vs code에서 파일을 쥬피터노트북 환경으로 보고 싶은데, 새 파일을 추가했을 때 자꾸 untitled란 이름으로 py환경으로 파일이 만들어졌다. 나는 쥬피터가 좋아서 그걸로 이름을 편집하려고 했는데 아예 이름편집이 없어졌다. 원래는 vs code 사용할 때 이름편집으로 해서 쥬피터노트북환경으로 바꿨는데,,, 그래서 결국 팀원분들에게 물어보고 도움을 받았다.(프로젝트 데이터를 봐야되는데 볼 수가없더,,,ㅠㅠ)
알고보니 옆에서 폴더를 열어놓고 거기서 파일을 만들어야 이름편집이 가능했다. 근데 그 폴더 여는것도 어떻게 하는지 모르겠어서 보니까 그 맨 왼쪽위에 보면 vscode 로고가 있고 그 옆에 짝대기 세개 그려진 것이 있다. 팀원분중 한분은 햄버거라고 표현하심. 암튼 그걸 클릭해서 열고->거기서 폴더 열기가 있어서 내가 생성하고 싶은 위치 폴더를 클릭하면 vs code환경에 폴더가 표시가 된다. 거기서 파일추가를 누르면 파일이름을 아예 지정해서 작성할 수 있게 됨!
그래서 파일하나 만들어서 지금 하고 있는중임. 안적어놓으면 또 나중에 까먹을 것 같아서 지금 적어놓는다.
오늘 할 일들: 데이터셋 살피기, vs code에서 글자 두번써지는거 고치기
데이터 셋 살펴보면서 알게된 점들, 공부한 내용
- pandas와 numpy에서 의 count()와 sum()의 차이점:
일단 count는 pandas에 있는 기능이고 numpy에는 없다. count()는 null값을 제외한 값들을 모두 세는 기능이고, sum()은 조건에 만족하는 수를 세는 기능이다. 아무리 조건을 설정해주어도 count로 계산하게 되면 null값 제외한 모든 값을 반환한다. 그래서 조건 설정해준 후에 그 갯수를 계산하려면 sum매서드를 쓰는것이 맞다.
(이것도 sql이랑 다른점..쓰다보면 익숙해지겠징... 괜히 헷갈린다 slq이랑 파이선이랑 같이 하다보면) - pandas에서 .describe()을 했을 때: 출력값이 평균값, 중앙값, 표준편차 이런게 나오는게 아니라 이런 식으로 나왔을 때:
count 592766
unique 104
top 0
freq 490868
Name: grade, dtype: object이렇게 나오는 이유는 보고자한 데이터셋이 범주형이기 때문이다. 숫자로 출력되어있지만 실제 타입은 범주형이라서 저렇게 나온다고 한다. 그래서 내가 원래 보고 싶었던 값들을 보려면 숫자형으로 바꿔주어야 한다. 바꿀 수 있는 방법: .astype(int), pd.to_numeric()
여기서 내가 생각했던 방법은 그냥 int()로 묶어주는 방법인데 이거는 전체 시리즈에 바로 적용되지는 않는다고 한다. 실제로 해보았을 때 typeerror가 난다.
