재미로 만들어 보는 llm으로 맞춤법 검사기 만들기!
설계
1. 목표
- 엄청 큰 텍스트라도 입력 받을 수 있게하기.
2. 구조
- 텍스트를 입력받기
- 입력 받은 텍스트를 문장을 기준으로 분할하기
- 분할한 문장마다 llm에 넣어서 교정하기
- 교정한 문장 결합
그림으로 보면 아래와 같다.
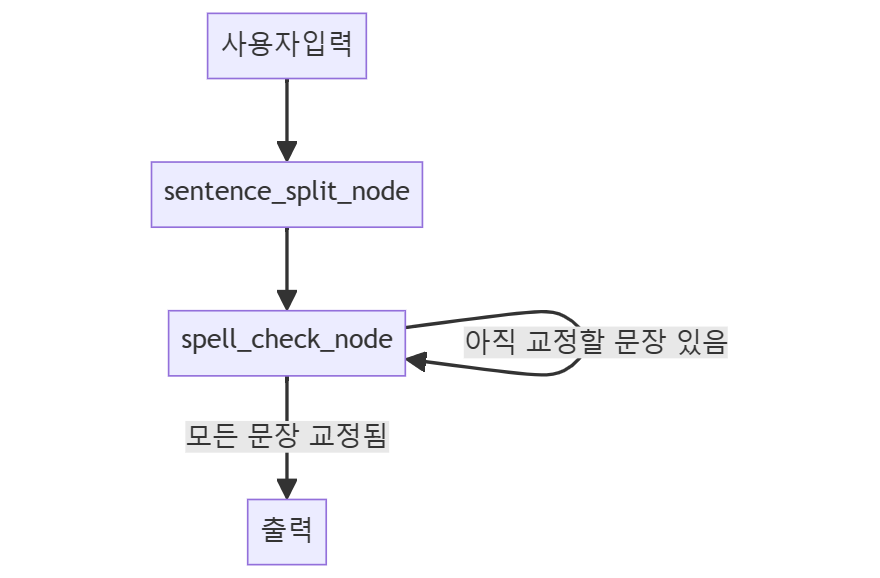
sentence_split_node는 문장을 분할하는 노드, spell_check_node는 맞춤법을 교정하는 노드로 구성했다!
3. 구현 프레임워크
- langgraph
- streamlit
구현
import streamlit as st
from typing import Annotated, List, TypedDict
from langchain_community.chat_message_histories.in_memory import ChatMessageHistory
from langchain_core.prompts import PromptTemplate
from langgraph.graph import END, StateGraph
from langchain_openai import ChatOpenAI
from openai import AuthenticationError
import operator
import relanggraph 에서 graph를 생성 할려면 우선적으로 각 그래프의 노드와 엣지에서 사용할 상태를 생성해야한다.
class State(TypedDict):
input : str
sentences : List[str]
index : int
output : Annotated[str, operator.add]input는 사용자가 입력한 텍스트고, sentences는 분할된 문장들, index는 현재 교정해야할 문장 위치, output는 교정된 텍스트다.
이제 graph를 생성하고 실행가능하도록 도와주는 클래스 SpellChecker를 정의하자!
