
해당 게시물은 인프런 "Java/Spring 주니어 개발자를 위한 오답노트" 강의를 참고하여 작성한 글 입니다.
1. 스프링 프로젝트에 추상화 적용 과정
스프링 프로젝트를 시작할 때 많은 개발자가 직면하는 결정 중 하나는 추상화 수준을 어느 정도로 가져갈 것인가 하는 것이다. 해당 파트에서는 전체적인 과정을 살펴보며 추상화에 대해서 고민해보겠다.
1-1. 기본 스프링 프로젝트 구조
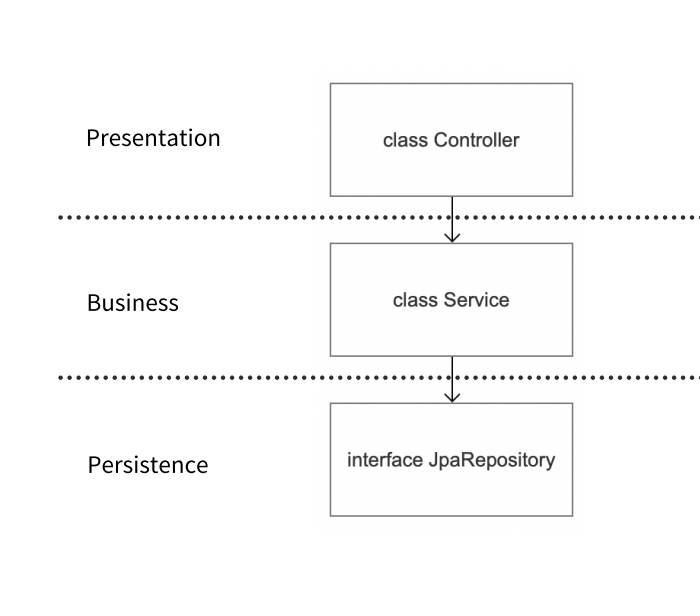
위 그림처럼, 리포지토리가 직접 서비스 계층에 연결되어 있을 때는 리포지토리에 변화가 생기면 서비스 계층에도 영향이 간다. 이는 의존성 관리에 문제를 일으키며, 유연성이 떨어진다.
참고 : https://m.blog.naver.com/seek316/221863498991
1-2. 추상화 적용 후 서비스 계층
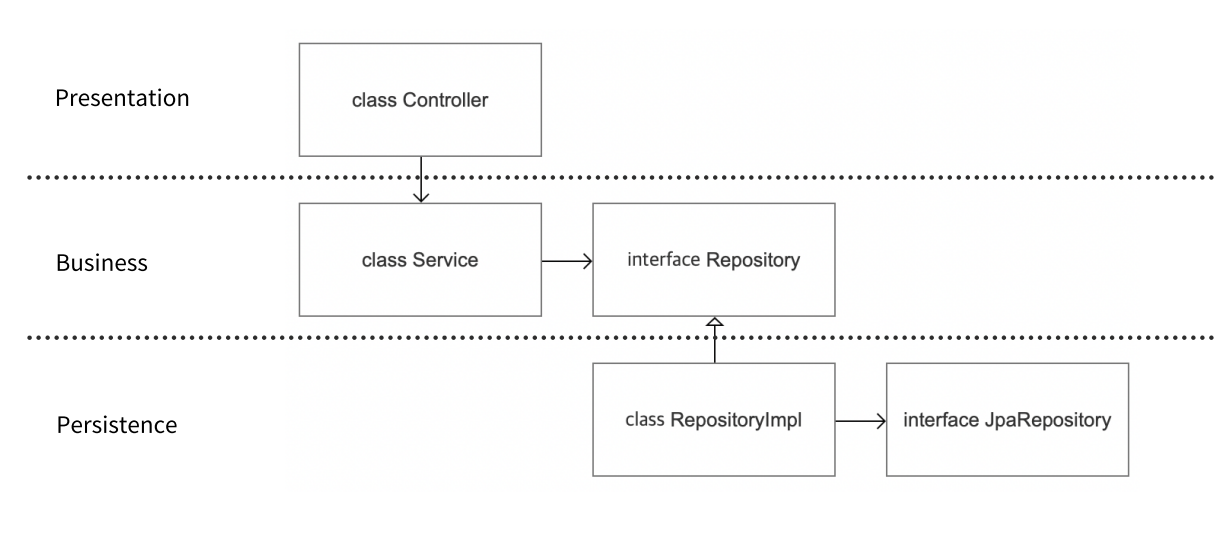
그래서 서비스 계층에 인터페이스를 도입해 추상화를 적용한다. 이렇게 함으로써 리포지토리의 변경사항이 서비스 계층에 영향을 주지 않도록 의존성 역전을 달성할 수 있다. 결과적으로 프로젝트는 변화에 더 민첩하게 대응할 수 있게 되며, 테스트 코드 작성이 한결 수월해진다.