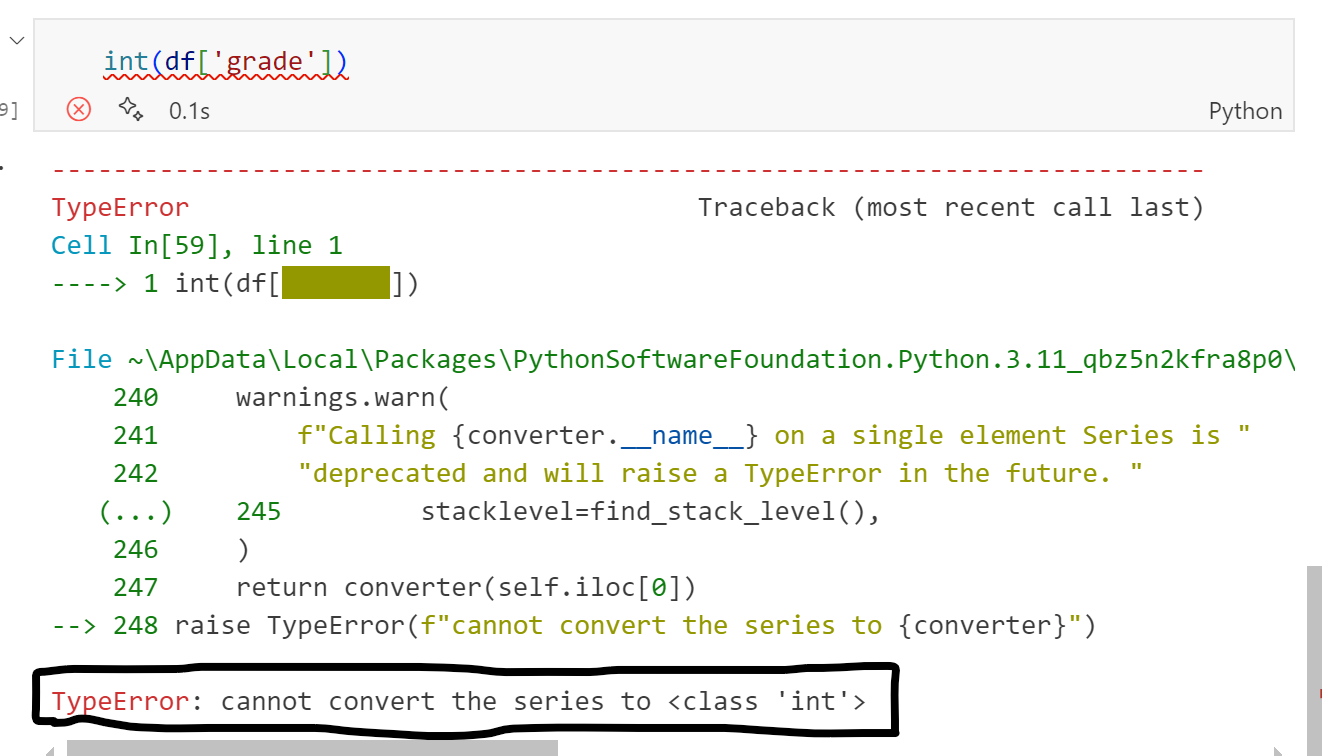
int()는 단일값은 바꿀 수 있지만(내장 자료형 하나에 쓰는 방식이라고 함) 시리즈에는 해당이 되지 않는다.

프로젝트 하면서 알게 된 사실
=> 💡결측치를 fillna로 채울 때 원래 dtype이 숫자형인데 채운값이 object형이면 그 컬럼은 dtype이 object가 된다.
프로젝트 하면서 알게 된 꿀팁
=> 💡여러줄에 마크다운 표시 해주려면 드래그 한 영역에 ctrl+/ 누르면 됨. ->드래그 한 영역 다 #처리가 된다.
프로젝트 하면서 알게 된 팁
=> 💡그 결측률 퍼센트 구하는 식이 있다고 한다. 결측률 몇퍼센트인지 계속 이야기가 나와서 물어봤는데 식이 있음. 바로 요것# 데이터프레임 전체에서 결측률 구하는 식 df.isnull().mean().sort_values(ascending=False) # 컬럼 하나의 결측률 구하는 식 df['컬럼'].isnull().mean() # 컬럼 하나의 결측률 구할 때는 .sort_values못 씀. 값이 하나이기 떄문에. .sort_values는 시리즈나 데이터프레임에서 사용가능함. 전체 컬럼 결측 비율 정렬 을 목적으로 할 때 .sort_values를 사용.근데 이해가 잘 안간다...왜 저기서 평균을 하는데 결측률이 나오는거지..? 이해감!! 그니까 그 결측값을 boolean?타입으로 보고 그 각 컬럼에서의 결측값평균을 구한다는 말은 전체값을 더해서 행수로 나눈다는 소리이다. 이거는 그냥 그렇게 생각하면 됨: 평균의 의미를 생각해보자! 평균이 무엇인가. 값을 더해서 그 갯수를 나누는거잖아. 그러니까 전체값을 더해서 갯수를 나눈다. 전체 true값 =1을 더해서 그거를 전체갯수로=행수 나누는것이다.