class SpellChecker:
def __init__(self, openai_api_key:str, *, spell_check_model:str="gpt-3.5-turbo") -> None:
self.openai_api_key = openai_api_key
self.spell_check_model = spell_check_model
def get_llm(self, model:str="gpt-3.5-turbo"):
return ChatOpenAI(temperature=0,
streaming=True,
model=model,
api_key=self.openai_api_key)
def sentence_split_node(self, state:State):
pattern = r'[^.!?]+[.!?]?\s*'
return {"sentences":re.findall(pattern, state["input"]),
"index":0,
"output":''}
def spell_check_node(self, state:State):
prompt = PromptTemplate.from_template("""당신은 국립국어원소속 박사로 맞춤법을 교정하는 일을 하고있다. 아래 텍스트의 맞춤법을 교정하라.\n```\n{input}\n```""")
llm = self.get_llm(self.spell_check_model)
chain = prompt | llm
pattern = r"\s*$"
origin_text = state["sentences"][state["index"]]
blanck_text = re.search(pattern, origin_text)
input_text = origin_text[:blanck_text.start()]
response = chain.invoke({"input":input_text})
return {"output":response.content + blanck_text.group(), "index":state["index"] + 1}
def create(self):
graph = StateGraph(State)
graph.add_node("sentence_split_node", self.sentence_split_node)
graph.add_node("spell_check_node", self.spell_check_node)
graph.set_entry_point("sentence_split_node")
graph.add_edge("sentence_split_node", "spell_check_node")
graph.add_conditional_edges("spell_check_node",
lambda state: "continue" if state["index"] < len(state["sentences"]) else "end",
{
"continue":"spell_check_node",
"end":END
})
return graph.compile()뭔가 길지만 요약하면 openai_api_key를 파라미터로 받아서 초기화하고, create 함수를 통해서 실행가능한 chain을 만드는거다.
위에서 설계한 대로 sentence_split_node 함수는 문장을 분할하고, spell_check_node 함수는 llm을 통해서 맞춤법을 교정하도록 구현했다!
여기까지 진행한 상태에서 그래프의 형태를 출력해보자.
spellchecker = SpellChecker("[여기에 OpenAI API KEY를 입력]").create()
spellchecker.get_graph().print_ascii()아래와 같이 출력된다.
+-----------+
| __start__ |
+-----------+
*
*
*
+---------------------+
| sentence_split_node |
+---------------------+
*
*
*
+------------------+
| spell_check_node |
+------------------+
*
*
*
+---------------------------+
| spell_check_node_<lambda> |
+---------------------------+
*
*
*
+---------+
| __end__ |
+---------+ 제대로 교정이 되는지 시험해 보자
text = """한 번은 어떤 마을에 많은 고민을 가진 소년이 살고 있었어요. 소년의 이름은 지훈이였는데, 지훈이는 항상 공부가 너무 어렵고, 친구들과 잘 어울리지 못한다고 생각했어요. 그래서 지훈이는 매일같이 학교에 가는 것이 두려웠어요.
어느날, 지훈이는 우연히 숲속에서 오래된 책 한권을 발견했어요. 그 책에는 이상한 글자들과 그림들이 가득했는데, 지훈이는 그 책이 마법의 책이라는 것을 알게 되었어요. 지훈이는 책을 읽기 시작했고, 자신이 가진 문제들을 해결할 수 있는 방법을 찾기 시작했어요.
하지만 지훈이는 책을 제대로 이해하지 못했어요. 그는 마법의 주문을 잘못 사용해서, 자기도 모르게 주변 사람들을 곤란에 빠트리기 시작했어요. 친구들은 지훈이가 이상한 행동을 한다고 생각해서, 더 멀리하게 되었어요.
그러던 어느날, 지훈이는 마법의 책에 나오는 가장 어려운 주문을 시도해보기로 결심했어요. 그런데 이번에는 주문이 너무 강력해서, 마을 전체가 엄청난 위험에 처하게 되었어요. 지훈이는 자신의 잘못을 깨닫고, 모든 것을 원래대로 돌리기 위해 노력했어요.
결국, 지훈이는 마법의 책을 다시 읽으며 이전에는 놓쳤던 중요한 부분을 발견했어요. 그는 마법이 아닌, 진심으로 사람들에게 사과하고, 자신의 문제를 해결하기 위해 노력하는 것이 중요하다는 것을 깨달았어요. 지훈이는 친구들과 화해하고, 학교 생활에도 적극적으로 참여하기 시작했어요.
이 이야기는 우리에게, 어떤 문제도 마법이 아닌 우리의 노력과 이해를 통해 해결할 수 있다는 교훈을 주고 있어요. 지훈이처럼 우리도 어려움을 마주했을 때, 용기를 내서 문제를 직면하고 해결해 나가야 한다는 것을 보여주고 있어요."""
output = spellchecker.invoke({"input": text}, {"recursion_limit": 150})
print(output["output"])여기서 recursion_limit를 크게 할 수록 문장이 더 긴 텍스트를 교정할 수 있게된다.
