
진짜 오랜만에 sql 코드카타를 풀었다.
오늘 푼 문제는
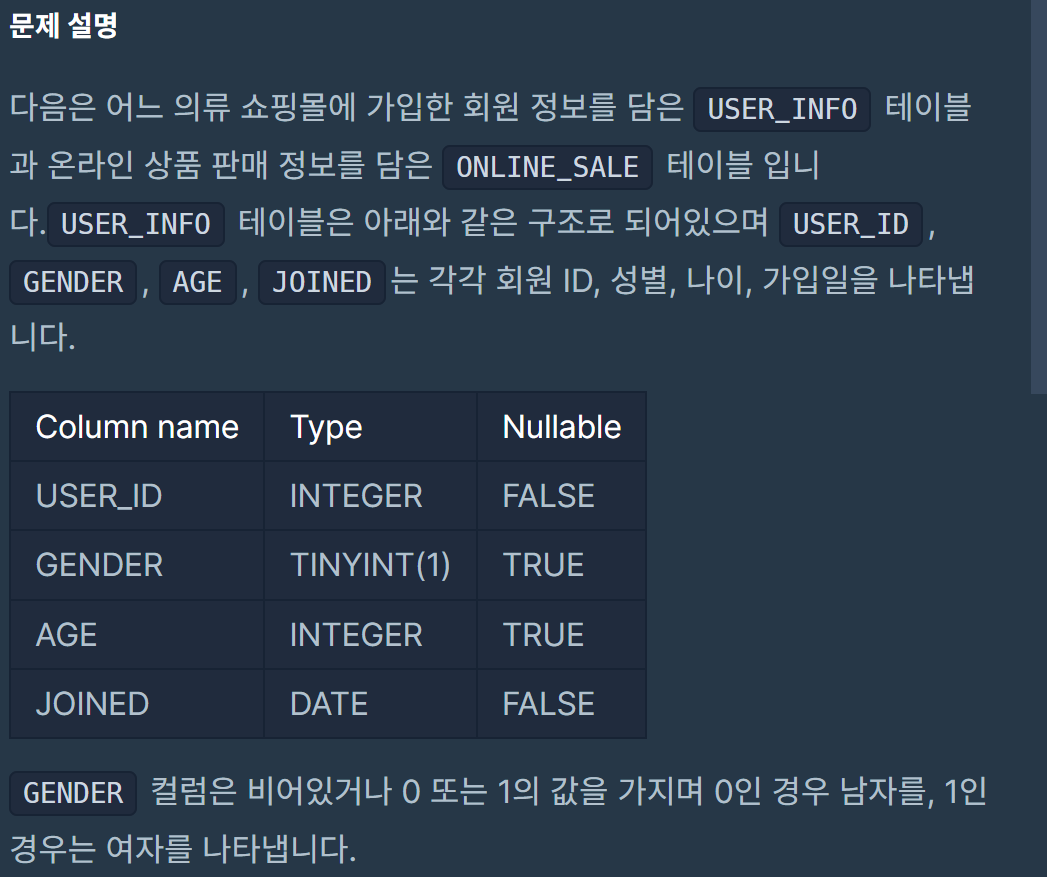
나의 풀이
-- Gender가 null값이면 회원수count 계산 하지 않음.(gender별로 계산해야하기 때문에)
#날짜 쪼개는게 뭐였지.. 컬럼값 스플릿하는게 뭐였지...!!->substr
#쪼개서 나누고 그걸로 group by 한 다음에 count()하면 될 것 같은데
SELECT substr(s.sales_date,1,4) YEAR,substr(s.sales_date,6,2) MONTH,
u.gender GENDER, count(distinct u.user_id) USERS
from user_info u inner join online_sale s on u.user_id=s.user_id
where gender is not null
group by YEAR, MONTH, GENDER
order by YEAR, MONTH, GENDER컬럼값을 쪼개는게 지금 판다스에서 df.split(구분자)밖에 생각이 안나서 결국 구글링을 했다.->정답은 substr!
💡sql에서 컬럼을 쪼개는 함수는 substr이다.
=>substr(컬럼,문자 또는 숫자쪼개는 시작 지점(sql에서는 1부터 시작한다),시작지점부터 몇 칸 후에 끝낼건지)
ex)substr(s.sales_date,6,2)은- s.sales_date컬럼 '값'에서 6번째부터 2번째까지 쪼개갰다는 소리. ->6~7번째에 위치한 문자열만 갖고 오겠다. 라는 말임
그래서 코드 적었더니 정답!!(이게 얼마만의 한번에 뜨는 정답화면인지..(감개무량..))
