
0. why?
이전 글에서 굉장히 절망적인 학습 결과를 보여주었다. 해당 문제를 해결하기 위해서 선택한 방법이 바로 이미지 해상도 향상이다. 그래서 이미지 해상도 향상을 위한 모델을 알아보던중 이미지 해상도 향상 모델중 유명한 ESRGAN모델을 이용해보기로 하였다.
1. ESRGAN
ESRGAN은 기존의 SRGAN 모델을 세 가지 주요 측면에서 개선하여 더 높은 품질의 이미지 초고해상도 결과를 달성한다.

- 더 깊은 모델 구조 (RRDB): ESRGAN은 Residual-in-Residual Dense Block(RRDB)을 사용하여 모델을 더 깊게 만듭니다. RRDB는 일반적인 잔차 블록의 개념을 확장한 것으로, 여러 개의 밀집 연결(dense connections)이 있는 잔차 블록을 중첩시킨 구조입니다. 이러한 구조는 모델이 더 복잡한 특징을 학습할 수 있게 하며, 배치 정규화(batch normalization) 계층을 제거함으로써 훈련 중 발생할 수 있는 아티팩트를 줄입니다.
- Relativistic average GAN의 적용: ESRGAN은 기존의 GAN(Generative Adversarial Network) 대신 Relativistic average GAN을 사용합니다. 이는 생성자(generator)와 판별자(discriminator) 간의 경쟁을 더 안정적이고 효과적으로 만들어 줍니다. Relativistic GAN은 판별자가 단순히 '진짜' 또는 '가짜' 이미지를 구분하는 대신, '진짜' 이미지가 '가짜' 이미지보다 더 진짜처럼 보이는지를 평가하도록 합니다. 이는 결과 이미지의 질을 향상시키는 데 도움을 줍니다.
- 인지적 손실의 개선: ESRGAN은 활성화 함수(activation function) 이전의 특징을 사용하여 인지적 손실(perceptual loss)을 개선합니다. 인지적 손실은 생성된 이미지가 인간의 시각적 인식과 얼마나 일치하는지를 측정하는 데 사용됩니다. 이러한 접근 방식은 텍스처와 같은 세부적인 이미지 특징을 보존하는 데 도움을 줍니다.
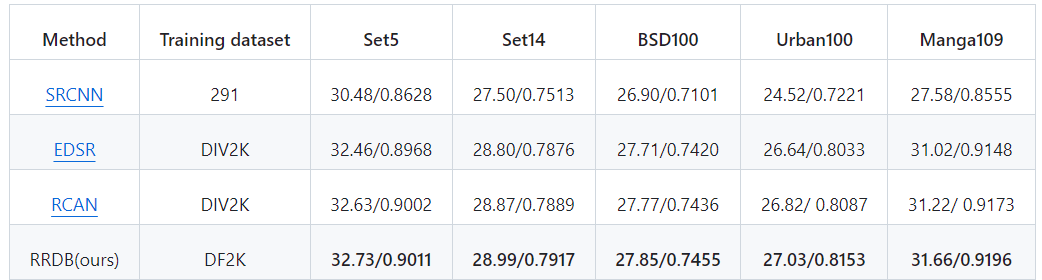
이미지 초고해상도를 위한 다양한 신경망 모델들의 성능을 비교한 표이다.
여기서 PSNR(최대 신호 대 잡음비)는 이미지 품질을 평가하는 데 사용되는 지표로, 높을수록 원본 이미지와의 차이가 적다는 것을 의미한다.
RRDB 모델은 특히 세부적인 텍스처가 많은 Urban100과 복잡한 일러스트가 포함된 Manga109에서 높은 성능을 보여주고 있다. 이러한 결과는 RRDB 모델이 이미지의 세부 사항을 복원하는 데 매우 효과적임을 보여준다.
2. Quick Test
단지 이미지 향상을 위한 모델이라 굉장히 편하게 테스트할 수 있도록 해준다.
-
필요한 환경 구성:
- Python 3가 설치되어 있어야 합니다.
- PyTorch 1.0 이상 버전이 필요하며, CUDA를 사용하여 설치하는 경우 CUDA 버전은 7.5 이상이어야 합니다.
