Markov Decision Process
1. MP(Markov Process)
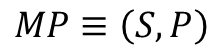
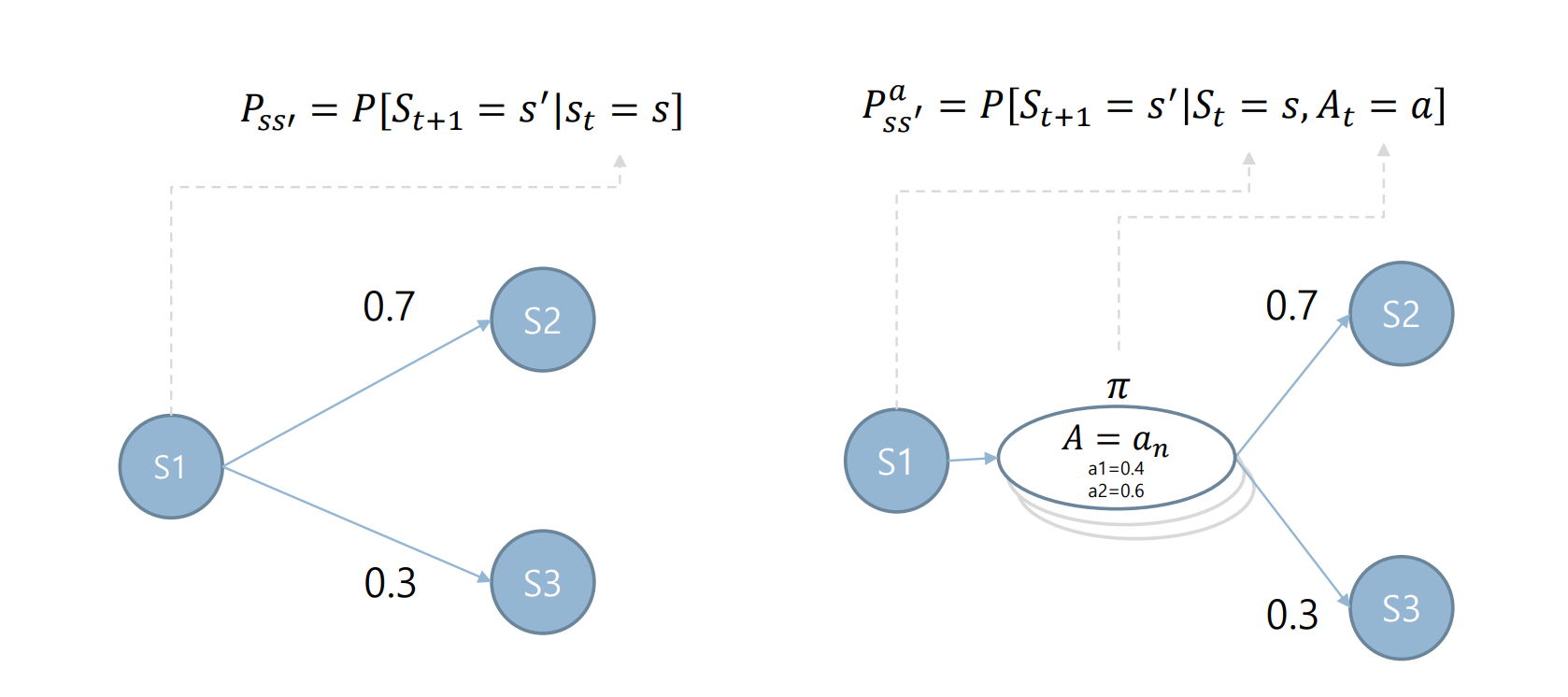
마르코프 프로세스는 상태(S)와 전이확률행렬(P)로 정의합니다
S : state space = {𝑆0, 𝑆1, 𝑆2, … }
P: Transition probability model (matrix)
1.1 Markov property
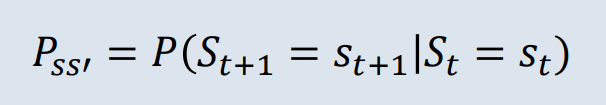 상태(St)일때 상태(St+1)로 전이 될 확률로 미래는 오로지 현재에 의해 결정됩니다. 따라서 상태(St)가 되기까지의 과정은 확률 계산에 영향을 주지 않습니다.
