[paper review] Xception: Deep Learning with Depthwise Separable Convolutions
Introduction
- Xception : eXtreme Inception
- 기존 Inception
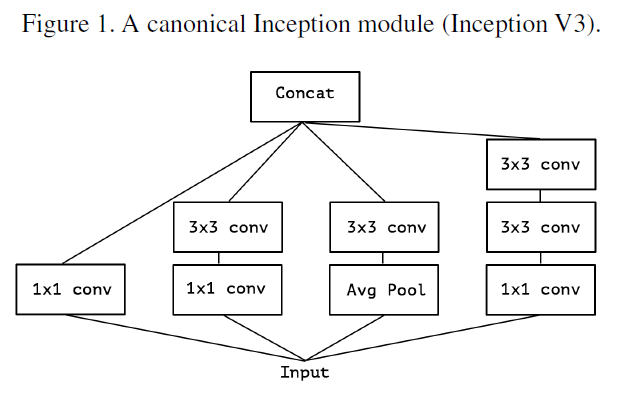
1x1 convolution을 통해 cross-channel correlation을 학습하고, 이후 3x3, 5x5 convolution을 통해서 spatial correlation을 학습한다.
- cross-channel correlation: 입력 채널들 간의 관계 학습
1x1 convolution(=pointwise convolution)을 통해서 학습 가능
- spatial correlation: filter와 특정 채널 사이의 관계 학습 (공간적인 특성 학습)
일반적인 convolution은 하나의 filter로 cross-channel correlation과 spatial correlation을 동시에 학습함
Inception은 이를 분리해서 학습함으로써 모델의 성능을 높일 수 있었다고 함
Xception의 저자는 이러한 분리를 더 강하게 해보자! 라는 아이디어로 출발
Xception
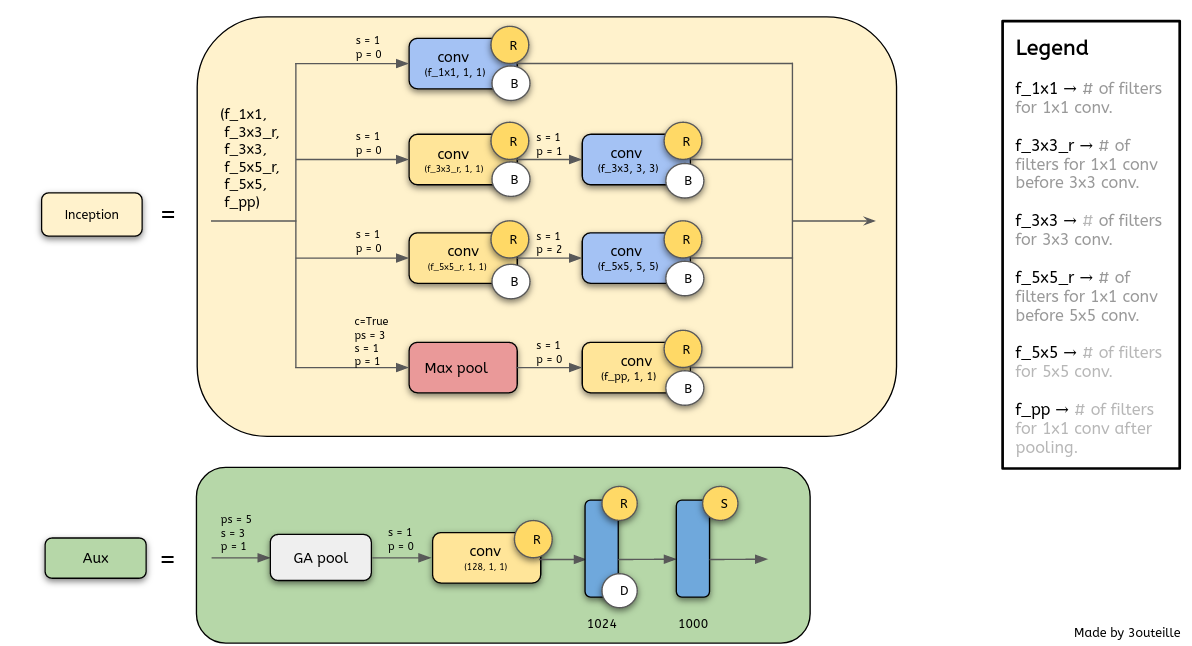
1) 먼저 Inception module을 단순화시킴
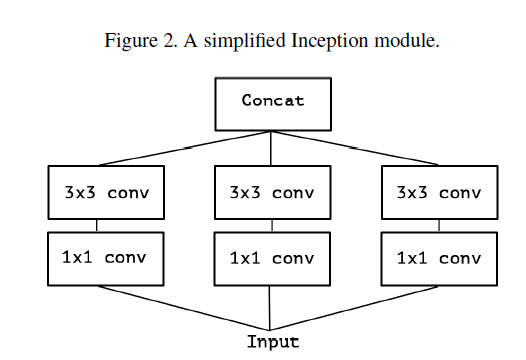
2) 해당 Inception module을 large 1x1 convolution으로 재구성하고 output channel이 겹치지 않는 부분에 대해서 spatial convolution(3x3)이 오는 형태로 재구성함
