
오늘 한 목록:
~(>_<。)\데이터 전처리 및 시각화 강의 4강 완강, 데이터 전처리 계속ing, 튜터님께 피드백 받은 후 머신러닝 돌리기 시작함, 돌려보니 팀원분들이 무슨 이야기했는지 알겠고, 머신러닝 돌릴 때 뭐가 필요한지 알게 됨. 역시 해봐야 안다.💡 고난과 역경ing, memory error남..->팀원분과 튜터님께서 피드백 해주심. 길을 찾았으나, 어떻게 돌아가야 할지 막막,, 저 지점은 알겠는데 거기까지 어떻게 가야하지? 이런 상황임. 일단 코드랑 흐름을 저장해놓고, 새로운 파일 열어서 다시 시작할 예정.🫡🤓 어디서부터 손을 대야할지 저녁이 되니 머리가 안돌아가는 것 같음.
드디어 전처리 및 시각화 강의 모두 들었다. 솔직히 들으면서 마음 한구석이 불편했다. 약간.. 전처리 해야하는데 그 시간에 들으니까 마음이 불편하고, 팀원들에게도 약간 나눠야하는데 좀 그 시간이 줄어드니까 그만큼 전처리가 늦어질 것 같아서 또 불편하고 그랬다. 암튼 그래도 시각화는 해야하니 다 듣긴했다.
일단 사용되는 라이브러리는 seaborn
- line 그래프(선 그래프): 데이터 간의 연속적인 관계를 시각화하는 데에 적합하다. 주로 시간의 흐름에 따른 데이터의 변화를 보여준다.
사용법은 .plot() - bar plot(막대 그래프): 범주형 데이터를 나타내며, 값의 크기를 비교하는데 사용된다.
사용법은 .bar() - box plot: 데이터의 통계적 특성+이상치를 확인 할 수 있다.
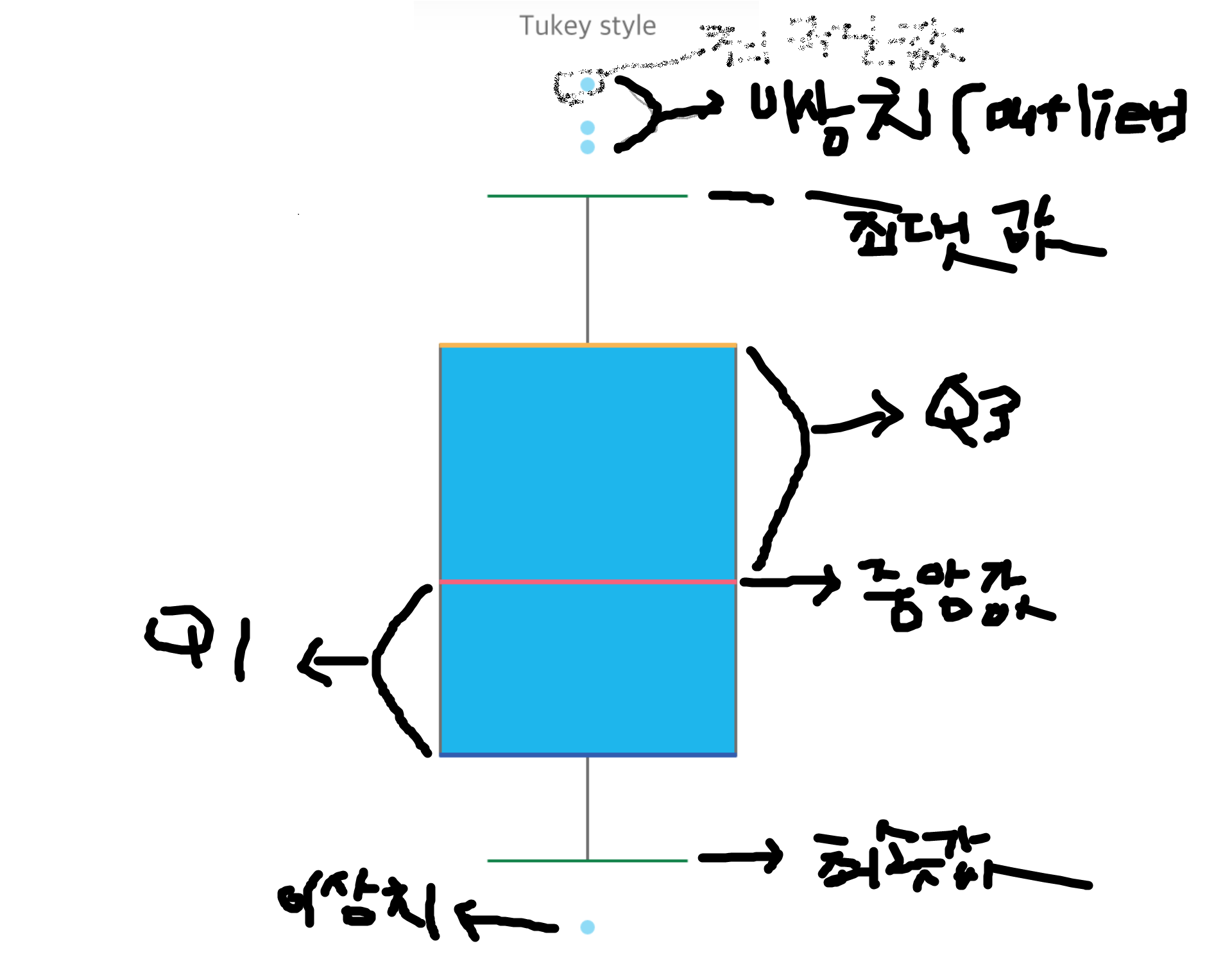
✏️Q1: 제1사분위수. 전체 데이터를 작은 값에서 큰 값으로 나열했을 때 전체 데이터의 25% 지점->전체 데이터에서 25%보다 작거나 같은 데이터들(하위 25% 지점)
✏️Q3: 제3사분위수. 전체 데이터를 작은 값에서 큰 값으로 나열했을 때 전체 데이터의 75% 지점-> 전체 데이터에서 75%보다 작거나 같은 데이터들(하위 75% 지점)
