요한 데이터를 빠르게 찾을 수 있다는 장점이 있다.
- Clustered Index와 Non-Clustered Index를 이렇게 구성한 이유는?
모든 인덱스에서 레코드의 모든 컬럼을 저장할 경우, 하나의 레코드가 변경되면 모든 인덱스에 변경 사항을 반영해야 한다. 이로 인해 성능에 큰 영향을 미칠 수 있다. 따라서 Non-Clustered Index는 PK를 통해 레코드 위치만 참조하도록 설계되었으며, 이 방식은 변경 작업 시 인덱스 유지 비용을 줄이는 데 유리하다.
Index Range Scan
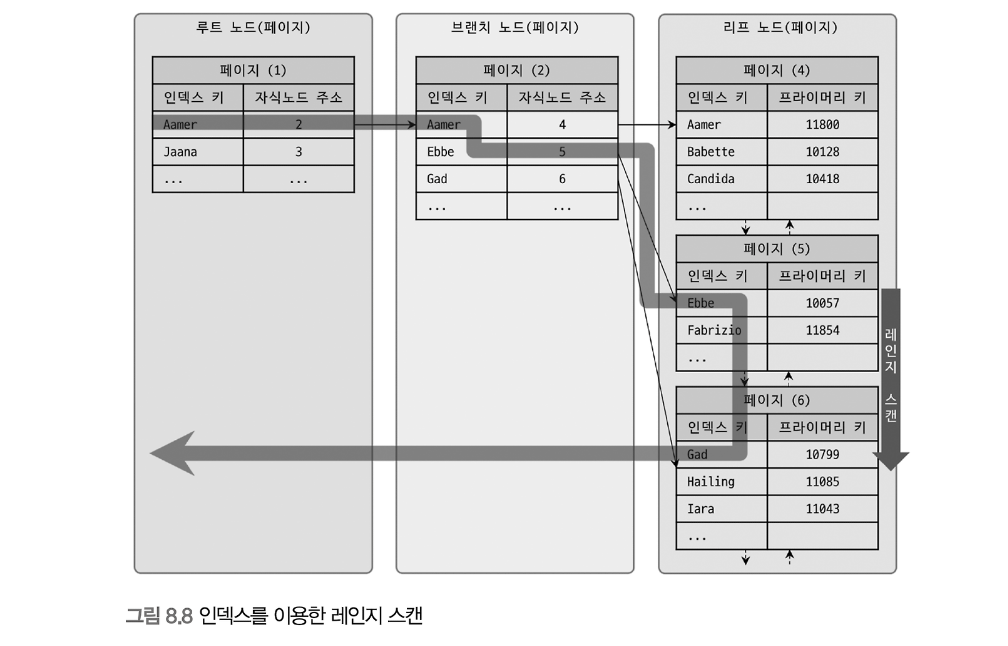
일반적으로 인덱스를 사용한다면 Index Range Scan을 사용하게 된다. 이는 인덱스를 이용해 특정 범위의 데이터를 탐색하는 방식이다.
- Index Range Scan을 사용하지 않을 때가 있는데?
Index Range Scan은 레코드를 읽을 때 랜덤 I/O가 발생하기 때문에 데이터베이스는 이를 피하려고 한다. 일반적으로 쿼리에서 20% 이상의 데이터를 읽어야 하는 경우, 인덱스를 사용하는 대신 Full Table Scan을 수행하는 것이 더 효율적일 수 있다. 이는 인덱스를 통해 레코드를 찾는 과정에서 발생하는 랜덤 I/O보다, 테이블 전체를 순차적으로 읽는 방식이 더 빠르기 때문이다.
