
1.개요
1. 목적
만약 우리가 여러 개의 단어들을 가지고있고, 그 단어들을 저장하고 검색하고싶다면 어떤 방식을 사용하면 좋을까? 우리가 배운 자료구조들은 많다. 예를들어 배열,리스트,트리,그래프,해시테이블등등말이다.
배열과 리스트를 적용시켜보자. 단순하게 일일이 비교해보면 된다. 하지만 컴퓨터는 이러한 방법이 매우 비효율적이다. 예를 들어, 최대 길이가 m인 문자열 n개의 집합에서 마찬가지로 최대 길이가 m인 임의의 문자열이 그 문자열들의 집합에 포함되는지를 일일이 확인하면 사전처리는 필요 없지만, 최악의 경우 O(nm)의 비교 횟수가 필요하다.
그 다음으로 이 문자열을 정렬시킨뒤, 이진 탐색이라는 알고리즘을 적용시켜보자. 참고로 이진탐색 알고리즘은 전체 문자열을 사전 순으로 배열 저장 후, 중간 값과 비교해 사전적으로 이전이면 좌측의 반 / 이후면 우측의 반으로 비교하는 방식을 반복하는 알고리즘이다.최대 문자열의 길이가 m이고, 전체 문자 개수가 n개시 시간복잡도는 정렬은 O(nmlogn) 탐색은 O(mlogn) 즉 O(nmlogn) 으로 단축시킬 수 있지만, 이것도 비효율적이다.
하지만 위의 시간 복잡도를 압도하는 알고리즘이 존재한다. 바로 트리구조이다. 트리구조가 무엇이냐면 일반적으로 대상 정보의 각 항목들을 계층적으로 구조화할 때 사용하는 비선형 자료구조이다. 이 트리구조가 왜 단어들을 관리하는 것에 효율적이냐면 트리의 구조는 '데이터 저장'의 의미보다는 '저장된 데이터를 더 효과적으로 탐색'하기 위해서 사용되기 때문이다.
트리구조에서도 여러 가지 종류들이있다. 예를들어 이진트리, B-tree, 포레스트, 트라이등등 말이다. 하지만 여기에 딱 맞는 자료구조가있다. 문자열로 구성된 여러 개의 단어들을 효율적으로 인덱싱하고 관리하기 위한 방법으로 널리 활용되는 자료구조인 트라이이다. 트라이는 영어 단어 “retrieval”로부터 유래하였다. 트라이에대해 간단히 설명해주자면 트라이에서 각 노드는 26개의 알파벳 문자(a~z) 중 하나를 저장하고 각 노드는 총 26개의 자식 노드를 가질 수 있다. 즉 26진 트리 루트 노드에서 시작하여 top-down 방식으로 노드를 방문하면서 단어를 검색하는 자료구조이다. 이 보고서는 트라이라는 알고리즘을 이용하여 단어를 효율적으로 삽입, 검색, 제거하는 알고리즘을 이용하여 코드를 구현해볼 것이고 그것을 기록해 볼 것이다.
2. 보고서 요약
목적에서 말했듯이 이 구현 보고서는 트라이에 대해 알아보고 알아본 것을 기록하기 위해 제작하였다. 당연히 트라이의 여러 가지 특징들을 분석하고 기록 할 것이고 개요에서도 분석했듯이 트라이라는 자료구조가 왜 단어를 관리하는데 효울적인지 자세하게 다른 자료구조와도 비교해 볼 것이다. 그리고 구현보고서이니만큼 삽입,검색,삭제 알고리즘을 기반으로 코드구현을 해본 결과를 기록하고 그 결과를 분석할 것이다. 그 외에도 트라이를 활용하여 어떤 응용프로그램을 구현할 수 있는가 등 여러 가지 논의주제에 대해 내 생각들을 기록 할 것 이다.
3.제약조건
본 문제에서는 영어 소문자로 구성된 단어만을 고려한다.
2. 프로그래밍 언어를 활용한 구현
1. 알고리즘 구현 코드와 각 라인 별 기능 설명
#include <stdio.h >
#include <stdlib.h >
#include <string.h >
//알파벳의 갯수가 26개이므로 선언
#define Alpha_Size 26
struct Trie_node //구조체 선언
{
struct Trie_node * children[Alpha_Size]; //알파벳사이즈크기만큼 미리 만들어줘야함.
int word_end; //마지막문자라고 알려주는 용도.
};
struct Trie_node * Get_node() //노드를 기본적으로 만들어주는 함수
{
struct Trie_node * node = (struct Trie_node *)malloc(sizeof(struct Trie_node));
if (node !=NULL) //malloc이 실패한다면 node가 NULL포인터를 갖게된다. 따라서 NULL 포인터의 변수를 참조해서 초기화하는 경우가 생길 수 있다 .따라서 이를 방지하고자 삽입한 코드이다.
{
node->word_end =0; //초기화
for (int index =0; index < Alpha_Size; index ++)
{
node->children[index] =NULL; //초기화
}
}
return node; //초기화시켜준 노드 반환.
}
void Word_insert(struct Trie_node ** root, const char * word) //노드를 삽입하는 함수.
{
struct Trie_node * curr = (*root);
int index =0;
while (word[index]) //단어의 첫번째 문자.
{
int idx = word[index] -'a'; //단어의 첫번째 문자 - a하면 알파벳상의 그 문자의 index가 나온다. 예) c-a -> 2
if (curr ->children[idx] ==NULL) //문자가 들어갈 공간이 비어있다면 채워준다.
{
curr->children[idx] = Get_node(); //이 때 위에 선언한 Get_node()가 나온다.
}
curr = curr ->children[idx]; //그 다음 문자를 삽입하기 위해 자식노드로 넘어간다.
index = index +1;
}
curr->word_end =1; //while문이 끝났다는건 단어삽입이 끝났다는 것이니까 마지막문자라고 표기해주기위해 word_end 값을 1로 표기해준다.
}
int Word_search(struct Trie_node * root, const char * word) //단어를 검색하는 함수이다.
{
if (root ==NULL) //넘겨준 트라이가 비었을경우 오류출력. (거의 GetNode를 안해줄 경우 발생한다.)
return 0;
struct Trie_node * curr = root;
int index =0;
while (word[index]) //똑같이 첫번째 문자부터 시작한다.
{
int idx = word[index] -'a'; //위와 마찬가지.
curr = curr ->children[idx]; //자식노드로 넘어가기
if (curr ==NULL)
return -1; //해당단어가 없는 경우. 리턴해줘서 바로 끝냄.
index = index +1;
}
if (curr ->word_end ==1)
return curr ->word_end; //해당단어가 있는경우
else
return -2; //해당문자열은 있으나 해당단어가 없는경우
}
int nochildren(struct Trie_node * curr) //자식이 있는지 없는지만 판단한다.