키포인트는.isna()가 결측값이 True로 반환된다는 것이다. 나는 계속 결측값이 아닌게 True로 된다고 생각하니까 이게 뭐지 싶었음.

프로젝트 주제는 결국 공모전은 하지 않기로 결정되었다. 너무 어려운 주제이고, 우리 팀 한분 빼고 모두가 도메인 지식이 없기도 했고, 도메인지식이 있으신분도 너무 어려운 데이터셋이라고 하셨다.
그래서 결국-> 저번주에 정했던 '교육'데이터로 정하게 됨.
오늘은 그래서 컬럼들 하나씩 살펴보고, 어떤식으로 분석하면 좋을지, 파생변수 등을 생각해보는 시간을 가졌다.
오늘 진행한 프로젝트 내용
- 프로젝트 방향성 큰 틀 잡기: 각자 데이터 살펴보면서 프로젝트 방향성이나 결측치 또는 이상치 처리, 파생 변수에 대한 아이디어 생각해보기
- 본인이 살펴본 데이터셋 자유롭게 공유하기
- 각자 컬럼 맡아서 결측치 또는 이상치 처리 어떻게 할지 뜯어보고 공유
- 다같이 코드 합치면서 컬럼 하나씩 전처리 진행
이런 인터넷강의,,에서 중요한 것이 aaarrr이라고 한다. 이거 저번에 어떤 강의에서 들었던 지표인데.. 암튼 그렇다.
이번팀은 코드 합치는 작업을 다 같이 진행했다는 점이 그전의 팀들과는 달랐다. 신선하고 좋았다. 같이 전처리에 대한 의견 나누면서 진행할 수 있었고, 내가 보지 못했던 부분들을 볼 수 있었고, 고민하던 부분에 대해서 또다른 정보를 통해 실마리가 풀리기도 했다.
일단 처음 나는 이 데이터가 약간 학원데이터 또는 강의 플랫폼의 흔한 데이터 중 하나라고 생각을 했다. 그리고 계속 컬럼들 및 데이터값을 보면서 알게된 점, 느낀점은 거의 망한 교육 데이터 라는 생각이 들었다. 왜냐하면 어떤 데이터를 파헤쳤을 때 편차가 다 너무 크고, 실행수나 수업을 다 듣고 받는 수업인증서 획득 수라던지 이런것들이 전체 데이터셋 크기에 비해 작았다. 이것에서 알게 되었던 점은: 열심히 하는 애들과 아예 안하는 애들의 편차가 크다는 것.
그래서 이런 데이터도 있구나 오히려 망한 인터넷강의를 어떻게 하면 살릴 수 있을지로 방향설정을 하게 되었다.
개인적으로는 certificated 컬럼에서 받은 사람과 못받은 사람 두부류로 나뉘니까 이거를 나눠서 비교해보면 어떨까 싶기도 했다.
그리고 계속 토론하고 고민했던 쟁점 중 하나가 강의를 듣기 시작한 날짜는 결측치 없이 다 있는데, 마지막으로 강의를 들은 날짜는 결측치가 있었다. 그래서 마지막 시청 날짜 컬럼이 last_event_DI인데, 이 결측치를 어떻게 처리해야할지에 대해서 계속 고민하고 나눴다. 결국은 튜터님께 찾아갔는데 튜터님께서 하신 질문은 이런것이었다.
- 그 컬럼에서 어떤 의미를 찾을 수 있는지?
- 어떤걸 뽑아내야 할까?
- 꼭 필요한 컬럼인가?
등 이었던 것 같다. 그래서 일단은 우리는 dropna를 사용해서 결측값이 있는 행은 날려버렸다.
# subset=은 특정 컬럼의 결측치가 있는 행만 지운다는 뜻이다.
df.dropna(subset=['last_event_DI'])내가 맡았던 컬럼은 나이에 관한 Yob컬럼이었다. 컬럼을 살펴보니
※ 코드 밑에 출력값을 적어놓았음.
