
1. 개 요
목적
만약 우리가 여러 개의 단어들을 가지고있고, 그 단어들을 저장하고 검색하고싶다면 어떤 방식을 사용하면 좋을까? 우리가 배운 자료구조들은 많다. 예를들어 배열,리스트,트리,그래프,해시테이블등등말이다.
배열과 리스트를 적용시켜보자. 단순하게 일일이 비교해보면 된다. 하지만 컴퓨터는 이러한 방법이 매우 비효율적이다. 예를 들어, 최대 길이가 m인 문자열 n개의 집합에서 마찬가지로 최대 길이가 m인 임의의 문자열이 그 문자열들의 집합에 포함되는지를 일일이 확인하면 사전처리는 필요 없지만, 최악의 경우 O(nm)의 비교 횟수가 필요하다.
그 다음으로 이 문자열을 정렬시킨뒤, 이진 탐색이라는 알고리즘을 적용시켜보자. 참고로 이진탐색 알고리즘은 전체 문자열을 사전 순으로 배열 저장 후, 중간 값과 비교해 사전적으로 이전이면 좌측의 반 / 이후면 우측의 반으로 비교하는 방식을 반복하는 알고리즘이다.최대 문자열의 길이가 m이고, 전체 문자 개수가 n개시 시간복잡도는 정렬은 O(nmlogn) 탐색은 O(mlogn) 즉 O(nmlogn) 으로 단축시킬 수 있지만, 이것도 비효율적이다.
하지만 위의 시간 복잡도를 압도하는 알고리즘이 존재한다. 바로 트리구조이다. 트리구조가 무엇이냐면 일반적으로 대상 정보의 각 항목들을 계층적으로 구조화할 때 사용하는 비선형 자료구조이다. 이 트리구조가 왜 단어들을 관리하는 것에 효율적이냐면 트리의 구조는 '데이터 저장'의 의미보다는 '저장된 데이터를 더 효과적으로 탐색'하기 위해서 사용되기 때문이다.
트리구조에서도 여러 가지 종류들이있다. 예를들어 이진트리, B-tree, 포레스트, 트라이등등 말이다. 하지만 여기에 딱 맞는 자료구조가있다. 문자열로 구성된 여러 개의 단어들을 효율적으로 인덱싱하고 관리하기 위한 방법으로 널리 활용되는 자료구조인 트라이이다. 트라이는 영어 단어 “retrieval”로부터 유래하였다. 트라이에대해 간단히 설명해주자면 트라이에서 각 노드는 26개의 알파벳 문자(a~z) 중 하나를 저장하고 각 노드는 총 26개의 자식 노드를 가질 수 있다. 즉 26진 트리 루트 노드에서 시작하여 top-down 방식으로 노드를 방문하면서 단어를 검색하는 자료구조이다. 이 보고서는 트라이라는 알고리즘을 이용하여 단어를 효율적으로 삽입, 검색, 제거하는 알고리즘을 이용하여 코드를 구현해볼 것이고 그것을 기록해 볼 것이다.
보고서 요약
결과보고서는 구현보고서와는 다르게 코드구현부분은 간략하게 적을 것이고 나머지 알고리즘부분이나 이론적인 부분을 좀 더 자세하게 다뤄볼 것이다. 구현보고서에서는 코드를 구현하고 그 실행해본 뒤 어떤 결과가 나오는지에 대해 다뤄보았었다. 그리고 우리가 트라이를 구현한 이유인 단어검색에서 효율적이라는 것에대해서 다른 알고리즘 들과 비교해보는 시간도 가졌고 이 트라이를 이용하여 어떤 응용프로그램을 구현할 수 있을지에대해 생각해보는 시간을 가졌다. 하지만 이번 결과보고서에서는 구현보고서에서 기록했던 부분은 간략하게 적고 이론적인 부분을 좀 더 자세하게 다뤄볼 것이다. 그리고 최종보고서인 만큼 마지막 마무리는 구현하는 과정에서 겪었던 어려움과 이를 어떻게 해결하였는지 적고 마무리 할 것이다.
제약조건
본 문제에서는 영어 소문자로 구성된 단어만을 고려한다.
2. 문제 정의 및 입출력 명세
문제정의
단어들을 효과적으로 인덱싱하고 관리하는 기술은 정보 검색(information retrieval) 알고리즘의 기반이 되는 기술로 굉장히 중요한 기술이다.
n개의 영단어들이 주어질 때 단어들을 효과적으로 인덱싱하고 관리하는 기술은 무엇일까?
단어들의 인덱싱과 추가, 검색, 삭제 기능을 제공해야 한다.
메모리의 공간을 절약하여 단어들을 인덱싱할 수 있어야 한다.
효율적으로 주어진 단어를 추가, 검색, 삭제할 수 있어야 한다.
위에 조건을 만족하는 자료구조 기술을 이용하여 단어들을 효과적으로 관리하시오.
입출력 명세
입력:n의 길이를 가진 단어.
출력:추가, 검색, 삭제 기능 제공 (아래 그림 참조)

3. 자료구조 설계
트라이의 구조와 원리를 요약 정리
자신이 사전에서 어떤 단어를 검색한다고 가정해보자. 사전에서 단어를 찾는 방법에는 여러 가지 방법들이 존재한다.