{
for (int index =0; index < Alpha_Size; index ++)
{
if (curr ->children[index] !=NULL) //자식이 하나라도 있을경우 바로 리턴으로 탈출한다.
return 0;
}
return 1;
{
}
}
int howchildren(struct Trie_node * curr) //자식노드가 몇개있는지 알려주는 함수.
{
int children_index =0;
for (int index =0; index < Alpha_Size; index ++)
{
if (curr ->children[index] !=NULL) //자식이있다면 children_index을 1더해준다.
children_index++;
}
return children_index; //자식의 개수를 리턴해준다.
}
//삭제하는 것에는 1.단어를 찾아 삭제하는 경우 2.단어를 찾지못해 삭제하지못하는 경우로 나뉜다.
//이때 1번의 경우 맨끝의 단어에 자식노드가 있는경우와 없는경우로 나뉜다. 자식노드가 있는경우에는 word_end의 변수값만 0으로 바꾸고 넘어간다. 하지만 자식노드가 없는경우에는 또 두가지로 나뉜다. 삭제하는 도중 분기가 발생하냐 안하냐이다. 이 두가지 모두 자식노드가 없거나 word_end의 변수값이 0 인경우에만 or으로 처리해주면 된다.
//2번에 경우에는 또 두가지로 나뉜다. 첫번쨰인 단어의 구성요소중에 노드에 속해있지않는 경우(완전히 다른 알파벳) 이경우에는 코드에 맨 윗줄에 걸린다. 두번째인 해당 문자열은 있으나 단어가 아닌경우에는 해당 단어에 마지막 단어의 자식노드가 존재하나 word_end도 0이여서 리턴 -2 으로 오류출력처리해주었다. 이 부분에서 걸린다.
int Word_delete(struct Trie_node ** curr, const char * word)
{
int correct_check =0; //삭제가 종료되고 어떤 상황인지 알려주는 변수
if ((*curr) ==NULL)
return -1; //해당 단어를 찾지 못해 삭제를하지못합니다.
if ((*word) =='\0')
{
if (nochildren(*curr) ==1 && (*curr)->word_end ==1) //자식노드도 없고 단어의 마지막인경우 tmi 정상적인 트라이구조라면 자식노드가없다면 당연히 단어의 마지막이다.
{
free(*curr); //curr을 free처리 해줌으로 삭제처리
(*curr) =NULL;
return 1; //해당 단어를 찾는데 성공하였습니다. 해당 단어를 단어를 포함하는 단어가 존재하지않아 해당단어는 남지않을 것입니다.
}
else if ((*curr)->word_end ==1) //자식노드가 있으나 단어의 마지막인경우에는 word_end만 0으로 고쳐 단어의 마지막인 흔적을 지워준다.
{
(*curr)->word_end =0;
return 2; // 해당 단어를 찾는데 성공해 삭제하였습니다. 하지만 해당 단어를 포함하는 단어가있어 문자열은 남아있을 것입니다.
}
else
return -2; //해당 문자열은 찾으나 단어가 아니여서 삭제를하지못합니다
}
int idx = (*word) -'a'; //위와 마찬가지. 표현을 다르게 했을뿐.
correct_check = Word_delete(&((*curr)->children[idx]), word +1); //다음 단어를 넘긴다는 뜻 이것도 표현만 다르게함.
if (nochildren(*curr) ==1 and (*curr)->word_end ==0) //맨위에 함수주석에서 설명한대로 단어의 상태를 이루지 못하고 문자열만 남아있는 상태인 애들을 지워준다.
{
free(*curr); //만약 여기들어왔다면 문자열만 남았다는 상태이므로 삭제.
(*curr) =NULL;
}
return correct_check; //삭제해준 상태를 알려주기위해 check변수를 리턴.
}
int delete_all(struct Trie_node ** curr) //직접 새로구현해준 함수이다. 해당 문자열을 포함하는 단어를 모두 삭제하는데 쓰인다. -> 그냥 문자열을 삭제한다.
{
if (!nochildren(*curr))
for (int index =0; index < Alpha_Size; index ++)
{
if ((*curr)->children[index])
{
delete_all(&((*curr)->children[index])); //부모노드의 노드만 free해준다면 편하지만 자식노드들을 free안해준다면 메모리손실이 발생해 하나하나 찾아가주어 free해준다. 그래서 재귀함수로 구현하였다.
}
}
free(*curr); //맨마지막자식노드부터 free시켜준다.
(*curr) =NULL;
return 1; //삭제성공시 1을 반환해준다.
}
int Word_delete_with(struct Trie_node ** curr, const char * word) //문자열을 넘겨주면 해당 문자열을 포함한 모든 단어들을 삭제해준다. (단어삭제하면서 필요없어진 문자열도 삭제해준다.)
{
int correct_check =0; //삭제가 종료되고 어떤 상황인지 알려주는 변수
if ((*curr) ==NULL)
return -1; //문자열을 찾지 못해 삭제를하지못합니다.
if ((*word) =='\0')
{
if (delete_all(&(*curr))) //위에 함수가 여기서 쓰인다. 성공하였다면 1을 반환해주는 것을 이용한다.
return 1; //문자열을 찾는데 성공해 해당 문자열로 시작하는 모든 단어들을 삭제하였습니다.
else
return -2; //오류
}
int idx = (*word) -'a'; //생략
correct_check = Word_delete_with(&((*curr)->children[idx]), word +1);
if (correct_check)//삭제해주었을때만 부모노드를 조사해주면 된다. 만약 삭제해준단어가 문자열이면서 단어인경우 필요없어진 문자열이 존재하므로 그것을 삭제해준다.
{
if (nochildren(*curr) ==1 and (*curr)->word_end ==0)//부모노드들을 올라가면서 조사한다. 단어가 아닐시 삭제해준다고 보면 된다.
{
free(*curr);
(*curr) =NULL;
}
}
return correct_check; //삭제한 상황을 알려줘야하니 리턴해준다.
}
void printf_all(struct Trie_node * curr,int word_index) //모든 단어들을 출력해주는 함수이다,
{
if (!nochildren(curr)) //저장된 알파벳이 없다면 출력할 것이없으므로 내려갈필요도없다.
for (int Alpha_index =0; Alpha_index < Alpha_Size; Alpha_index ++) //저장된 알파벳을 찾기위한 반복문이다.
{
if ((curr)->children[Alpha_index]) //해당 알파벳이 저장되있다면을 분석해주는 if문이다.