- 필요한 파이썬 패키지를 설치합니다: numpy와 opencv-python. 이는 pip install numpy opencv-python 명령어로 설치할 수 있습니다. -
모델 테스트:
- GitHub 저장소를 복제합니다
git clone https://github.com/xinntao/ESRGAN- 복제한 저장소 폴더로 이동합니다
cd ESRGAN.- 자신의 저해상도 이미지를 ./LR 폴더에 넣습니다. (이미 두 개의 샘플 이미지인 baboon과 comic이 있습니다.)
- Google Drive 또는 Baidu Drive에서 사전 훈련된 모델을 다운로드합니다. 다운로드한 모델을 ./models 폴더에 넣습니다. 높은 인지적 품질과 높은 PSNR 성능을 가진 두 가지 모델을 제공합니다(모델 목록 참조).
- 테스트를 실행합니다
python test.py- ESRGAN 모델과 RRDB_PSNR 모델을 제공하며, test.py에서 설정을 구성할 수 있습니다.
- 결과는 ./results 폴더에 저장됩니다.
해당 과정을 실행하면 아래와 같은 결과를 얻을 수 있다.
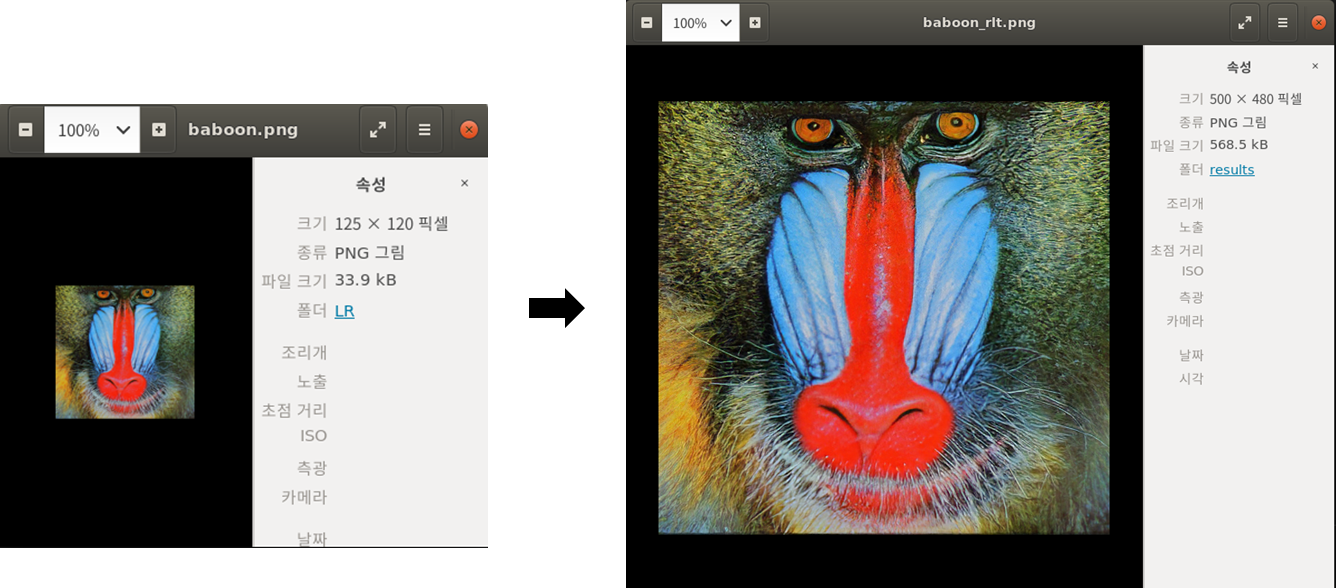
사진에서 보는 것과 같이 해상도가 향상된 모습이다.