내가 sql 푸는 방법은 일단 문제 읽고, 예시를 꼼꼼히 읽은 다음에 테이블 하나씩 다 봐주면서 파악을 한다. 그리고나서 select절에 어떤 것이 와야하고, from 절에서 join을 해줘야 한다면 어떤방식으로 해줘야하는지 파악한 후에- 조건이 있다면 where절로 조건을 작성해준다.
-그리고 문제에서 "년,월,성별 별로 상품을 구매한 회원수를 집계"하는 쿼리를 짜달라고 요청했기 때문에- group by로 묶어야 한다고 생각이 자연스럽게 이어졌다(나 이제 자연스럽게 group by 생각할 수 있는 사람이야,.🥲🥳감동,,)년-월별-성별이기 때문에 차례대로 그룹바이 해줘야 한다고 생각했다. 그리고 마지막 count는 회원수이기 때문에 count를 해주는데- 여기서 같은년도-같은월에 구매한(일자는 다른)동일한 user_id가 있기 때문에 distinct를 추가로 쿼리를 짰다.
그다음 문제


내가 짠 쿼리
-- sql에서 평균값 구하는게 mea()아닌가,,?ㅋㅋㅋ mean은 파이선이고, sql은avg임..ㅋㅋㅋ
-- 그룹바이를 하나만 해줘도 되는구나,, 아닌가,,? 요 프로그램 내에서는 동작이 가능한데, 이렇게 쓰는게
-- 맞는.. 가능한..건지는 여쭤보아야겠음.
SELECT i.rest_id, i.rest_name, i.food_type, i.favorites, i.address,
round(avg(r.review_score),2) score
from rest_info i inner join rest_review r on i.rest_id=r.rest_id
where address like '서울%'
group by i.rest_id
order by score desc, i.favorites desc또 바로 정답이 나왔다. 대박사건 ...나 감동받아,,,
암튼 여기서의 블로커는 평균값이었다.ㅋㅋㅋ 파이선판다스만 계속 하다보니 평균값 구하는 함수가 mean()밖에 생각이 안났다. 근데 sql에서는 평균값이 avg() 이다.
❓그리고 궁금했던 점 하나: 수업 들을 때 select절에서 집계함수가 나오면 그 앞에 있는 것은 무조건 group by를 해줘야한다는 것.이었는데 요 쿼리에서는 avg앞에 5개나 되는 컬럼들이 위치해있다. 그래서 이걸 꼭 다 group by로 묶어줘야 하는것인가?(지금 코드카타 환경에서는 이게 정답으로 잘나오지만 다른 환경에서는 에러가 날 가능성이 있는건가?)가 내 의문이었다. 그래서 어차리 한 id별 당 하나의 가게와 리뷰수가 있으니 id만 그룹바이로 묶어주었는데- 정답으로 나왔다. 그리고 집계된 컬럼 앞에 있는 모든 컬럼 다 가져와서 group by 해줘보기도 했다.
group by i.rest_id, i.rest_name, i.food_type, i.favorites, i.address그래도 결과값 동일하고 채점했을 때 정답이 나옴.
=> 그래서 튜터님께 가서 여쭤봄. 어쨌든 푸드타입이 한 가게에 여러개 있을 수 있기 때문에 만약에 그렇다면 내가 처음 짠 쿼리는 틀릴 가능성이 있다는 것-을 말씀해 주셨고, 에러에 대해서는 지금 사용하는게 mysql이기 때문에 mysql환경에서는 에러없이 잘 나올거라고 하심. 근데 다른 sql환경(예를 들어 오라클이나 무슨sql뭐 또 다른게 있었다)에서 하면 에러가 날 수도 있다고 하셨음. 그리고 디비버는 그냥 껍데기라고 생각하면 된다고 하셨다. 그니까처음에 mysql을 디비버에 또 설치해야한다고 해서 뭘까..싶었는데 이건가보다.
정리하면 문제마다 다를 수 있고, 약간 정석같은 느낌은 다 써주는게 맞긴하다. 라는 것이다. 문제를 많이 풀어보면서 더 감각을 익히는게 중요할 듯하다.
💡파이선 에러메세지에서
"not 1-dimensional" 은 1차원이 아니다- 라는 뜻이다.
파이선이나 판다스에서 에러메세지로 자주 등장한다고 함.
이 에러는 Series 또는 1차원 배열을 기대하는 곳에 2차원 이상의 데이터가 들어갔을 때 발생한다.
태블로 강의듣고 실습하고 문제도 풀어보았다.