✏️극단점: 이상치 중에서도 가장 바깥쪽에 위치한 데이터를 극단점이라고 한다. - 히스토그램: 연속형 데이터에 사용된다. 얼핏 보기에는 막대그래프와 똑같아 보이지만 자세히 보면 막대그래프는 범주마다 떨어져있는데, 히스토그램은 다닥다닥 붙어있는 것을 볼 수 있다.->그게 바로 연속형 데이터이기 때문! 근데 이 히스토그램을 시본에서도 사용가능하지만, 넘파이에서도 사용이 가능하다고 한다.
- 파이차트: 전체 비율에서 얼마나 차지하고 있는지 볼 때 사용한다. 근데 그 아티클에서도 그렇고, 같은 팀원분 경제학과 교수님도 그렇고 파이차트 사용은 지양 하도록 이야기하셨다고 한다. 실제로 내가 사용했을 때에도 파이차트는 눈에 들어오는것이 명확하지 않았던 것 같아서 왠지 사용하기 꺼려졌던 차트이다.
- scatter(산점도): 상관관계 분석. 두 변수 간의 관계. 약간 띠형태로 나타나는 것이 상관관계가 있다는 것을 확인 해 볼 수 있다. 만약 상관관계가 없다면 그냥 여기저기 분포되어 있음.
- 피어슨 상관계수: 두 변수 간의 선형적인 관계의 정도를 나타내는 지표이다. 범위는 -1 ~ +1 사이의 값을 가지고, +1이면 완벽한 양의 선형 관계를 나타내고, -1이면 완벽한 음의 선형 관계를 나타낸다. 0이면 선형 관계가 없다는 뜻이다.(두 변수 간의 상관관계가 없다는 뜻.) -> 그렇다면 음이든 양이든 1에 가까울수록 상관관계가 있다는, 높다는 뜻으로 알아들으면 될 것 같다.
사용할 때는 .corr()로 구할 수 있다. 예를 들어 df가 두개의 컬럼이 있을 때 correlation = df.corr(method='pearson')이런식으로 구할 수 있다.
하지만 주의할 점은 피어슨 상관계수는 선형 관계만 측정하기 때문에 곡선형 관계에서는 적절하지 않다는 것과 이상치에 민감하여 이상치 하나 때문에 상관계수가 왜곡될 수도 있다는 것이 있다.