3. 적용
ESRGAN에서 제공해주는 test코드를 수정하여서 아래 코드를 구현하였다.
import os.path as osp
import glob
import cv2
import numpy as np
import torch
import RRDBNet_arch as arch
model_path = 'models/RRDB_ESRGAN_x4.pth'
device = torch.device('cuda')
test_img_folder = 'LR/*'
model = arch.RRDBNet(3, 3, 64, 23, gc=32)
model.load_state_dict(torch.load(model_path), strict=True)
model.eval()
model = model.to(device)
print('Model path {:s}. \nTesting...'.format(model_path))
idx = 0
for path in glob.glob(test_img_folder):
idx += 1
base = osp.splitext(osp.basename(path))[0]
print(idx, base)
img = cv2.imread(path, cv2.IMREAD_COLOR)
img = img * 1.0 / 255
img = torch.from_numpy(np.transpose(img[:, :, [2, 1, 0]], (2, 0, 1))).float()
img_LR = img.unsqueeze(0)
img_LR = img_LR.to(device)
with torch.no_grad():
output = model(img_LR).data.squeeze().float().cpu().clamp_(0, 1).numpy()
output = np.transpose(output[[2, 1, 0], :, :], (1, 2, 0))
output = (output * 255.0).round()
cv2.imwrite('results/{:s}_rlt.png'.format(base), output)
해당 코드를 이용하여서 아래와 같은 결과를 얻었다.
아래는 이미지 향상의 결과이다.
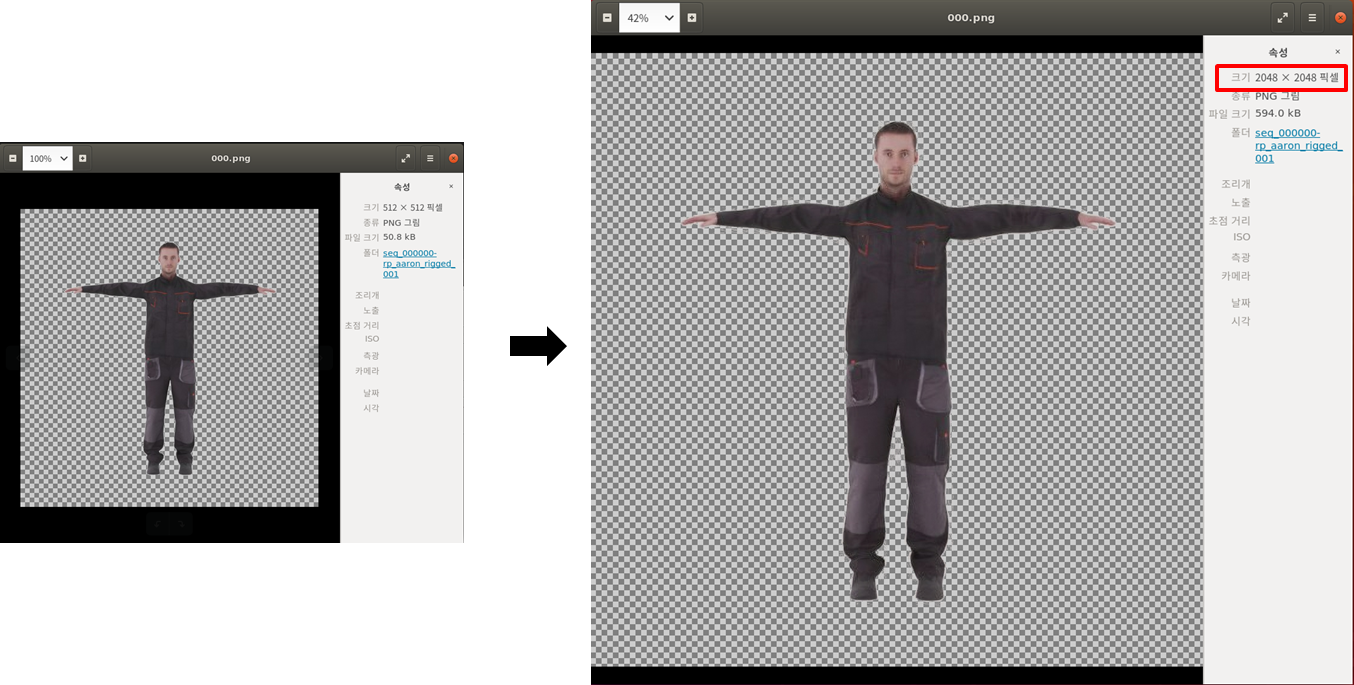
이제 해당 결과를 이용해서 학습해볼 예정이다,