1-3. 서비스 계층의 추상화 여부
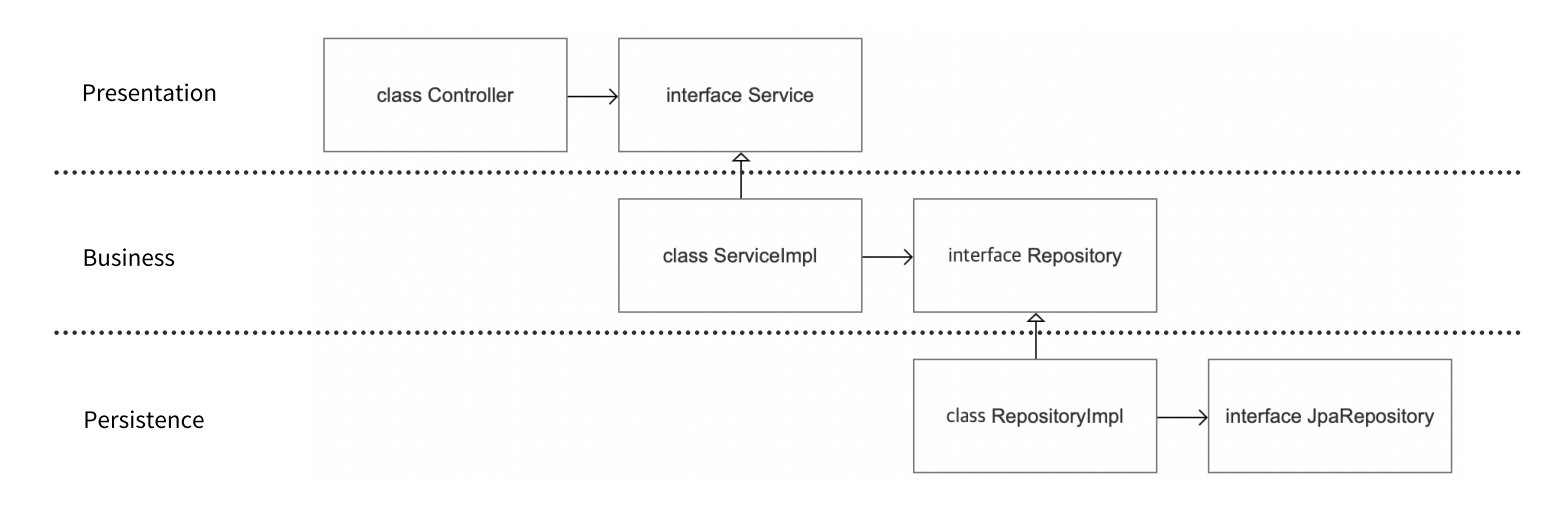
그럼에도 불구하고, 서비스 자체를 추상화할 필요는 없다는 의견도 있다. 서비스와 컨트롤러는 일단 정해지면 변경될 일이 거의 없는 '영속적' 객체이기 때문이다. 이 객체들은 주어진 역할을 계속해서 수행하기 때문에, 추상화를 통해 얻는 이점이 크지 않다.
1-4. 도메인 계층을 이용한 서비스 분리
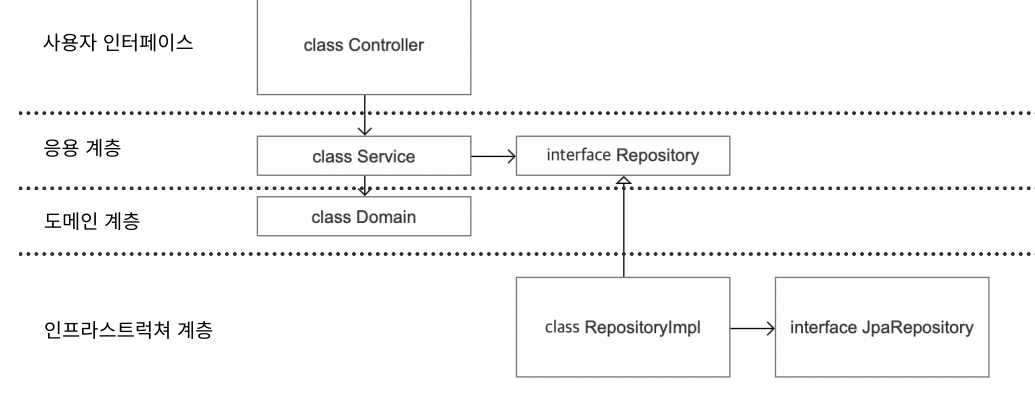
서비스를 도메인 계층으로 분리하면 서비스가 과도한 기능을 담당하지 않게 된다. 도메인 계층에서 각각의 역할과 책임을 분명히 정의하면, 서비스는 더욱 명확하고 관리하기 쉬운 형태로 유지될 수 있다. 이는 테스트 용이성을 높이고, 좋은 설계의 가능성을 향상시키는 방법이다. 테스트하기 좋은 코드가 좋은 설계의 기초가 된다는 점을 감안할 때, 이러한 설계는 좋은 설계라고 생각한다.
