
이번 게시글에서는 MongoDB를 공부하며 흥미롭게 접한 내용을 정리하고자 한다. 흔히 볼 수 있는 내용보다는 흥미로운 사실들만 모아 작성했으므로, 다소 가독성이 떨어질 수 있다.
1. 아키텍처
MongoDB는 애초에 데이터베이스의 확장 문제를 해결하기 위해 분산 확장을 염두에 두고 설계 됐다.
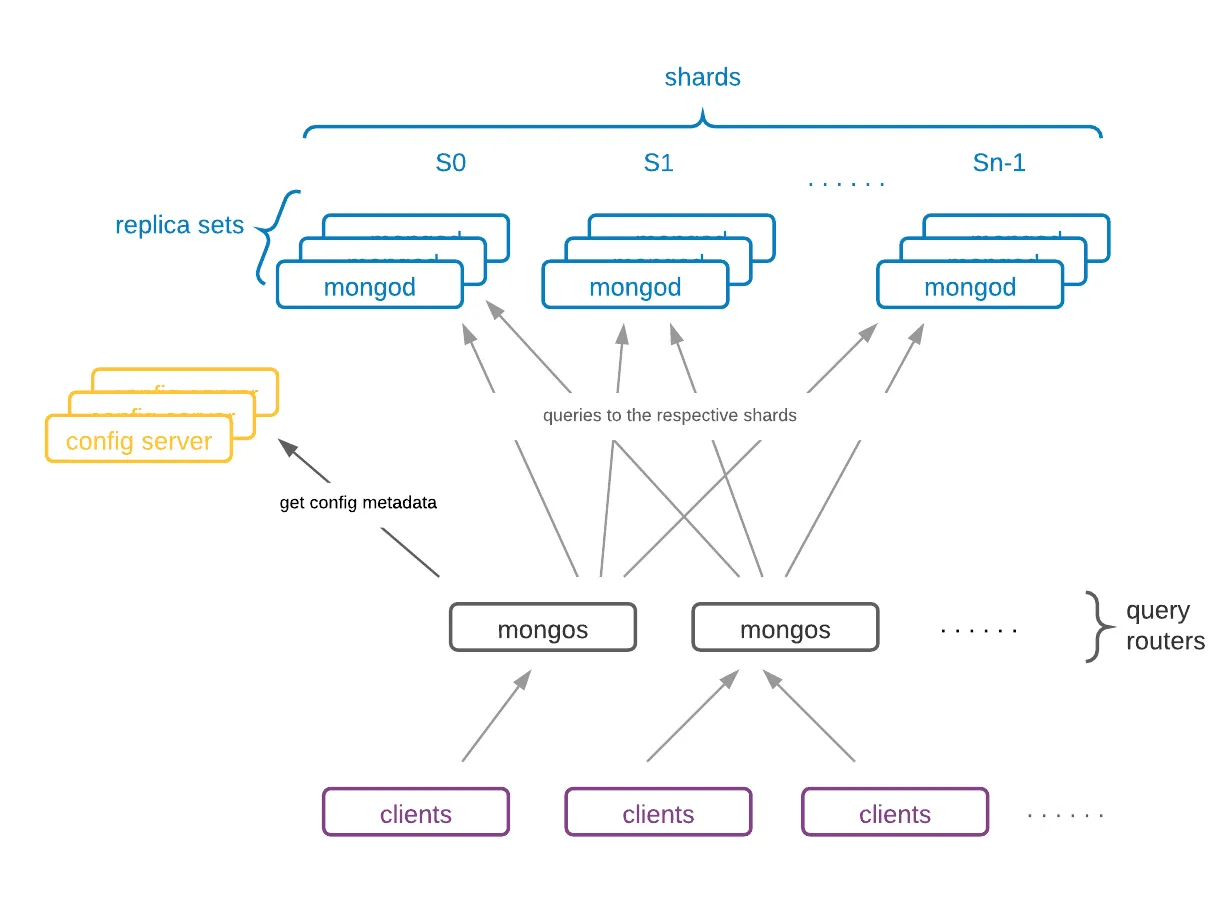
- mongos는 MongoDB 샤딩 아키텍처에서 라우터 역할을 담당한다.
- config 서버는 키 범위와 클러스터 구성 등 메타데이터를 저장하고 관리한다. 이 서버는 홀수 개로 구성하는 것이 권장된다.
- mongod 인스턴스는 독립적으로 작동하며 데이터 저장, 인덱싱, 쿼리 처리, 복제 등을 수행한다.
-
왜 config 서버를 홀수 개(3개 이상)로 구성해야 할까?
그만큼 config 서버가 중요하다는 것으로 이해하면 될 것 같다. config 서버는 클러스터 구성을 유지하는 역할을 한다. 3중화 구성을 통해 서버 하나가 다운되더라도 나머지 서버가 설정 정보를 보유해 클러스터 운영을 지속할 수 있도록 한다. 또한 홀수 개로 구성하는 이유는 마스터 DB가 다운되었을 때, Config 서버 간의 투표를 통해 다수결로 새로운 마스터를 선정하고 페일오버를 실행할 수 있기 때문이다.
-
MongoDB의 암흑기?
MongoDB는 MySQL처럼 Plugin 형태로 Storage Engine을 제공하며 교체가 가능하다. 초기에는 WiredTiger가 아닌 MMAPv1 엔진을 기본으로 사용했으나, 3.2 버전부터 WiredTiger가 기본 Storage Engine이 되면서 성능과 안정성이 크게 개선되었다.
2. 인덱스
MongoDB를 다른 NoSQL 대신 선택하는 이유를 묻는다면, 대부분 다양한 형태의 인덱스를 제공하기 때문이라고 답할 것이다. 다른 블로그에서 흔히 볼 수 있는 내용은 제외하고, 궁금했던 몇 가지를 정리해보자.
