sql 코드카타

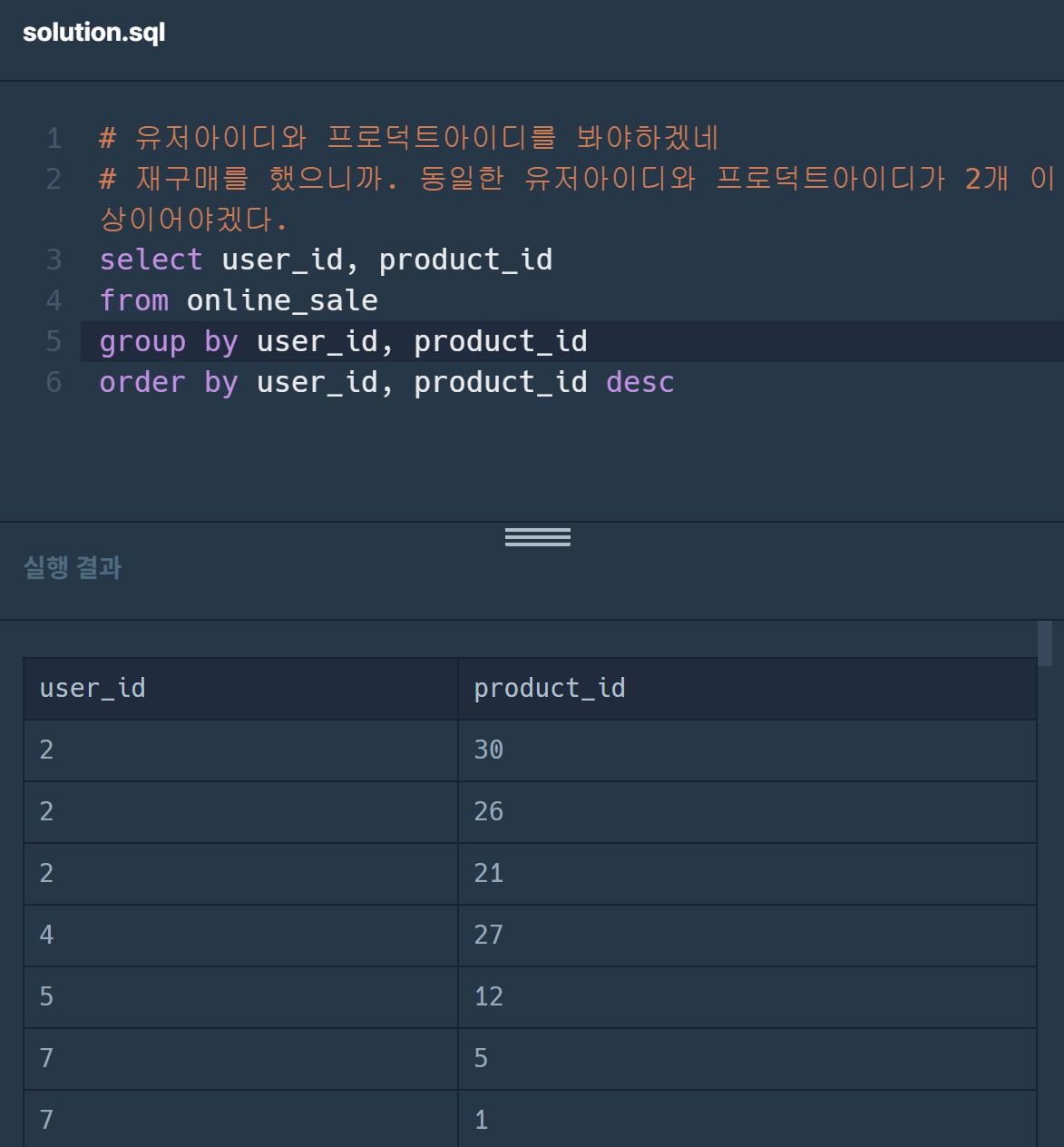
여기까지는 생각을 해냈다. 그리고 having을 썼다가 나는,,having이 꼭 select절에 있는 컬럼만을 사용해야된다고 생각했다.