Index Full Scan
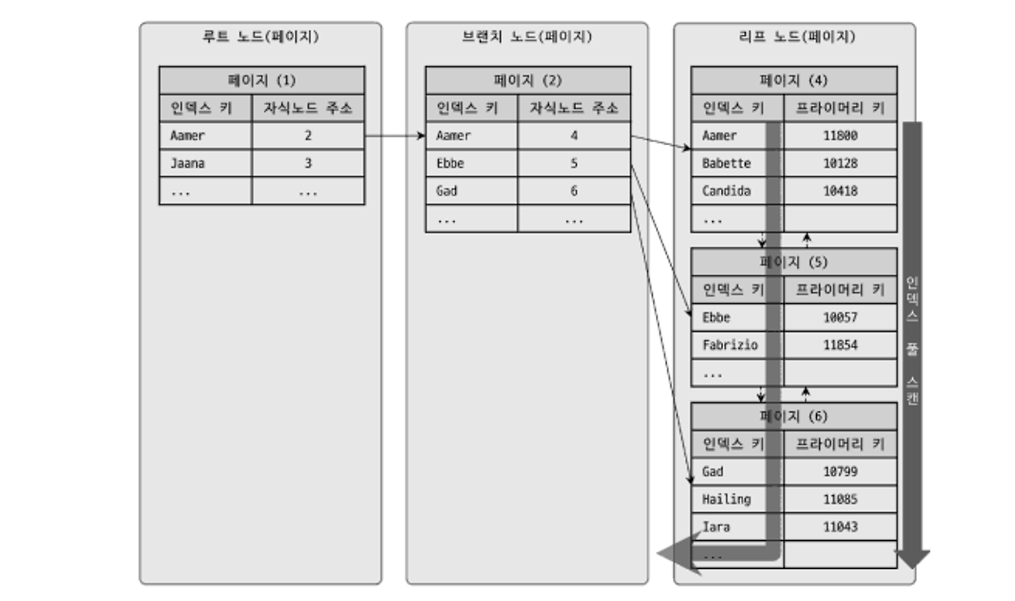
인덱스를 처음부터 끝까지 읽는 방식이다.
- 이걸 언제 쓰지?
테이블을 읽는 것보다 인덱스를 읽는 게 더 빠르다고 판단될 때 사용한다. 쿼리의 조건절에 사용된 컬럼이 인덱스의 첫 번째 컬럼이 아닐 경우, Index Full Scan을 수행해 인덱스를 이용해 데이터를 검색한다. 또한, 인덱스만으로 쿼리를 해결할 수 있는 경우에도 Index Full Scan이 유리할 수 있다.
커버링 인덱스
간단히 말해 인덱스만으로 쿼리를 해결하므로 테이블 접근을 하지 않는 것이다. 예를 들어, 쿼리에서 필요한 모든 컬럼이 인덱스에 포함되어 있다면, 인덱스를 통해 바로 데이터를 조회하고 테이블에 접근할 필요가 없다.
- 내가 설정한 Non-Clustered Index에 PK가 포함되지 않았는데?
앞에서 설명한 대로 Non-Clustered Index는 기본적으로 클러스터링 인덱스를 사용해 실제 레코드에 접근한다. Non-Clustered Index에는 레코드의 위치 정보가 포함되어 있지 않기 때문에, 검색한 후 실제 데이터를 가져오려면 클러스터링 인덱스를 통해 접근해야 한다. 이로 인해 Non-Clustered Index를 설정할 때, PK가 포함되지 않은 인덱스라도 PK는 기본적으로 제공된다.
커버링 인덱스는 실제 테이블에 접근하지 않는 다는 점에서 데이터베이스가 굉장히 좋아할만한 인덱스이다.
5. MySQL
- 쿼리 캐시
- MySQL 8.0으로 올라오면서 쿼리 캐시는 MySQL 서버의 기능에서 완전히 제거되고, 관련된 시스템 변수도 모두 제거 됐다.
- 프라이머리 키에 의한 클러스터링
- InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 저장된다. 즉, 프라 이머리 키 값의 순서대로 디스크에 저장된다는 뜻이며, 모든 세컨더리 인덱스는 레코드의 주소 대신 프 라이머리 키의 값을 논리적인 주소로 사용한다.
- 프라이머리 키가 클러스터링 인덱스이기 때문에 프라 이머리 키를 이용한 레인지 스캔은 상당히 빨리 처리될 수 있다. 결과적으로 쿼리의 실행 계획에서 프라이머리 키는 기본적으로 다른 보조 인덱스에 비해 비중이 높게 설정된다.
