tansformer
attention은 하나의 토큰에 대해 Query, Key-value를 입력으로 가지는 데 tansformer는 Query, Key,value를 한번에 넣습니다. → self attention → 문장에서 단어 연관성을 알기 위해서 사용합니다.
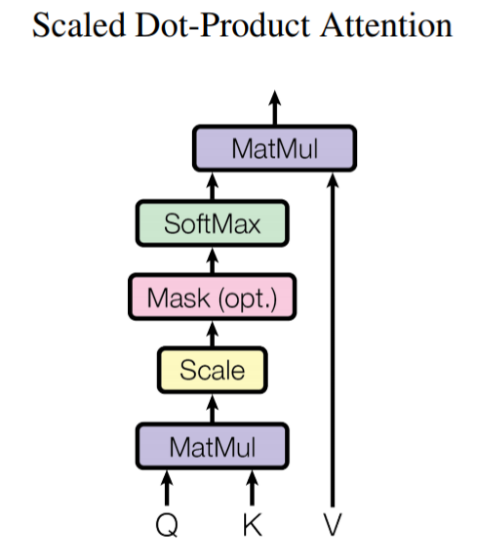
scaled dot product를 이용해 attention value를 계산합니다.
mask를 사용해 input이 계산되는 데 제약을 줄 수 있습니다. → 한번에 문장을 다 넣어주다보니 단어를 예측할 때 뒤 단어를 보고 예측할 수 있기 때문에 mask를 사용합니다.
padding은 문장의 길이를 맞추기 위해 사용합니다.
decoder에서는 mask 안된 부분, padding 안된 부분만 사용합니다.
앞서 언급했듯이 한번에 문장을 다 넣어주다보니 단어 간 순서가 반영되지 않습니다. → positional encoding을 통해 위치 정보를 각 단어 임베딩에 더해줍니다.
multihead attention
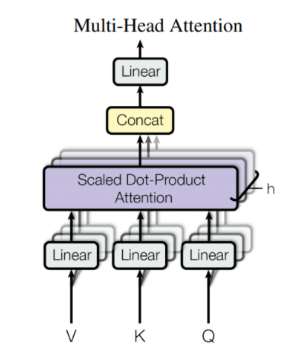
head 수만큼 attention을 병렬로 처리합니다 (성능이 올라갑니다) 나온 attention value를 concat해줍니다.
teacher forcing
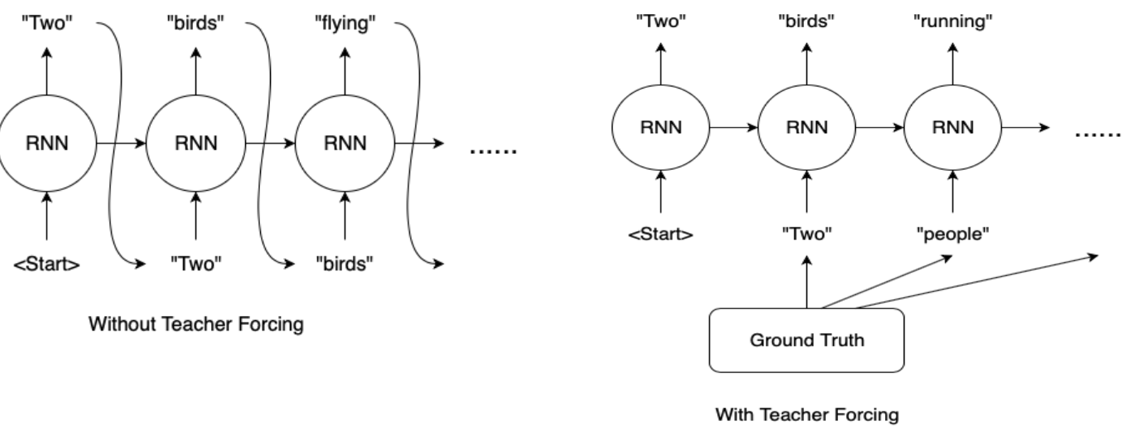 오답을 예측하면 ground truth로 바꾸어 입력으로 넣어줍니다. 이렇게 하면 초기 학습 속도가 올라가고 더 정확하게 예측합니다.
오답을 예측하면 ground truth로 바꾸어 입력으로 넣어줍니다. 이렇게 하면 초기 학습 속도가 올라가고 더 정확하게 예측합니다.
내 생각
그래프를 이용해 변역 단어의 관계를 파악한 후 번역을 하면 성능이 더 올라가지 않을까...
