Bellman Equation
상태의 가치와 특정 정책을 따라가는 동안 해당 상태에서 기대되는 누적 보상 간의 (재귀적)관계를 표현합니다.
Bellman Expectation Equation
벨만 기대 방정식은 예상되는 즉각적인 보상과 다음 상태의 기대값 측면에 따른 상태의 가치를 표현합니다.
State Value Function
MDP일때
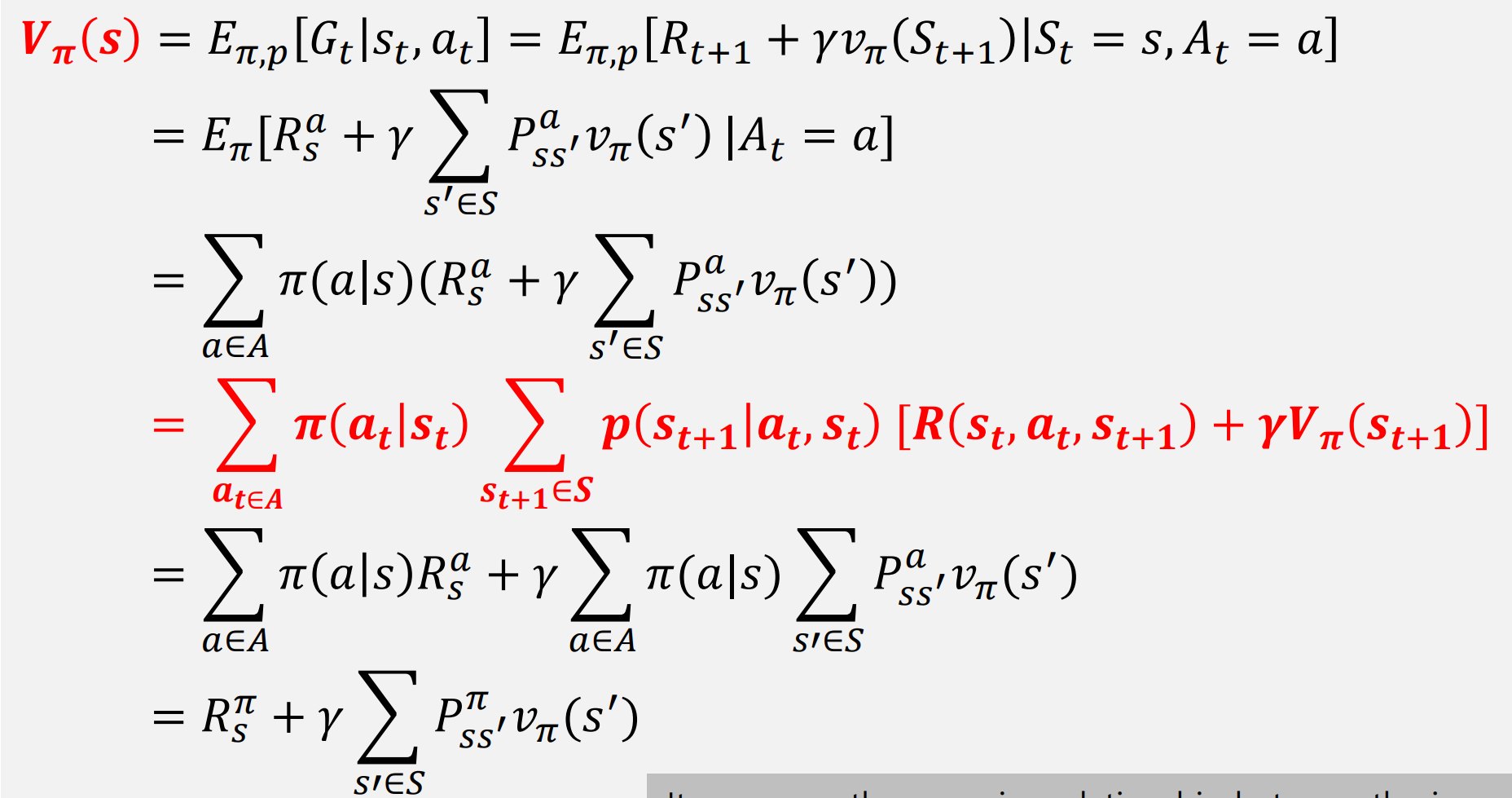
Action-Value Function
정책을 기반으로 한 특정 액션이 얼마나 좋은지를 추정합니다.