첫 번째로는 사전의 모든 단어들을 내가 찾는 단어들과 대조해보는 것이다. 가장 확실한 방법이지만 찾고자하는 단어가 제일 뒤에있을 경우 정말 느리게 찾을 것이다. 즉 효율적이지 않은 방법이다. 참고로 이 방법을 단순탐색이라 말한다.
그다음으로는 사전의 모든단어들 중에 절반자리에 위치하는 단어를 찾는다. 그 다음에는 내가 찾고자하는 단어가 그 단어를 기준으로 왼쪽에 위치하나 오른쪽에 위치하나 확인한다. 이런 식으로 탐색하는 범위를 절반씩 줄여나간다면, 전체 단어의 개수를 N이라고 했을 때 logN만에 단어를 찾을 수 있다. 하지만 이 역시도 비효율적이다, 왜냐하면 이 탐색기법은 모든 단어들이 정렬되어야한다는 전제가 필요하기 때문이다. 만약 사전이 아니라면 단어들을 정렬한 뒤 탐색을 시작해야하기 때문에 추가적인 시간이 소요된다. 이 탐색기법을 이진탐색이라 말한다.
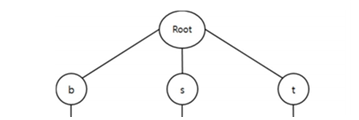
우리가 일반적으로 사전에서 단어를 찾을 때를 생각해보자. 우리는 단어의 첫 글자를 이용하여 해당 글자로 시작하는 단어들이 모여져있는 부분으로 간 뒤, 또 다시 그 곳에서 두 번째 단어와 비교할 것이고 계속해서 이런 과정을 반복 할 것이다. 이 과정을 반복하는 자료구조가 있다. 바로 트라이이다.
트라이는 문자열의 정보를 담은 트리 구조이다. 즉 {bit, bite, study, student, stuff,
the, them, there} 해당 문자열을 트라이라는 자료구조에 담았다고 하면 아래 모양 일 것이다.

사진에서 보는 것과같이 단어의 문자들을 하나하나씩 트리구조형태로 저장해준다. 만약 저장하려는 단어가 이미 저장한 단어의 문자들과 겹친다면 사진에서 bit, bite 같이 이미 저장한 단어를 이용하여 저장한다. 또한 위에 사진과 같이 단어의 문자들을 저장하기 위해서 트라이에서는 트라이 객체 내에는 각 알파벳에 해당하는 자식 트라이 객체를 담을(또는 연결할) 배열을 속성으로 갖도록 한다. 아래는 이해를 도와줄 예시이다.

이 트라이 구조를 이용하여 단어들을 효과적으로 인덱싱하고 관리하면 될 것이다. 단어들을 효과적으로 인덱싱하고 관리하기 위해서는 아래 기능들이 필요할 것이다.
① 단어들을 삽입하여 트라이를 구성하는 기능
만약 {bit, bite, study, student, stuff, the, them, there} 이라는 단어들을 트라이 자료구조에 삽입하려고 한다면 아래 사진처럼 트라이가 형성될 것이다.

삽입할 때에는 맨 처음 단어인 bit를 먼저 입력 할 것이다. 루트노드의 26가지의 포인트 배열중에서 b에 해당하는 배열에 노드를 삽입해 줄 것이다. 2번째 사진을 참고하면 이해하기 쉬울 것이다. 그다음 그 b노드로 가서 이번에는 i에 해당하는 배열에 노드를 삽입해줄 것이다. 이 과정을 반복하다보면 bit는 무사히 삽입 될 것이다. 그다음인 bite를 삽입 해 준다고 하자 앞서 말한대로 단어의 문자들이 겹치게된다면 이용하여 저장한다고 하였다. 즉 이러한 과정들을 간단하게 정리한다면 주어진 문자열에서 현재 문자를 가져온다. -> 현재 문자로 이루어진 노드가 존재한다면, 그 노드로 그 다음 문자열을 탐색하고, 노드가 없다면 그 노드를 새로 할당 받은 후, 해당 노드를 통해 다음 문자열을 탐색한다. 로 정리 할 수 있을 것이다. 하지만 여기에서 bit와 bite를 구분할 수 없게 되는 오류가 발생한다. 이 오류는 트라이 객체에 단어의 끝이라고 알려주는 변수를 집어넣어서 각 노드에 단어의 끝 여부를 나타내어 단어의 끝이라고 표시한다. 아래는 이해를 도와줄 예시이다.

위에 사진처럼 bird의 단어가 삽입이 완료되었을 때 변수를 1로 설정해주는 것이다.(사진에서는 isLastChar이 그 변수이다.)
이런 방식을 반복 하다보면 삽입이 완료된다.