출력은 아래와 같이 나왔다.
참고로 예시로 사용한 문장은 GPT보고 생성해달라고 했다.
한 번은 어떤 마을에 많은 고민을 가진 소년이 살고 있었어요. 소년의 이름은 지훈이였는데, 지훈이는 항상 공부가 너무 어렵고, 친구들과 잘 어울리지 못한다고 생각했어요. 그래서 지훈이는 매일 같이 학교에 가는 것이 두려웠어요.
어느 날, 지훈이는 우연히 숲 속에서 오래된 책 한 권을 발견했어요. 그 책에는 이상한 글자들과 그림들이 가득했는데, 지훈이는 그 책이 마법의 책이라는 것을 알게 되었어요. 지훈이는 책을 읽기 시작했고, 자신이 가진 문제들을 해결할 수 있는 방법을 찾기 시작했어요.
하지만 지훈이는 책을 제대로 이해하지 못했어요. 그는 마법의 주문을 잘못 사용해서, 자기도 모르게 주변 사람들을 곤란에 빠트리기 시작했어요. 친구들은 지훈이가 이상한 행동을 한다고 생각해서, 더 멀리하게 되었어요.
그러던 어느 날, 지훈이는 마법의 책에 나오는 가장 어려운 주문을 시도해 보기로 결심했어요. 그런데 이번에는 주문이 너무 강력해서, 마을 전체가 엄청난 위험에 처하게 되었어요. 지훈이는 자신의 잘못을 깨닫고, 모든 것을 원래대로 돌리기 위해 노력했어요.
결국, 지훈이는 마법의 책을 다시 읽으며 이전에는 놓친 중요한 부분을 발견했어요. 그는 마법이 아닌, 진심으로 사람들에게 사과하고, 자신의 문제를 해결하기 위해 노력하는 것이 중요하다는 것을 깨달았어요. 지훈이는 친구들과 화해하고, 학교 생활에도 적극적으로 참여하기 시작했습니다.
이 이야기는 우리에게, 어떤 문제도 마법이 아닌 우리의 노력과 이해를 통해 해결할 수 있다는 교훈을 주고 있어요. 지훈이처럼 우리도 어려움을 마주했을 때, 용기를 내서 문제를 직면하고 해결해 나가야 한다는 것을 보여주고 있어요.어느정도 맞춤법이 잘 교정된 모습이다.
최종 코드
이제 streamlit를 통해서 예쁘게 꾸며보자. 아래는 최종 코드다
import streamlit as st
from typing import Annotated, List, TypedDict
from langchain_community.chat_message_histories.in_memory import ChatMessageHistory
from langchain_core.prompts import PromptTemplate
from langgraph.graph import END, StateGraph
from langchain_openai import ChatOpenAI
from openai import AuthenticationError
import operator
import re
class State(TypedDict):
input : str
sentences : List[str]
index : int
output : Annotated[str, operator.add]
class SpellChecker:
def __init__(self, openai_api_key:str, *, spell_check_model:str="gpt-3.5-turbo") -> None:
self.openai_api_key = openai_api_key
self.spell_check_model = spell_check_model
def get_llm(self, model:str="gpt-3.5-turbo"):
return ChatOpenAI(temperature=0,
streaming=True,
model=model,
api_key=self.openai_api_key)
def sentence_split_node(self, state:State):
pattern = r'[^.!?]+[.!?]?\s*'
return {"sentences":re.findall(pattern, state["input"]),
"index":0,
"output":''}
def spell_check_node(self, state:State):
prompt = PromptTemplate.from_template("""당신은 국립국어원소속 박사로 맞춤법을 교정하는 일을 하고있다. 아래 텍스트의 맞춤법을 교정하라.\n```\n{input}\n```""")
llm = self.get_llm(self.spell_check_model)
chain = prompt | llm
pattern = r"\s*$"
origin_text = state["sentences"][state["index"]]
blanck_text = re.search(pattern, origin_text)
input_text = origin_text[:blanck_text.start()]
response = chain.invoke({"input":input_text})
return {"output":response.content + blanck_text.group(), "index":state["index"] + 1}
def create(self):
graph = StateGraph(State)
graph.add_node("sentence_split_node", self.sentence_split_node)
graph.add_node("spell_check_node", self.spell_check_node)
graph.set_entry_point("sentence_split_node")
graph.add_edge("sentence_split_node", "spell_check_node")
graph.add_conditional_edges("spell_check_node",
lambda state: "continue" if state["index"] < len(state["sentences"]) else "end",
{
"continue":"spell_check_node",
"end":END
})
return graph.compile()
@st.cache_resource
def get_spell_checker(openai_api_key:str):
if not (openai_api_key and openai_api_key.startswith("sk-")):
return None
return SpellChecker(openai_api_key).create()
st.title("맞춤법 검사기")
if "langchain_messages" not in st.session_state:
st.session_state.langchain_messages = ChatMessageHistory()
st.session_state.langchain_messages.add_ai_message("교정 하고자 하는 텍스트만 입력해 주세요.")