{
for (int start_index =0; start_index < word_index; start_index ++) //몇번쨰 글자인지 표시해주기위해서 사용하는 반복문
{
printf(" ");
}
printf("%c", Alpha_index +'a');
if (((curr)->children[Alpha_index])->word_end ==1) //문자의 마지막이라는것을 알려준다.
printf("!\n"); //!가 마지막이라는 표시이다.
else
printf("\n"); //아니라면 그냥 개행해준다.
printf_all((curr)->children[Alpha_index], word_index +1); //그 다음글자라는 뜻이므로 word_index를 1더해준다.
}
}
}
void search_check(struct Trie_node * root, const char * word) //검색하였을때 어떤 상태인지 알려주기위한 함수이다.
{
int correct_check =0; //검색이 종료되고 어떤상황인지 알려주는 변수
correct_check = Word_search(root, word);
if (correct_check ==1)
printf("%s 단어를 찾았습니다.\n", word);
else if (correct_check ==-1)
printf("%s 단어를 찾지못했습니다.\n", word);
else if (correct_check ==-2)
printf("%s 단어를 찾지못했습니다. 문자열은 있으나 단어가 아닙니다.\n", word);
else
printf("예기치못한 에러발생.\n");
}
void delete_check(struct Trie_node ** curr, const char * word, int choose_mode) //삭제하였을때 어떤 상태인지 알려주기위한 함수이다. 단어삭제,문자열삭제 두개가 있으므로 모드를 1,2,중에 선택하면 된다.
{
int correct_check =0; //삭제가 종료되고 어떤 상황인지 알려주는 변수
if (choose_mode ==1) //1번 모드면 단어삭제
{
correct_check = Word_delete(&(*curr), word);
if (correct_check ==1)
printf("%s 단어를 삭제하였습니다. 해당 단어를 단어를 포함하는 단어가 존재하지않아 해당단어는 남지않을 것입니다.\n", word);
else if (correct_check ==2)
printf("%s 단어를 삭제하였습니다.하지만 해당 단어를 포함하는 단어가있어 문자열은 남아있을 것입니다.\n", word);
else if (correct_check ==-1)
printf("%s 단어를 찾지 못해 삭제를하지못합니다.\n", word);
else if (correct_check ==-2)
printf("%s 문자열은 찾으나 단어가 아니여서 삭제를하지못합니다.\n", word);
else
printf("예기치못한 에러발생.\n");
}
else if (choose_mode ==2) //2번 모드면 문자열 삭제
{
correct_check = Word_delete_with(&(*curr), word);
if (correct_check ==1)
printf("%s 문자열을 찾는데 성공해 해당 문자열로 시작하는 모든 단어들을 삭제하였습니다.\n", word);
else if (correct_check ==-1)
printf("%s 문자열을 찾지 못해 삭제를하지못합니다.\n", word);
else
printf("예기치못한 에러발생.\n");
}
else
printf("삭제 모드를 잘못 선택하셨습니다.");
}
int main()
{
struct Trie_node * song =0; //아무것도 없을경우 오류 잡는것을 보여주기위해 사용.
search_check(song, "abc");
song = Get_node();
Word_insert(&song, "bit");
Word_insert(&song, "bite");
Word_insert(&song, "stuff");
Word_insert(&song, "study");
Word_insert(&song, "student");
Word_insert(&song, "the");
Word_insert(&song, "them");
Word_insert(&song, "there");
printf_all(song,0);
search_check(song, "stuf");
search_check(song, "stuff");
search_check(song, "stud");
search_check(song, "th");
search_check(song, "s");
search_check(song, "zo");
search_check(song, "song");
search_check(song, "bit");
delete_check(&song, "bit", 1);
delete_check(&song, "the", 1);
delete_check(&song, "there", 1);
printf_all(song, 0);
delete_check(&song, "st", 2); //st로 시작하는 단어를 전체삭제하였으므로 해당 단어가 모두사라짐.
printf_all(song, 0);
delete_check(&song, "s", 2); //위에서 st로 시작하는 모든 단어를 삭제했으므로 해당 문자열로 시작하는 모든 단어가 사라졌음 그래서 s로 시작하는 단어가 없음.
printf_all(song, 0);
delete_check(&song, "t", 2); //문자열 t로 시작하는 단어 삭제.
printf_all(song, 0);
}2. 구현 결과 화면(screenshot) 및 결과 논의
-트라이에 단어 삽입을 위해 {bit,bite,stuff,study,student,the,them,there}을 이용한다.
소스코드
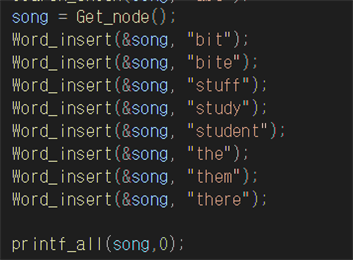
결과화면

-트라이에서 단어의 검색을 위해 위의 집합에 포함된 단어를 사용한다. 또한 위의 집합에 포함되지 않은 단어를 입력하여 수행된 결과를 확인한다.
소스코드
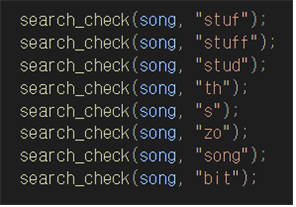
결과화면

-삭제할 단어를 bit,them,there로 주어 수행결과를 확인한다.
소스코드

결과화면
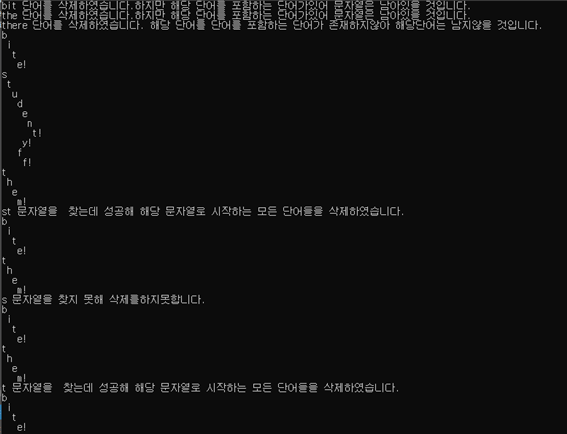
결과논의
문제에서 지정한 단어인 {bit,bite,stuff,study,student,the,them,there}를 삽입하는데 성공하였다. 이중포인터를 사용하였으므로 주소값을 넘겨주면 루트노드가 바뀐다. 이중포인터를 사용하지 않는방법으로도 짜보았었는데 리턴값으로 node를 리턴해주어 값을 받아와야한다. 이 모습이 이쁘지않아 이중포인터를 사용하는방식으로 바꾸었다. 어떤방식으로 넣는지는 소스코드에도 나와있고 결과보고서에 기술 할 것이기 때문에 간단히 설명해주자면 맨처음에는 루트노드에 아무값이없다. 하지만 bit를 삽입해줄 때 node에 children[해당 알파벳index(예를 들어 a면 0 c면 2이다.)]에 노드를 삽입해준다. bit의 첫글자는 b이므로 children[1]이다. 그런 식으로 삽입할 단어의 마지막까지 while문으로 돌면서 삽입해준다. 그리고 word_end변수를 1으로 바꾸어서 마지막 단어라고 표시해준다.
