이번에 도전해볼 과제는 가상면접장이다. 생성형 AI 기반으로 가상 면접장을 생성하기 위해 여러가지 자료들을 조사해본 결과, 아래 영상들을 발견할 수 있엇다.
그래서 해당 영상들을 기반으로 파노라마 이미지를 생성하고 해당 이미지를 기반으로 유니티 엔진을 이용해서 3D로 구성하는 것을 시도해보기로 하였다. 그래서 파노라마 이미지를 생성해주는 생성형 AI를 찾아보던 중 Text2Light 모델을 발견하였고, 해당 모델에 대해서 간단하게 공부한 결과를 정리하고자 한다.
1. Text2Light

Text2Light는 자유 형식 텍스트만을 사용하여 4K+해상도의 HDR 파노라마를 생성할 수 있는 모델이다.
2. 기술의 작동 원리
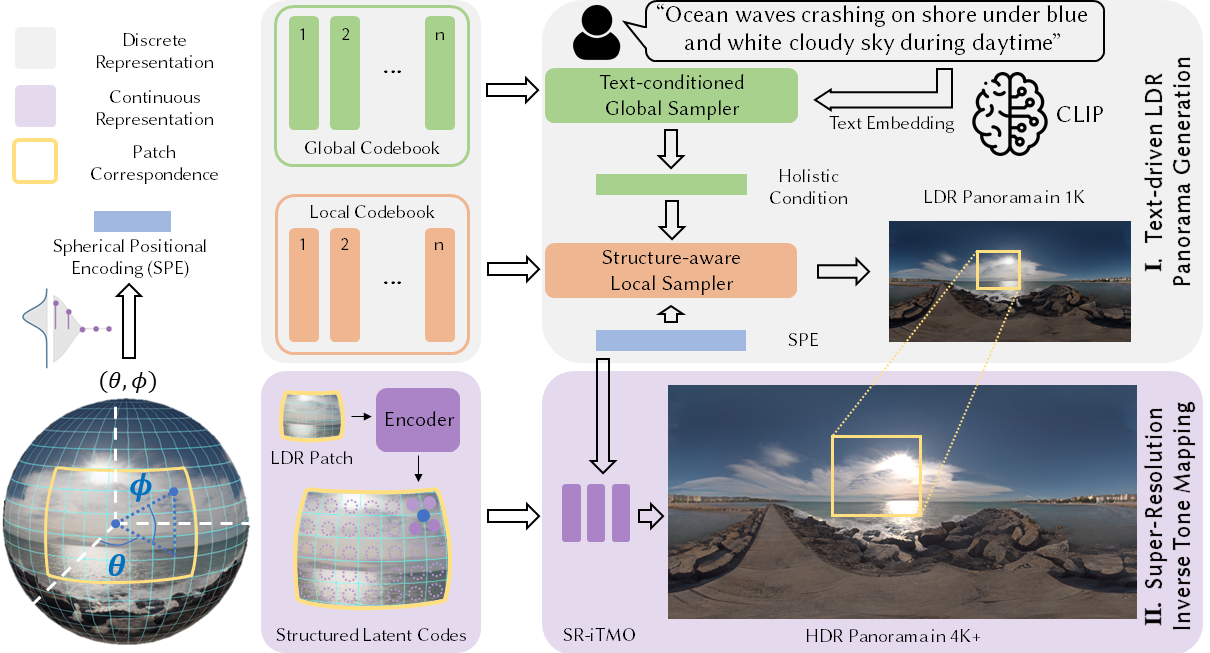
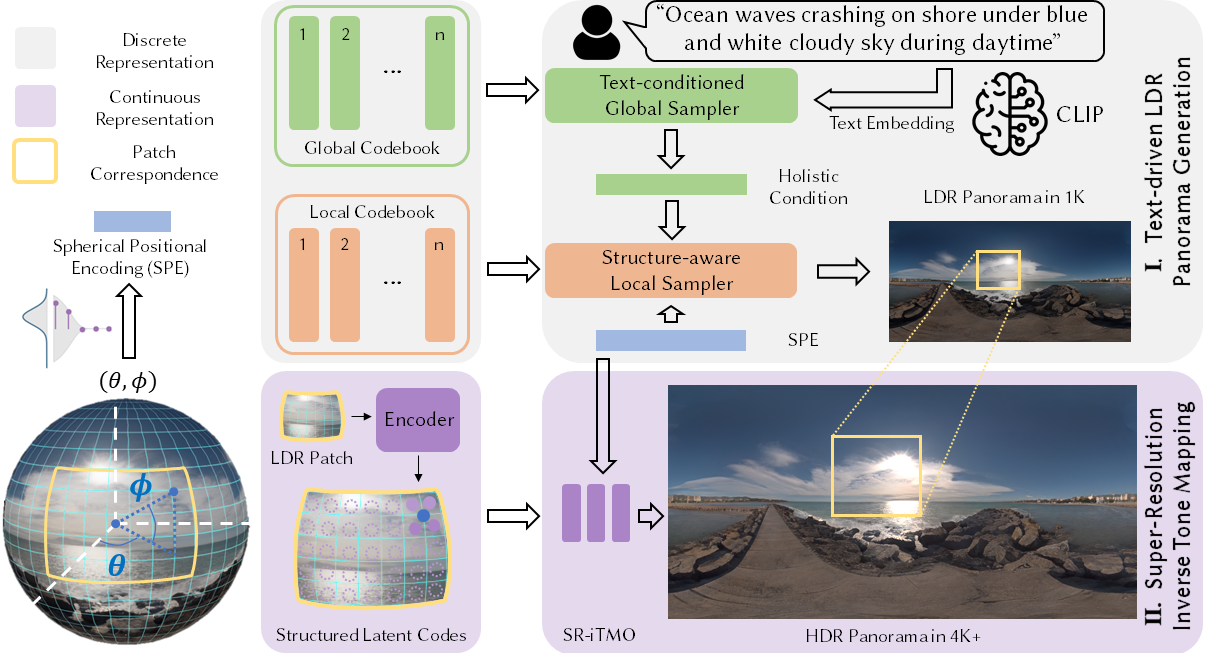
1. 입력과 전역 샘플링
- 텍스트 입력: 사용자가 자유 형식의 텍스트로 장면을 설명한다. 예를 들어 "Ocean waves crashing on shore under blue and white cloudy sky during daytime" 같은 설명이 사용될 수 있다.
- Text Embedding: CLIP 모델을 사용하여 입력된 텍스트를 임베딩한다. CLIP은 텍스트와 이미지 사이의 상관관계를 학습한 모델로, 텍스트를 이미지의 특징과 연결할 수 있는 벡터로 변환한다.
- Text-conditioned Global Sampler: 텍스트 임베딩을 바탕으로 전역 코드북에서 장면의 전체적인 특징을 샘플링한다. 이는 장면의 큰 그림을 그리는 데 사용된다.
2. 지역 샘플링과 구조화된 잠재 코드
- Spherical Positional Encoding (SPE): 파노라마의 구면 좌표를 인코딩하여 각 패치의 위치 정보를 제공한다. 이를 통해 전역 샘플러가 생성한 큰 그림 내에 각 패치가 어떻게 배치되어야 할지를 결정한다.