② 트라이에서 단어를 검색하는 기능
단어를 검색하는 기능도 사실 삽입과 돌아가는 방식은 비슷하다고 생각하면 된다, 위에 1번에서 성공적으로 삽입을 끝마쳤다면 현재 트라이에는 {bit, bite, study, student, stuff, the, them, there} 단어들이 저장되어있을 것이다. 우리가 bit라는 단어를 검색한다고 가정해보자. 루트노드의 26가지의 포인터 배열중에서 b에 해당하는 배열이 존재하는지 확인한다. 존재한다면 내려가면 되는 것이다. 이렇게 반복하다보면 t에 도착할 것이다. 아래 사진을 본다면 보다 이해하기 쉬울 것이다.

여기에서 우리가 만들어줬던 단어의 마지막임을 나타내는 변수를 확인하는 것이다. 만약 이 변수가 1이라면 해당 단어는 존재하는 것이므로 검색완료이다. 만약 우리가 저장하지 않았던 단어인 zong을 검색한다고 했을 때는 루트노드의 26가지의 포인터 배열 중 z에 해당하는 배열이 비어있을 것이다. 아래 사진을 보면 이해하기 쉬울 것이다.
이러면 없는 단어이기 때문에 검색불가능이라고 출력해주면 될 것이다. 이것말고도 하나 생각해주어야 하는 것이있는데 예를 들어 stud를 검색한다고 가정하자. 문자 하나하나씩 쭉 내려가다보면 다 존재할 것이다. 왜냐하면 student를 저장해 놓았기 때문이다. 그렇다고해서 해당 단어가 존재할 것인가? 아니다. 왜냐하면 단어의 마지막을 표시한 변수가 d에서 0일 것이기 떄문이다. 이 문제를 조심한다면 검색도 무사히 끝낼 수 있을 것이다.
③ 트라이에서 단어를 삭제하는 기능
트라이에서 단어를 삭제할 때에는 삭제 예정인 단어와 같은 전위를 갖는 단어들이 존
재할 수 있으므로, 단말 노드부터 bottom-up 방식으로 삭제를 진행해야한다. 아래 그림을 보면 이해하기 쉬울 것이다.

단어를 삭제할 경우 삭제할 단어가 자식노드를 가지냐 안가지냐로 나눈다. 자식노드를 가지지 않는다면 그림에서 1번과 3번이고 가진다면 2번경우이다. 먼저 쉬운 2번의 경우부터 설명하자면 자식노드가 있다는 것은 해당 단어를 이용하여 저장한 단어가 있다는 뜻이다, 그래서 삭제하면 해당단어를 이용한 단어 또한 삭제되게 된다. 그래서 단어의 마지막을 나타내는 변수를 0으로 바꿈으로 해결한다. 그러면 해당단어는 삭제되게 될 것이고 해당단어를 이용하여 저장한 단어는 남아있게 된다. 1번과 3번같은 경우 자식노드가 없을 경우인데 이 경우 또한 두가지로 나뉜다. 삭제하는 도중 분기가 발생하냐 안하냐이다. 그림의 1번의 경우 그냥 쭉 삭제하면 된다. 왜냐하면 삭제한다고 해도 다른 단어한테 영향을 줄 것이 없기 때문이다. 하지만 3번처럼 분기를 만나게 될 경우에는 다르다. r을 삭제한 후 e를 삭제하게 된다면 them까지 삭제하게 될 것이다. 이 경우에는 r을 삭제한 후 e의 자식노드를 확인한다. 만약 자식노드가 있다면 삭제를 멈추면 될 것이다. 이렇게 한다면 삭제역시 아무문제 없을 것이다.
앞에서 설명한대로 트라이를 이용한다면 단어들의 인덱싱과 추가, 검색, 삭제 기능을 제공할 수 있고 메모리의 공간을 절약하여 단어들을 인덱싱할 수 있고 효율적으로 주어진 단어를 추가, 검색, 삭제할 수 있다.
4. 알고리즘 설계
트라이에서 필요한 알고리즘 소개 및 기능 명세
문제 해결 논리가 정확하게 표현될 수 있도록 의사코드를 활용하여 기술하겠다
1.트라이에 단어를 삽입하는 알고리즘
-루트부터 시작하여서 단어의 첫번째 문자부터 트리에 포함되어 있는지 확인한다.
-특정문자 노드가 트리에 포함되어 있으면, 자식 노드로 이동하여 다음 문자 노드가 있는지 확인한다.
-특정문자 노드가 트리에 포함되어 있지 않으면, 새로운 자식 노드를 생성한다.
-단어의 마지막문자라면 단어의 마지막 문자라고 알려주는 변수를 1로 바꾼다.
위 과정들을 반복하면 된다. 아래는 이해를 도와줄 사진이다.

위에 사진처럼 트라이구조에 bed를 삽입하려는 과정이다. 루트노드의 26개 알파벳 포인터 배열에 b에 해당하는 인덱스에 노드가 존재한다면 이미 트라이구조에 저장됐다는 뜻이다. 그래서 자식노드로 내려간다. 마찬가지로 e도 확인한다. 그다음 마지막 d차례에서 d에 해당하는 포인터배열이 비어있으므로 새롭게 삽입을 해준다. 그리고 단어의 마지막 문자이므로 단어의 마지막 문자임을 알려주는 변수를 1로 바꿔준다. 참고로 알고리즘에서 해당 변수는 word_end이다.
