딥러닝
1.Attention
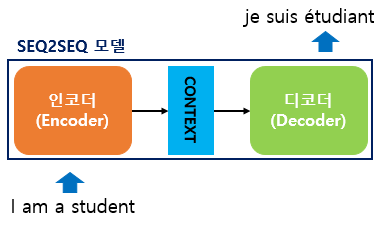
seq2seq의 encoder-decoder는 2개의 RNN(일반적으로 LSTM or GRU)응용분야 : 번역, 질의응답, 챗봇, 문서요약 등등Source sequence x= (x1, x2,..., x|x|): 문장의 각 단어를 vecto들로 표현한 (embeddin
2023년 12월 4일
2.tansformer
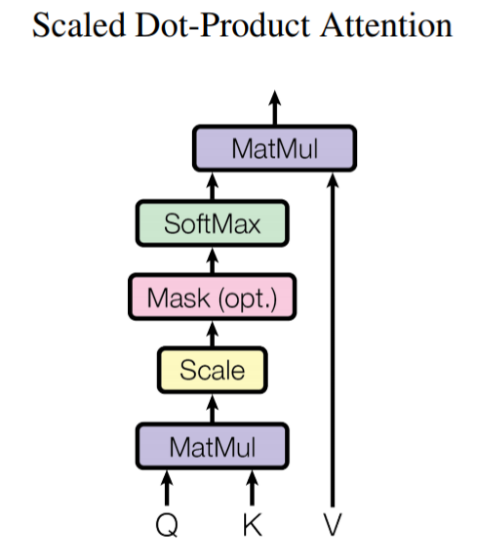
attention은 하나의 토큰에 대해 Query, Key-value를 입력으로 가지는 데 tansformer는 Query, Key,value를 한번에 넣습니다. → self attention → 문장에서 단어 연관성을 알기 위해서 사용합니다.scaled dot pro
2023년 12월 4일
3.Diffusion Model
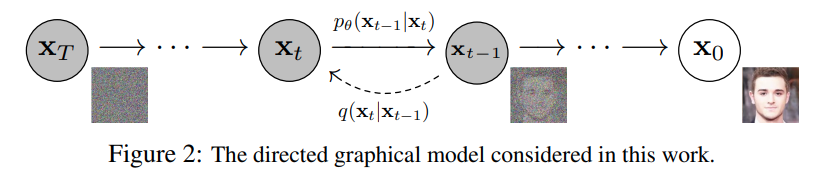
특정 data에 점차 nosie를 더해서 완전한 noise로 만든 후 역으로 복원하는 과정을 학습하는 model입니다q(xt-1|xt)를 model로 근사화 하는 것이 diffudion model p(xt-1|xt)의 핵심입니다. 해당 data가 noise될 때 진행
2023년 12월 4일
4.self supervised learning

정리중 정리중 정리중
2023년 12월 4일
5.constrative learning(SimCLR, MoCo)
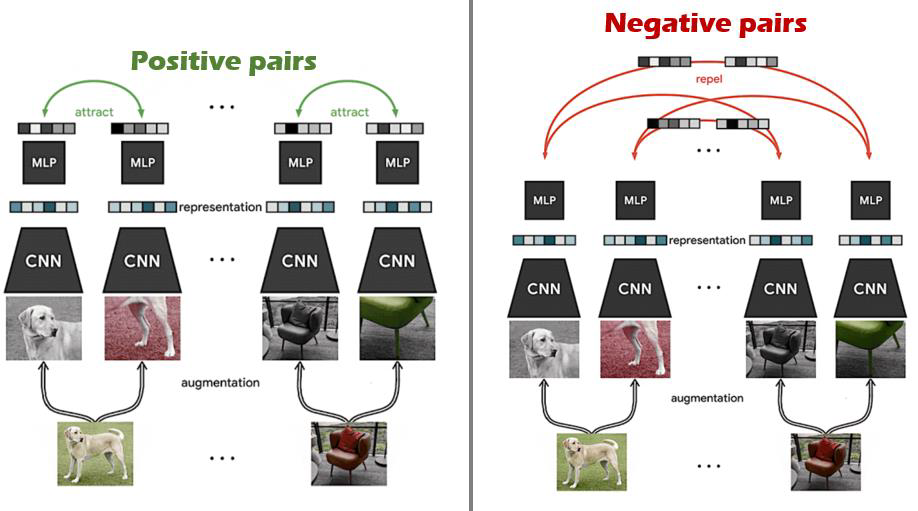
self-supervised learning(자기지도학습)에 사용되는 접근법 중 하나로, 사전에 정답 데이터를 구축하지 않는 판별 모델이라고 할 수 있습니다. 따라서, 데이터 구축 비용이 들지 않음과 동시에 학습 과정에 있어서 보다 용이하다는 장점을 가져가게 됩니다.
2023년 12월 4일