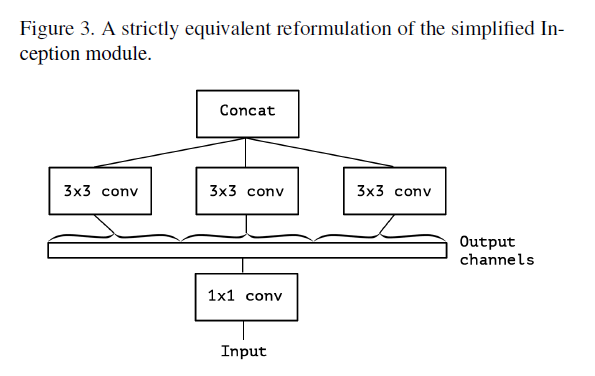
Figure2와 Figure3는 서로 동일한 형태
(branch 1은 input에 대해 1x1 conv를 수행하고, output channels에 대해서 3x3 convolution을 수행하는데, branch 2, branch 3 역시 동일한 과정을 거치고, 마지막으로 각 결과를 concat)
3) 기존에는 3,4개의 branch로 나눠서 각 branch에 대해서 spatial convolution 연산을 수행한 후 concat하였다면, Xception은 3,4개로 나누는 것이 아니라 각 output channel에 대해서 spatial convolution을 수행함
tensorflow/Inception_v3

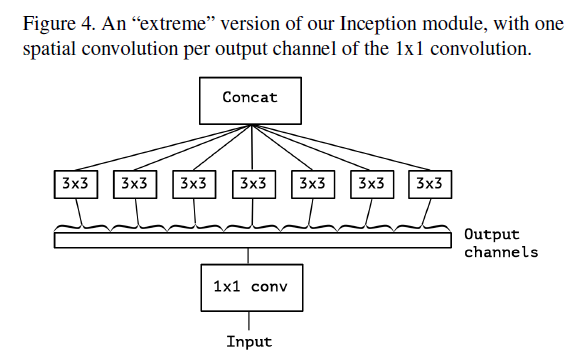
그렇게 함으로써 cross-channel correlation과 spatial correlation을 완전하게 분리시켜서 학습할 수 있다고 생각함(hypothesis)
Xception with Depthwise Separable Convolution
- Xception이 학습하는 과정
1) 1x1 conv를 통해 cross-channel correlation 학습
2) 각 output channel에 대해서 spatial correlation 학습
위와 같은 학습을 위해 Depthwise Separable Convolution을 사용함
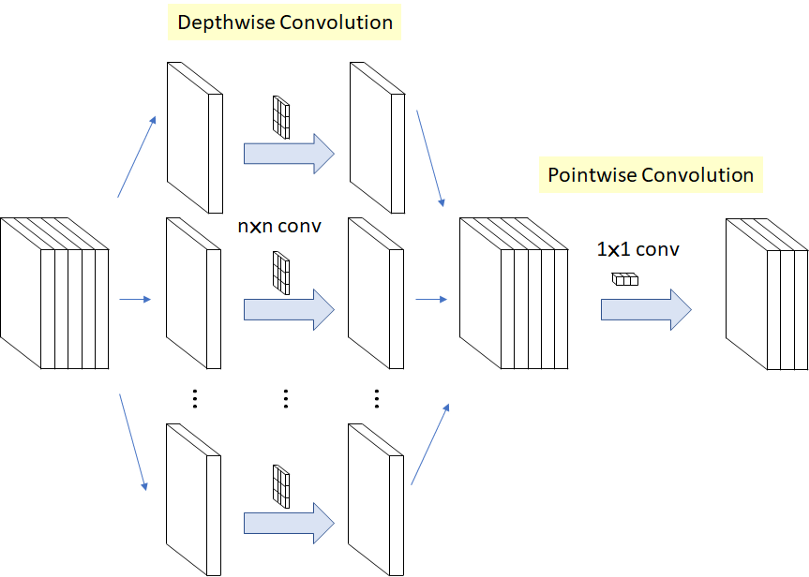
