SQL 요약
SQl을 실제로 쓸 때에 의미있는 것들만 요약을 한번 해보겠다.
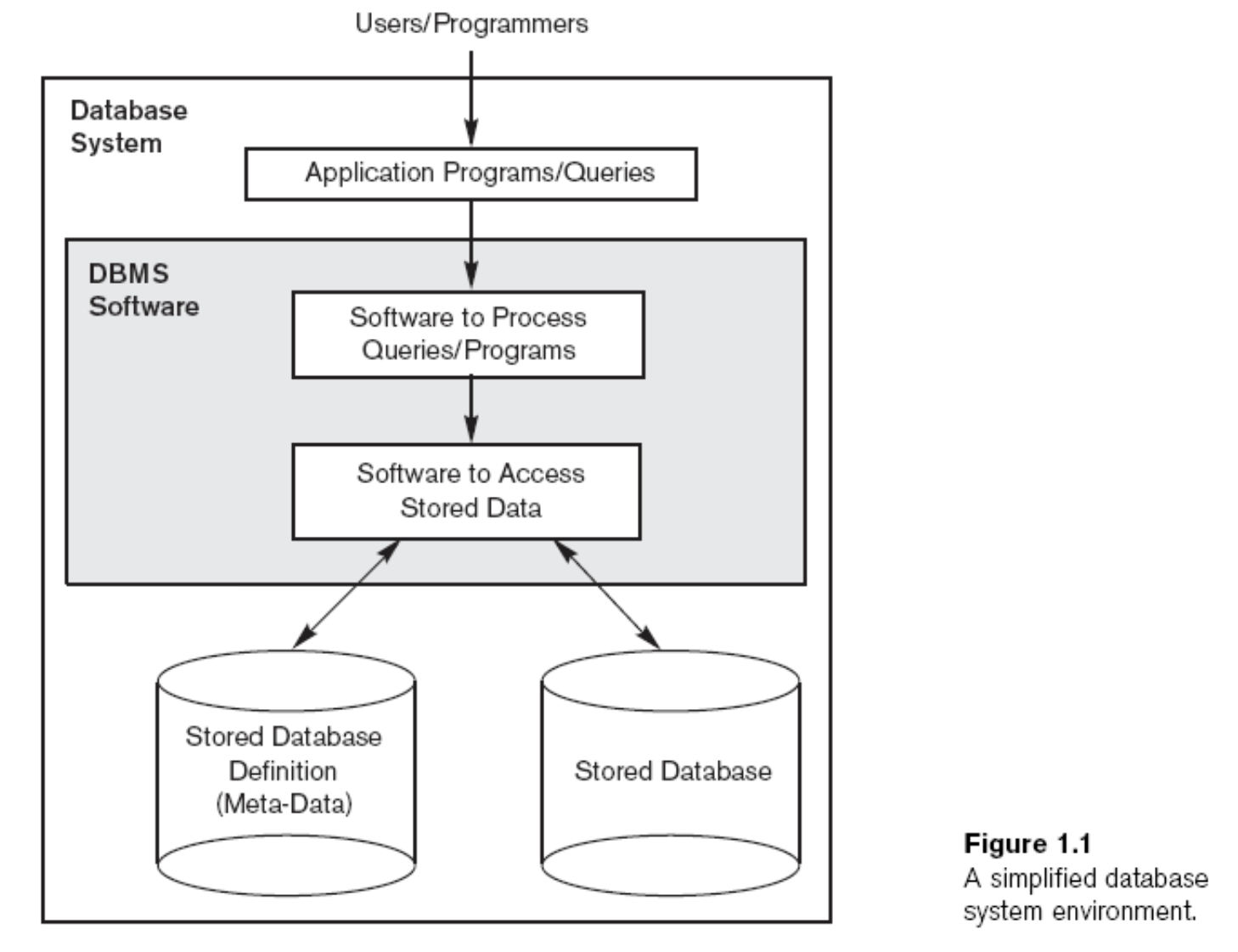
이 사진을 중심으로 말이다.
Database 사용
유저들이 실제로 Database System을 어떻게 사용하는가?
Application Programs
Application program을 통해서 간접적으로 DB에 Query, Update등의 처리를 할 수 있다. 우리가 sql몰라도 lms 쓸 수 있는것 처럼 말이다.
밑의 세게는 직접적으로 sql에 적용하는 명령문이다.