- 자동 데드락 감지
- InnoDB 스토리지 엔진은 데드락 감지 스레드를 가지 고 있어서 데드락 감지 스레드가 주기적으로 잠금 대기 그래프를 검사해 교착 상태에 빠진 트랜잭션들 을 찾아서 그중 하나를 강제 종료한다.
- 이때 어느 트랜잭션을 먼저 강제 종료할 것인지를 판단하는 기 준은 트랜잭션의 언두 로그 양이며, 언두 로그 레코드를 더 적게 가진 트랜잭션이 일반적으로 롤백의 대상이 된다. 트랜잭션이 언두 레코드를 적게 가졌다는 이야기는 롤백을 해도 언두 처리를 해야 할 내 용이 적다는 것이며, 트랜잭션 강제 롤백으로 인한 MySQL 서버의 부하도 덜 유발하기 때문이다.
- InnoDB 버퍼 풀
- 운영체제의 전체 메모리 공간이 8GB 미만이라면 50% 정도만 InnoDB 버퍼 풀로 설정하고 나머지 메모리 공간은 MysQL 서버와 운영체제, 그리고 다른 프로그램이 사용할 수 있는 공간으로 확보해주는 것이 좋다.
- 전체 메모리 공간이 그 이상이라면 InnoDB 버퍼 풀의 크기를 전체 메모리의 50%에서 시작해서 조금씩 올려가면서 최적점을 찾는다. 운영체제의 전체 메모리 공간이 50GB 이상이라면, 대략 15GB에서 30GB 정도 를 운영체제와 다른 응용 프로그램을 위해서 남겨두고 나머지를 InnoDB 버퍼 풀로 할당하자.
- 버퍼 풀과 리두 로그
- MysQL 서버를 포함한 대부분 데이터베이스 서버는 데이터 변경 내용을 로그로 먼저 기록한다. 거의 모든 DBMS에서 데이터 파일은 쓰기보다 읽기 성능을 고려한 자료 구조를 가지고 있기 때문에 데이터 파일 쓰기는 디스크의 랜덤 액세스가 필요하다. 그래서 변경된 데이터를 데이터 파일에 기록하려면 상 대적으로 큰 비용이 필요하다. 이로 인한 성능 저하를 막기 위해 데이터베이스 서버는 쓰기 비용이 낮은 자료 구조를 가진 리두 로그를 가지고 있으며, 비정상 종료가 발생하면 리두 로그의 내용을 이용해 데이터 파일을 다시 서버가 종료되기 직전의 상태로 복구한다.
- 처음부터 리두 로그 파일의 크기를 적절히 선택하기 어렵다면 버퍼 풀의 크기가 100GB 이하의 MySQL 서버에서는 리두 로그 파일의 전체 크기를 대략 5~10GB 수준으로 선택하고 필요할 때마다 조금씩 늘려가면서 최적값을 선택하는 것이 좋다.
- Dobule Write Buffer
- DoubleWrite buffer에 더티 페이지를 작성함으로써, 데이터 파일 쓰기 중간에 실패할 때(비정상 종료) 해당 버퍼의 내용과 file의 page들의 내용을 비교하여 안정성과 무결성을 높인다.
- 언제써야 하는가? OS 에서 처리하는 페이지 단위(4KB or 8KB)와 InnoDB 의 페이지 단위(16KB) 처리가 다른 경우 중간에 OS crash 가 발생하면 여러 물리 페이지에 나눠서 써지다가 중간에 잘리는 문제가 발생한다. 대부분의 file system 의 default block size 가 4KB 이다.
- 이름은 버퍼이나 Doublewrite Buffer 는 메모리가 아니라 데이터 파일
- 체인지 버퍼
- InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행하지만 그렇지 않고 디스크로부터 읽어와서 업데이트해야 한다면 이를 즉시 실행하지 않고 임시 공간에 저장 해 두고 바로 사용자에게 결과를 반환하는 형태로 성능을 향상시키게 되는데, 이때 사용하는 임시 메모 리 공간을 체인지 버퍼(Change Buffer)라고 한다.
- 사용자에게 결과를 전달하기 전에 반드시 중복 여부를 체크해야 하는 유니크 인덱스는 체인지 버퍼를 사용할 수 없다.