그 다음은 검색기능을 테스트해보았다. 어떤 단어를 검색했을 때 나올 수 있는 것은 검색을 성공했느냐 못했느냐이다. 여기서 검색을 성공했을 때는 한가지밖에 나올 수 없으나. 검색을 성공하지 못했는 경우 즉 그 단어가 없을 경우에는 두가지 경우가 나온다. 첫 번째로는 해당단어가 아예없는 것이다. 예를 들어 삽입한 단어들은 song,bit가 있으나 내가 검색을 갑자기 쌩뚱맞게 sony를하거나 young를 하면 당연히 해당 단어가없다고 나올 것이다. 두 번째 경우는 해당문자열은 존재하나 단어가 없다는 것이다. 이 경우를 이해하기 쉽게 설명하자면 저장하고있는단어가 내가 검색한 단어를 포함할때이다. 예를 들면 이해하기 쉽다. song을 저장하였는데 son이라는 단어를 검색했을 경우이다. 소스코드와 실행결과를 보면 stuf를 검색했으나 노드에는 stuff라는 단어가 저장되어있어 stuf라는 문자열은 존재하고있다고 알려주는 모습이다. 당연히 song이라고 검색했을때는 노드에는 song이 존재하지않아 찾아주지 못하는 모습이고 bit를 검색했을 때에는 bit라는 단어를 저장하고있기 때문에 잘 찾아준 모습을 볼 수있다. 검색기능도 코드도있고 후에 결과보고서에 자세히 기술할 것이기 때문에 간단히 설명하자면 돌아가는 과정은 삽입과 비슷하다고 보면된다. 검색할 단어를 첫 번째부터 노드에 해당 단어가 존재하는지 확인한다. 만약 없다면 찾지못한 것에 첫 번째 경우이다. 하지만 만약 단어의 첫 번째문자부터 끝문자까지 존재한다면 삽입할 때 변수값인 word_end를 이용하면 된다. wor_end가 1이라면 마지막 문자라는 뜻이므로 해당 단어가 있다는 뜻이다. 만약 0이라면 못찾았을 때 두 번째 경우이다. 즉 문자열은 존재하나 단어가 없다는 뜻이다.
그다음으로 삭제기능이다.bit,the,there을 차례대로 삭제하였다. 앞에 두 단어 경우 bite와 them이 저장되어있으므로 문자열은 남아있다고 알려주었고 뒤에 단어인 there의 경우 포함하는 단어가 없어 문자열도 남지않는다고 알려준다. 그리고 printfall함수로 현재 노드의 값들을 보여준다. 잘 삭제되어 잘 출력해준다. 그리고 내가 직접 만든 함수인 문자열 삭제기능을 확인한다. st를 삭제하여 student와 stuff 남아있는 st로 시작하는 단어들을 삭제해준다.그 다음 s로 시작하는 단어를 삭제해주려고했으나 이미 st로 시작하는 단어를 삭제할 때 다 삭제해주었어서 삭제하지 못한다고 잘 알려주는 모습이다. 그리고 t로 시작하는 단어들을 모두 삭제해주어 printfall을 했을 때 bite밖에 남지않은 모습이다. 삭제도 마찬가지로 간단히 설명해주자면 삭제하는 것에는 1.단어를 찾아 삭제하는 경우 2.단어를 찾지못해 삭제하지못하는 경우로 나뉜다. 이때 1번의 경우 맨끝의 단어에 자식노드가 있는경우와 없는경우로 나뉜다. 자식노드가 있는경우에는 word_end의 변수값만 0으로 바꾸고 넘어간다. 하지만 자식노드가 없는경우에는 또 두가지로 나뉜다. 삭제하는 도중 분기가 발생하냐 안하냐이다. 이 두가지 모두 자식노드가 없거나 word_end의 변수값이 0 인경우에만 or으로 처리해주면 된다. 2번에 경우에는 또 두가지로 나뉜다. 첫번쨰인 단어의 구성요소중에 노드에 속해있지않는 경우(완전히 다른 알파벳) 이경우에는 코드에 맨 윗줄에 걸린다. 두번째인 해당 문자열은 있으나 단어가 아닌경우에는 해당 단어에 마지막 단어의 자식노드가 존재하나 word_end도 0이여서 리턴 -2 으로 오류출력처리해주었다. 그 다음에는 문자열을 이용한 삭제이다. 이 함수는 기본적인 구조는 단어삭제와 같다. 하지만 다른 점은 해당 문자열로 모든 시작하는 단어들을 모르는 상태로 삭제해줘야하기 때문에 직접 찾아줘야한다는 점이다. 이 것을 for문으로 찾아준다. 물론 자식노드들을 찾아주지않고 부모노드 하나를 지워줘도 되긴한다. 하지만 자식노드들이 해제(free)되지 않은 상태로 있기 때문에 메모리 손실이 발생한다. 이를 해결하기위해 자식노드부터 하나하나 free시켜주는 구조로 제작하였다.
출력함수인 printfall을 설명하겠다. 이 함수는 기본적인 구조는 문자열삭제의 자식노드들을 찾아주는 알고리즘과 비슷하다. 어떤 단어들이 들어있는지 모르니까 for문으로 찾아주도록 만들었다. 이 함수의 특징은 출력의 가시성을 위해서 단어의 문자들의 인덱스값을 넘겨줘야한다는 것이다. 0부터 시작하여 자식노드를 찾을때마다 word_index를 +1 시켜 함수의 인자로 넘겨준다.
delete_check와 search_check함수는 사용자를 위한 함수이다. 삭제와 검색에서 발생하는 오류들을 정리해놓고 삭제나 검색 행동 후에 발생하는 결과나 오류를 출력해준다.
3. 논의
1. 트라이 자료구조가 이진 탐색 트리, 해시 테이블 등의 자료구조와 비교했을 때 갖는 장점과 단점에 대해 기술할 것.