-
제약 조건?
MongoDB는 데이터 삽입 시 _id 필드가 존재하는지, 16MB보다 작은지 등 최소한의 조건만 검사할 정도로 성능에 미쳐있다. 때문에 RDBMS에서 제공하는 제약 조건이 MongoDB에서는 주로 인덱스 형태로 제공된다.
-
인덱스를 선택하는 방법?
MongoDB는 인덱스를 굉장히 특이하게 선택한다. 간단하게 이야기해서 병렬 스레드에서 쿼리를 직접 실행해보고 가장 빨리 반환하는 인덱스를 선택한다. 그리고 이를 캐시에 저장해서 다음에도 사용한다.
-
정렬 관련 이슈?
MongoDB는 인덱스를 통해 정렬 순서를 지정할 수 있으며, 그렇지 않으면 메모리에서 정렬을 수행한다. 정렬에 사용할 수 있는 메모리는 32MB로 제한되며, 이를 초과하면 예외가 발생한다.
3. 집계 파이프라인
MongoDB의 집계 파이프라인은 데이터 처리 및 분석을 위해 데이터를 여러 단계에 걸쳐 가공하는 데 사용된다. 마찬가지로 이와 관련해 궁금했던 몇 가지를 정리해보자.
-
왜 탄생했을까?
기존의 find 쿼리에 집계 기능을 추가할 수도 있었을 텐데, 왜 별도로 집계 파이프라인이 탄생했을까? 개인적인 생각으로는 Java의 Stream과 비슷한 이유일 것 같다. MongoDB의 복잡한 클러스터 구조에서 내부적인 최적화를 통해 복잡하고 고비용인 연산을 더 효율적으로 처리하기 위한 구조라고 본다.
-
집계 파이프라인이 너무 클 경우
allowDiskUse()옵션을 사용하여 파이프라인에서 100MB를 초과하는 작업이 디스크에 임시 파일을 쓸 수 있게 할 수 있다. MongoDB 6.0부터는 100MB 이상의 메모리가 필요한 작업에서 임시 파일을 자동으로 사용하도록 설정되었다.
4. 트랜잭션
MongoDB는 ACID보다 BASE 속성(Basically Available, Soft State, Eventually Consistent)을 우선시하여 설계되었기 때문에, 다른 SQL 데이터베이스와 비교했을 때 트랜잭션 기능이 제한적이다. MongoDB 트랜잭션과 관련해 궁금했던 몇 가지를 정리해보자.
-
트랜잭션 기능의 제한?
MongoDB는 기본적으로 BASE 아키텍처를 중심으로 설계되었으나, WiredTiger 스토리지 엔진을 통해 트랜잭션 기능을 지원하기 시작했다. WiredTiger는 NoSQL뿐만 아니라 여러 데이터베이스에서 사용할 수 있는 범용 스토리지 엔진으로 다양한 격리 수준(Read Uncommitted, Read Committed, Snapshot)을 제공한다. 하지만 MongoDB는 스냅샷 격리 수준(Repeatable Read)만 고정적으로 지원하며, 이는 사용자가 직접 선택할 수 있는 구조가 아니다.
-
해결된 문제점
4.0 버전 이전에는 MongoDB가 단일 도큐먼트에 대해서만 트랜잭션을 지원했다. 단일 도큐먼트 트랜잭션이 MongoDB 모델에 적합하다는 입장이었으나, 현실에서는 여러 도큐먼트를 사용하는 비즈니스 로직이 늘어나면서 트랜잭션이 필요해졌다. 이에 따라 다중 도큐먼트와 샤딩 환경에서 트랜잭션을 지원하기 시작했다.
-
여전히 남은 문제점
MongoDB에서는 동일한 도큐먼트를 동시에 업데이트하려는 트랜잭션이 발생하면 Write Conflict가 발생할 수 있다. 예를 들어, 트랜잭션 A와 트랜잭션 B가 동일한 도큐먼트를 업데이트하려 할 때, 하나의 트랜잭션이 이미 도큐먼트를 수정 중이라면 나중에 실행된 트랜잭션은 Write Conflict 에러로 인해 롤백된다. 이를 해결하려면 충돌이 발생한 트랜잭션을 재시도해야 한다. 마치, 낙관적 동시성 제어 방식으로 동작하는 것이다. 참고로, Write Conflict 감지 방식은 MVCC를 통해 트랜잭션 버전 정보를 이용한다.
이러한 문제 외에도 트랜잭션에는 기본적으로 60초의 시간 제한이 있으며, 대규모 샤딩 환경에서는 성능 비용이 높아진다는 점을 고려할 때, 성능을 중시하는 MongoDB에서 완벽한 트랜잭션을 추구할수록 본래의 장점이 희석되는 문제가 발생할 수 있다.
Off The Record
Document의 최대 크기가 16MB라는 점, 메모리에서 정렬 시 32MB 제한이 있는 점, 집계 파이프라인에서 100MB 제한이 있는 점, 트랜잭션에는 기본적으로 60초의 시간 제한이 있는 등 MongoDB는 생각보다 제약 조건이 많다.
그러나 이와 같은 제한은 성능과 안정성을 고려한 MongoDB의 설계에 따른 것라고 생각하면 MongoDB는 유연하고 빠른 데이터 스토리지를 만든다는 것에 미쳐있다는 생각이 들정도다. 만약 ACID 트랜잭션이 중요하지 않은 프로젝트라면 MongoDB도 충분히 사용할 만하다고 본다.
무작정 RDBMS vs NoSQL으로 비교하기 보다는 상호보완적인 구조로 같이 사용하는 것이 정신 건강에 이로울 것이라고 생각한다.