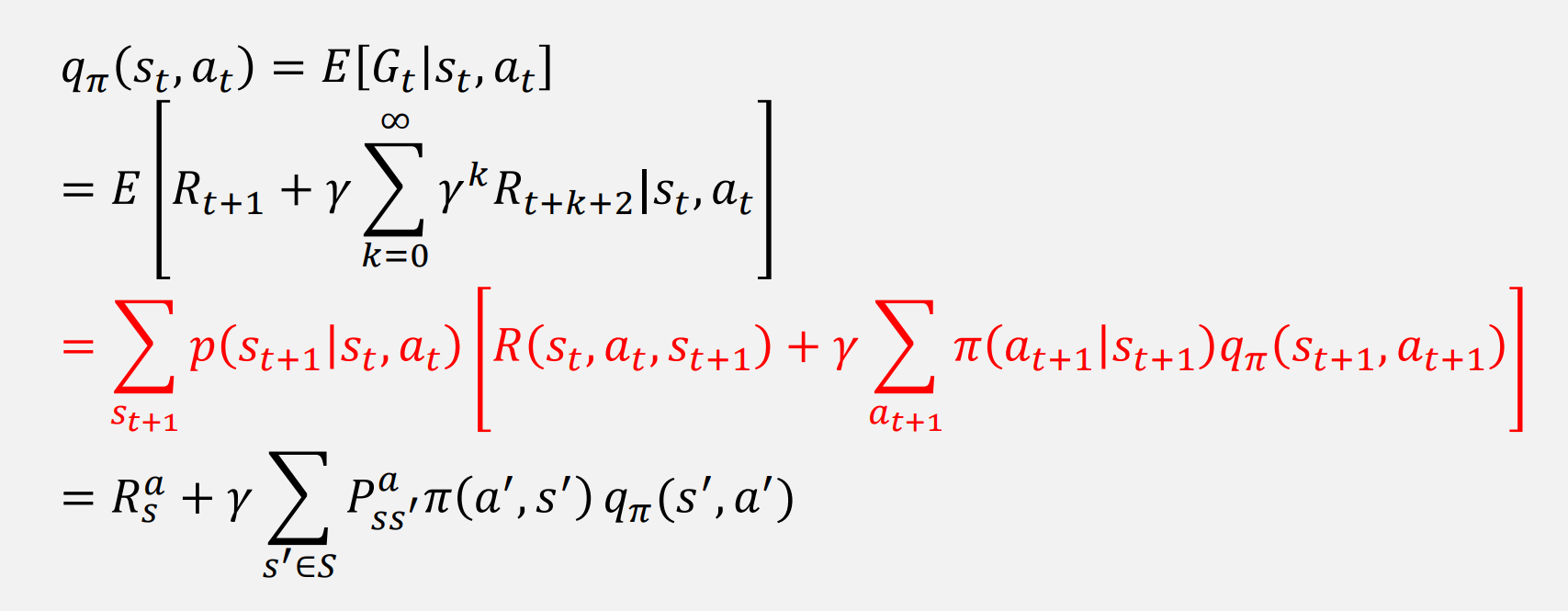
Bellman Optimality Equation
각 상태에서 달성할 수 있는 최대 예상 누적 보상을 나타내는 최적 가치 함수 입니다. 최적의 정책 𝝅∗를 구합니다.
Optimal State-Value Function
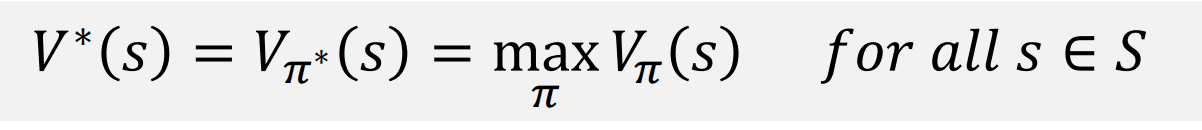 가장 큰 값을 가지는 가치함수가 최적의 상태 가치 함수
가장 큰 값을 가지는 가치함수가 최적의 상태 가치 함수
Optimal Action-Value Function
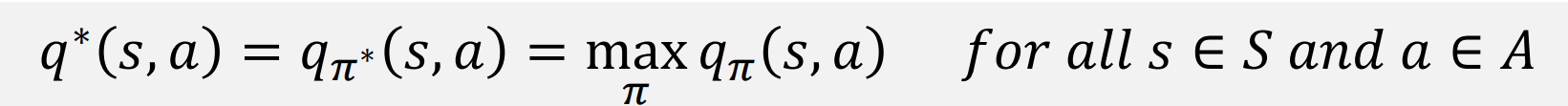 Optimal State-Value Function과 마찬가지로 가장 큰 값을 가지는 action value함수가 최적의 action value 함수
Optimal State-Value Function과 마찬가지로 가장 큰 값을 가지는 action value함수가 최적의 action value 함수
내 생각
공부할 때 diagram을 그리면서 하면 좋을 것 같음!