일단 트라이에 대해 설명해주겠다. 트라이는 간단히 말하자면 문자열을 빠르게 탐색해주는 자료구조이다. 즉 문자열을 관리하는 방법 중의 하나라고 생각하면 편하다. 트라이는 기본적으로 k진 트리구조를 보이고 있다. 저장하는 방식과 검색하는 방식은 영어사전을 생각해보면 도움이된다. 만약 본인이 song이라는 단어를 저장하려면 단어의 첫 번째문자인 s부터 끝 문자인 g까지 순서대로 트리구조로 저장한다. 그리고 검색할때에는 마찬가지로 s부터 g까지 비교하며 검색한다. 이것을 논리적으로 컴퓨터에 적용한구조가 트리구조이다. 아래는 이해를 도와줄 사진이다.
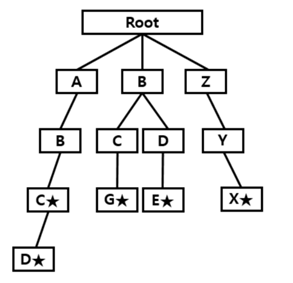
이 트라이 구조는 당연히 문자를 하나씩 저장하므로 저장공간을 많이 사용한다. 하지만 장점은 확실하다. 탐색이 빠르다는 것이다. 그러한 장점으로 O(M)의 시간복잡도 (가장 길이가 긴 Strings의 길이(M)만큼만 탐색하면 된다)를 가진다. 참고로 삽입, 검색, 삭제 모두 같은 시간복잡도를 가진다.단점인 저장공간에 대해 설명하자면 각 노드는 자식에 대한 포인터를 모두 저장하므로 공간을 많이 차지한다. 그래서 공간복잡도는 주어진 단어의 길이가 len이고 삽입된 전체 단어의 수가 no 일 때 O(Alpha_size x len x no )만큼의 공간을 차지한다.
추가로 트라이의 장점을 한가지 더 설명해주겠다. 트라이에 단어들을 삽입한다고 했을 때 그 단어들이 자동으로 정렬된다고 하는 점이다. 위에 사진에서 삽입한 단어들이 [ABC , ABCD , BCG , BDE , ZYX] 존재하고 우리가 이 단어들의 삽입할 때 역시 [ABC , ABCD , BCG , BDE , ZYX] 이 순서대로 삽입했다고 하자. 하지만 만약 여기서 [ABC , BCG , ZYX, ABCD , BDE] 이 순서대로 삽입했다고 하자. 그렇다고 해도 트라이의 구조자체는 동일 할 것이다. 즉 순서를 변경한다고해도 트라이에 저장된 단어들의 구조는 변함 없다는 뜻이다. 이렇게 트라이는 삽입순서를 바꿔도 정렬된 형태로 저장해준다는 장점이있다.
트라이에 대해 설명해주었으니 이제 여러 자료구조들과 비교해보겠다.
먼저 배열이다. 배열은 검색에 경우 최대 길이가 m인 문자열 n개의 집합에서 마찬가지로 최대 길이가 m인 임의의 문자열이 그 문자열들의 집합에 포함되는지를 일일이 확인하면 사전처리는 필요 없지만, 최악의 경우 O(nm)의 비교 횟수가 필요하다.
당연히 트라이보다 느리다. 하지만 배열은 안쓰는 이유가 좀 특별하다고 생각한다.기초레벨1에서 설명했듯이 배열을 쓰지않는 이유는 원소가 삽입/삭제된다고 생각한다면 배열은 너무나 비효율적인 구조이기 때문이다. 우리가 현재 트라이 구조를 만들면서 삭제를 할 때 문자를 하나씩 삭제를 하기 때문에 배열 자료구조는, 삽입/삭제 될 Index 를 찾은 후, 그 Index 뒤에 위차한 원소들을 한칸씩 전부 뒤로 이동해야 하는 수고가 존재한다. 또한, 배열공간이 모자라, 배열 크기를 증가시키거나 혹은 공간이 너무 남아, 축소 시키는 작업은 덤으로 발생할 수 있다. 반면 트리구조는 그에 반면에, 트리 구조는 참조(포인터)만 변경해주면 되므로, 원소의 대량 이동이 필요 없고, 공간 복잡도를 신경안써도 되는 장점이 있다. 그렇다보니, 삽입/삭제 연산이 한번이라도 존재한다면, 이는 삽입이 연속적으로 N번 발생할 수도 있다는 의미이므로 굳이 배열 자료구조를 사용할 필요가 없다. 배열구조의 장점이 있다면 구현하기 쉽다는 것과 저장공간에 있어서 포인터의 저장공간이 필요없어 트라이보다 효울적일 수 있다.
그다음으로는 리스트 자료구조와 비교해보겠다. 리스트는 배열과 달리 원소들 간의 논리적인 순서를 위한 자료구조이다. 아래는 이해를 도와줄 예시이다.

포인터를 이용해 구현된 리스트를 연결 리스트(linked list)라고 한다. 이 경우 위에서 말했던 삽입/삭제부분에서는 배열보다 좋은 모습을 보여준다. 왜냐하면 배열과 다르게 삽입할 때 에는 ① 삽입할 노드를 생성한다. ② 삽입할 노드의 링크가 삽입될 위치의 후행 노드를 가리키게 한다. ③ 삽입될 위치의 선행 노드의 링크가 삽입할 노드를 가리키게 한다. 삭제할 경우에는 ① 삭제할 노드의 선행 노드의 링크가 삭제할 노드의 후행 노드를 가리키게 한다. ② 삭제할 노드를 메모리에 반환한다. 이 규칙만 지켜준다면 새롭게 선언할 필요도없기 때문이다. 하지만 연결리스트의 경우에는 트라이보다 검색,삭제,삽입분야에서 취약하다. 연결리스트에 단어의 문자 하나씩 담았다면 당연히 나무처럼 뻗어있는 트리보다 느릴 것이다. 연결리스트에 단어 하나를 담았을 때 시간복잡도가 O(n)의 시간복잡도를 가진다. 하지만 여러 개의 단어를 담는순간 그 배수만큼 늘어날 것이다. 당연히 트라이가 더 효율적이다. 장점이있다면 구현하기 쉽다.
그다음으로 그래프자료구조와 비교해보겠다. 그래프란 단순히 노드(N, node)와 그 노드를 연결하는 간선(E, edge)을 하나로 모아 놓은 자료 구조이다. 간단히 설명하자면 그래프는 트리와는 다르게 루트노드의 개념도 없고 부모자식의 개념도없다. 그냥 단순히 노드들을 이어준 것이다. 아래는 이해를 도와줄 사진이다.

이 경우에는 단어를 삽입하기에도 힘들다. 왜냐하면 단어의 문자들의 순서를 하나하나 다 지정해줘야하기 때문이다. 마찬가지로 검색, 삭제 역시 힘들 것이다. 당연하게도 트라이보다 비효율적이다.