하지만 아니었고,, 이미 group by로 묶어주었기 때문에 having을 쓸 때는 그 안에서 연산이 가능하다고 한다. 이미 묶어져있는 것 가지고 연산 가능!
->저 쿼리에서 중복되는 행을 구하면 되니까: count(*)를 써줘서 중복된 행을 구해줄 수 있다.
쿼리를 더 수정해보면:
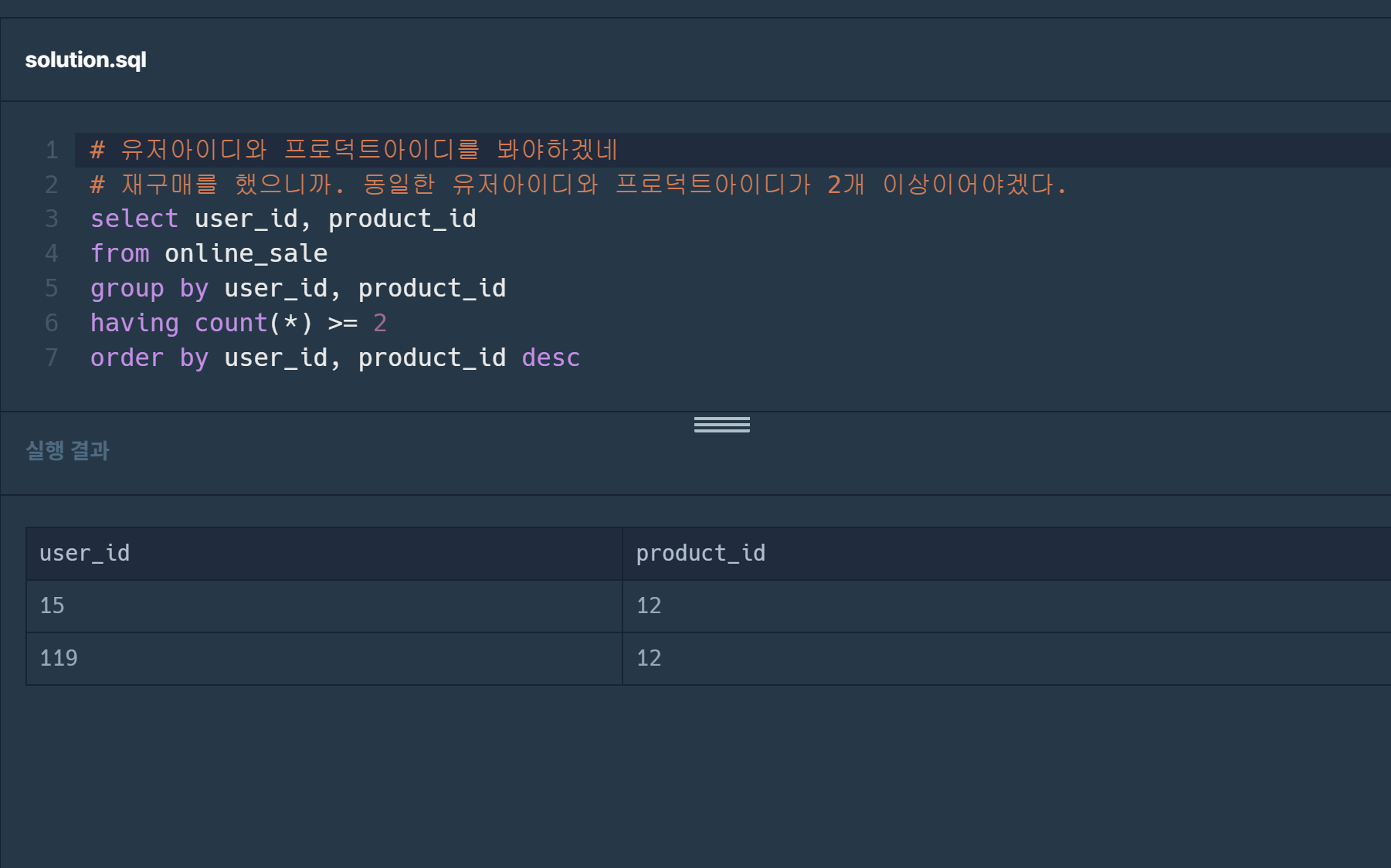
이렇게 나온다. 그리고 이것은 정답이다!
