겨울방학동안 열심히 공부하여 우매함의 언덕에 오르는 순간 다시 챌린지에 부딪치고 겸손의 협곡으로 갈 수 있었던 24년 1학기 종합설계 프로젝트에 대한 회고를 써보고자 한다.
프로젝트 준비
종합설계는 우리학교 sw ai 전공의 졸업 프로젝트 수업이다. 모든 전공생들이 2학년이나 3학년때쯤 진입을 시작하는 이중전공생이기 때문에 이 프로젝트는 많은 학우들에게 두려움의 대상이 된다. (매년 1학기만 되면 에타 융소 게시판에 종설에서 할줄아는 게 없으면 어쩌냐고 묻는 사람들이 허다하게 올라온다.)
나역시 작년에 개발 공부를 시작했고, 많이 하지 않았던 사람으로서 종설을 이번에 듣기로 결심한 이후로 이를 위해 실력을 열심히 쌓아야겠다고 생각했다.
프로젝트 팀이 배치되면 웹개발을 할 줄 아는 사람이 보통 반도 안된다 해서, 백엔드 팀원은 최악의 경우 나만 있을 것이며, 웬만하면 장고나 스프링으로 개발을 할것이라 생각했다. 그래서 장고 책을 사서 처음부터 기본기를 다지며 공부하고, 돔토리 프로젝트를 시작하여 개발도 쫌쫌따리 진행했다.
그렇게 부족하지만 만반의 준비를 하고 개강을 맞이했고, 개강 2주차쯤에 팀이 짜였다.
팀구성원은 예상외였다. 팀원 6명 중 PM에 자원한 팀원이 1명, 프론트는 많이는 아니지만 할줄 안다고 한 분이 1명이었다. 그리고 백엔드에 나말고도 한 명이 더 있었는데, 개발 경험도 아주 많고 실력이 매우 뛰어난 분이었다. 작년 멋사에서 우연히 알게 된 선배라, 백엔드에 아주 실력자가 있다는 점이 안심이 되면서도 내가 역할을 잘 해낼수 있을지 지레 걱정스러웠다.
🪝 프로젝트 기획 - hook
pm님의 리드 하에 각자 프로젝트 아이디어를 공유했다. 감사하게도 내 아이디어가 뽑혔다.
 나는 나에게 카톡하기 기능을 매우 잘 쓰는 사람이다. 메모 작성과 파일 업로드 다운로드가 매우 쉽고, 디바이스간 호환성과 접근성이 매우 높기 때문이다. 시중에 많은 메모앱이 있지만, 긴 메모 대신 금세 떠오르는 아이디어를 빠르게 적어두거나, 나중에 참고할 url 등을 기입하기엔 이만한 게 없었따.
나는 나에게 카톡하기 기능을 매우 잘 쓰는 사람이다. 메모 작성과 파일 업로드 다운로드가 매우 쉽고, 디바이스간 호환성과 접근성이 매우 높기 때문이다. 시중에 많은 메모앱이 있지만, 긴 메모 대신 금세 떠오르는 아이디어를 빠르게 적어두거나, 나중에 참고할 url 등을 기입하기엔 이만한 게 없었따.
매우 간단한 게 장점인만큼 아쉬운 점 역시 "너무 간단하다"는 점에서 기인한다.
1. 메모 분류 기능이 없어서 원하는 메모를 찾기가 어렵다.
2. url을 올려놓는 경우 해당 url에 직접 접속해봐야 내용을 알 수 있다.
그래서 이러한 점을 해결하면서도 간편하고 최소한의 필요한 기능만 제공하는 메모앱을 생각했다.
일반적인 메모앱이 아닌 'url 수집기' 라는 이름으로, url을 저장할때만 사용할 수 있다. 대신 다른 메모앱이나 나에게 카톡하기 기능과 비교해 다음과 같은 편의성을 제공하도록 기획하였다.
- url을 저장하는 유저플로우가 단순하다 (웹브라우저에서 공유버튼을 통해 바로 저장이 가능하다)
- url을 저장하면 해당 url의 내용을 읽어들여 url의 내용의 카테고리를 분류하는 태그를 자동으로 달아준다. 태그는 url의 분류 폴더로도 사용될 수 있다.
🪝 개발
내가 맡은 파트는 크게 태그 자동생성 기능과 카카오톡 로그인 기능이었다. 그중에서 태그 자동생성 기능에 공을 많이 들였기 때문에 이부분에 대해 회고해보고자 한다.
1. 설계
url을 저장하는 경로는 2가지가 있다. 첫번째는 앱 내부에서 추가하는 것, 두번째는 외부 브라우저에서 공유버튼을 통해 저장하는 것이다. 이중 태그가 자동 생성되는 경우는 두번째 방법을 사용한 경우이다. 사용자는 url을 저장할때 제목과 부가설명, 사용자지정태그를 추가할 수 있고, 클라이언트는 이를 받아 서버에 title, description, url, tags를 전달한다.
이를 받아 서버에서 자동태그를 생성해 저장하는 알고리즘을 몇가지 짜보았다.
1. url의 html페이지를 파싱하여 meta태그값 추출, 추출된 태그값들을 자연어처리해 출현횟수 순으로 키워드 선정
-> 자연어처리를 사용하여 분석하는 것은 다소 뒤떨어진(?) 방식이라고 생각했다... 또한 페이지마다 태그의 종류가 다르기 때문에 이를 일일이 추출하는 것은 다소 번거로운 일이었다.