Depthwise Separable Convolution
depthwise convolution을 수행한 후에 pointwise convolution을 수행함으로써 일반적인 convolution 보다 연산량을 줄임
-
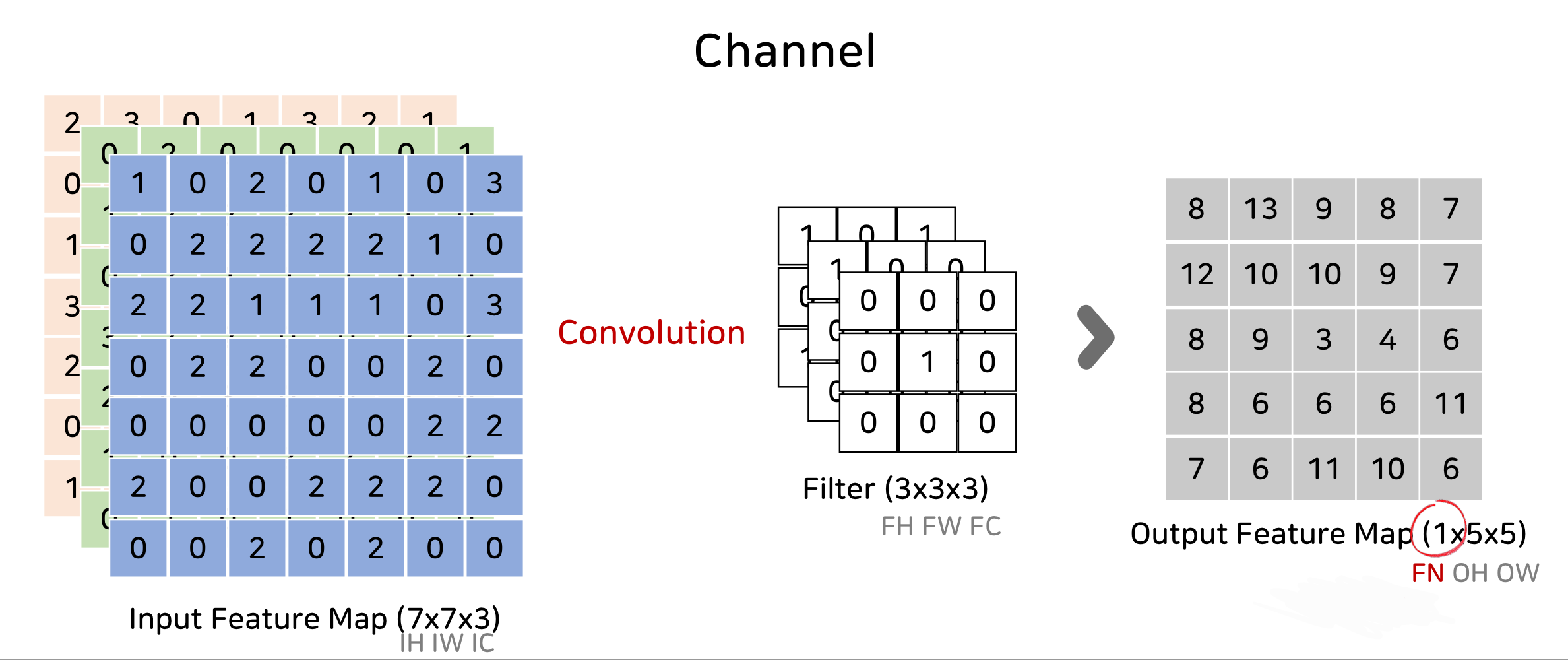
depthwise convolution: 각 channel마다의 spatial feature를 추출하기 위한 방식. 일반적인 convolution은 한 개의 filter가 channel 전체에 convolution을 연산하는 반면에, depthwise convolution은 한 개의 filter가 한 개의 channel만 연산을 함
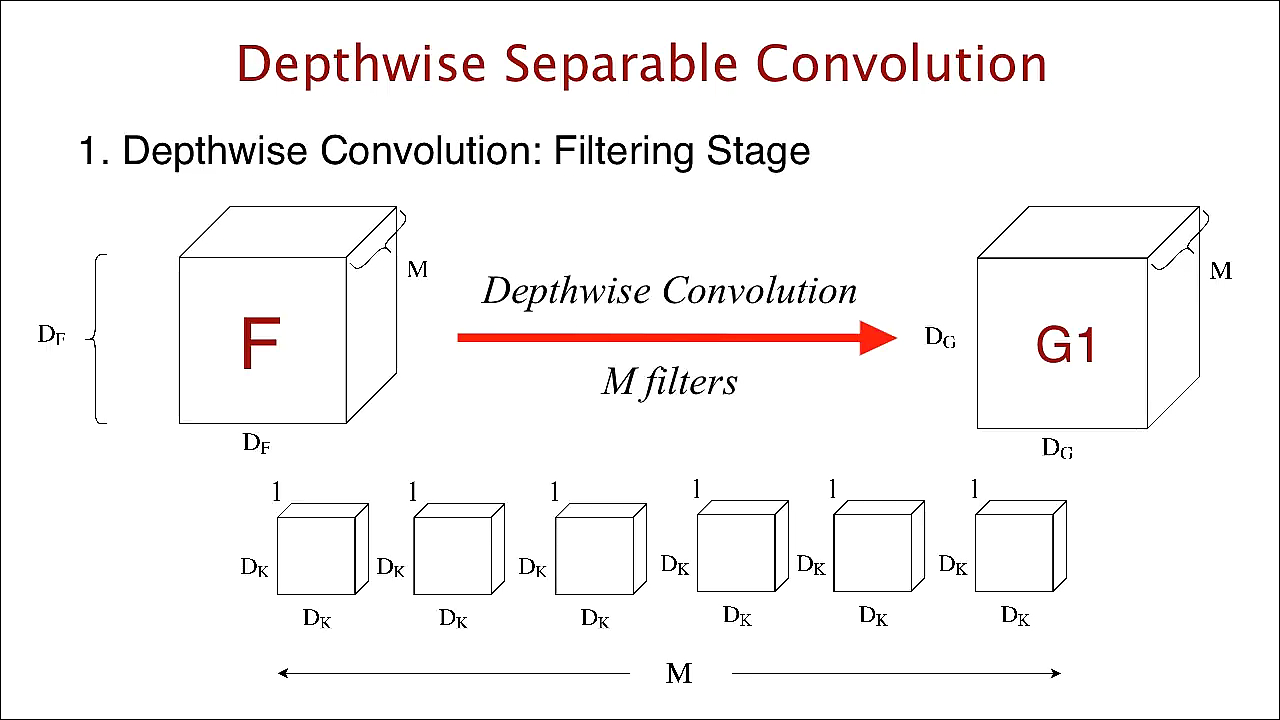
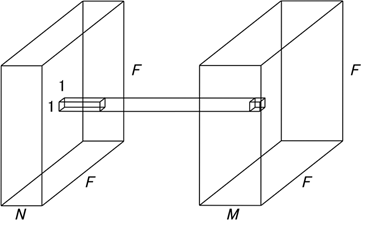
M개의 channel이 있으면 첫번째 channel인 ()에 대해서 () filter가 존재. 최종적으로는 총 M개의 filter가 존재하게 됨. output volume = () -
pointwise convolution: 1x1 convolution
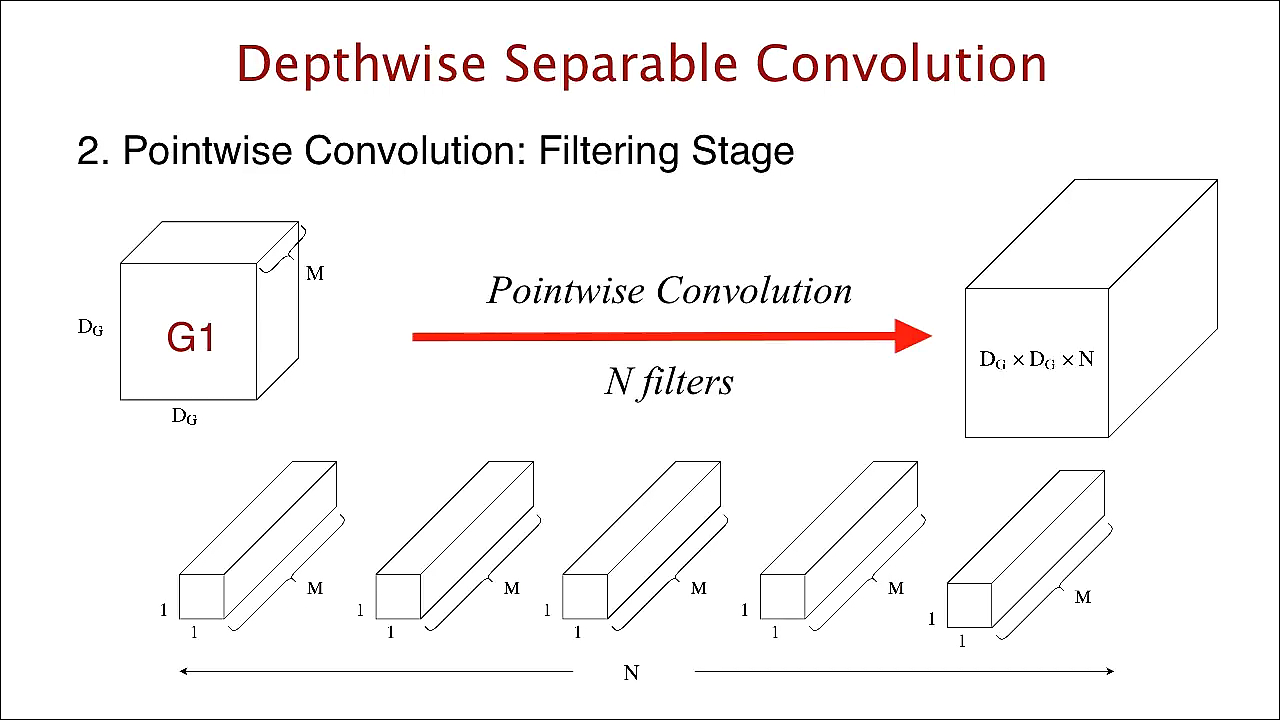
depthwise convolution의 output인 ()을 input으로 받아서 N개의 (1,1,M) filter를 사용하여 convolution 연산. output volume = ()
얼마만큼 연산량을 줄였는가?
depthwise separable convolution의 연산량 계산하기 전에, 먼저 일반적인 convolution 연산량을 살펴보도록 하겠습니다.
