🔍사건의 발단
AWS EC2 서버에서 여러가지 작업 중이었는데, 갑자기 제보를 받았다
👤"슈아님, 쓰고 계신 인스턴스가 꽉 찼다고 나오던데, 확인해보셨나요?"
넹😅?
어리둥절해진 나는 df -h로 스토리지를 확인해봤다.

띠용????
정말 많이 쳐줘야 20GB를 쓰고 있었는데 갑자기 100GB를 썼다고?
원인을 파악하기 위해서 파일 별로 용량을 확인해봤다.
그리고는 엄청난 파일을 발견하게 되는데...
🔍 원인
sudo du -ah /tmp | sort -rh | head -n 20 : tmp 파일 크기 순 상위 20개 출력하기
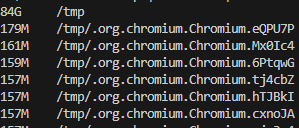
임시 파일이 84GB요??????????
chromeium이라고 나오는 걸 보니 크롤링 문제인 듯 싶었다.
조금 찾아보고 이유를 알게 되었다.
- 데이터를 수집하기 위해 브라우저를 실행할 때 저장되는 캐시 데이터
- 수집하면서 닫히지 않은 브라우저
이 두개가 임시 파일에 계속 쌓이면서 생긴 현상이었다.
그래서 자동으로 수집되고 있던 데이터들도 수집이 안되고 있었고...
수집되는 데이터가 워낙 많다 보니 빠르게 쌓인 듯 보였다.

(대충 슬픈 짤)
🔍 해결 방법
- tmpwatch(접근 시간을 기준으로 삭제, CentOS)
sudo yum install tmpwatch// 설치
tmpwatch 24 /tmp// 디렉토리에서 마지막 접근 시간이 24시간 이상 지난 파일 삭제
- tmpreaper(접근 시간 + 생성 시간 + 수정 시간 가능, Ubuntu)
sudo apt update// apt 최신화
sudo apt install tmpreaper// 설치
sudo tmpreaper 1440 /tmp// 접근 시간이 1440분(24시간) 이상 지난 파일 삭제
두 가지 중 선택해서 크론탭을 걸어놓는 것이다.
🔍 그런데도 오류가 난다?

문제는 계속 run time 오류가 발생하는 것이다
도대체 왜 이럴까 찾아봤는데, tmpreaper는 위에서 부터 차례로 파일을 삭제하는 형식이 아닌 전체 파일을 읽고 삭제하는 방식이었다.
한번에 84GB에 해당하는 전체 파일을 읽으려고 하니 오류가 발생한 것..🙄
그래서 강제로 삭제시키는 명령어를 사용할 수 밖에 없었다.
sudo find /tmp -type f -mtime +7 -exec rm -f {} \;
sudo: 관리자 권한으로 명령 실행
find /tmp: /tmp 디렉토리에서 검색 시작
-type f: 검색 대상이 파일(file)임을 지정 (디렉토리는 제외)
-mtime +7: 마지막으로 수정된 지 7일 이상 지난 파일 찾기(+7은 7일 초과를 의미 = 즉 8일째부터 해당)
-exec rm -f {} \;:
찾은 파일에 대해 rm -f 명령을 실행하여 삭제
{}: 검색된 파일 이름 참조
\;: find 명령에 대한 -exec 옵션의 종료

열심히 지워지고 있는 나의 tmp 파일...
그 뒤로 자동화도 걸어둔다.
crontab -e// 크론탭 실행
0 0 * * * /usr/sbin/tmpreaper 10080 /tmp// 매일 자정 마지막으로 접근한 지 7일 이상 지난 파일을 삭제
/
/
얼추 자동화가 끝났다고 생각해서 손도 안대고 있던 항목이었는데 이런 상황이 생겨서 매우 당황했다.
왜 이상치에 대해 알림을 해놓는지도 뼈저리게(?) 알게된 순간이었다.
나중에 또 서버를 이용하게 된다면 그 땐 모니터링에 신경을 좀 써야겠다 ㅠㅠ