- 체인지 버퍼에 임시로 저장된 인덱스 레코드 조각은 이후 백그라운드 스레드에 의해 병합되는데, 이 스레드를 체인지 버퍼 머지 스레드(Merge thread)라고 한다.
- 리드 어헤드
- 리드 어헤드는 데이터베이스 시스템이 성능을 최적화하기 위해 사용하는 기술 중 하나이다. 이 기술은 시스템이 앞으로 필요할 데이터를 미리 예측하여 메모리로 읽어들이는 방식이다. MySQL InnoDB에서도 리드 어헤드 기능을 사용하여 디스크 I/O 성능을 개선한다.
- 순차 접근 패턴 감지: 데이터베이스가 순차적으로 데이터를 접근하는 패턴을 감지한다. 예를 들어, 대량의 데이터를 순차적으로 읽는 쿼리나 테이블 스캔 등이 있을 때 이를 인지한다.
- 미리 읽기: 순차 접근 패턴이 감지되면, 데이터베이스는 앞으로 필요할 것으로 예상되는 데이터 페이지들을 미리 디스크에서 읽어와 버퍼 풀에 적재한다.
- 디스크 I/O 최소화: 이렇게 미리 데이터를 읽어 놓으면, 실제로 쿼리가 해당 데이터를 필요로 할 때 디스크에 접근하는 시간을 줄일 수 있다. 이는 디스크 I/O를 최소화하고 쿼리 성능을 향상시키는 효과가 있다.
- 리드 어헤드는 데이터베이스 시스템이 성능을 최적화하기 위해 사용하는 기술 중 하나이다. 이 기술은 시스템이 앞으로 필요할 데이터를 미리 예측하여 메모리로 읽어들이는 방식이다. MySQL InnoDB에서도 리드 어헤드 기능을 사용하여 디스크 I/O 성능을 개선한다.
- 언두 로그 모니터링
- MySQL 서버에서 INSERT 문장으로 인한 언두 로그와 UPDATE(DELETE 포함) 문장으로 인한 언두 로그는 별 도로 관리된다. UPDATE와 DELETE 문장으로 인한 언두 로그는 MVCC와 데이터 복구(롤백 포함)에 모두 사용되지만, INSERT 문장으로 인한 언두 로그는 MVCC를 위해서는 사용되지 않고 롤백이나 데이터 복구만을 위해서 사용되기 때문이다.
- 소트버퍼
- MySQL에서 정렬을 수행하기 위해 만들어둔 메모리 공간이다.
- 소트 버퍼의 크기가 너무 크면 동시 접속이 잦은 환경에서 운영체제는 메모리 부족 현상을 겪을 수 있다.
- 정렬 처리 방법
- 인덱스를 이용한 정렬
- 인덱스를 이용하려면 먼저 ORDER BY 에 명시된 컬럼이 제일 먼저 읽는 테이블(조인을 한다면)에 속해야 한다. 또한, ORDER BY의 순서대로 생성된 인덱스가 있어야 한다.
- 조인을 하더라도 네스티드 루프 방식으로 실행되기 때문에 조인으로 인해 순서가 흐트러지지 않는다.
- 조인의 드라이빙 테이블만 정렬
- 인덱스를 이용하려면 먼저 ORDER BY 에 명시된 컬럼이 제일 먼저 읽는 테이블(조인을 한다면)에 속해야 한다.
- 일반적으로 조인이 수행되고 나면 레코드 수가 꽤나 증가한다. 따라서 조인을 실행하기 전에 첫 번째 테이블의 레코드를 먼저 정렬한 다음 조인을 실행하는 것이 정렬의 차선책이다.
- 임시 테이블을 이용한 정렬
- 하나의 테이블만을 정렬하거나 9.2.3.3.2와 같이 2개 이상의 테이블을 조인하더라도 드라이빙 테이블만 정렬하여 처리할 수 있는 경우는 임시 테이블이 필요하지 않다.
- 하지만 그 외 패턴의 쿼리에서는 항상 조인의 결과를 임시 테이블에 저장하고 그 결과를 다시 정렬하는 과정을 거친다.