그다음으로는 이진탐색트리와 비교해보겠다. 이진탐색트리는 이진트리로 자료가 구성되는 트리중 하나인데 이진트리는와 다른점은 특정 규칙(rule)에 의해 자료가 저장되어 진다. 이진탐색트리는 이름에서 유추할 수 있듯이 탐색을 위한 트리 자료구조이라 자료 검색에 성능이 좋다. 아래는 이해를 도와줄 예시이다.
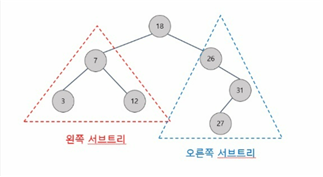
간단하게 사진과함께 설명해주자면 왼쪽 서브트리에는 루트키(18)보다 작은 값들만 모아져 있으며, 오른쪽 서브트리에는 루트키(18)보다 큰 값들만 모아져 있다. 이러한 룰은 왼쪽 서브트리 자체에도 적용된다. 왼쪽 서브트리로 내려간 순간, 새로운 루트키(7)을 기준으로 왼쪽에는 7보다 작은 3이, 오른쪽에는 7보다 큰 12가 위치하고 있다. 이러한 조건을 만족하는 것이 이진 탐색 트리다. 우리는 현재 영 단어를 저장하고 검색하고 있으니 해당단어의 인덱스의 숫자를 이용하여 저장할 것이다.
이진 탐색트리의 검색에 대한 시간복잡도는 균형 상태이면 모든 연산은 트리안에서 수행되므로 O(logN)의 시간이 걸리고 불균형 상태라면 한쪽으로 편향된 상태이므로 최대 O(N) 시간이 걸린다. 문자에대한 이진탐색트리의 경우 메모리는 트라이와 비슷할 것이다. 하지만 탐색에서는 트라이가 더 빠르다. 그래서 트라이가 더 효율적이다.
하지만 노드들을 단어의 문자로 놓지않고 문자열에대한 이진트리를 적용한다면 가장 길이가 긴 문자열의 길이가 M이라면 두 문자열을 비교하는데 O(M) + 문자열의 총 개수 O(LogN) 이므로 O(MlogN)만큼 시간복잡도를 가진다.
아래는 문자열에대한 이진탐색트리를 적용한 예시이다.
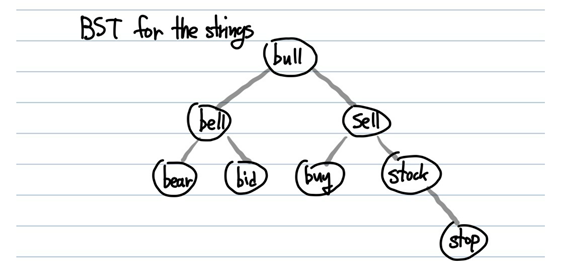
이 경우에 장점은 저장공간을 아낄 수도 있다는 점이다. 왜냐하면 트라이의 경우 단어들의 문자들이 많이 겹칠 경우 효율적으로 저장하지만 만약 하나도 겹치지않는다면 정말 메모리를 많이 쓸 것이다. 하지만 이 문자열에대한 이진 탐색트리의 경우에는 단어자체를 저장하기 때문에 상관없다. 하지만 이 경우는 굉장히 특수한 상황을 가정한 경우이다. 일반적으로는 트라이가 더 효율적이다.
마지막은 해시테이블과 비교하겠다. 해시테이블은 해시함수를 사용하여 키를 해시값으로 매핑하고, 이 해시값을 색인(인덱스) 또는 주소삼아 데이터를 key와 함께 저장하는 자료구조이다. 단순하게 key - value로 이루어진 자료구조라고 생각하면 된다.
아래는 이해를 도와줄 예시이다.

그림을 보면 알겠지만, 이론상 해시함수가 이상적이라면, 각 바구니에는 단 하나의 값만 담길 것이고, 검색시간복잡도는 O(1)이 된다. 그러나 최악의 해시함수를 사용해서 단 하나의 바구니에 모든 값이 담기면 O(n)이겠지만 일반적으로 최대한 많은 바구니를 만들도록 해시함수를 사용하므로 그럴일은 없다고 본다. 아래사진은 해시테이블을 이용한 단어를 저장한 예시사진이다.

해시함수는 인덱싱을 하는데 사용하는 배열로 이름을 넣어주면 어느 바구니로 가야하는 지 알려주는 함수를 의미한다. 위 사진에서는 해시함수를 단어의 첫글자로 인덱싱 한 사진이다. 사진처럼 트라이와는 다르게 정렬되지않은 모습을 보여준다. 물론 해시함수를 이상적으로 잡는다면 해시테이블도 트라이와 마찬가지로 정렬된 모습을 보여줄 것이다. 하지만 굉장히 어려운 일이라고 생각한다.
해시와 트라이를 비교하면서 여러 가지 자료들을 보던중 흥미로운 자료를 들고왔다.해시와 트라이의 속도를 비교해 보았다. 데이터는 약 30만 어절(문자열)이고 트라이로 만들었들때 8.5M정도의 파일로 만들어 지고 해시로 만들었을때는 18M정도가 된다. 트라이는 ARRAY 상에서 index를 이동하는 방식으로 구현하였고 해시는 finger print hash function을 사용하여 구현하였다. 우선 입력으로 들어간 문서에 대해 검색시간을 비교하니 해시가 2배가까이 빠른 처리 속도를 보였다. 트라이 : 1.4/s 해시 : 0.7/s 이 자료에서 한눈에 볼 수 있듯이 저장공간은 트라이가 효율적이다. 하지만 속도는 해시를 이길 수 없다. 요즘은 저장공간의 발달로 공간복잡도보다는 시간복잡도가 더 중요하므로 해시가 더 효율적이라고 본다. 하지만 트라이도 충분히 빠른 속도를 보여주기도하고 앞에서 말했듯이 자동으로 정렬된 효과도 보여준다. 상황에 맞춰서 둘중에 하나를 선택해서 사용하면 될 것같다.
2. 트라이를 활용하여 어떤 응용 프로그램을 구현할 수 있는가에 대한 본인의 아이디어를 간단한 도면을 첨부하여 자유롭게 기술할 것.