진짜 드래그앤드롭이면 다 된다. 여기저기 다 갖다넣을 수가 있다.
함수도 사용이 가능한데- sql에서 쓰는 함수를 쓰기도 하고 조금 다른 함수같은것을 쓰기도 한다. datediff함수랑 dateadd함수. 이런거
대시보드 구축 프로세스가 있다. 여러가지 기능도 많고 여러가지 예시도 많고, 효과적인 대시보드를 만들기 위한 기준들도 있고 암튼 배우고 익힐 수 있는 자료들이 넘쳐난다. 오늘은 다시 1,2강부터 복습하면서 그것들을 보는 시간들을 가졌다.
LOD식에서 실무에서는 fixed를 가장 많이 활용한다고 한다. fixed랑 include?랑 exclude가 있다.
-ARPU:Average revenue per user = 총 매출/ 전체 구매자 수
대시보드에서 대시보드 탭-동작 으로 타고 들어가면 원본시트와 대상시트가 있다. 원본시트는 동작하는 것이고 대상시트는 동작할 때 바뀌는 시트를 말한다.
그리고 대시보드같은거 저장할 때 twb와 twbx가 있는데, twb는 통합문서이고 데이터를 포함하지 않는다. 시각화만 볼 수 있음. twbx는 데이터랑 같이 저장이 되어서 서로 파일 주고 받기 할 때(거기서 수정도 가능함) 저 파일형식으로 저장해야 함.
countd는 count distint를 말한다.
오늘 과제에서 내가 만든 대시보드
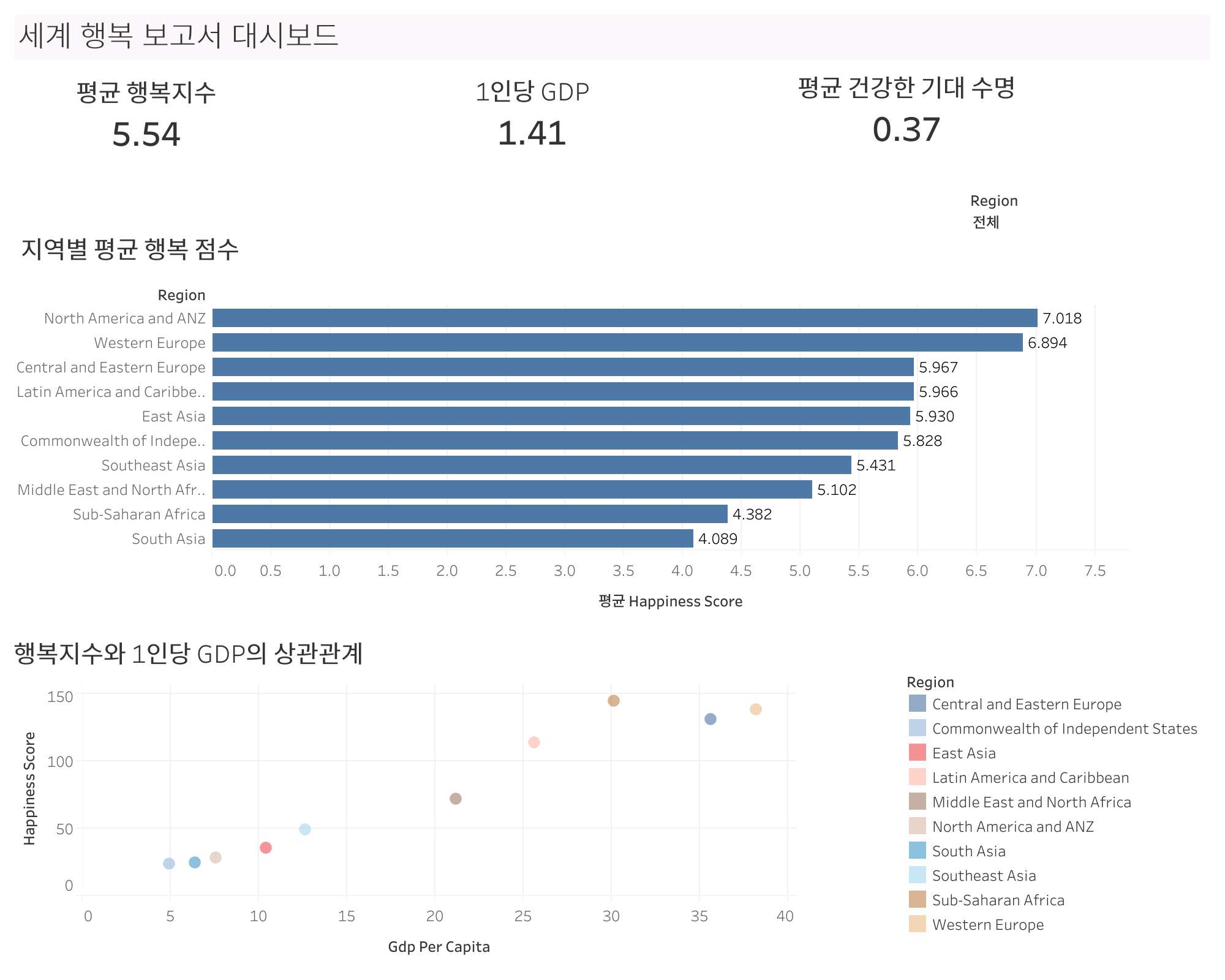
처음치고는 잘 만들었다고 생각한다. 왠지 뿌듯한걸..?