def chat_clear_btn():
st.session_state.langchain_messages.clear()
st.session_state.langchain_messages.add_ai_message("교정 하고자 하는 텍스트만 입력해 주세요.")
with st.sidebar:
openai_api_key = st.text_input("OpenAI API Key", type="password")
st.button("채팅 초기화", on_click=chat_clear_btn)
for message in st.session_state.langchain_messages.messages:
with st.chat_message(message.type):
st.markdown(str(message.content))
if prompt := st.chat_input("여기에 입력하세요!"):
spellchecker = get_spell_checker(openai_api_key)
with st.chat_message("user"):
st.markdown(prompt)
if spellchecker:
with st.chat_message("ai"):
try:
with st.spinner("로딩중..."):
response = spellchecker.invoke(input={"input": prompt},
config={"recursion_limit": 1500})
st.session_state.langchain_messages.add_user_message(prompt)
st.session_state.langchain_messages.add_ai_message(response['output'])
st.markdown(response['output'])
except AuthenticationError:
st.markdown("올바른 openai api key를 입력해주세요")
else:
st.cache_resource.clear()
with st.chat_message("ai"):
st.markdown("passcode 또는 openai api key를 입력해 주세요.")실행한 화면이다.!
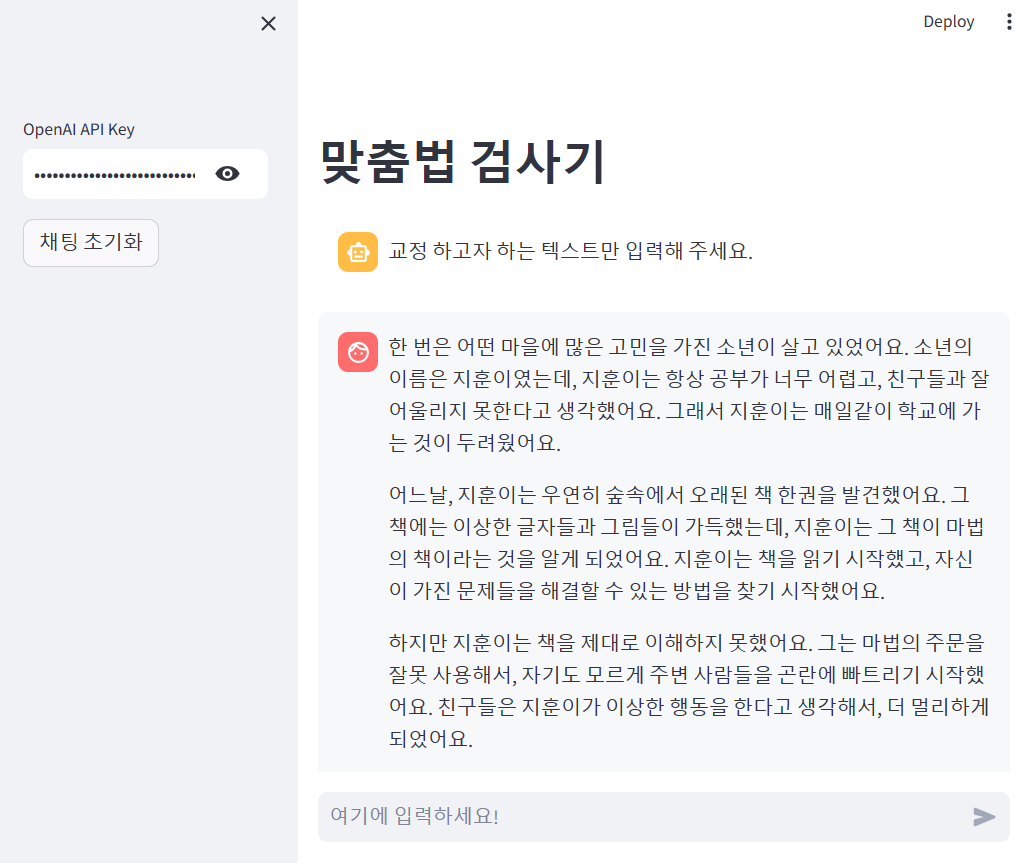
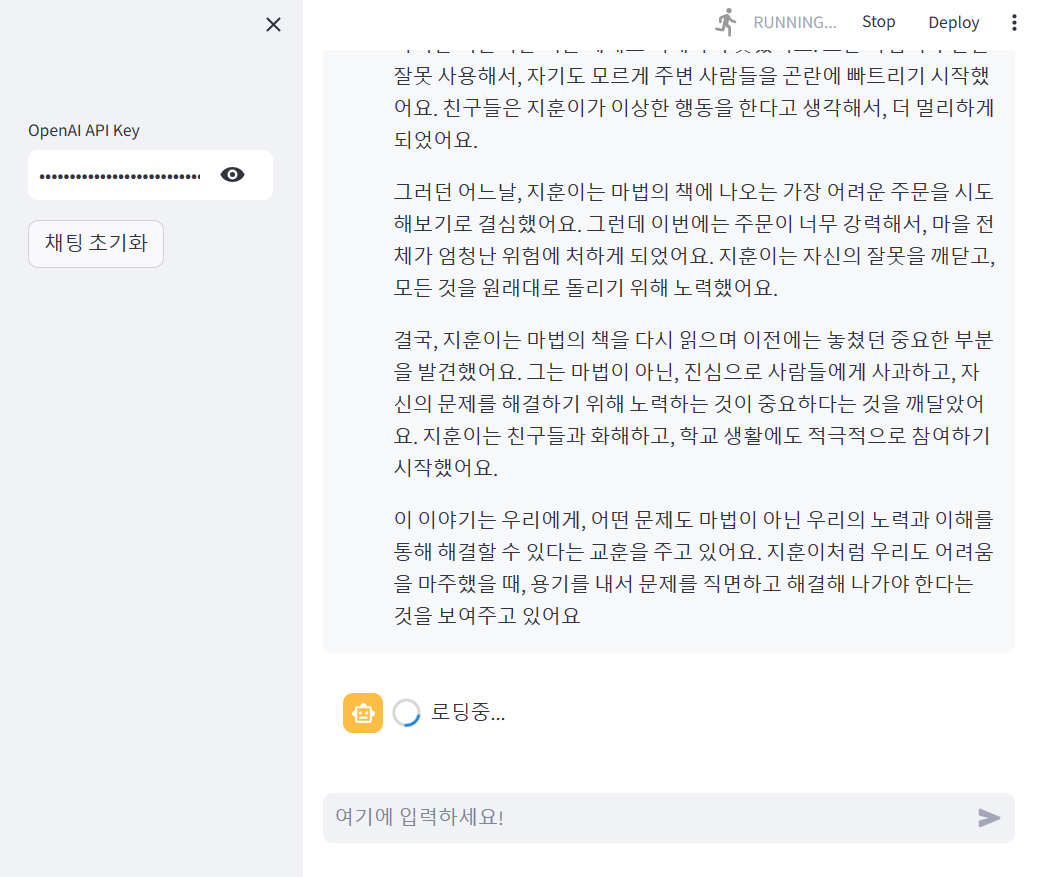
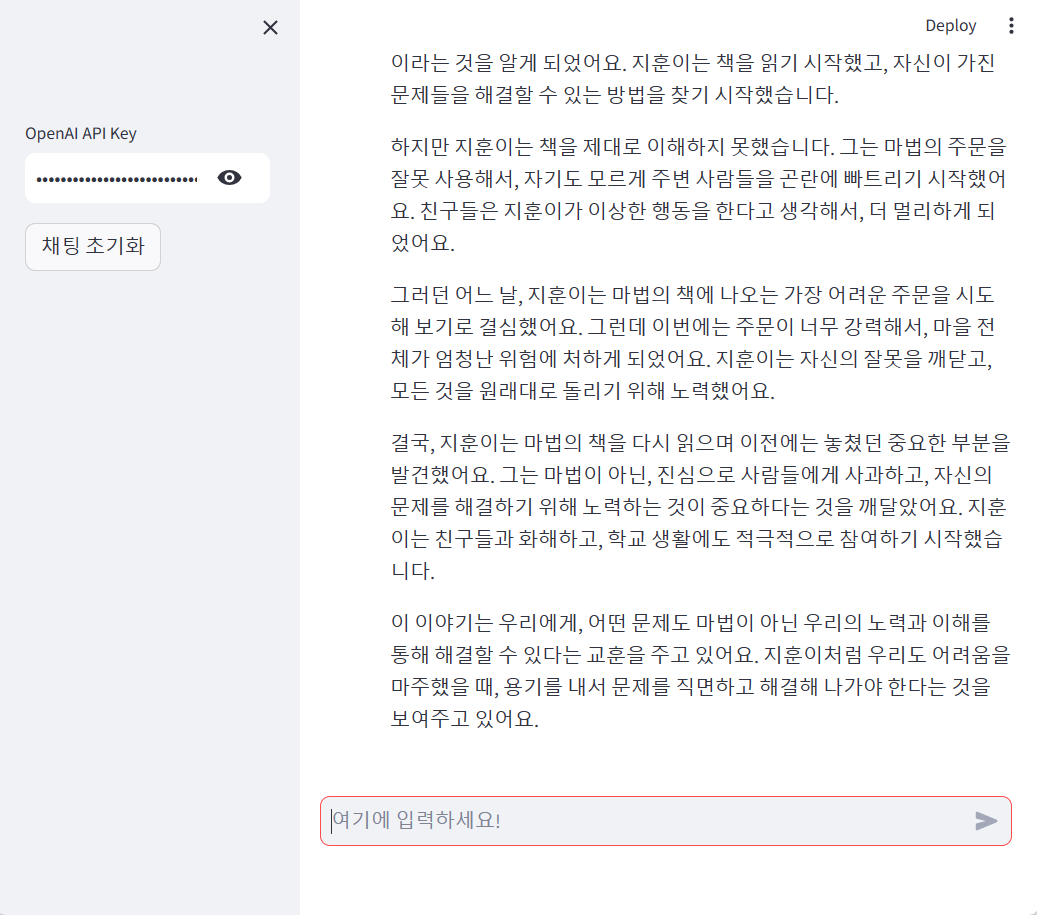
문제점
- 문장을 나눌때
r'[^.!?]+[.!?]?\s*'을 이용해서 분단하는데 이 정규식은 이메일, url 형식의 데이터가 들어간 텍스트의 경우 문단을 잘못 분해한다. - 구조를 잘못 짯는지 결과가 나오는 속도가 매우 느리다.
- langgraph에서 streaming으로 출력하는 법을 아직 찾지 못해서 UX가 떨어진다.
그래도 예상한대로 동작해서 재밌었다. langgraph 복잡한 문제를 해결하기 위한 설계가 매우 쉬워서 앞으로 더 많이 쓰일 거 같다.

정말 큰 도움이 되었어요!!