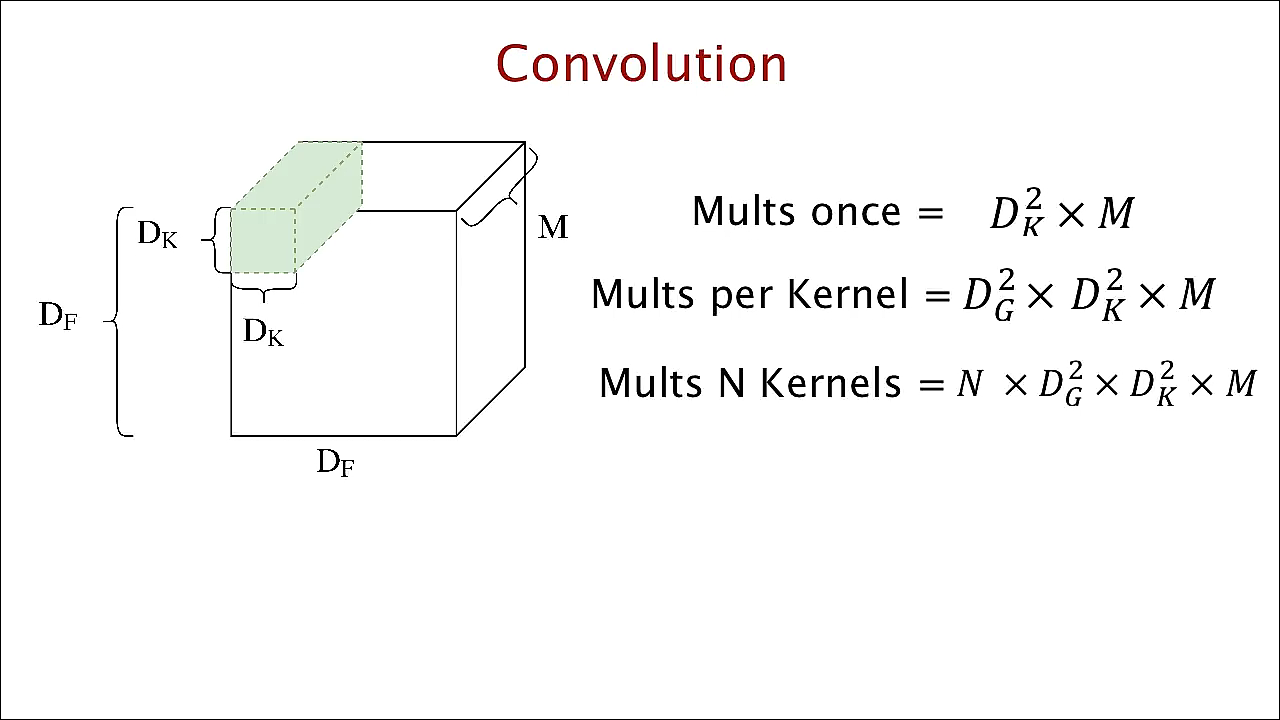
한 개의 filter가 input의 한 위치에서 곱연산을 수행할 때의 연산량은
이동할 수 있는 위치의 경우의 수는 output의 height width인
하나의 filter가 하나의 input을 처리하는 데 필요한 연산량은
N개의 filter가 input을 처리하는 데 필요한 연산량은
이제 depthwise separable convolution의 연산량을 살펴보도록 하겠습니다.
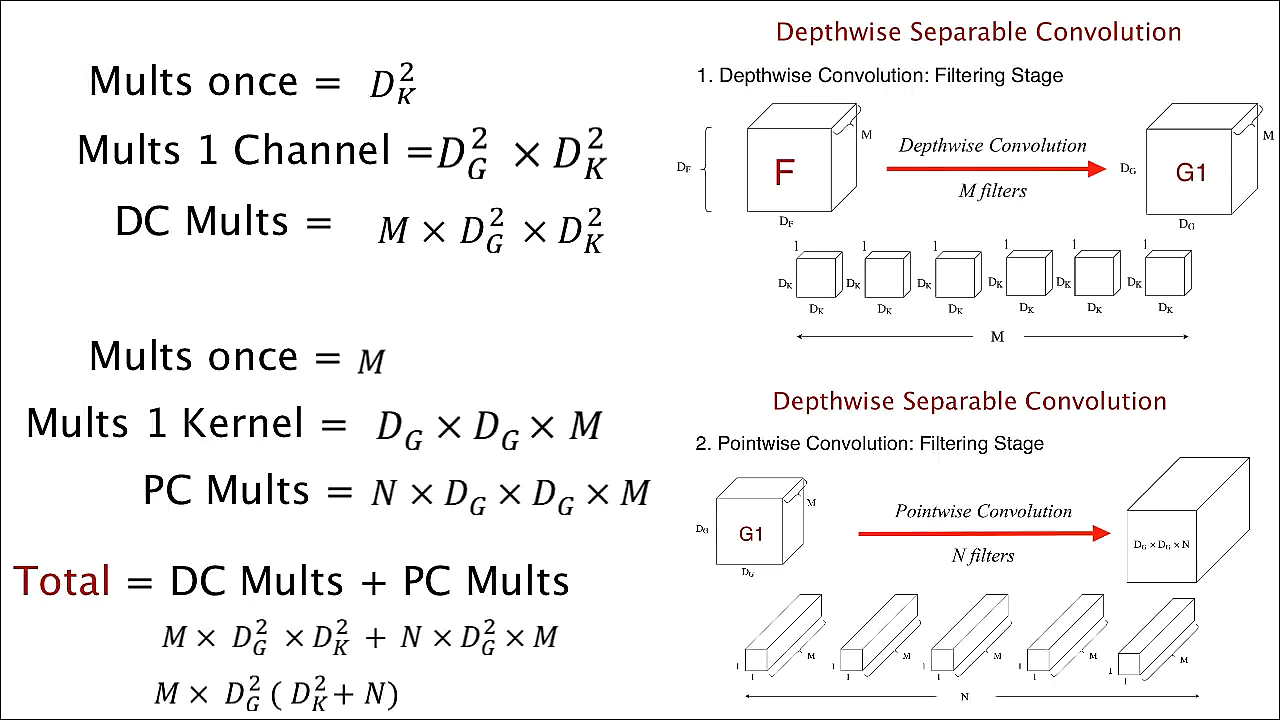
전체 연산량 = depthwise convolution 연산량 + pointwise convolution 연산량
1) depthwise convolution 연산량
한 개의 filter가 input의 한 위치에서 곱연산을 수행할 때의 연산량은
이동할 수 있는 위치의 경우의 수는 output의 height width인
하나의 filter가 하나의 channel 전체를 처리하는 데 필요한 연산량은
channel이 총 M개가 있으므로 filter가 input을 처리하는 데 필요한 총 연산량은
2) pointwise convolution 연산량
한 개의 filter가 input의 한 위치에서 곱연산을 수행할 때의 연산량은
이동할 수 있는 위치의 경우의 수는 output의 height width인
하나의 filter가 하나의 input을 처리하는 데 필요한 연산량은
N개의 filter가 input을 처리하는 데 필요한 연산량은
일반적인 convolution 연산량과 비교를 해보면, output channel의 수가 1024이고 filter의 size가 3x3일 때, 약 만큼 연산량이 줄어들었음

- Xception with Depthwise Separable Convolution