- 이 방법은 가장 느린 정렬 방법이다.
- 인덱스를 이용한 정렬
- 정렬 처리 방법의 성능 비교
- 스트리밍 방식: 서버 쪽에서 레코드가 검색될 때마다 바로바로 클라이언트로 결과를 전송해주는 방식이다. 이 방식에서는 limit 제한을 걸면 처리량을 줄이고 마지막 레코드를 가져오는 시간을 줄일 수 있다.
- MySQL JDBC 드라이버(Connector/J)는 기본적으로 서버의 스트리밍 결과를 소켓 버퍼에 일괄 수신 후, 클라이언트 메모리에 저장(buffering) 한다.
- 개발자 입장에서는
while (rs.next())루프가 즉시 가능한 것처럼 보이지만, 사실상 드라이버 내부에서 데이터를 이미 다 받아둔 상태일 수 있다.
- 진짜 스트리밍(행 단위 전송)을 원한다면
stmt.setFetchSize(Integer.MIN_VALUE)설정으로 서버 커서 기반 스트리밍 모드를 활성화해야 한다.
- 이 모드에서는 JDBC가 버퍼에 데이터를 모아두지 않고,
ResultSet.next()호출 시마다 소켓에서 한 행씩 바로 읽는다.
- MySQL JDBC 드라이버(Connector/J)는 기본적으로 서버의 스트리밍 결과를 소켓 버퍼에 일괄 수신 후, 클라이언트 메모리에 저장(buffering) 한다.
- 버퍼링 방식: 데이터를 스캔할 때 order by나 group by를 걸면 스트리밍이 불가능하다. where 조건에 만족하는 모든 레코드를 가져와서 정렬하거나 그루핑해서 차례로 응답을 보내야한다. 즉 결과를 모아서 일괄 가공해야 하므로 limit과 같은 결과 건수를 제한하는 조건은 성능 향상에 도움이 되지 않는다.
- 서버가 정렬 결과를 한꺼번에 보낸다면, JDBC는 이를 소켓 수신 버퍼에 전부 담은 뒤, 다시 내부 메모리에 캐싱한다.
- 즉, 서버와 클라이언트 모두 “버퍼링”이 일어나며 대용량 정렬 결과일수록 네트워크·메모리 부담이 커진다.
- 이 경우
fetchSize나 스트리밍 모드 설정을 해도 서버 쪽에서 이미 전체 정렬을 끝내야 하기 때문에 네트워크 레벨 스트리밍 이점은 없다.
- order by 처리방식 중에서 인덱스를 이용한 정렬 방식만 스트리밍 형태의 처리이고 나머지는 모두 버퍼링 방식이다.
- 스트리밍 방식: 서버 쪽에서 레코드가 검색될 때마다 바로바로 클라이언트로 결과를 전송해주는 방식이다. 이 방식에서는 limit 제한을 걸면 처리량을 줄이고 마지막 레코드를 가져오는 시간을 줄일 수 있다.
- 내부 임시 테이블 활용
- MySQL이 ORDER BY, GROUP BY, DISTINCT, UNION, 서브쿼리 같은 연산을 처리하기 위해 엔진 내부에서 자동으로 생성하는 메모리/디스크 임시 저장소다.
- 기본은 메모리(TempTable 엔진)에서 처리되지만, 데이터 크기가 커지거나 긴 문자열이 포함되면자동으로 디스크 기반 임시 테이블(Using temporary)로 전환된다.
- 레플리케이션 동작 과정
- 이 때, 레플리카 서버의 I/O 쓰레드와 SQL 쓰레드는 서로 독립적으로 동작한다. SQL 쓰레드가 느리게 데이터를 반영한다고, I/O 쓰레드가 소스 서버로부터 이벤트를 읽어오는데에는 영향을 주지 않는다.
- 또, 레플리카 서버가 소스 서버의 변경 내역을 반영하는게, 소스 서버와 독립적으로 동작한다. 따라서 레플리카 서버에 문제가 생기더라도 소스 서버는 그 영향을 받지 않는다.
