
코딩 공부하는 방법: 문법 구조보다는 언제 쓰는지가 중요하다. 쿨하게 넘어가기(문법 구조를 달달달 외울 필요가 없다는 말임)
1. 한가지만 집중하기 2. 끝까지 완성하기 3. 성실하게 삽질하기 4. 코딩 많이 해보기
데이터 전처리 강의 완강-
데이터 전처리를 해야 하는 이유: 데이터의 형태가 다르면 데이터 다루기가 어렵다.
전처리 시 생각해야 할 점: 데이터 전달의 목적성을 꼭 지녀야 함. -> 데이터 전달의 효과성이 높아진다.
-unnamed 컬럼은 인덱스 값을 지정해주지 않아서 생기는 컬럼이다.(프로젝트 할 때 데이터프레임에 저 컬럼이 왜 있나 싶었다.
pandas는 데이터 분석에 최적화 되어있는 라이브러리이다.
불러올 때 import pandas as pd로 불러와주고 저장해준다. 통상적으로 pandas를 pd로 요약한다.
그리고 Series(1차원 데이터)와 Dataframe(2차원 데이터)가 있는데, 1차원 데이터는 인덱스와 컬럼 한개의 데이터들이다. 2차원 데이터는 인덱스와 컬럼이 2개 이상인 데이터들의 프레임이다.
데이터 전처리에서 사용한 라이브러리 및 기능 요약:
1. pandas
- .isna()=.isnull: 결측치가 있는지 확인하는 기능이다.
- .astype(): 컬럼의 타입을 확인하는 기능이다.
- .loc(): 데이터프레임에서 값을 인덱스 기준으로 뽑아오는 기능이다. 문자타입, 숫자타입 가능
- .iloc(): 데이터프레임에서 값을 행,열의 순번(숫자)로 뽑아오는 기능이다.
- and조건은 &로 표시하고, or조건은 |로 표시한다.
- isin: 컬럼안에 어떤 값들이 있는지 확인하는 기능이다. 불리언타입으로 반환한다. 더 정확히 말하면 데이터프레임 객체의 각 요소가 values값과 일치하는 지 여부를 불리언타입으로 반환한다.
ex)df.isin(values) -> df.isin([1,3]): df안에 1,이나 3이 있는지 확인하는 함수.
df.['Year'].isin(['2019'])💡isin()함수는 반복 가능한 자료형을 인자로 받아야 한다! 그래서 2019년도에 해당하는 것들을 뽑아올 때에도 꼭 리스트, 셋, 튜플 등의 형태를 해주어야 함. - .concat(): 데이터를 병합하는 함수.행 또는 열 형식으로 위 또는 옆으로 데이터프레임을 병합한다. axis=0을 하면 위 아래로, axis=1을 설정해주면 옆으로 병합된다. 약간 sql의 union함수 같기도 하다. 근데 union은 위아래로만 붙여줄 수 있으니 다르긴 하다. +concat의 join기본옵션은 outer형식으로 설정되어 있음. 합치는 데이터프레임들의 열을 모두 포함하는 것. 임.
- .reset_index(): 인덱스를 컬럼으로 옮기고 0부터 인덱스를 다시 부여해주는 것.(만약 컬럼이 없다면,, 굳이 이 함수를 쓸 필요가 없음. 기존 인덱스를 컬럼으로 옮기고 숫자 인덱스를 주고 싶을 때 사용이 가능하다.
- .reset_index(drop=True): 기존 인덱스를 아예 삭제(컬럼으로 옮기지 않고 버림)+숫자로 된 새로운 인덱스 부여.
- .merge(): sql에서 join과 같은 개념이라고 생각하면 됨. 공통된 key를 가지고 데이터프레임을 병합하는 함수. 이 아이는 합칠 때 리스트 형식으로 합쳐주지 않아도 괜찮다.
ex)pd.merge(df1,df2,on='key') how=로 조인 방식을 정할 수도 있다. 기본값은 inner임.
-> concat과 merge의 차이점: concat은 인덱스 기준으로 결합한다.(행or열) merge는 특정 컬럼을 기준으로 결합한다. key컬럼 on=을 사용. - .groupby('컬럼명'): 컬럼명으로 집계를 사용이 가능하다. sql이랑 똑같음. 데이터를 그룹화하여 연산을 수행하는 메서드. 데이터를 그룹별로 분할하여 독립된 그룹에 대하여 별도로 데이터를 처리하거나 그룹별 통계량을 확인하고자 할 때 유용한 함수이다.
.groupby().mean()이렇게 뒤에 집계함수를 부텨서 사용이 가능하다.
df.groupby('과일')[['수량', '가격']].mean()-> 이런식으로도 가능함. 과일 컬럼을 기준으로 그룹을 만들고. 수량과 가격이라는 두 개의 컬럼만 뽑아서 각 그룹에대해 평균을 구하는 것임. - .agg(): pandas의 집계함수를 사용할 수 있는 기능인데, 여러개의 함수를 한번에 적용할 수 있게 해준다.
->하나의 컬럼에 하나의 함수
->하나의 컬럼에 여러 함수
->전체 컬럼에 함수 적용
->여러 컬럼에 각각 함수 적용(딕셔너리로 묶어주어야 함)
->groupby()후 여러 함수 적용: df.groupby('column').agg({})형태로 사용
이 가능하다. - pivot_table: 내가 보고 싶은대로 보는 방법. index=,columns=,values=, 다 지정이 가능하다.
- sort_values(by='columns'): 'columns'를 기준으로 정렬하는 기능. ascending=True또는False 사용 가능. 여기서도 by에는 여러개의 컬럼이 올 수 있고, ascending에도 마찬가지로 여러개가 올 수 있다.