- Structure-aware Local Sampler: SPE를 사용하여 각각의 패치를 생성한다. 이는 전역 샘플러에 의해 생성된 장면의 전체적인 구조 내에서 각각의 지역적 디테일을 정밀하게 재현하는 데 중요하다.
- Encoder: 생성된 각 LDR 패치를 인코딩하여 구조화된 잠재 코드로 변환한다. 이 코드는 각 패치의 구조적인 디테일과 질감을 포함한다.
3. 초고해상도 이미지 생성
- SR-iTMO (Super-Resolution Inverse Tone Mapping): 낮은 해상도의 LDR 패치를 초고해상도 HDR 파노라마로 변환한다. 이 과정에서 이미지의 해상도가 증가할 뿐만 아니라 동적 범위도 확장되어 더 선명하고 실제와 같은 이미지가 생성된다.
3. 기술의 한계
-
Text Bias: Text2Light 프레임워크는 CLIP 모델을 기반으로 하기 때문에, 텍스트 기반 합성에서 사용되는 데이터 쌍이 없는 경우, 성능이 CLIP 모델에 크게 의존한다. CLIP은 특정 단어-이미지 쌍에 편향될 수 있으며, 이러한 편향은 생성 과정에 영향을 미친다. 예를 들어, '실루엣'이라는 단어가 입력 설명에 포함될 경우, 모델은 다른 단어들과 상관없이 순수하게 어두운 영역을 생성할 수 있으며, 이는 낮은 충실도로 이어질 수 있다.
-
Uncommon Scenery: Text2Light는 데이터셋에서 흔하지 않은 장면 콘텐츠를 합성하는 데 어려움을 겪는다. 예를 들어, "tree and aurora rays"라는 문장이 주어졌을 때, 모델은 'tree'에만 초점을 맞추고 'aurora rays'는 무시할 수 있다.
4. 적용 방안
Text2Light의 고품질 결과는 가벼운 3D 장면 및 몰입형 VR과 같은 다운스트림 작업에 직접 적용될 수 있다고 한다. 현재 진행중인 프로젝트 기준으로는 적절한 텍스트로 파노라마를 생성한 후 유니티에서 해당 파노라마를 3D로 구성하는 것으로 적용할 수 있다.
다음 게시글에서는 Text2Light를 사용하기 위해 환경 구축한 내용과 프롬프트를 이용하여 생성한 결과 파노라마들에 대한 내용을 작성하겠다.