Query
Query:User가 Database에게 Data를 요구한다.
예시
- 영수증 data를 불러오세요.
- List the names of students who took the section of the 'Database' course offered in fall 2020 and their grades in that section
- List the 선수강과목 of the 'Database' course
Update
Data의 직접적인 변경.
예시
- Change the class of 'smith' to sophomore
- Create a new. section for the 'Database' course for this semester
- Enter a grade of 'A' for 'Smith' in the 'Database' section of last semester.
Transaction
Data의 변경을 초래 할 수도 있고, Data를 읽어오게 될 수도 있다.
Update와 Query와 뭐가 다르지? 싶을 수 있다. 밑에서 다시 알아보겠다.
DBMS Software
실제로 발생하는 유저들의 요구에 어떻게 대응할 것인가? 사실 우리가 software를 만드는 것은 수업의 취지가 아니기 때문에 별 비중이 없다.
Protection
System/Security protection
Maintain the databsase system
System은 requirement의 변경에 따라 유동적으로 진화할 수 있다.
Database 정의
Meta-data
Database에 대한 정의, 그리고 세세한 설명. DBMS 안에 저장되어있다.
예를 들어서 DB의 구조가 명시되어 있다. Data type for data element 를 명시해 놓음으로써. Student의 이름은 char name[20] 이런식으로 말이다.
Relation between data
Database의 요소들은 서로 독립적인가? 아니다. 학생 데이터베이스가 있다고 할 때에, 그 학생은 이름도 있고, 학생번호도 있고, 듣는 과목도 있고, 그 과목의 점수도 있다.
학생을 중심으로 보았을 때에 이름, 학생번호, 과목, 과목점수가 서로 relationship을 가지는 것이다. 이 realationship을 어떻게 구조적으로 표현할 지는 굉장히 중요한 문제이다.
엑셀같은 사용자 개인의 file processing 과의 차이
엑셀: 개인이 모두 다른 define(분류, schema같은 것들을). 개개인의 필요에 맞게 다 다른 implementation.
DB: 하나의 repository가 한번 define 되고 다른 유저들이 그것을 access.
사용자가 여러명이라는 것은 여러므로 생각할 점을 준다. Database의 특징인 Multiple Views of Data와 연결된다. 사진에는 없는 내용이므로 따로 다루겠다.
Database 특징들 더 알아보기
엑셀하고 다른 것 말고(하나의 definition), 어떤 특징들이 더 있는가?
Self-Describing nature
Meta data 라는 db에 대한 description이 독립적으로 존재한다. DB는 그 자체로 혼자를 설명할 수 있다.
Meta data는 DBMS에 의해 많이 사용이 되겠지만, User들도 사용한다고 한다.
Insulation between programs and data
Program-data independence
- Structure of data file (아까 나온 char name[20])은 access program과는 별개로 존재.
Program-operation independence
- Interface includes operation name(Sql 명령문들) and data type (char name[20]) of its arguments .
Operation 자체가 명령문들과 data abstraction과 함께 한다. 그렇기 때문에 Program이 바뀌어도, (예를 들어 My sql 에서 Postregsql로 바뀌더라도) Operation은 독립적이다.
Data Abstraction
Relation에 대한 이야기들.
실제로 학생에 대한 Database 가 이렇게 있다고 하자.