공부할수록 재밌군. 오히려 밤에 공부하니까 집중도가 왜이렇게 올라가지..? 이것저것 읽으면서 공부하고 있는데 예전에는 코드 읽는게 뭔소린지 모르겠었는데 지금은 코드보면서 이해가 된다.. 감사합니다 정말로. 진짜 감사합니다.. 앞으로 계속 마음 다잡고 나아가보자
=> 전처리 시각화 하기 전에 생각해 볼 점!
"내가 무엇을 위해 데이터를 확인할 것인가"-에 대해 사전에 설계하는 습관을 꼭 들이기.
어떤 목적성을 가지고 어떤 식으로 분석 설계할 것인가- 에 대해 청사진 그리기
- 내가 희망하는 데이터 분석가의 청사진을 그려보기를 추천하셨다. 내가 되고 싶은 데이터 분석가는 어떤 사람인가?
🌟 반복해서 따라하고 사용해보면서 익숙해지기. 그렇게 하다보면 익숙해지고, 또 코드도 알 수 있음!!
1. 반복되는 연습이 답이다
2. 구글링을 적절히 사용하자.
오늘 진행한 프로젝트: 드디어 오늘 머신러닝을 나도 도전해보았다. 다른 사람들보다는 늦은감이 많지만 그래도 (비교하지말기!!) 어제는 다 죽어가는 목소리로 매니저님이랑 튜터님이랑 찾아가고 막 그동안의 내 사정 또 나누고 눙물,, 을 흘림 암튼 그,,
from sklearn.ensemble import RandomForestClassifier
X_train = df_encoded
y_train = df_encoded
model = RandomForestClassifier()
model.fit(Xtrain, y_train)
importances = model.feature_importances

요 코드를 적용해보았음. importance feature확인해서 중요도가 낮은 것들 빼버릴려고 함. 하지만 이걸 돌리는 과정도 쉽지않았으니..
암튼 지금 시간이 늦어서 일단 중요한 정보만 정리해보자면- 저기 위의 x_train이랑 y_train은 같으면 안된다고 하셨다.
그리고 원핫인코딩 자체가 그 고유값이 많으면...?컬럼이 기하급수적으로 많아진다고 함.->Q 근데 어차피 범주형은 다 인코딩해버린,,아 ,,그때 컬럼들이 많아진다는 뜻. ㅇㅋ
그래서 x값에다는 인코딩 한 df 넣어주고, y는 예측값을 넣어주면 된다고 하셨다. 그게 뭔지에 따라서 넣는 컬럼이 바뀌는 듯 우리는 가격을 예측해야하기 때문에 price컬럼만 넣기로 함.+그리고 여기서 중요한 것은 x에 넣는 값에는 price컬럼을 제외하고 넣어야 한다고 하셨다.
그리고 연속형 변수가 우선되어야 한다고 하심. 내일 다시 돌려보고 다시 해보쟈,, 일단 범주형 데이터들 처리도 해야함,,,,,,하,, 그 꿀팁을 알려주셨는데- 범주형 데이터 고유값이 많다면-> 그 고유값들을 카테고리화가 가능하다면 카테고리화 해서 숫자를 적게 설정할 수 있음.ex)국가 컬럼이 있어서 100개의 국가가 있다고 칠 때 국가를 6대륙으로 나누어서 100->6개로 범주화 시키는 것. 거기서 인코딩하면 훨씬 수월.
그래서 나는 뭘 해야하냐,,,,,,,음,,, 일단 ,,, 그,,,내일 다시 돌려보고,,,, 안되면 다시해보고,,,,,지피티 활용해보고,, 모르겠으면 다시 튜터님 찾아가기,,, 화이팅!!!
아 그리고 이번 프로젝트 메인 튜터님이 이 프로젝트도 공부의 일환이니 꼭 끝까지 돌려보라고 하셨다. 혼자서라도. 배운다는 마음가짐으로 프로젝트 흐름은 계속 따라가라고 하심.
트리기반 모델-피쳐 importance.
컬럼이 몇개 정도여야 이상적인지 물어봄->컬럼 갯수의 기준은 없지만 2~30개 정도 생각하고 돌려보라고 하심.
너무 처지지 않게 따라가라고 하셨음.
오늘 알게된 것들 더 많긴한데:일단 스케일링은 수치비교 하기 위해서 하는 것임.
범주형이 중요도가 떨어지긴 함. 수치형이 더 중요!(머신러닝 할 때)