나와 같은 대학생들은 대학교를 다니며 정말 많은 과제들을 한다. 하지만 이 과제들을 정리해두지는 않는다. 정리해둔다고해도 개인의 컴퓨터에 폴더를 만들어 정리를 해둔다. 이 경우 컴퓨터가 고장나 포맷되다면 다 삭제된다는 문제점이 있다. 나의 경우에도 최근에 컴퓨터가 고장나 초기화를 시켜서 지금까지 했던 1학년과 2학년 과제들이 전부 날아갔다. 과제들을 저장 시켜야하는 이유가 무엇이냐면 여러 가지 것들을 배우는 대학교 특성상 공부한 것이라도 학기가 끝나고 방학중에 공부를 게으르게 한다면 다 까먹는다. 기억을 되살려서 다음학기를 시작할 때 자신이 한 과제를 보는 것만큼 효과적인 것은 없다고 본다. 혹시 옛날 기억이 잘 나는가? 아마 대부분 옛날 기억이 잘 나지않을 것이다. 하지만 옛날 사진을 본 적이 있는가? 옛날에 찍은 사진을 보면 사람들을 그때의 추억이 되살아나기 마련이다. 과제도 똑같다고 본다. 자신이 열심히 한 과제를 보면 그때의 생각이 난다. 컴퓨터공학과로 예를 들면 까먹었던 프로그래밍하는법 이라던지 자료구조라던지 다 기억이 나기 마련이다.
또한 과제가 중요한 이유는 나중에 취업할 때 포트폴리오로 쓰일 가능성이 있기 때문이다. 나중에 취업을 할 때 본인이 공부한 것을 보여주어야 할 것인데 그때 아무것도 남아있지않다면 후회할 것이다. ‘미리미리 저장해놓을걸’이라고 말이다. 또한 앞에서도 말했듯이 자신이 했었던 과제들을 본다면 자신이 무엇을 했었는지 갈피가 잡힐 것이고 포트폴리오를 쓰기에도 보다 더 쉬울 것이다.
이러한 이유들 때문에 과제를 보관하는 것은 굉장히 중요하다. 그래서 나는 이러한 문제들 때문에 학생이 과제를 내면서 자동으로 저장해주는 학생과제관리 프로그램을 만들고싶다. 물론 과제를 내면 저장해주고있긴하다. 현재 우리학교는 강의지원시스템에 과제를 올리고 그 과제를 저장해주는방식이다. 아래사진을 참고하면 이해하는데 도움이 될 것이다.

사진처럼 현재 우리의 저장방식은 굉장히 사용자에게 친절하지않다고 할 수 있다. 물론 과제를 제출하는용도이지 저장하는용도가 아니일 것이기 때문이다. 또한 과제만 저장해줄 뿐이지 추가적으로 내가 필기했던 것이라던지 공부했던 것들은 어디에도 저장해주지않는다.
또한 혹시 그런 경험이있는가 무언가를 검색하고싶은데 단어 하나가 기억나지않아서 검색하지못하고 고통받던 경험이? 사람들은 아마 이런경험은 한번쯤있을 것이다. 과제또한 그렇다 만약 과제를 어디에 저장해놓았는데 “아~ 이거 했었는데 뭐였지~ 트무슨 자료구조였는데”이 정도만 기억난다고 할 때 해결방법은 무엇이 있을까? 바로 ‘2022트’만 검색했는데 ‘2022트라이과제’가 뜬다면 바로 기억날 것이다. 바로 검색어 추천 및 자동완성 기능이다.
정리해보자 과제를 저장하고 싶고 효율적으로 관리하고싶다. 이때 말하는 효율적관리란 삭제, 삽입, 검색을 모두 포함하며 추가로 자신이 과제를 검색하려고했을 때 검색어를 자동으로 완성하거나 추천해줘야한다. 그렇다면 이때 사용할 자료구조가 바로 트라이이다. 트라이를 활용하면 대학교과제를 효율적으로 저장할 수 있다. 왜냐하면 대학교 특성상 ‘20222어벤디트라이, 20222공윤발표자료, 20211파이썬별그리기, 20211파이썬응용별움직이기’ 처럼 저장하려는 단어의 문자들이 많이 겹치기 때문이다. 또한 검색, 삽입, 삭제 역시 효율적이다. 이에 대한 설명은 생략하겠다. 제일 중요한 것은 검색어 자동완성 및 추천기능이다. 트라이를 활용하여 이 기능을 효율적으로 구현할 수 있기 때문이다. 또한 트라이는 앞에서 말해두었든 자동으로 정렬해준다는 장점이있다. 본인이 정말 기억이 나지않을 경우 전체를 출력해서 직접 보는 것밖에 방법이 없는데 정렬이 되어있으니 찾기 보다 쉬울 것이다. 아래는 이해를 도와줄 사진이다.

위 사진은 트라이구조에 국뽕, 일본 , 한국은행 등 여러단어를 넣은 트라이이다. 검색하려고할 때 어떤 방식으로 검색어추천을 진행할까? 간단하다 자신이 기억나는 단어까지 일단 입력한다. 한국이라고 입력했을 경우 자식노드가 두 개있다 ‘은’ 또는 ‘만’이다 이 것을 추천해주면 된다. 또한 입력의 순서를 바꾸어도 트라이의 구조는 변하지않는다. 즉 정렬된다는 뜻이다. 이러면 전체출력을 하여도 사용자가 보다 쉽게 원하는 정보를 찾을 수 있다.
이렇게 트라이라는 자료구조가 대학생과제들을 저장해주는데 효율적인 자료구조라는 것을 알게되었다. 어떤 방식으로 응용프로그램을 설계하면 될지 지금부터 자세히 이야기 하겠다.

우선 저장은 위에 사진처럼 저장한다. 내가 원하는 프로그램은 학생이 강의지원시스템에 과제를 올린다면 자동으로 트라이에 삽입해주는 응용프로그램이다. 학생마다 루트노드를 가지고있고 그 밑으로 몇 년도인지, 몇학기인지, 어떤과목인지, 어떤 과제인지 저장하고 과제제목의 단어가 끝났다면 파일을 저장하는 방식이다. 만약 학생이 파일을 수정했다고해도 다시 저장해주면 된다. 그러면 덮어쓰기가 될 것이니까. 또한 강의지원시스템에 올리지않더라도 개인적으로도 저장할 수 있다. 자신이 수업시간중 필기한 것들 개인적으로 만든 수업관련프로젝트들 모두 올려야하기 때문이다.
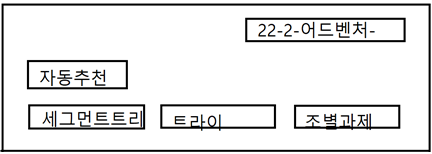
위 그림처럼 프로그램을 실행하고 22년도 2학기 어드벤처만 검색해도 저장해놓은 과제들의 이름을 자동으로 추천해준다. 자동추천해준 단어들을 마우스로 클릭한다면 바로 추가적인 검색이 되도록 구현하고 싶다.