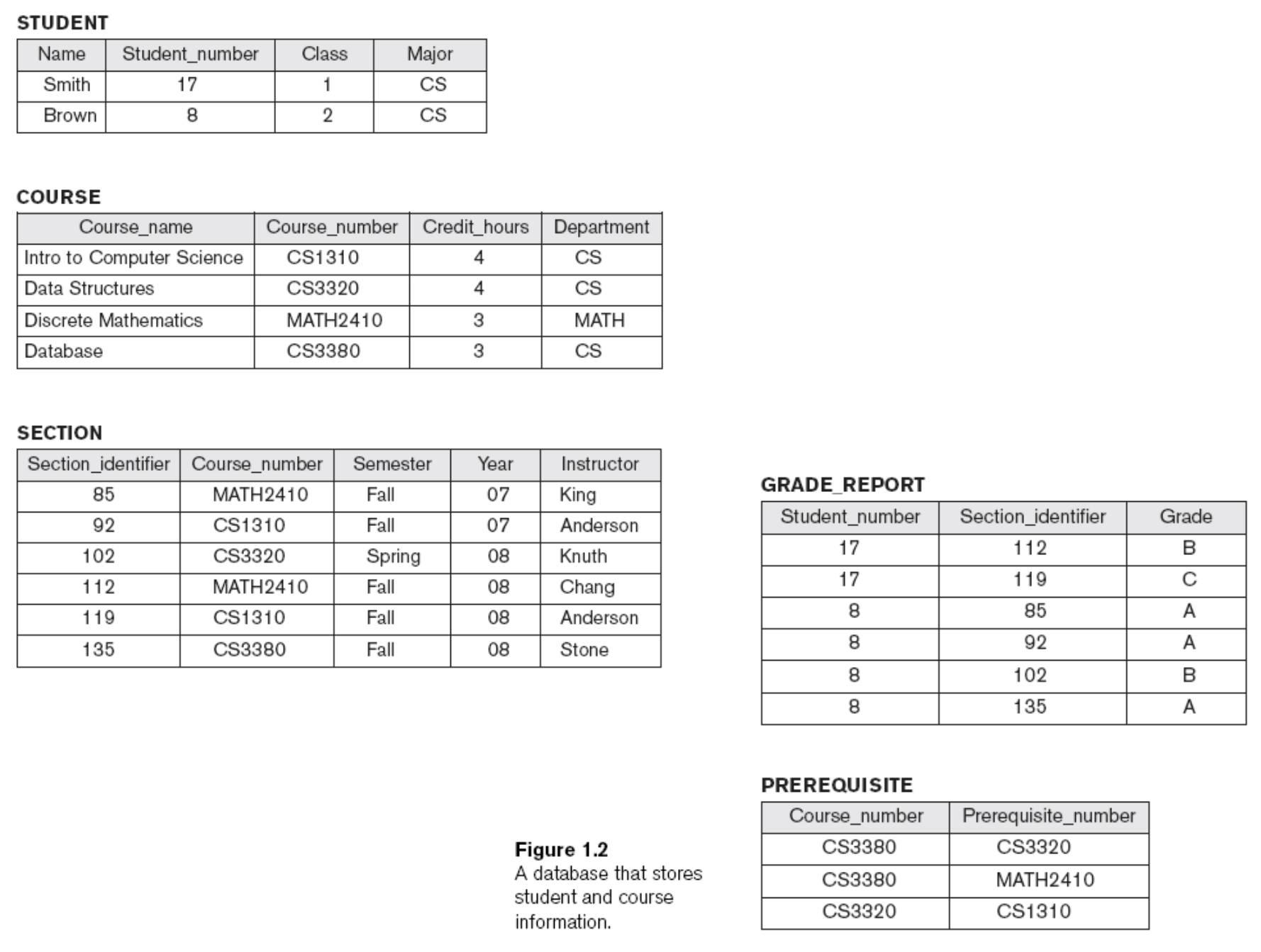
이 Data들은 독립적으로 존재하지 않는다. 서로의 관계가 존재한다. Relation은 이들을 묶는 하나의 그룹이다.
밑의 그림은 위의 Database의 realation과, 어떻게 data가 저장되는지 (data type)들을 기술한 정보이다. 이런 추상적이지만, 중요한 정보를 우리는 Data model 이라고 한다.