상태(St)일때 상태(St+1)로 전이 될 확률로 미래는 오로지 현재에 의해 결정됩니다. 따라서 상태(St)가 되기까지의 과정은 확률 계산에 영향을 주지 않습니다.
2. MRP(Markov Reward Process)
마르코프 프로세스에 보상의 개념이 추가되면 마르코프 리워드 프로세스입니다.
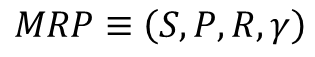
R: Reward
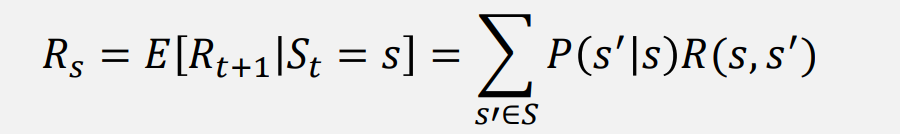 어떤 상태 S에 도착했을 때 받게 되는 보상
어떤 상태 S에 도착했을 때 받게 되는 보상
𝛾: Discount Factor
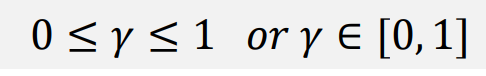 미래에 얻을 보상과 지금 얻는 보상 중에 어느 것을 더 중요하게 여길 것인지를 나타내는 파라미터
미래에 얻을 보상과 지금 얻는 보상 중에 어느 것을 더 중요하게 여길 것인지를 나타내는 파라미터
- return value가 무한대로 가는 것을 방지해줍니다.
Episode
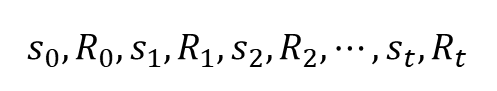 S0에서 St까지 가는 여정을 표현
S0에서 St까지 가는 여정을 표현
Return(G)
에피소드 동안에 발생하는 모든 보상의 합
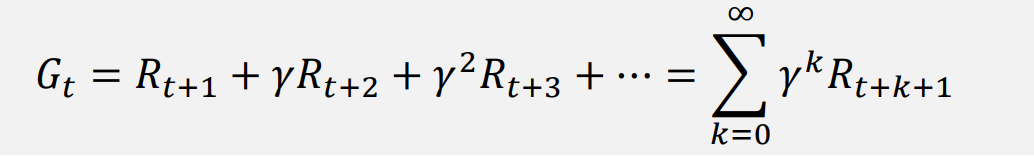
- 에피소드가 주어지면 state transition probability는 항상 1입니다.
3.MDP(Markov Decision Process)
위와 다른 것은 의사결정이 핵심입니다.
- MRP에 에이전트가 더해진 것
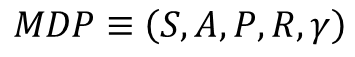
A: Set of action
에이전트가 취할 수 있는 액션들의 모음
Policy (𝝅): Probability for Action
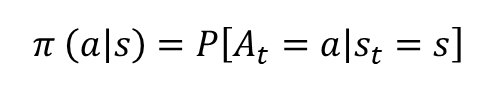
각 상태에서 어떤 액션을 선택할지 정해주는 함수로 𝝅로 표기합니다.
State Transition probability
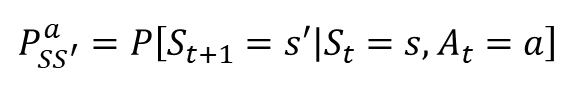 현재 상태 s이며 에이전트가 액션 a를 선택했을때 다음 상태가 s'이 될 확률
현재 상태 s이며 에이전트가 액션 a를 선택했을때 다음 상태가 s'이 될 확률
reward considering policy
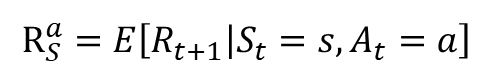 현재 상태 s이며 에이전트가 액션 a를 선택했을때 받는 보상의 기댓값
현재 상태 s이며 에이전트가 액션 a를 선택했을때 받는 보상의 기댓값
MRP vs MDP