다시 기억을 되살려보면 Xception은 1x1 conv를 통해 cross-channel correlation 학습을 하고 각 output channel에 대해서 spatial convolution을 수행함
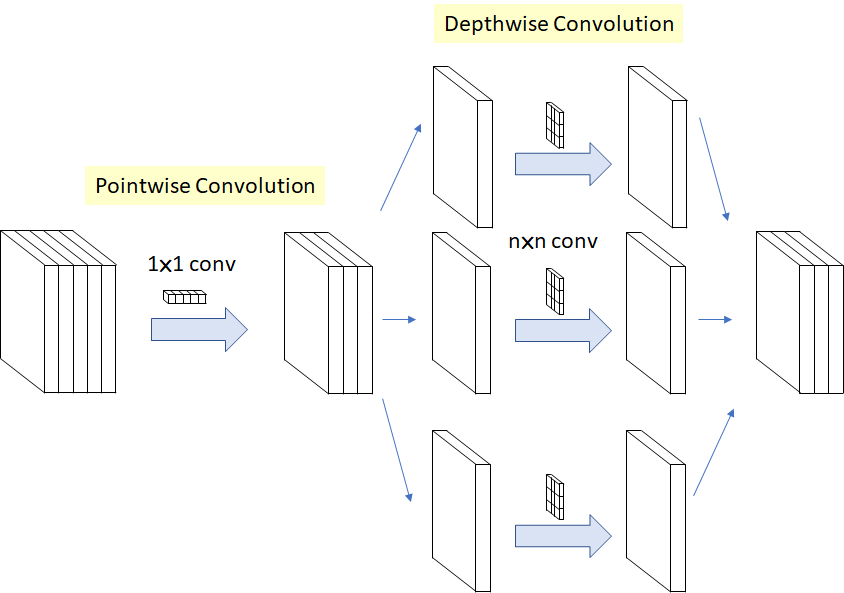
그러나, depthwise separable convolution(depthwise->pointwise) 순서대로 convolution을 수행해도 상관이 없다고 함
We argue that the first difference is unimportant, in particular because these operations are meant to be used in a stacked setting
그리고 Xception 코드를 보면, tensorflow에서 제공하는 depthwise separable convolution을 그대로 사용하는 것을 볼 수 있음
keras-team/xception

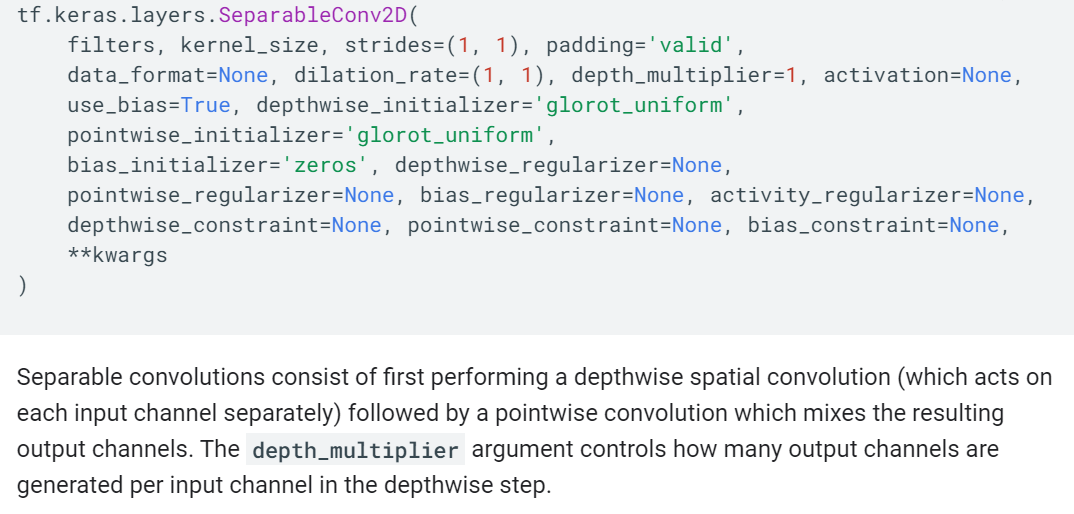
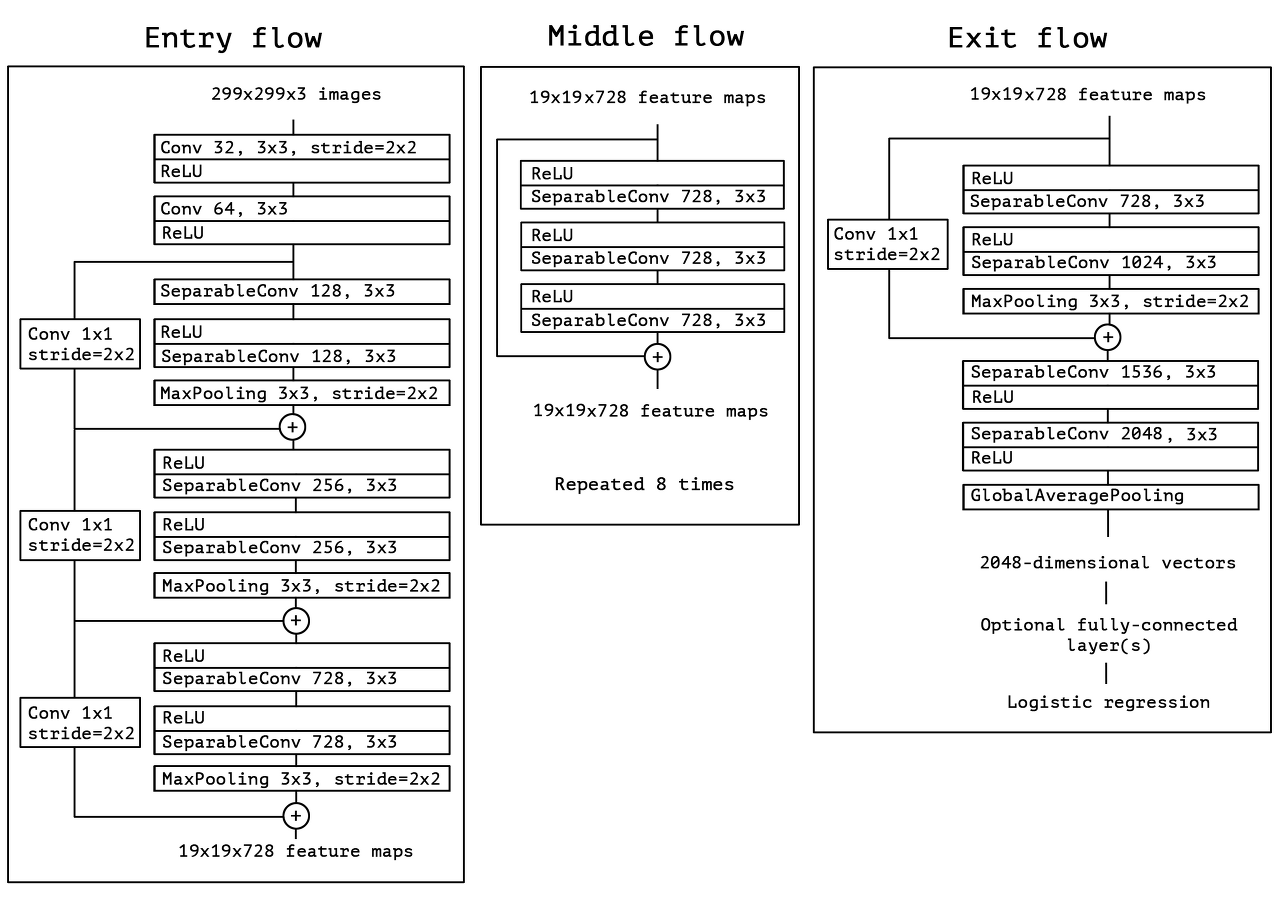
Xception 구조
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning(Feb 2016) : Inception에 ResNet을 결합한 모델을 제시했었음
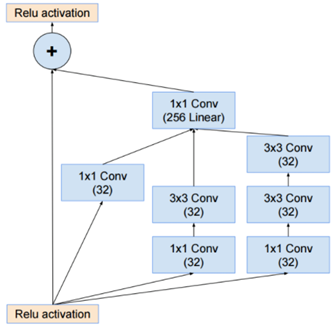
Xception 구조는 residual connection이 있는 depthwise separble convolution의 linear stack으로 볼 수 있음
Result
- ImageNet dataset(1000-class single-label classification)
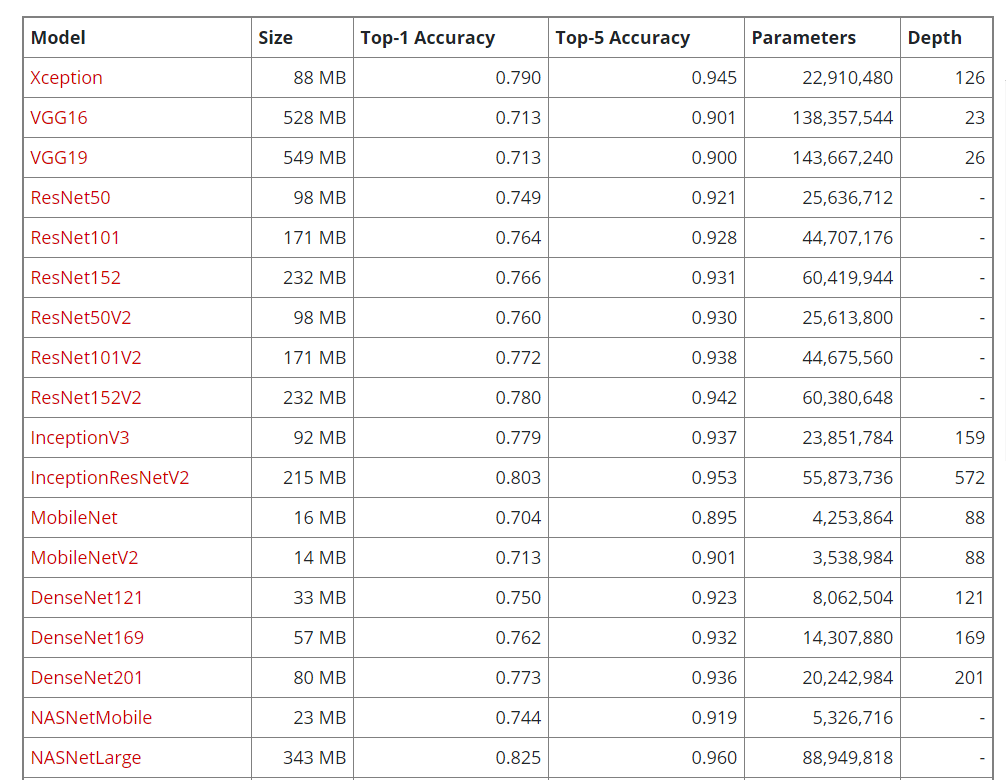