이 코드카타로 인해서 배운것:
1. having 절에서는 이미 그룹화 되어있는 것 안에서 연산이 가능하다. 굳이 select절에 count쓰지 않아도 연산이 가능!!
- 중복행을 구해줄 때는 count(*)를 사용해서 중복된 행의 갯수를 구할 수가 있다.
다음문제: 코드카타 55번-조건에 맞는 사용자 정보 조회하기
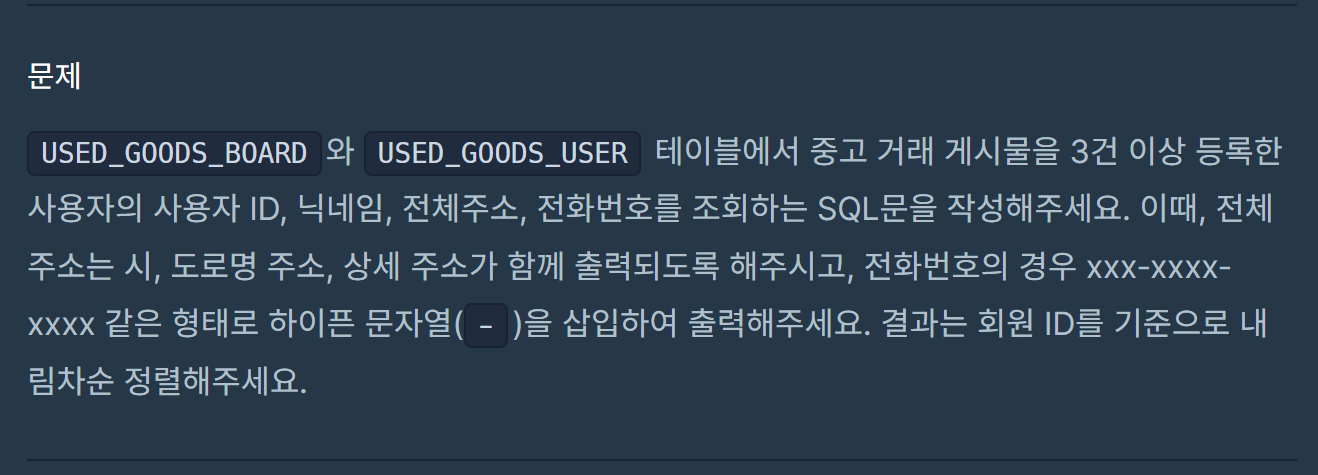
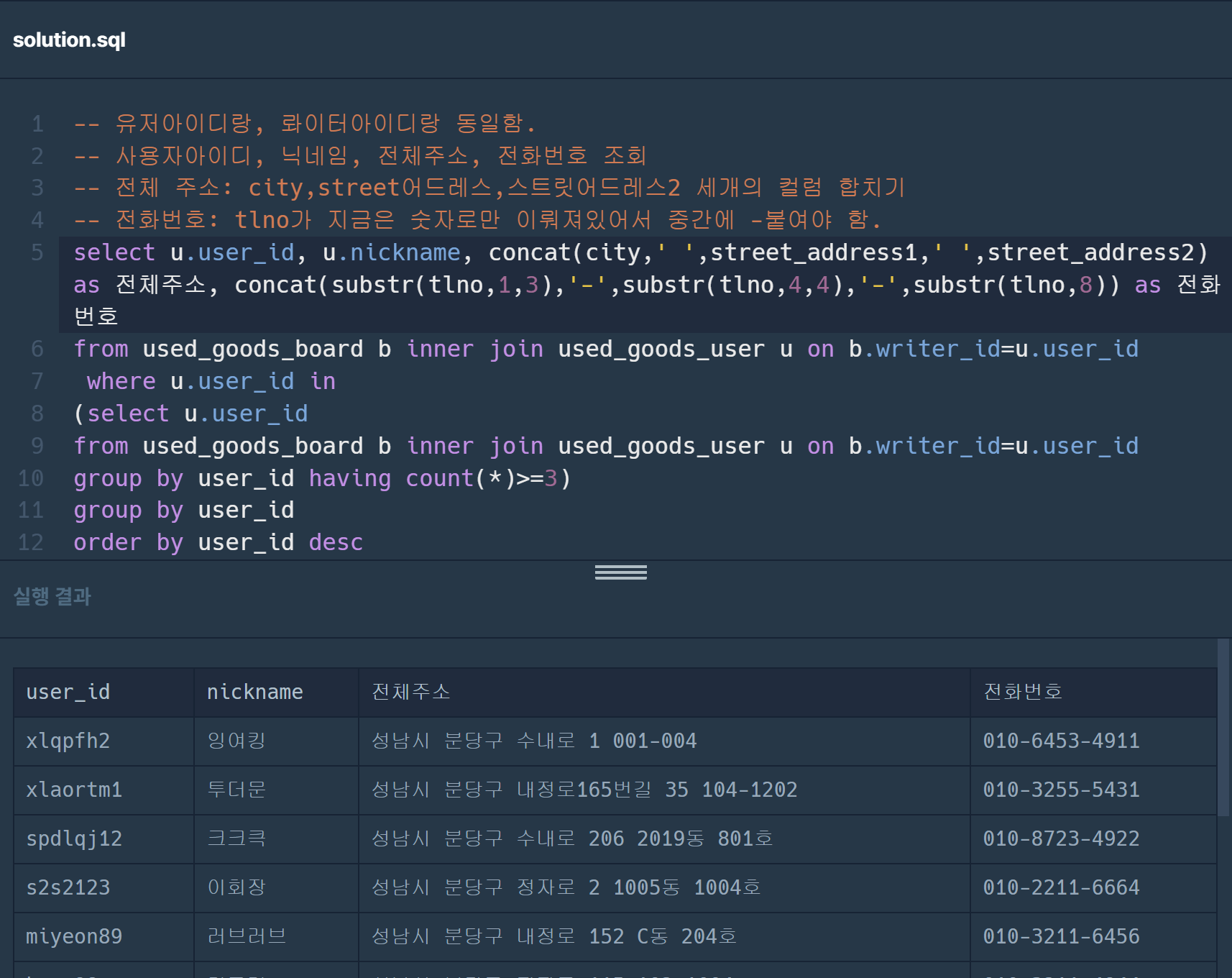
어떻게 해서 정답을 구하긴 했는데,, 그,, where절 서브쿼리에 =로 작성했었다. 여기서 정리하고 가는 연산자 뜻
=: 동일한 값. 만약에 where 절에 한 컬럼만 작성했다면, where절 서브쿼리에도 한 컬럼만 작성해야함.
in: where 컬럼1 in (select a컬럼, b컬럼, c컬럼,,,)라고 했을 때 - 컬럼이 in안 서브쿼리에 있는답이 있는지 확인.(select절에 있는지 확인하기) 약간 or의 개념이라고 생각하면 좋을듯,, 아 왜 이게 머릿속에 막 유레카가 되지 않는걸까.. 정확하게 개념정리가 확실하게 안되는걸까,,!!!!