Algorithm Get_node()
Input: 없음
Output: 새로 할당된 노드의 포인터
1. Trie_node node ← malloc(sizeof(Struct Trie_node))
2. node.word_end ← 0
3. for i ← 0 to Alpha_size-1
4. node.children[i] ← Null
5. return nodeAlgorithm Word_insert(root, word)
Input: 트라이의 루트 노드(root), 삽입할 단어의 문자 배열(word)
Output: 이중포인터로 구현하였기 때문에 없음
1. *curr ← *root
2. i ← 0
3. while (word[i]) {
4. idx ← word[i] - ‘a’
5. if (*curr.children[idx] = Null)
6. *curr.children[idx] ← Get_node()
7. *curr ← *curr.children[idx]
8. i ← i + 1
9. }
10. *curr.word_end ← 12.트라이에서 단어를 검색하는 알고리즘
검색또한 삽입과 돌아가는 구조자체는 비슷하다. 단어의 각 문자에 해당하는 자식 노드로 순차적으로 내려가면서 탐색한다. 아래는 이해를 도와줄 사진이다.

만약 beer을 검색한다고 생각해보자. 맨처음에 루트노드에서 b가 존재하는지 확인한다. 존재하므로 내려간다. 이런 방식으로 계속해서 가다보면 마지막 문자인 r이 존재하는지 확인 할 것이다. r이 존재하므로 이제 word_end가 1인지 확인하면 된다. 위 그림에서 word_end가 1(파랑색노드)이므로 검색끝이다.
이제는 bee를 검색한다고 생각하자. 마찬가지로 쭉 내려가다가 마지막 문자인 e에서 더 이상 내려가지않고 word_end의 변수값만 확인해줄 것이다. 근데 word_end가 0이므로 해당 단어는 없는 단어이다. 그래서 검색 불가능일 것이다.
이제는 zong를 검색해본다고 생각해보자, root노트에서 z에 해당하는 포인트 배열이 비어있으므로 트라이구조에서 해당하는 단어가 없다는 뜻이 된다. 그러므로 없는 단어이다. 검색불가이다.
위에 과정을 알고리즘설계에 맞게 정리해보면 아래와 같다.
-탐색 과정에서 해당 문자가 자식 노드에 존재한다면 해당 자식 노드로 이동함.
-단어의 모든 문자가 트라이에서 발견되면 1(=true)을 반환하고 탐색을 종료함.
-만약 탐색 과정에서 해당 문자가 자식 노드에 없다면 즉시 0(=false)를 반환하고 탐색을 중단함
Algorithm Word_search(root, word)
Input: 트라이의 루트 노드(root), 검색할 단어의 문자 배열(word)
Output: 검색할 단어가 존재하면 1, 그렇지 않으면 0을 반환
1. if (root = Null) return 0
2. curr ← root
3. i ← 0
4. while (word[i]) {
5. idx ← word[i] - ‘a’
6. curr ← curr.children[idx]
7. if (curr = Null) return 0
8. i ← i + 1
9. }
10 if(curr.word_end=1)
11. return curr.word_end
12. else
13. return 0추가적인 설명을 더하자면 7번 오류는 해당단어가 없는경우이다. 13번오류는 해당 문자열은 있으나 해당 단어가 없는 경우이다. 11번의 경우는 해당단어가 있는 경우이다.
3.트라이에서 단어를 삭제하는 알고리즘
트라이에서 단어를 삭제할 때에는 삭제 예정인 단어와 같은 전위를 갖는 단어들이 존
재할 수 있으므로, 단말 노드부터 bottom-up 방식으로 삭제를 진행해야한다. 아래 그림을 보면 이해하기 쉬울 것이다.

단어를 삭제할 경우 삭제할 단어가 자식노드를 가지냐 안가지냐로 나눈다. 자식노드를 가지지 않는다면 그림에서 1번과 3번이고 가진다면 2번경우이다. 먼저 쉬운 2번의 경우부터 설명하자면 자식노드가 있다는 것은 해당 단어를 이용하여 저장한 단어가 있다는 뜻이다, 그래서 삭제하면 해당단어를 이용한 단어 또한 삭제되게 된다. 그래서 단어의 마지막을 나타내는 변수를 0으로 바꿈으로 해결한다. 그러면 해당단어는 삭제되게 될 것이고 해당단어를 이용하여 저장한 단어는 남아있게 된다. 1번과 3번같은 경우 자식노드가 없을 경우인데 이 경우 또한 두가지로 나뉜다. 삭제하는 도중 분기가 발생하냐 안하냐이다. 그림의 1번의 경우 그냥 쭉 삭제하면 된다. 왜냐하면 삭제한다고 해도 다른 단어한테 영향을 줄 것이 없기 때문이다. 하지만 3번처럼 분기를 만나게 될 경우에는 다르다. r을 삭제한 후 e를 삭제하게 된다면 them까지 삭제하게 될 것이다. 이 경우에는 r을 삭제한 후 e의 자식노드를 확인한다. 만약 자식노드가 있다면 삭제를 멈추면 될 것이다. 아래는 이 경우의 이해를 도와줄 사진이다.