- 단, 소스 서버에 문제가 생기면 그 즉시 레플리카 서버에 에러가 발생하고 복제가 중단된다. 하지만 이때에도 복제만 중단된 것이므로 레플리카 서버에서 쿼리는 정상적으로 실행할 수 있다. 다만 이때에는 레플리카 서버는 과거의 데이터를 가지고 있을 수 있으므로, 즉 정합성이 깨져있는 상태이므로 주의해야한다.
- 글로벌 트랜잭션 ID 기반 복제
- 바이너리 로그 파일 위치 기반 복제에서는 같은 이벤트라고 하더라도 서로 식별 값이 다르다고 했다. 레플리카(전 레플리카B)는
binary-log.000002:120까지 동기화 되어 있다는 정보를 가지고 있지만, 이는 새로운 소스 서버에는 유효하지 않다. 따라서 이 레플리카는 동기화할 수 없다. - 물론 새로운 소스 서버의 릴레이 로그가 살아있다면, 이 릴레이 로그에 남아있는 (전) 소스 서버의 바이너리 로그 정보를 가져와서 복구할 수 있다. 하지만 릴레이 로그는 불필요한 시점에 자동 삭제되므로 이 방법은 제한적이다. 수동으로 직접 확인하는 방법도 있지만 당연하게도 매우 어렵다.
- 레플리케이션에 참여하고 있는 모든 서버들이 이벤트에 대해 동일한 식별자를 가지도록 하는 방식이 글로벌 트랜잭션 ID 기반 복제이다. 그리고 이때 이벤트에 부여된 식별자를 GTID(Global Transaction IDentifier)라고 한다. GTID는 MySQL 5.6에서 처음 도입되었다.
- 바이너리 로그 파일 위치 기반 복제에서는 같은 이벤트라고 하더라도 서로 식별 값이 다르다고 했다. 레플리카(전 레플리카B)는
- 복제 지연(Replication Lag)
- 복제 지연은 원본(Source) 의 트랜잭션 커밋 시점과 복제본(Replica) 이 이를 실제로 반영한 시점의 차이를 뜻한다.
- 주된 원인은 SQL 스레드의 처리 속도 저하이며, 대용량 트랜잭션·락 경합·디스크 I/O 병목 등으로 relay log를 제때 처리하지 못할 때 발생한다.
- 지연은 원인이 해결되면 자동으로 빠르게 복구되므로, “지연 시간 수치”보다는 병목의 원인을 해결하는 것이 핵심이다.
- 복제 지연의 원인
- 트랜잭션 처리량 초과: 복제본의 SQL 스레드가 원본보다 느릴 때 발생한다.
- 장애 후 재구축: 오프라인 동안 쌓인 binlog 이벤트를 따라잡는 과정에서 지연이 커진다.
- 네트워크 지연: binlog 이벤트 전송 지연 또는 패킷 손실이 발생할 수 있다.
- 복제 지연의 위험 (데이터 손실)
- 비동기 복제에서는 원본이 커밋 즉시 응답하기 때문에, 복제본이 아직 이벤트를 받지 못한 상태에서 장애가 발생하면 커밋된 트랜잭션이 유실된다.
- 복제 지연이 10초라면, 최근 10초 동안의 트랜잭션이 사라질 수 있음을 의미한다.
- 반동기 복제를 사용하면, 최소 1대의 복제본이 릴레이 로그에 기록(ACK)할 때까지 원본이 커밋을 대기하므로 데이터 손실 위험을 크게 줄일 수 있다.
- 반동기 복제(Semi-Synchronous Replication)
- 원본은 binlog를 복제본 여러 대에 동시에 전송하지만, 최소 한 대(기본값) 가 릴레이 로그에 기록했다고 ACK 응답하기 전까지 커밋을 완료하지 않는다.
- 이 방식은 비동기보다 느리지만, 데이터 손실 가능성을 거의 0 으로 낮춘다.
- 대기 복제본 수(
rpl_semi_sync_master_wait_for_slave_count)를 늘리면 안정성은 높아지지만, 네트워크 지연에 따라 커밋 속도는 느려진다. - 지연을 최소화하기 위해 보통 동일 리전 내 인스턴스 간 반동기 구성을 사용한다.