- sort_index(ascending=True/False): 인덱스를 기준으로 알파벳/숫자 순으로 정렬하는 것.
- .head():상위 n개 행을 보여주는 기능이다. 기본값은 5행이고, ()안에 숫자를 넣으면 그 숫자만큼의 행을 반환한다. 데이터프레임이 거대할 경우에 데이터 구조를 빠르게 파악하거나 샘플을 확인할 때 많이 사용하는 방법.(because, 용량과 시간 측면에서 훨씬 빠르기 때문)
- .tail():하위 n개 행을 보여주는 기능이다. 요 기능도 기본값이 5행이다.
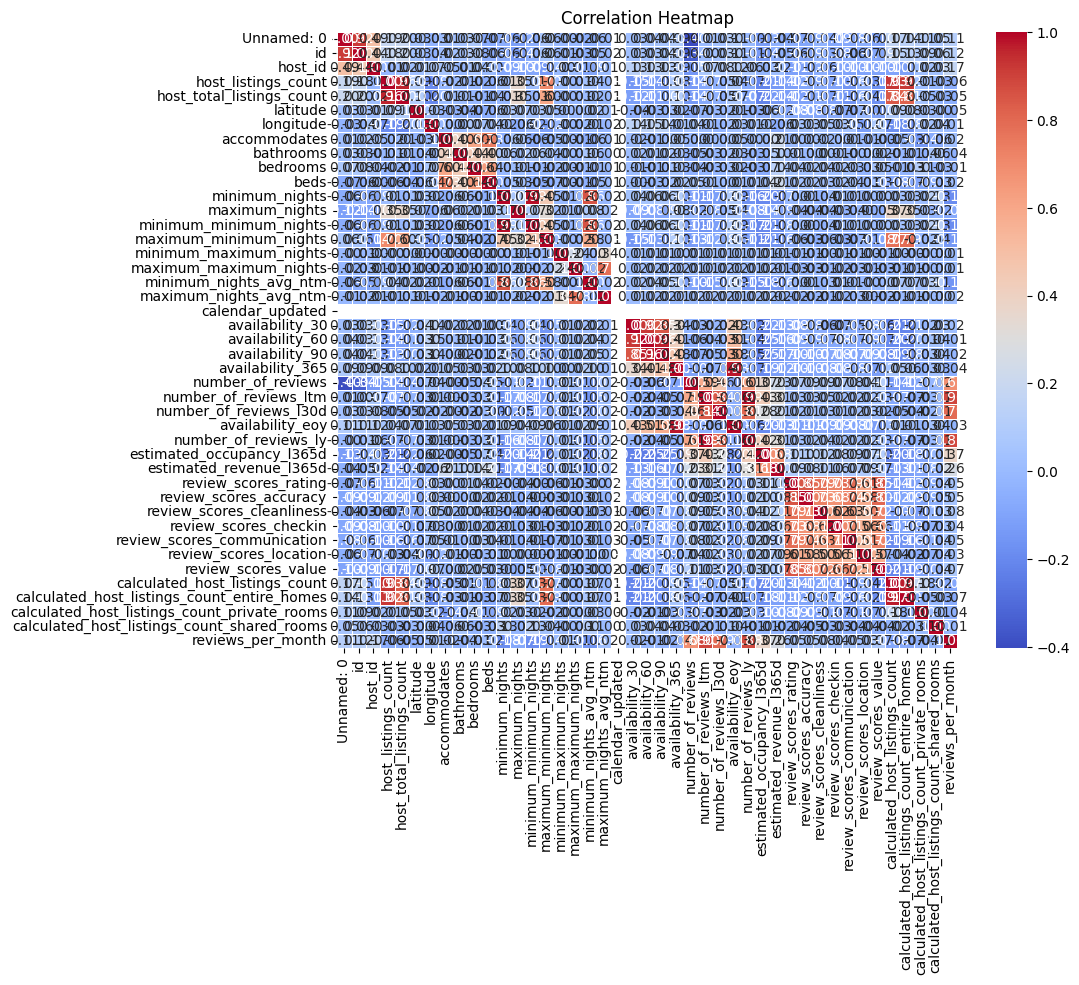
프로젝트 현재 EDA하는 중인데, 저번에 생각했던 컬럼들을 일단 제외를 해보았다. 그리고 그걸로 상관관계를 히트맵으로 나타내보았는데, 컬럼 제외를 더 해야할 듯하다.. 그리고 생각보다 상관관계가 많이 없는 듯..? 그 리뷰들 간에 상관관계가 조금 있는 편이고 다른 것들은 거의 없는 것 같이 보인다.
<머신러닝 최적화 라이브세션>
과소적합: 높은 편향
과적합: 높은 분산 ->해결하려면 정규화, 차원 축소 등
-
하이퍼 파라미터: 모델 학습 과정에서 사용자가 직접 설정해야 하는 값이다. 훈련을 통해 자동으로 학습되지 않는 파라미터. but 요즘에는 기술이 많이 발전해서 컴퓨터가 설정하기도 한다고 함. 하지만 기본은 사람이 지정해주어야 하는 것임.
-
프로젝트 시 시각화를 꼭 많이 해야 한다. 결과에 대한 근거로 제시할 수 있는게 제일 쉬운게 시각화이다.
평가기준을 세우고, 성능향상을 꼭 하기
그리드 서치, 랜덤 서치, 앙상블 방법론이 있음.
프로젝트에서 과적합인지 과소적합인지 꼭 검증을 하기