이게 튜터님이 강의에서 하신것처럼 그 바둑판식으로 했을 때 위치를 여러가지로 추천을 해줬는데 내 대시보드에서는 너무 투박하게 진짜 도 아니면 모 식으로 추천을 해줘서 부동으로 하나하나 그리드 보이게 해줘서 그거에 맞춰서 대시보드를 짰다. 원래 저 형태아니었는데 만들다 보니까 또 욕심이 생겨서 요롷게 저렇게 만들다가 저렇게 나왔다. 근데 또 보다보니까 바꿔보고 싶기도 하네..? 저 지역별 평균 행복 점수표랑 행복지수와 1인당 gdp상관관계 표 위치를 바꿔보면 어떨까.?> 흠..아직 도전문제는 못풀어봤는데 풀어봐야겠다. 일단은 그 라이브세션 다시 들으면서 계속 풀었다.
필터 거는 법은 그냥 필터 걸고싶은 컬럼? 가져다가 필터란에다가 드래그 앤 드롭 해주면 된다. 그리고 그것을 대시보드에 가져다 놓고 거기있는 시각화들에도 다 필터 적용하고 싶으면 필터 옆에 세모 눌러서 거기서 '워크시트에 적용'-> 둘 중 하나 누르면 된다. 그러면 여러개에 다 적용이 가능해짐. 하나 누르면 다른 데이터도 움직인다. 신기..
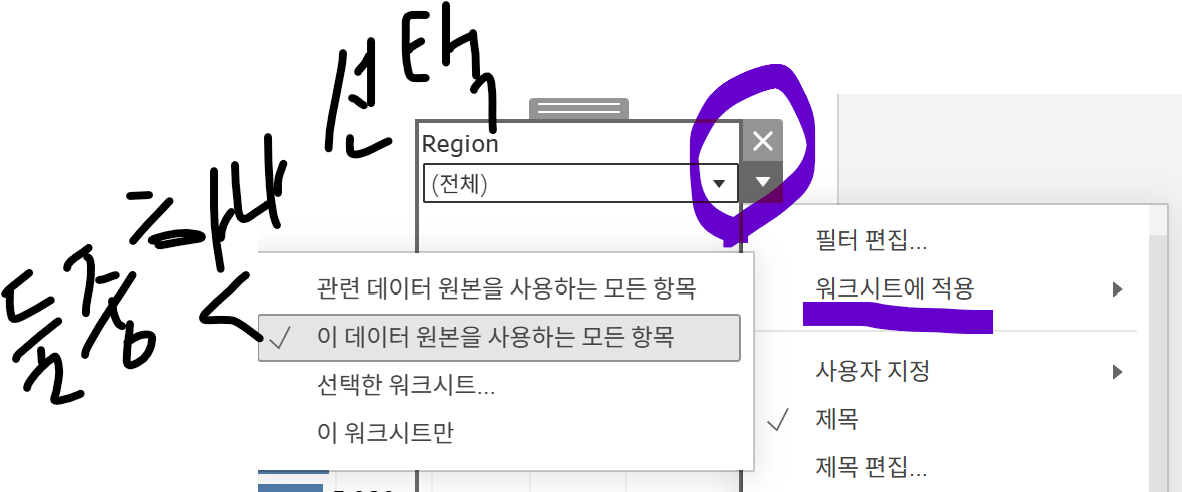
그.. 화이팅!! 내가 배움이 느리긴 한 것 같다. 다른 사람들은 토끼같다. 엄청 빠르게 배우고 막 적용하고 막 파바박 하는데 나는 하나,하나,하나 요론느낌스.. 뭐 거북이권법으로 가보겠다.. 화이팅!@!!!