위에 사진과 같은 경우 bear을 삭제하려는 과정이다. r 과 e를 성공적으로 제거 한 뒤 분기를 만나 e를 제거 못하고 마무리한다. 왜냐하면 e를 제거하면 bed도 삭제되기 때문이다.
추가로 나는 문자열을 이용해서 단어를 삭제하는 알고리즘을 만들었다. 아래 그림은 이해를 도와줄 그림이다.

트라이 구조에서 bi를 삭제하려고 했을 때 하늘색 선을 따라서 삭제시켜준다. bird의 d를 삭제시켜준다. 그 다음 r을 삭제시켜준다. 그리고 여기서 중요하다. I를 삭제시켜주기 이전에 g를 삭제시켜줘야한다. 왜냐하면 I를 삭제시켜준다면 g로 갈 방법이 없기 때문이다. 그리고 마지막으로 I를 삭제시켜주고 마무리한다. 아래 알고리즘 코드르 본다면 보다 더 이해하기 쉬울 것이다.
Algorithm nochildren(curr)
Input: 트라이의 현재 노드(curr)
Output: 자식을 갖지 않을 경우 1, 그렇지 않을 경우 0
1. for i ← 0 to Alpha_size
2. if (curr.children[i] ≠ Null) return 0
3. return 1해당 알고리즘은 삭제하는 알고리즘을 도와주는 알고리즘이다. 자식이 있나 없나 판단해준다.
Algorithm howchildren(curr)
Input: 트라이의 현재 노드(curr)
Output: 자식의 개수
1. for i ← 0 to Alpha_size
2. if (curr.children[i] ≠ Null) children_index++
3. return children_index해당 알고리즘은 자식을 몇 개가지고있는지 알려주는 함수이다. 직접 구현해보았다.
-단어를 이용한 삭제
Algorithm Word_delete(curr, word)
Input: 트라이의 루트 노드(curr), 삭제할 단어의 문자 배열(word)
Output: 삭제했을 때 삭제가 잘되었는지 실패했는지 알려주는 숫자
1. if (*curr = Null) return Null
2. if (*word == ‘\0’) {
3. if (nochildren(*curr) = 1 && *curr.word_end==1 ) {
4. free(*curr)
5. *curr ← Null
6. }
7. else if (*curr.word_end = 1) *curr.word_end ← 0
8. else return Null
9. }
10. idx ← word[depth] - ‘a’
11. correct_check ← Word_delete(*curr.children[idx], *word+1)
12. if (nochildren(*curr) = 1 and *curr.word_end = 0) {
13. free(*curr)
14. *curr ← Null
15. }
16. return correct_check참고로 1번 오류는 해당단어가 없는 경우이고 5번의 경우 해당 단어를 깔끔하게 삭제해준 경우이다. 7번의 경우 해당단어를 삭제는 했으나 해당 단어를 이용하여 저장한 단어가 있어 해당 문자열은 남아있는 경우이다. 8번의 경우에는 해당 문자열은 존재하나 해당 단어가 없어 삭제를 못하는 경우이다. 즉 마지막 문자의 word_end가 0이라는 뜻이다.
-문자열을 이용한 삭제
Algorithm delete_all(curr)
Input: 트라이의 현재 노드(curr)
Output: 삭제성공시 1을 반환해준다.
1. if(!nochildren(*curr)) {
2. for i ← 0 to Alpha_size
3. if (*curr.children[i]) delete_all(*curr.children[i]) }
4. free(*curr)
5. (*curr)=Null
6. return 1위 함수는 삭제하려는 문자열 뒤에 남아있는 모든 문자들을 삭제해주기 위해서 포인터를 찾아가주는 함수이다. 제일 가까운 곳에 있는 포인터만 삭제해주면 편하긴하지만 메모리의 문제가있어 하나 하나 찾아가준 뒤 뒤에서부터 삭제 해주어야한다. 문자열을 이용하여 삭제하는 함수를 도와주는 함수이다.
Algorithm Word_delete_With(curr, word)
Input: 트라이의 루트 노드(curr), 삭제할 단어의 문자 배열(word)
Output: 삭제했을 때 삭제가 잘되었는지 실패했는지 알려주는 숫자
1. if (*curr = Null) return Null
2. if (*word == ‘\0’) {
3. if (delete_all(*curr)) return 1;
4. else
5. return 0
6. }
7. idx ← word[depth] - ‘a’
8. correct_check ← Word_delete(*curr.children[idx], *word+1)
9. if (correct_check ) {
10. free(*curr)
11. *curr ← Null
12. }
13. return correct_check참고로 1번 오류는 해당문자열이 없는 경우이고 3번의 경우 해당 문자열을 깔끔하게 삭제해준 경우이다.
4.트라이에서 단어를 출력하는 알고리즘
마지막으로 트라이에 저장되있는 모든 단어들을 출력해주는 알고리즘이다. 아래는 이해를 도와줄 사진이다.

