constrative learning
self-supervised learning(자기지도학습)에 사용되는 접근법 중 하나로, 사전에 정답 데이터를 구축하지 않는 판별 모델이라고 할 수 있습니다.
따라서, 데이터 구축 비용이 들지 않음과 동시에 학습 과정에 있어서 보다 용이하다는 장점을 가져가게 됩니다. 이러한 데이터 구축 비용 이외에도 label이 없기 때문에,보다 일반적인 feature representation과 새로운 class가 들어와도 대응이 가능하다는 장점이 추가적으로 존재합니다.
이후, classification 등 다양한 downstream task에 대해서 네트워크를 fine-tuning시키는 방향으로 활용하곤 합니다.
Contrastive Representation Learning
앞서 말했듯이 입력 샘플 간의 비교를 통해 표현을 학습하게 됩니다. 따라서, 학습된 표현 공간 상에서 "비슷한" 데이터는 가깝게, "다른" 데이터는 멀게 존재하도록 표현 공간을 학습하는 것이 목적입니다.
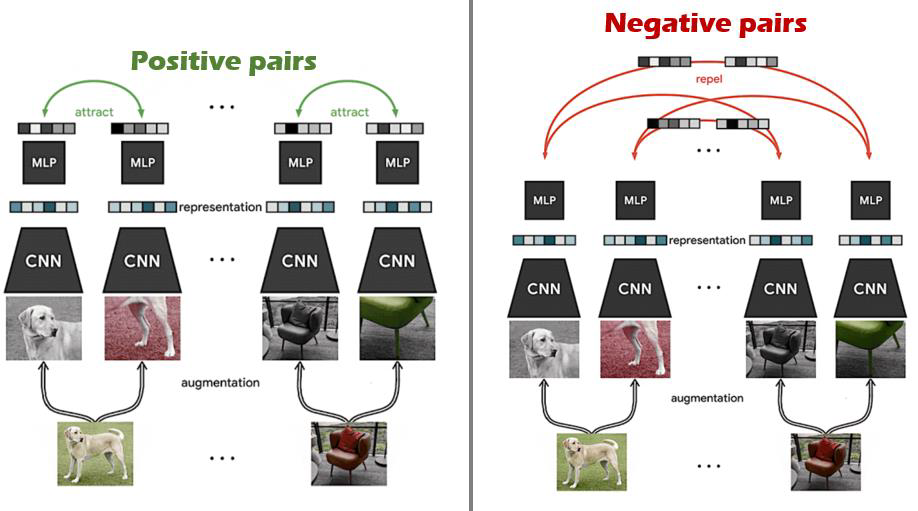
여러 입력쌍에 대해 유사도를 라벨로 판별모델을 학습합니다. 유사함의 여부는 데이터 자체로 정의될 수 있습니다.
(→ 데이터 자체로 정의되기 때문에 self supervised learning입니다.)
SimCLR
정리중
MoCo
정리중
참고자료
- 수업 PDF 참고
- https://daebaq27.tistory.com/97