- 병렬 복제(Parallel Replication)
- 복제본의 단일 SQL 스레드 병목을 해결하기 위해 MySQL 5.7 이상에서는 여러 SQL Worker 스레드가 동시에 relay log를 적용할 수 있다.
- 트랜잭션 간 의존성을 추적(
LOGICAL_CLOCK,WRITESET)하여 커밋 순서를 유지하면서 병렬 적용한다. - 이를 통해 복제본의 처리량을 2배 이상 향상시키고, 복제 지연을 크게 줄일 수 있다.
- 복제 모니터링
Seconds_Behind_Source: 복제본이 처리 중인 binlog 이벤트의 타임스탬프와 현재 시각의 차이를 의미하지만, 실시간 반영이 아니므로 정확하지 않을 수 있다.pt-heartbeat도구를 사용하면 일정한 주기로 타임스탬프를 기록하여 일관된 복제 지연 측정이 가능하다.- AWS Aurora MySQL에서는
aws_rds_mysql_aurora_binlog_replica_lag_average메트릭으로 복제 지연을 초 단위로 모니터링할 수 있다.
- 복제 지연 복구의 특성
- 지연이 증가하는 동안은 relay log에 backlog가 쌓이지만, 원인이 해결되면 SQL 스레드가 I/O 스레드보다 빠르게 이벤트를 처리하여 지연이 급격히 감소한다.
- 복제 지연 값 자체보다 원인(락, 병목, 대용량 트랜잭션) 을 해결하는 것이 우선이다.
- 복제는 항상 이벤트 기반으로 동작하므로, 시간이 걸릴 뿐 항상 복구된다.
- 트랜잭션 처리량 한계와 샤딩(Sharding)
- 복제 구조는 읽기 부하를 분산할 수 있지만, 쓰기 부하는 원본(Writer) 한 대에 집중되므로 트랜잭션 처리량의 절대 한계가 존재한다.
- CPU, I/O, 버퍼풀 튜닝으로도 개선되지 않는다면 단일 인스턴스 한계를 초과한 것이다.
- 데이터를 여러 인스턴스로 분할(샤딩)하여 여러 Writer가 병렬로 트랜잭션을 처리하도록 해야 한다.
- 샤딩은 쓰기 부하를 수평으로 분산해 처리량을 확장하는 궁극적인 단계이며, 복제 지연 문제를 구조적으로 완화하는 근본적인 방법이다.
- MySQL 레플리케이션 토폴로지
- 싱글 레플리카 복제 구성: 가장 기본적인 형태이며 가장 많이 쓰이는 형태이다. 싱글 레플리카 복제 구성에서 웹 서버가 레플리카 서버에 읽기 요청을 전달하면, 레플리카 서버에 문제가 발생했을 때 서비스 장애 상황이 발생할 수 있다. 따라서 일반적으로 소스 서버가 읽기/쓰기 연산을 모두 처리하며, 레플리카는 예비용 서버로 활용한다. 예비용 서버란, 소스 서버가 장애가 발생했을 때 소스 서버를 대체하거나 및 데이터 백업을 할 수 있는 서버를 말한다.
- 멀티 레플리카 복제 구성: 웹 서버가 레플리카 서버로 읽기 요청을 보내는 순간, 레플리카 서버는 소스 서버만큼 중요해진다. 이야기했듯, 레플리카 서버가 장애가 발생하면 서비스에도 장애가 발생하기 때문이다. 이런 상황을 대비하기 위해 백업 등 제한적인 용도로 활용되는 예비 레플리카 하나는 확보해두는게 좋다. 이 서버는 소스 서버의 대체 서버 겸 다른 레플리카 서버의 대체 서버로 활용된다.
- 듀얼 소스 복제 구성: 두 개의 데이터베이스 서버가 서로의 소스 서버이자 레플리카 서버인 구성이다. Active-Passive 구성과 Active-Active 구성으로 나뉜다.