위에 사진의 파란색 선을 따라가며 출력해준다. 여기서 주의깊게 봐야하는 점은 저렇게 문자들만 쭉 출력해줄 경우 해당 문자가 단어상에서 어디에 위치하는지 모를 것이다. 위에 사진을 예시로 든다면 birdgeer 이런 식으로 출력만 해줄 것이다. 그래서 문자의 해당 단어에서 위치값을 인자로 넘겨주어 어디에 위치하는지 알려주어야한다.
Algorithm printf_all(curr,word_index)
Input: 트라이의 현재 노드(curr), 단어상에서 문자의 위치(word_index)
Output: 없음(저장된 단어 출력)
1. if(!nochildren(curr)) {
2. for i ← 0 to Alpha_size {
3. if (curr.children[i]) {
4. for start_index ← 0 to word_index
5. printf(“ ”)
6. printf(“%c”, I + ‘a’)
7. if (curr.children[i].word_end=1) printf(“!\n”)
8. else printf(“\n”)
9. printf_all(curr.children[i],word_index+1)
10. }
11. }위에 알고리즘에서 printf 부분이 핵심 부분이다. 단어상에 문자의 위치만큼 “ ”를 프린트해줘서 맞춰준다. 그러다가 마지막 문자면 !를 추가로 프린트해줘서 단어가 끝났다고 알려준다.
이렇게 알고리즘에대해서 다 정리해보았다. 참고로 나는 리턴값으로 노드를 반환하는 것을 별로 안 좋아하기 때문에 이중포인터를 활용하여 구현하였다.
시간복잡도와 공간복잡도
먼저 트라이의 높이는 단어의 길이가 len이라고 했을 때 len이다. 왜냐하면 단어를 문자하나하나씩 저장하기 때문이다.
삽입, 검색, 삭제알고리즘에서 시간복잡도는 위에서 알고리즘설계에서 봐왔듯이 문자의 길이와 같다. 즉 주어진 단어의 길이가 len이라고 했을 때 시간복잡도는 O(len)이다.
공간복잡도의 경우 트라이에 삽입된 전체 단어의 수가 no라고 했을 때 O(Alpha_size x len x no)이다. 왜냐하면 트라이는 앞에서 봐온대로 단어가 있든없드 하나의 노드마다 알파뱃 개수인 26개의 포인터 배열을 가지고 있기 떄문이다. 그 노드가 len x no 개 있기 때문이다.
5. 알고리즘 구현 및 분석
구현한 알고리즘과 구현 방법 및 결과
Algorithm Get_node()코드구현
struct Trie_node * Get_node() //노드를 기본적으로 만들어주는 함수
{
struct Trie_node * node = (struct Trie_node *)malloc(sizeof(struct Trie_node));
if (node !=NULL) //malloc이 실패한다면 node가 NULL포인터를 갖게된다. 따라서 NULL 포인터의 변수를 참조해서 초기화하는 경우가 생길 수 있다 .따라서 이를 방지하고자 삽입한 코드이다.
{
node->word_end =0; //초기화
for (int index =0; index < Alpha_Size; index ++)
{
node->children[index] =NULL; //초기화
}
}
return node; //초기화시켜준 노드 반환.
}
Algorithm Word_insert(root, word)코드구현
void Word_insert(struct Trie_node ** root, const char * word) //노드를 삽입하는 함수.
{
struct Trie_node * curr = (*root);
int index =0;
while (word[index]) //단어의 첫번째 문자.
{
int idx = word[index] -'a'; //단어의 첫번째 문자 - a하면 알파벳상의 그 문자의 index가 나온다. 예) c-a -> 2
if (curr ->children[idx] ==NULL) //문자가 들어갈 공간이 비어있다면 채워준다.
{
curr->children[idx] = Get_node(); //이 때 위에 선언한 Get_node()가 나온다.
}
curr = curr ->children[idx]; //그 다음 문자를 삽입하기 위해 자식노드로 넘어간다.
index = index +1;
}
curr->word_end =1; //while문이 끝났다는건 단어삽입이 끝났다는 것이니까 마지막문자라고 표기해주기위해 word_end 값을 1로 표기해준다.
}
Algorithm Word_search(root, word)코드구현
int Word_search(struct Trie_node * root, const char * word) //단어를 검색하는 함수이다.
{
if (root ==NULL) //넘겨준 트라이가 비었을경우 오류출력. (거의 GetNode를 안해줄 경우 발생한다.)
return 0;
struct Trie_node * curr = root;
int index =0;
while (word[index]) //똑같이 첫번째 문자부터 시작한다.
{
int idx = word[index] -'a'; //위와 마찬가지.
curr = curr ->children[idx]; //자식노드로 넘어가기
if (curr ==NULL)
return -1; //해당단어가 없는 경우. 리턴해줘서 바로 끝냄.
index = index +1;
}
if (curr ->word_end ==1)
return curr ->word_end; //해당단어가 있는경우
else
return -2; //해당문자열은 있으나 해당단어가 없는경우
}
Algorithm nochildren(curr)코드구현
int nochildren(struct Trie_node * curr) //자식이 있는지 없는지만 판단한다.
{
for (int index =0; index < Alpha_Size; index ++)
{
if (curr ->children[index] !=NULL) //자식이 하나라도 있을경우 바로 리턴으로 탈출한다.
return 0;
}
return 1;
{
}
}
Algorithm howchildren(curr)코드구현
int howchildren(struct Trie_node * curr) //자식노드가 몇개있는지 알려주는 함수.