Inception-v3와 동일한 optimization configuration 사용했고, Xception에 최적화된 hyperparameter를 조정하려는 시도를 하지 않았음. 즉 inception-v3에 맞춰진 최적값이었는데 비슷한 수의 파라미터를 가지면서 정확도를 향상시킴. 저자는 모델의 parameter를 효율적으로 사용했다고 말함

- JFT dataset(17000-class single-label classification, internal Google dataset)
JFT에 대해 학습된 모델의 성능 평가는 보조 dataset인 FastEval14k 사용


-
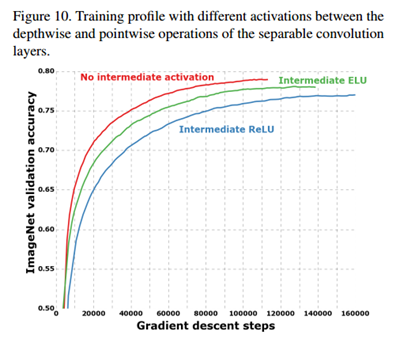
non-linearity
기존의 inception은 1x1 conv 이후와 spatial conv 이후 모두 non-linearity로 ReLU를 수행하는데, Xception의 경우 activiation을 사용하지 않는 것이 더 성능이 좋았음저자는 이에 대해서 spatial convolution이 적용되는 intermediate feature space의 depth가 non-linearity의 실용성에 매우 중요하게 작용된다고 말함
즉, Inception module에 있는 deep feature space(여러 개의 channel)의 경우에는 non-linearity가 도움이 되지만, shallow feature space(1-channel)의 경우에는 오히려 정보 손실로 인해 해로울 수가 있다고 함
Inception-v1
Xception 활용
DeepLab V3+ Encoder로 Xception 제안
-
DeepLab 시리즈는 semantic segmentation 알고리즘으로, atrous convolution 활용하는 것을 제안한 모델
DeepLab V1
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. ICLR 2015.