위 그림은 트라이를 추가적으로 검색한 사진이다. 자동추천으로는 구현보고서와 결과보고서를 추천해주고있고 파일로는 트라이.py 트라이 소스코드를 보여주고 있다. 이 것도 트라이를 이용해주어 구현할 수 있는데 바로 word_end 변수를 이용하는 것이다. 저장하려는 과제의 마지막 문자이면 word_end변수를 1로 바꾸고 파일을 저장해준다. 그러면 검색할때도 word_end 변수가 1이면 파일을 보여주면 된다. 파일을 다운로드 받을때는 파일을 누르면 다운받아지도록 만들고싶다.
트라이로 구현한다면 삭제또한 굉장히 사용자에게 편하다. 만약 자신이 22년도 1학기를 다니다가 개인사정으로 휴학한다면 1학기 전체 파일을 삭제해야할 것이다. 이때는 그냥 22-1을 삭제하면 된다. 그럼 그 아래에있는 파일들은 전부 삭제 될 것이다.

그림처럼 22-1을 검색한뒤 삭제버튼을 누르면 22-1아래에있는 모든 파일들이 삭제된다. 물론 개별적으로도 지울 수 있다.
이렇게 나는 강의지원시스템과는 별개로 학생들을 위한 과제관리프로그램을 설계해보았다. 장점은 과제말고도 다른 파일들을 저장할 수 있다는점, 검색어 자동추천기능을 제공한다는점, 효율적으로 관리할 수 있다는점이있다.
3. 본 수업시간에 배운 트라이를 실제 응용프로그램에 적용하기 위해 해결해야 할 주요이슈에 대해 논의할 것
현재 내가 구현한 트라이가 응용프로그램에 적용되려고하면 우선 알파벳소문자만 저장되는 이슈를 해결해야한다. 내가 설계한 학생과제관리프로그램에서도 그렇고 사실 알파벳소문자로만 단어를 저장할 응용프로그램은 잘 없다. 알파벳소문자말고도 대문자는 물론이고 한글, 숫자, 특수기호를 저장할 수 있게 되어야지 실제 응용프로그램에 적용 될 수 있을 것같다.
그리고 더욱 더 사용자에게 친숙해져야할 것같다. 내가 최대한 사용자의 편의성을 위해서 여러기능들을 만들어 놓았는데 사용자가 쓰기에는 아직 부족한 것같다. 예를들면 출력에서 내가 사용하는 방식이 아닌 모든 단어들을 한번에 출력하는 방식으로 변경하는 등 여러 가지 방법을 이용해서 사용자에게 더 편리함을 제공해야할 것같다. GUI형식으로 만드는 것이 사용자에게는 제일 편할 것이다.
여러 가지 기능들도 추가로 구현해야 한다. 현재 우리가 만든 기능으로는 응용프로그램에 적용되기에는 많이 부족하다. 삽입, 검색, 삭제기능만을 필요로하는 응용프로그램은 없다. 내가 생각한 학생과제관리프로그램도 검색어 자동완성기능이 핵심이라고 생각한다. 솔직히 삽입, 삭제, 검색기능만을 사용할 것이면 트라이말고도 다른 자료구조를 사용해도 된다고 본다. 트라이만이 효율적인 검색어 자동완성, 추천, 맞춤법 검사기 등 여러 가지 기능들을 추가로 더 구현해야지 경쟁력이 있다고 생각한다.
또한 트라이는 앞서 여러자료구조들과 비교해보았을 때 저장공간측면에서 특히 단점을 보인다. 저장공간을 절약할 방법을 찾아야할 것같다. 이 단점을 해결하기 위해 보통 map이나 vector를 이용하여 필요한 노드만 메모리를 할당하는 방식들을 이용하는데, 문제에 따라서 메모리 제한이 적은 경우에는 최적화가 까다롭다. 그래서 생각해보았는데 최소한 자식노드가 없고 wordend 변수가 1일때에는 노드의 포인터 배열 26개를 모두 해제해주어야 할 것같다. 방법을 하나 더 생각해보았는데 영어단어기준으로 많이 등장하는 문자들이있다. 예를들어 영단어의 사람을 나타내는 -er, -or, -ee, -ian, -ent, -ist 말이다. 이러한 것들을 미리 할당해버린다면 메모리적으로 더 공간을 아낄 수 있을 것이다. 또한 추가적으로 외적에서도 해결방법을 찾아야할 것 같다. 학생과제관리프로그램에 트라이를 적용하는 예로들면 효율적인 저장을 위해 과제낼 때 제목의 형식을 통일하여야한다. 현재는 수강하는 과목마다 과제를 내는 형식이 모두 다르다. 예를들어보자 어벤디는 ‘20190633송제용기초레벨2구현보고서’라는 제목으로 제출 했고 컴퓨터구조과목은 ‘20190633송제용(컴퓨터구조과제3)’ 라는 제목으로 제출했다. 이러한 방식이 계속해서 지속될 경우 트라이의 특성상 비효율적인 저장들이 계속될 것이다. 해결책으로는 학교에서 과제를 낼 때 제목의 형식을 통일 하는 것이다. 과제의 맨처음은 학번이들어가고 그다음으로는 이름 그다음으로는 년도 그다음에는 학기 그다음에는 과목 이런 방식으로 말이다. 이럴 경우 트라이의 특성상 보다 효율적인 저장이 가능해진다. 이러한 방법들을 이용해서 최대한 공간복잡도를 보다 효율적으로 만들어줘야한다.
4. 참고문헌
https://m.blog.naver.com/cjsencks/221740232900
https://lotuslee.tistory.com/53
https://wondangcom.com/2120
https://nooblette.tistory.com/312
https://haesoo9410.tistory.com/186
https://jchern96.tistory.com/8848581
https://kldp.org/node/128037
https://mattlee.tistory.com/30
https://mommoo.tistory.com/101
https://atoz-develop.tistory.com/entry/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EB%8B%A8%EC%88%9C-%EC%97%B0%EA%B2%B0-%EB%A6%AC%EC%8A%A4%ED%8A%B8-%EC%A0%95%EB%A6%AC-%EB%B0%8F-%EC%97%B0%EC%8A%B5%EB%AC%B8%EC%A0%9C
https://m.blog.naver.com/raylee00/221944085465
https://gmlwjd9405.github.io/2018/08/13/data-structure-graph.html
https://leejinseop.tistory.com/43
https://biewoom.github.io/non%20linear%20ds/advanced%20ds/nodes%20ds/2020/04/14/Trie.html
https://velog.io/@klloo/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%8A%B8%EB%9D%BC%EC%9D%B4Trie-%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0