{
int children_index =0;
for (int index =0; index < Alpha_Size; index ++)
{
if (curr ->children[index] !=NULL) //자식이있다면 children_index을 1더해준다.
children_index++;
}
return children_index; //자식의 개수를 리턴해준다.
}
Algorithm Word_delete(curr, word)코드구현
int Word_delete(struct Trie_node ** curr, const char * word)
{
int correct_check =0; //삭제가 종료되고 어떤 상황인지 알려주는 변수
if ((*curr) ==NULL)
return -1; //해당 단어를 찾지 못해 삭제를하지못합니다.
if ((*word) =='\0')
{
if (nochildren(*curr) ==1 && (*curr)->word_end ==1) //자식노드도 없고 단어의 마지막인경우 tmi 정상적인 트라이구조라면 자식노드가없다면 당연히 단어의 마지막이다.
{
free(*curr); //curr을 free처리 해줌으로 삭제처리
(*curr) =NULL;
return 1; //해당 단어를 찾는데 성공하였습니다. 해당 단어를 단어를 포함하는 단어가 존재하지않아 해당단어는 남지않을 것입니다.
}
else if ((*curr)->word_end ==1) //자식노드가 있으나 단어의 마지막인경우에는 word_end만 0으로 고쳐 단어의 마지막인 흔적을 지워준다.
{
(*curr)->word_end =0;
return 2; // 해당 단어를 찾는데 성공해 삭제하였습니다. 하지만 해당 단어를 포함하는 단어가있어 문자열은 남아있을 것입니다.
}
else
return -2; //해당 문자열은 찾으나 단어가 아니여서 삭제를하지못합니다
}
int idx = (*word) -'a'; //위와 마찬가지. 표현을 다르게 했을뿐.
correct_check = Word_delete(&((*curr)->children[idx]), word +1); //다음 단어를 넘긴다는 뜻 이것도 표현만 다르게함.
if (nochildren(*curr) ==1 and (*curr)->word_end ==0) //맨위에 함수주석에서 설명한대로 단어의 상태를 이루지 못하고 문자열만 남아있는 상태인 애들을 지워준다.
{
free(*curr); //만약 여기들어왔다면 문자열만 남았다는 상태이므로 삭제.
(*curr) =NULL;
}
return correct_check; //삭제해준 상태를 알려주기위해 check변수를 리턴.
}
Algorithm delete_all(curr)코드구현
int delete_all(struct Trie_node ** curr) //직접 새로구현해준 함수이다. 해당 문자열을 포함하는 단어를 모두 삭제하는데 쓰인다. -> 그냥 문자열을 삭제한다.
{
if (!nochildren(*curr))
for (int index =0; index < Alpha_Size; index ++)
{
if ((*curr)->children[index])
{
delete_all(&((*curr)->children[index])); //부모노드의 노드만 free해준다면 편하지만 자식노드들을 free안해준다면 메모리손실이 발생해 하나하나 찾아가주어 free해준다. 그래서 재귀함수로 구현하였다.
}
}
free(*curr); //맨마지막자식노드부터 free시켜준다.
(*curr) =NULL;
return 1; //삭제성공시 1을 반환해준다.
}
Algorithm Word_delete_With(curr, word)코드구현
int Word_delete_with(struct Trie_node ** curr, const char * word) //문자열을 넘겨주면 해당 문자열을 포함한 모든 단어들을 삭제해준다. (단어삭제하면서 필요없어진 문자열도 삭제해준다.)
{
int correct_check =0; //삭제가 종료되고 어떤 상황인지 알려주는 변수
if ((*curr) ==NULL)
return -1; //문자열을 찾지 못해 삭제를하지못합니다.
if ((*word) =='\0')
{
if (delete_all(&(*curr))) //위에 함수가 여기서 쓰인다. 성공하였다면 1을 반환해주는 것을 이용한다.
return 1; //문자열을 찾는데 성공해 해당 문자열로 시작하는 모든 단어들을 삭제하였습니다.
else
return -2; //오류
}
int idx = (*word) -'a'; //생략
correct_check = Word_delete_with(&((*curr)->children[idx]), word +1);
if (correct_check)//삭제해주었을때만 부모노드를 조사해주면 된다. 만약 삭제해준단어가 문자열이면서 단어인경우 필요없어진 문자열이 존재하므로 그것을 삭제해준다.
{
if (nochildren(*curr) ==1 and (*curr)->word_end ==0)//부모노드들을 올라가면서 조사한다. 단어가 아닐시 삭제해준다고 보면 된다.
{
free(*curr);
(*curr) =NULL;
}
}
return correct_check; //삭제한 상황을 알려줘야하니 리턴해준다.
}
Algorithm printf_all(curr,word_index)코드구현
void printf_all(struct Trie_node * curr,int word_index) //모든 단어들을 출력해주는 함수이다,
{
if (!nochildren(curr)) //저장된 알파벳이 없다면 출력할 것이없으므로 내려갈필요도없다.
for (int Alpha_index =0; Alpha_index < Alpha_Size; Alpha_index ++) //저장된 알파벳을 찾기위한 반복문이다.