2. 프로젝트에 적용 사례
변화에 유연하게 대응하고, 테스트 작성을 용이하게 하기 위해, 프로젝트에서는 의존성을 추상화하는 방법으로 리팩토링을 진행하였다.
2-1. 기존코드
@Service
@Transactional
public class SnackService {
private final SnackRepository snackRepository;
private final WebClient webClient;
public SnackService(SnackRepository snackRepository, @Value("${spring.flask.base-url}") String flaskBaseUrl) {
this.snackRepository = snackRepository;
this.webClient = WebClient.builder()
.baseUrl(flaskBaseUrl)
.build();
}
...
public List<Snack> analyzeSnacks(List<MultipartFile> images) {
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
images.forEach(image -> {
try {
Resource resource = new ByteArrayResource(image.getBytes()) {
@Override
public String getFilename() {
return image.getOriginalFilename();
}
};
body.add("images", resource);
} catch (IOException e) {
throw new ImageReadException(e);
}
});
List<SnackDto> snackDtos = webClient.post()
.uri("/detect")
.contentType(MediaType.MULTIPART_FORM_DATA)
.body(BodyInserters.fromMultipartData(body))
.retrieve()
.bodyToMono(new ParameterizedTypeReference<List<SnackDto>>() {})
.onErrorResume(WebClientRequestException.class, e -> Mono.error(new NullResponseFromApiException()))
.block();
List<Snack> snacks = snackDtos.stream()
.map(dto -> Snack.builder()
.filename(dto.getFilename())
.objectName(dto.getObject_name())
.position(new Position(dto.getPosition().getX1(), dto.getPosition().getX2(), dto.getPosition().getY1(), dto.getPosition().getY2()))
.build())
.collect(Collectors.toList());
snackRepository.saveAll(snacks);
return snacks;
}
}
기존의 SnackService 클래스는 직접 WebClient를 사용하여 외부 API와 통신하는 구조였다. 이러한 접근 방식은 테스트 작성을 복잡하게 만들고, 서비스의 변경에 대응하기 어렵게 만드는 단점이 있었다.
2-3. 의존성 역전을 통한 리팩토링
public interface SnackAnalysisClient {
List<SnackDto> analyzeSnacks(List<MultipartFile> images);
}
...
@Service
public class SnackAnalysisClientImpl implements SnackAnalysisClient {
private final WebClient webClient;
public SnackAnalysisClientImpl(@Value("${spring.flask.base-url}") String flaskBaseUrl) {
this.webClient = WebClient.builder()
.baseUrl(flaskBaseUrl)
.build();
}
@Override
public List<SnackDto> analyzeSnacks(List<MultipartFile> images) {
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
images.forEach(image -> {
try {
Resource resource = new ByteArrayResource(image.getBytes()) {
@Override
public String getFilename() {
return image.getOriginalFilename();
}
};
body.add("images", resource);
} catch (IOException e) {
throw new ImageReadException(e);
}
});
return webClient.post()
.uri("/detect")
.contentType(MediaType.MULTIPART_FORM_DATA)
.body(BodyInserters.fromMultipartData(body))
.retrieve()
.bodyToMono(new ParameterizedTypeReference<List<SnackDto>>() {})
.onErrorResume(WebClientRequestException.class, e -> Mono.error(new NullResponseFromApiException()))
.block();
}
}의존성 역전 원칙을 적용하여, SnackAnalysisClient 인터페이스를 도입함으로써, WebClient 사용 로직을 추상화하였다.
RequiredArgsConstructor
@Service
@Transactional
public class SnackService {
private final SnackRepository snackRepository;
private final SnackAnalysisClient snackAnalysisClient;
...
public List<Snack> analyzeSnacks(List<MultipartFile> images) {
List<SnackDto> snackDtos = snackAnalysisClient.analyzeSnacks(images);
List<Snack> snacks = snackDtos.stream()
.map(dto -> Snack.builder()
.filename(dto.getFilename())
.objectName(dto.getObject_name())
.position(new Position(dto.getPosition().getX1(), dto.getPosition().getX2(), dto.getPosition().getY1(), dto.getPosition().getY2()))
.build())
.collect(Collectors.toList());
snackRepository.saveAll(snacks);
return snacks;
}
}WebClient 구현체를 사용하는 대신, 인터페이스에 정의된 메소드를 통해 외부 API와의 통신 로직을 구현하였다.
이러한 변경을 통해, SnackService는 SnackAnalysisClient 인터페이스에 의존하게 되어, 테스트 작성이 용이해지고, 서비스의 변경에 더 빠르고 유연하게 대응할 수 있게 되었다.