DeepLab V2
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. TPAMI 2017.
DeepLab V3
Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017.
DeepLab V3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018. -
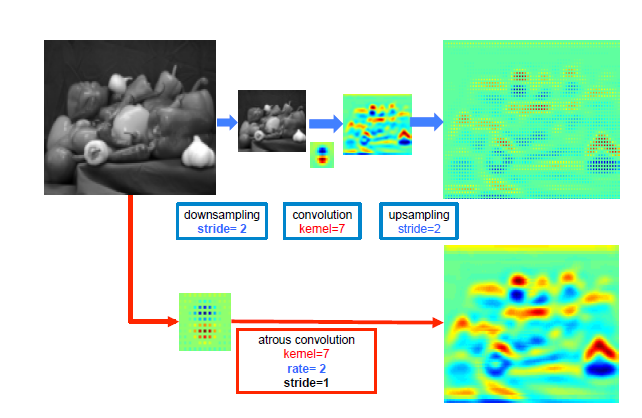
atrous convolution: filter 내부에 빈 공간(trous=hole)을 두고 convolution 수행
빈 공간에 대해서는 0으로 채워져서 계산됨
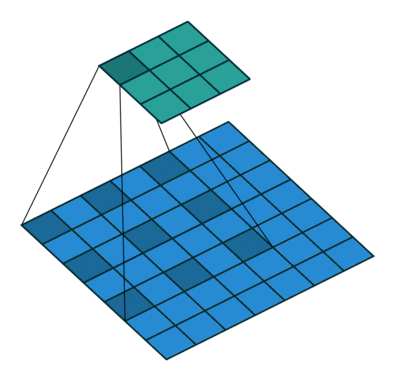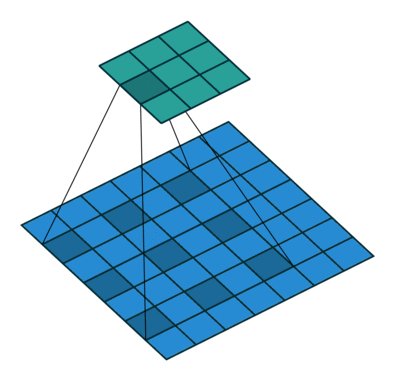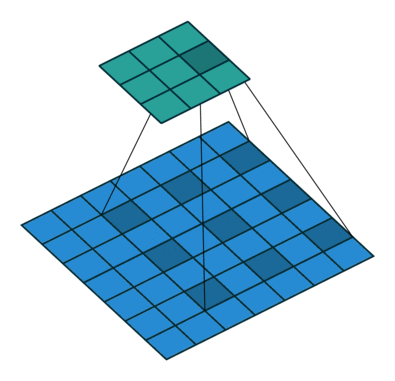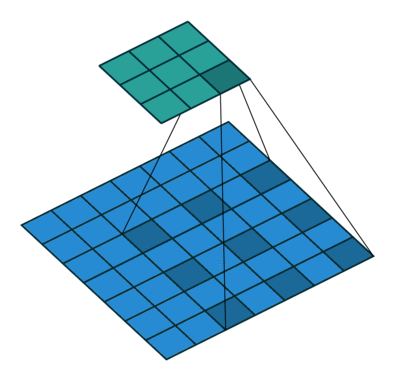
filter 사이의 간격을 dilation rate이라고 함 (예시 그림: dilation rate=2)
이를 통해 일반적인 convolution과 동일한 computational cost를 가지고도 더 넓은 receptive field를 가질 수 있음
DeepLab은 pooling layer 대신에 atrous convolution을 이용하여 receptive field를 확장시켜 조밀한 예측을 수행하고자 함
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- DeepLab V3+: Depthwise Separable Convolution과 Atrous Convolution을 결합한 Atrous Separable Convolution의 활용 제안
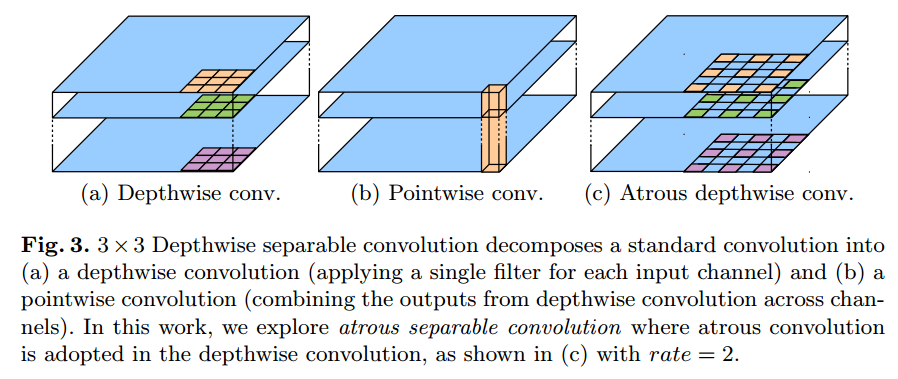
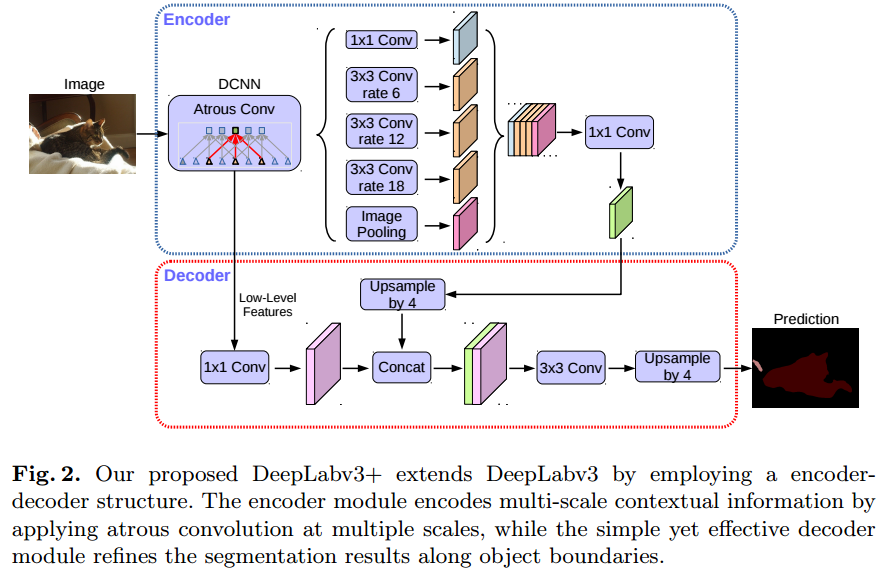
Spatial Pyramid Pooling 적용: multi-scale에 잘 대응하기 위한 방법으로 여러개의 확장 비율을 사용해서 atrous convolution을 수행한 후 concat 시킴