- Active-Passive는 하나의 서버로만 읽기/쓰기 요청이 전달되고, 나머지 하나의 서버는 켜져있는 상태로 대기하는 형태이다. 두 서버가 모두 소스 서버이므로 언제든 쓰기 작업이 가능한 형태이다. 따라서 장애 발생 시 별다른 설정 없이 바로 Passive 서버로 전환하여 Failover할 수 있다.
- Active-Active는 지리적으로 매우 떨어진 위치에서 유입되는 쓰기 요청도 원활히 수행하기 위해 사용한다. 다만, 서로의 트랜잭션이 동기화 되기 전까지는 정합성이 깨질 수 있으므로 주의해야한다.
- Active-Active 구성에서의 주의점
- 첫번째로, 동시에 같은 데이터에 대해 쓰기 작업을 수행할 때이다. 하나의 데이터베이스를 사용하면 동일한 데이터에 대한 동시에 발생한 두 요청은 잠금 경합으로 인하여 순차적으로 처리된다. 하지만 Active-Active 구성에서 동일한 데이터에 대한 변경 트랜잭션이 각 서버로 동시에 유입되면 예상치 못한 결과가 나올 수 있다. 마지막 트랜잭션이 최종적으로 반영되기 때문이다.
- 두번째로, Auto-Increment 키를 사용할 때이다. 새로운 데이터가 동시점에 각 서버에 유입되었을 때 같은 Auto-Increment 키가 생성될 수 있다. 이로 인한 중복 키 에러가 발생할 수 있다. 따라서 Active-Active 구성에서는 Auto-Increment 사용을 지양하고 애플리케이션 단에서 유일하고 글로벌한 값을 생성하는 것이 좋다.
- 듀얼 소스 복제 구성은 사실 쓰기 성능을 개선하는 용도로는 그다지 효과적이지는 않다. 서로의 쓰기 요청을 자신의 데이터베이스에 반영하는 작업이 발생하기 때문이다. 오히려 두 서버간 트랜잭션 충돌로 인한 롤백이나 복제 멈춤 현상으로 인한 역효과가 많다. 따라서 쓰기 성능을 개선하고 싶다면 샤딩(sharding)을 권장한다.
- InnoDB Cluster
- Master(Source) - Replica 구조의 복제만으로는 고가용성이나 서비스 영속성을 충분히 구현하기 어렵다. MySQL 복제 기능 자체에는 HA 기능이나 Failover 기능이 포함되어 있지 않기 때문에, Master(Source) 인스턴스에 장애가 발생하면 관리자가 수동으로 복구나 Failover를 수행해야 한다. 또한 다중 Replica 노드에 대한 부하 분산 역시 별도의 네트워크 장비나 솔루션, 혹은 기타 아키텍처적 접근이 필요하다.
- InnoDB Cluster는 이름 그대로 MySQL에서 제공하는 여러 스토리지 엔진 중 InnoDB 엔진에서만 지원되는 기능이다. 그룹 복제를 활용하기 위해서는 최소 3대 이상의 서버가 필요하다.
- MySQL Group Replication: MySQL 인스턴스의 고가용성을 보장하는 기능으로, InnoDB Cluster는 이를 보다 쉽게 활용할 수 있는 프로그래밍적 대안을 제공한다. 단순 복제 역할뿐 아니라 복제에 참여하는 멤버 관리 기능도 포함한다.
- MySQL Router: 애플리케이션과 InnoDB Cluster 사이에서 투명한 라우팅을 제공하는 경량 미들웨어다. 이는 클라이언트나 애플리케이션에서 전달된 쿼리를 MySQL 서버로 중개하는 프록시(Proxy) 역할을 수행한다.
- MySQL Shell: MySQL 용 고급 클라이언트 및 코드 편집기
Off The Record
개인적으로는 PostgreSQL을 더 선호한다. 여러 문제를 고유한 방식으로 해결하려는 접근이 개발자로서 감탄을 자아내기 때문이다. 다재다능한 PostgreSQL...
하지만 단순 CRUD 쿼리에서 MySQL이 뛰어난 성능을 보여주고, 참고 자료가 많다는 점을 고려하면 학생 수준의 프로젝트에서는 MySQL을 사용하는 것이 더 적절하다고 생각한다.
그래도 돌고래 보다는 코끼리지