그러니까,,, 저 컬럼1이 select이하의 나열되어있는 컬럼 값이 포함되어있는지를 조건으로 지정하는 것이다(where절이니까)
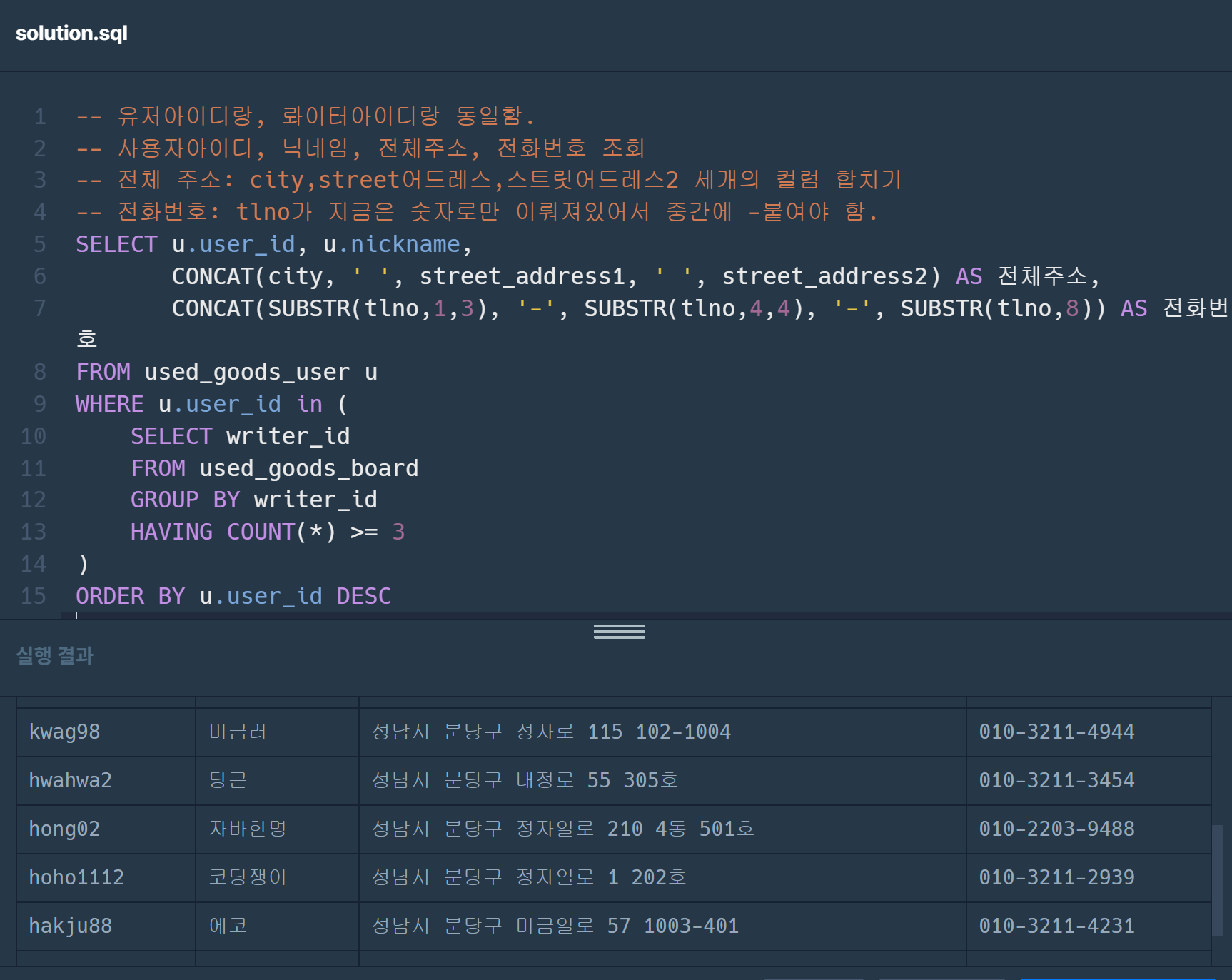
이런식으로도 쓸 수 있다.
select user_id, nickname, concat(city,' ', street_address1,' ', street_address2) as 전체주소, concat(substr(tlno,1,3),'-',substr(tlno,4,4),'-',substr(tlno,8,4)) as 전화번호
from used_goods_board b inner join used_goods_user u on b. writer_id = u.user_id
group by user_id
having count(*)>=3
order by user_id desc
아니면 이런식. 근데 지피티한테 물어보니 내가 쓴 쿼리들에서 에러가 날 수도 있는것이- group by 사용할 때 하나 외의 다른 것들은 무조건 묶어줘야 한다고 해서.. 에러가 날 수도 있다고 한다. 그래서 정확하게 조건을 주어서 쓸 수 있는 쿼리를 사용해야한다고 한다..