{
if ((curr)->children[Alpha_index]) //해당 알파벳이 저장되있다면을 분석해주는 if문이다.
{
for (int start_index =0; start_index < word_index; start_index ++) //몇번쨰 글자인지 표시해주기위해서 사용하는 반복문
{
printf(" ");
}
printf("%c", Alpha_index +'a');
if (((curr)->children[Alpha_index])->word_end ==1) //문자의 마지막이라는것을 알려준다.
printf("!\n"); //!가 마지막이라는 표시이다.
else
printf("\n"); //아니라면 그냥 개행해준다.
printf_all((curr)->children[Alpha_index], word_index +1); //그 다음글자라는 뜻이므로 word_index를 1더해준다.
}
}
}
테스트함수들
serch_check
void search_check(struct Trie_node * root, const char * word) //검색하였을때 어떤 상태인지 알려주기위한 함수이다.
{
int correct_check =0; //검색이 종료되고 어떤상황인지 알려주는 변수
correct_check = Word_search(root, word);
if (correct_check ==1)
printf("%s 단어를 찾았습니다.\n", word);
else if (correct_check ==-1)
printf("%s 단어를 찾지못했습니다.\n", word);
else if (correct_check ==-2)
printf("%s 단어를 찾지못했습니다. 문자열은 있으나 단어가 아닙니다.\n", word);
else
printf("예기치못한 에러발생.\n");
}
delete_check
void delete_check(struct Trie_node ** curr, const char * word, int choose_mode) //삭제하였을때 어떤 상태인지 알려주기위한 함수이다. 단어삭제,문자열삭제 두개가 있으므로 모드를 1,2,중에 선택하면 된다.
{
int correct_check =0; //삭제가 종료되고 어떤 상황인지 알려주는 변수
if (choose_mode ==1) //1번 모드면 단어삭제
{
correct_check = Word_delete(&(*curr), word);
if (correct_check ==1)
printf("%s 단어를 삭제하였습니다. 해당 단어를 단어를 포함하는 단어가 존재하지않아 해당단어는 남지않을 것입니다.\n", word);
else if (correct_check ==2)
printf("%s 단어를 삭제하였습니다.하지만 해당 단어를 포함하는 단어가있어 문자열은 남아있을 것입니다.\n", word);
else if (correct_check ==-1)
printf("%s 단어를 찾지 못해 삭제를하지못합니다.\n", word);
else if (correct_check ==-2)
printf("%s 문자열은 찾으나 단어가 아니여서 삭제를하지못합니다.\n", word);
else
printf("예기치못한 에러발생.\n");
}
else if (choose_mode ==2) //2번 모드면 문자열 삭제
{
correct_check = Word_delete_with(&(*curr), word);
if (correct_check ==1)
printf("%s 문자열을 찾는데 성공해 해당 문자열로 시작하는 모든 단어들을 삭제하였습니다.\n", word);
else if (correct_check ==-1)
printf("%s 문자열을 찾지 못해 삭제를하지못합니다.\n", word);
else
printf("예기치못한 에러발생.\n");
}
else
printf("삭제 모드를 잘못 선택하셨습니다.");
}
구현한 자세한 방법은 주석을 참고하길 바란다. 각각의 기능과 에러가 어떤 경우인지, 처리해줘야할 경우의 수가 몇 개인지 써 놓았다.
나는 노드를 리턴값으로 받으면 밑에 테스트할 때 메인함수에서 편집된 노드를 다시 받아와야하는 것이 보기도 싫고 귀찮기도 하였다. 그래서 포인터의 주소값을 넘겨주고 함수의 인자로 받을 때는 이중 포인터로 받아주었다. 그래서 메인함수에서 함수의 리턴값을 받아줄 필요가 없다. 검색, 삭제에 있어서 어떤 결과 값들이 발생하는지 생각해보고 최대한 모든 경우를 사용자에게 알려줄 수 있도록 노력하였다. 그 노력이 테스트 함수들에 나타난다. 최대한 테스트할 때 사용자는 함수만 입력할 수 있도록 구현하여 사용자가 최대한 편하게끔 구현하였다. 중간에 Word_delete함수에서 경우들은 하나하나 따져보고 교수님의 ppt에서는 if if 문 처리 되어있던 것을 if elseif 문으로 바꾸어 차이는 없겠지만 보다 더 효율 적으로 구현하였다. 이에 대해 자세히 이야기하자면 원래는 word_end의 변수값을 비교해주고 자식이 없다면 삭제시켜주는 것이였는데 나는 자식노드가없다면 당연히 단어의 마지막이라고 생각하고 그 순서를 바꾸어주었다. 그렇게 else if 로 구현 할 수 있었다.
코드 실행 결과와 분석들은 구현단계에 정리하였다.
6. 참고 문헌
https://4legs-study.tistory.com/91
https://lotuslee.tistory.com/54
https://m.blog.naver.com/cjsencks/221740232900
https://nooblette.tistory.com/312
https://mattlee.tistory.com/30