DeepLab V2, DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
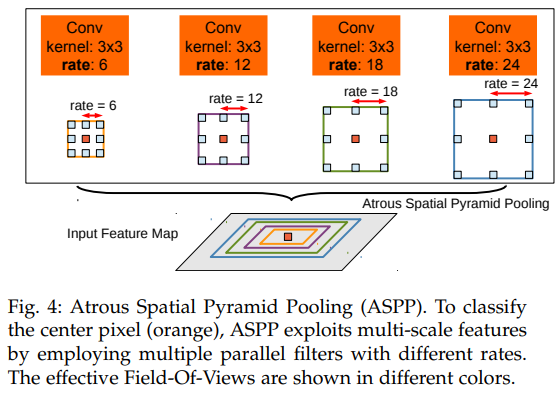
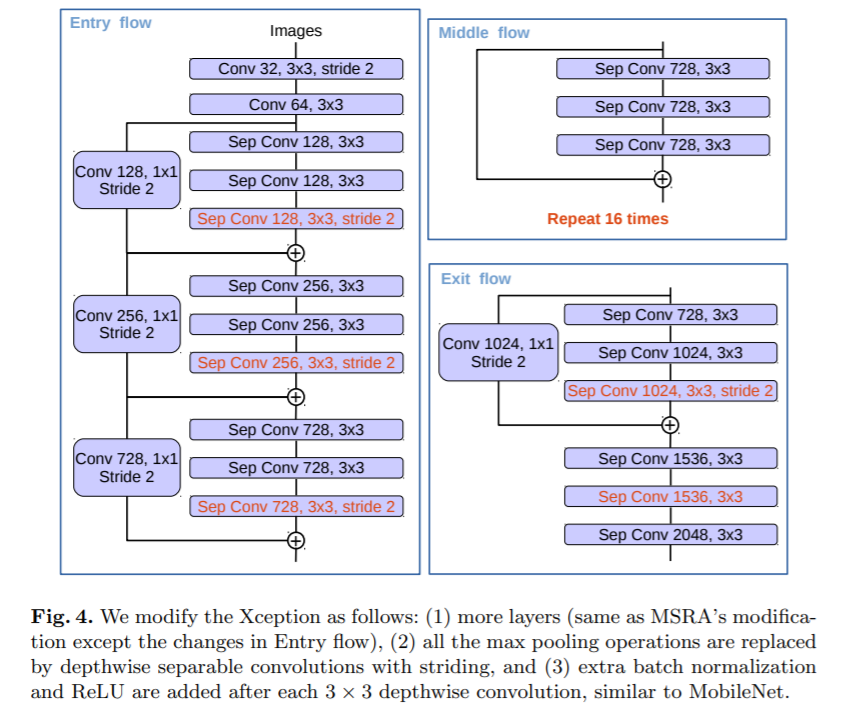
Encoder의 backbone으로 MSRA의 Xception 모델을 변형하여 사용
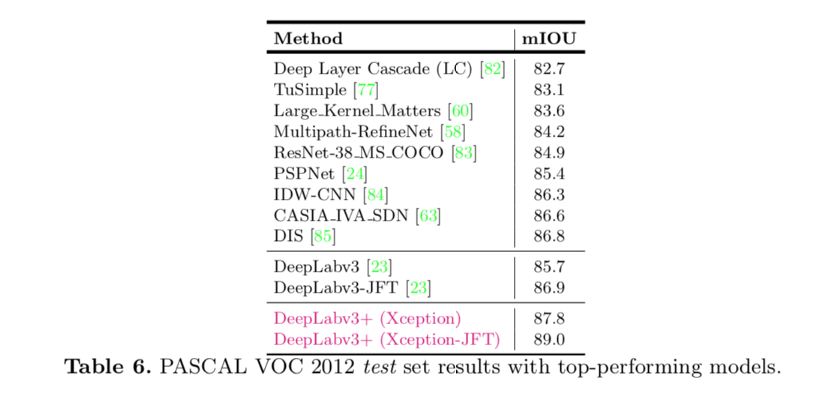
JFT dataset-pretrained Xception이 가장 좋은 성능을 보임

Reference
- Xception: Deep Learning with Depthwise Separable Convolutions
- Encoder-Decoder with Atrous Separable
Convolution for Semantic Image Segmentation - https://github.com/tensorflow/tensorflow/blob/v2.4.1/tensorflow/python/keras/applications/inception_v3.py#L46-L360
- https://kkkkhd.tistory.com/80
- https://gaussian37.github.io/dl-concept-dwsconv/
- https://github.com/keras-team/keras-applications/blob/bc89834ed36935ab4a4994446e34ff81c0d8e1b7/keras_applications/xception.py#L40
- https://keras.io/api/applications/
- https://hackmd.io/@bouteille/Bk-61Fo8U
- https://towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
- https://kuklife.tistory.com/121
- https://medium.com/hyunjulie/2%ED%8E%B8-%EB%91%90-%EC%A0%91%EA%B7%BC%EC%9D%98-%EC%A0%91%EC%A0%90-deeplab-v3-ef7316d4209d