Data model: Type of data abstraction used to provide conceptual representation
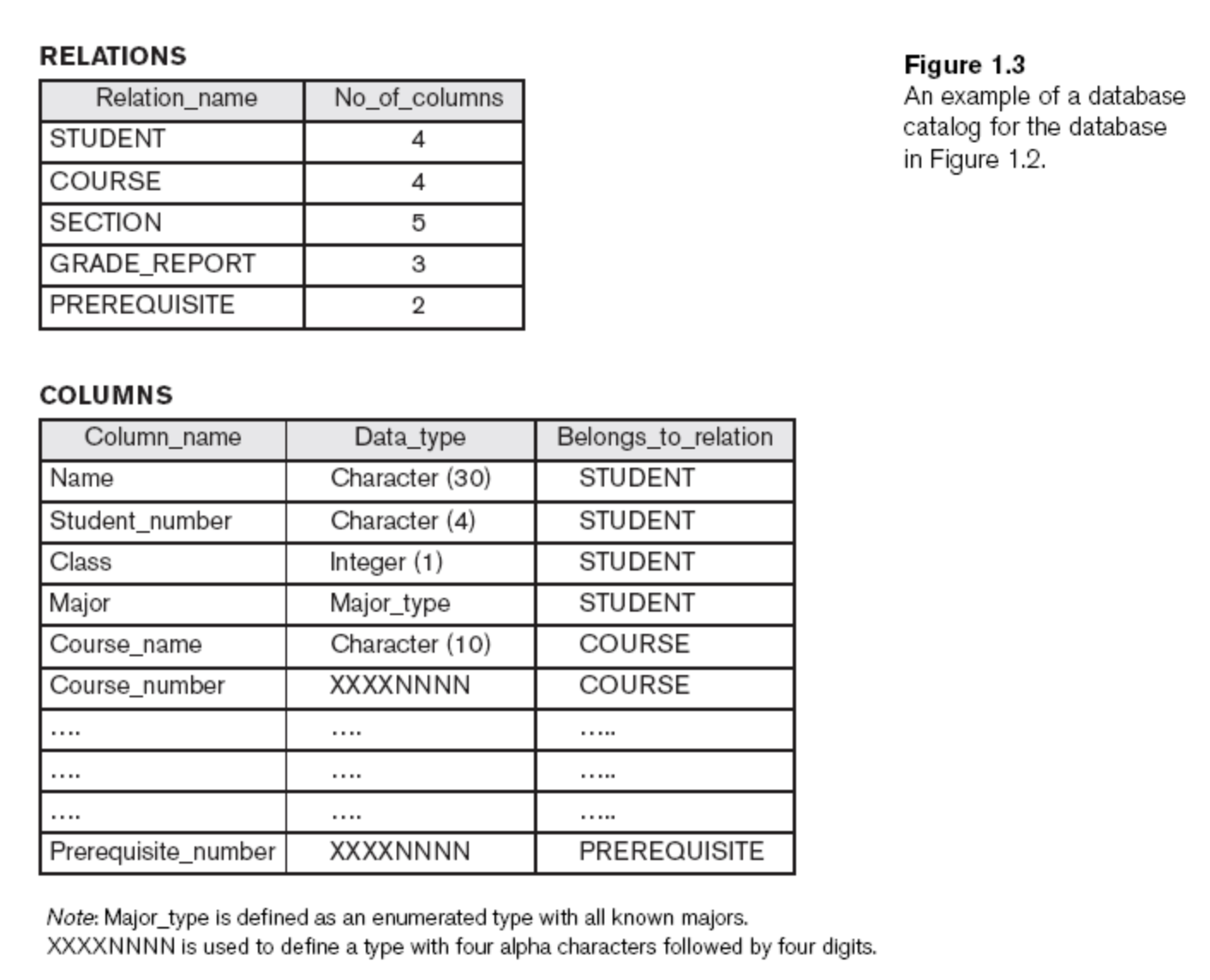
Database는 이렇게 추상적인(Abstracted) 방법으로 Data를 표현한다. 이는 앞에서 나온 Program-data independence와 Program-operation independence 를 구현한다.
Support of multiple views of data
View: Subset of the database, Contains virtual data derived from the database files but is not explicitly stored
유저들이 한가지 DB를 본다고 했을 때에 그 DB를 그대로 본다면 혼란이 발생할 것이다. 실시간으로 Update 와 transaction이 발생하는 db는 계속 바뀌기 때문이다. 그래서 유저들이 보는 View 와 실제 DB는 분리되어 있다.
또한 유저들은 한가지 device가 아닌, 여러 기기에서 접속하기에 더더욱 같은 View를 가질 수 없다. '하나의 정의된 DB'와 여러 유저들이 보는 View들은 필연적으로 나올 수 밖에 없는 개념이다.
Sharing of data and multiuser transaction processing
View는 개념적으로 어떻게 DB가 multiuser를 support하는지에 대한 이야기였다. 실제로는 어떻게 구현되는가?
Concurrency control software
- Ensure that several users trying to update the same datado so in a controlled manner
- Result of the updates is correct
Online transaction processing (OLTP) application
라는 걸 이용해서 한다고 한다.
Transaction
더 정확히 정의하자면 여러 DB를 포함하는 program을 실행하는 명령문이다. 여러 user들이 여러 db에 한번에 access한다니. 머리가 아프다.
그래서 두가지 특성이 있다.
-
Isolation property: Each transaction appears to execute in isolation from other transctions
-
Atomicity property: Either all the database operations in a transactions are executed or none are.