# 결측치 96,605개. 결측치 어떻게 처리할지? & 이상치 제거 범위 설정
# 값이 있는 행 544,533개
df['YoB'].count()
#출력값
np.int64(544533)
df['YoB'].nunique()
78
df['YoB'].describe()
count 544533.000000
mean 1985.253279
std 8.891814
min 1931.000000
25% 1982.000000
50% 1988.000000
75% 1991.000000
max 2013.000000
Name: YoB, dtype: float64
#날짜 확인
min_date = df['start_time_DI'].min()
max_date = df['start_time_DI'].max()
print("최소 날짜:", min_date)
print("최대 날짜:", max_date)
최소 날짜: 2012-07-23
최대 날짜: 2013-09-08
#1931년생 기준 2012년에 등록했다고 치면 만 80~81세임. 80세 어르신이.. 강의를...들으실 수.. 있을랑가..? 혹시 강의 주제에 대한 정보가 있나..?
2013년생은 결측치네. 어떻게 들어..
#히스토그램 확인
plt.hist(df['YoB'], bins= 'auto')
plt.xlabel("Year of Birth")
plt.ylabel("count")
plt.title("Histogram of Year of Birth")
plt.show()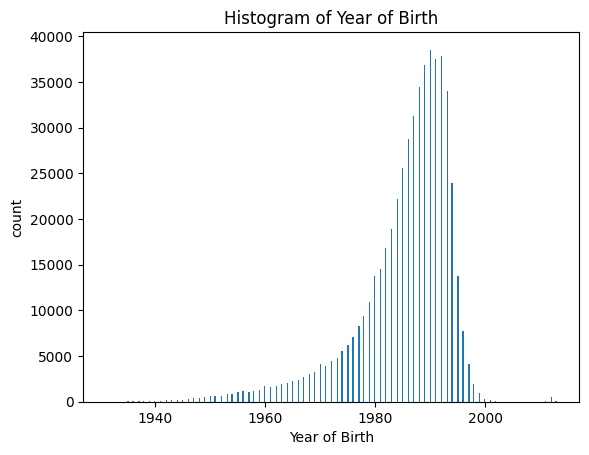
1940년생 = 만71~72세
근데 실제 자격증 시험같은거 볼 때 70세이상이신 분들도 굉장히 소수이지만 있었다. 나 사회복지사 1급 시험 합격률 확인했을 떄도 있었음. 그래서 놀랐던 경험이 있음.
또 찾아보니까 80세에 검정고시 합격하신 분도 계셔서,,, 고령자는 이상치 처리 굳이해야되려나 싶긴 함...
또한 나이많은 사람들이 교수님일 가능성도 있으니 일단은 나이가 많은 사람들은 빼지 않기로 하였다.하지만 2013년생은 이상치로 봐야함.
#컬럼 확인: 과목같은거나 강의 주제에 관련한 컬럼 없음.
df.columns이후에 노인들쪽 말고 출생년도가 가장 늦은 년생을 보았더니 2013년생이 있었다. 이것은 명백한 이상치인데, 몇살까지를 이상치로 처리해야할지 고민이 되었다.
강의데이터를 찾아보니 실제 있는 강의들이었고, 하버드,MIT의 인터넷강의들이었다. 강의명도 찾음. 그래서 일단 미취학아동에 해당하는 나이들은 다 제거하였다.(명확하게 절대 듣지 못하는 아이들나이 이상치 제거)
# 이상치 처리
df = df[df['YoB'] < 2005] # 2005년 이전 출생자만 조회(미취학 아동)등등으로 오늘은 drop할 컬럼들 지정하고, 수업이름 바꿔주고, 결측치 fillna로 채워주고, 이상치 제거, 결측치 날릴거 날리고, dtype바꿔주고, 파생변수1개 생성하였다. 전체 코드 공유하였고, 내일부터는 본격적으로 데이터 셋 살펴봐야 할 듯하다. 아까 이야기했는데. 뭘 볼지...갑자기 또 기억이 안난다..
(641138, 21) -> (543925, 18) 데이터 전처리 1차 완료.
다행히 이번 프로젝트는 잘 따라가고 있다....힝,,, 다행이ㅑ 감사해.. 열심히하겠습니다! 소프트 스킬!