2. html의 바디값을 분석해 카테고리 키워드를 추출해주는 인공지능api 사용
-> 따라서 url을 요청하면 카테고리 키워드를 응답으로 주는 외부api를 사용하는 방식을 채택했다.
2. 외부 api를 사용하는 험난한 과정
당시엔 외부 api에 요청을 보내는 것도 처음이었기 때문에 연결만으로도 상당히 험난했다.
여러 api를 비교해보고 curl로 요청을 보내본 결과, ibm watson natural language understanding api의 categorize모델을 사용하는 것이 가장 간단하고 비용효율적이었다.
당시에는 클라우드 컴퓨팅에 대한 개념이 부족해서, ibm cloud의 모델을 빌려오는 과정도 다소 어려웠다. api key를 받아오고 이를 config로 숨기는 것도 어려웠고 모델 버전이 안맞아서 받아올때도 오류가 많이 생겼었다 ^_^;
데이터를 받아온다음, 데이터를 후처리했다. 해외 api이기 때문에 영어 데이터였고, A and B 등의 형식으로 왔다. 이러한 불용어를 처리하여 카테고리를 단어 단위로 추출하고, 여러개의 카테고리값을 받아오면서 중복단어가 있을 수 있으므로 중복 검사도 하여 후처리 로직을 짰다.
이후 받아온 값들이 생각보다 굉장히 정확도가 낮음을 느꼈다. 따라서 받아온 카테고리를 다 반환하지 않고, 중복 카테고리가 있을 시 이를 반환했다. 중복 카테고리가 없다면 모델에서 함께 보내주는 카테고리별 성능(score)값이 높은 것을 반환했다.
3. 태그값 보정과 코드 리팩토링
중간발표때까지 개발을 하고, 여러 해결해야 할 이슈들을 발견하여 해결했다.
- 앞서 추출한 태그가 영문이라서, 사용자가 지정한 태그가 한글일 경우 일관성이 보장되지 않는다. 따라서 google translate api를 사용하여 영문태그를 한글태그로 번역했다.
- 번역한 한글태그가 항상 명사형으로 번역되지 않는다는 걸 발견했다. -> 이를 해결하기 위해 nlp 라이브러리를 써서 한글태그를 명사형으로 변환했다.
- 이 과정에서 비동기 처리로 인해 메서드가 의도된 순서로 처리되지 않아, 반환하는 최종태그 리스트에 태그값이 제대로 담기지 않는 문제가 발생했다. 이는 자바스크립트 메서드의 특성으로, async-await를 도입하여 코드를 리팩토링했다.
- 하나의 service안에 태그 생성 기능이 모두 들어가다보니 코드가 많이 복잡해져, 기능별로 메서드를 분리해서 리팩토링했다.
그렇게 해서 다음과 같은 코드를 최종적으로 작성했다.
import { CreateHookDTO } from '../hook/hook.dto';
import _ from 'lodash';
const NaturalLanguageUnderstandingV1 = require('ibm-watson/natural-language-understanding/v1');
const { IamAuthenticator } = require('ibm-watson/auth');
let mecab = require('mecab-ya');
// google translate api
const google_api = process.env.GOOGLE_TRANSLATE_KEY;
const googleTranslate = require('google-translate')(google_api);
/**
* dto 넘겨주면 자동 태그 생성해서 string[] 형태로 반환
*/
export const getAutoTagHookService = _.memoize(() => {
return {
async createAutoTag(payload: CreateHookDTO) {
// 태그 자동 생성
const naturalLanguageUnderstanding = new NaturalLanguageUnderstandingV1({
version: '2019-07-12',
authenticator: new IamAuthenticator({
apikey: process.env.IBM_CLOUD_API_KEY,
}),
serviceUrl: process.env.IBM_CLOUD_INSTANCE_URL,
});
const analyzeParams = {
'url': payload.url,
'features': {
'categories': {
'limit': 3
}
}
};
try {
const analysisResults = await naturalLanguageUnderstanding.analyze(analyzeParams);
const userTags = payload.tags;
const autoTagsEN = this.oraganizeAutoTag(analysisResults);
const autoTags = await this.translateToKr(autoTagsEN, userTags);
return autoTags;
} catch (err) {
console.error(err);
}
},
oraganizeAutoTag(analysisResults: any): string[] {
const labels: string[] = [];
const final_labels: string[] = [];
for (const category of analysisResults.result.categories) {
const label = category.label;
// 자동생성된 라벨들 처리, 2번 이상 반복된 단어 포함시키기
let word = "";
for (const c of label) {
if (label.indexOf(c) === label.length - 1 || c == " " || c.charCodeAt(0) < 97 || c.charCodeAt(0) > 122) {
if (word === 'and') {
word = "";
continue;
} else if (word === "") {
continue;
} else if (labels.includes(word)) {
if (!final_labels.includes(word)) {
final_labels.push(word);
}
} else {
labels.push(word);
}
word = "";
} else {
word += c;
}
}
}
if (final_labels.length === 0) {
final_labels.push(labels[0]); // 2개 이상 겹치는 게 하나도 없으면 가장 score가 높은 label 저장
}
return final_labels; // 자동생성 + 사용자추가 태그 리스트 반환
},
async translateToKr(autoTags: string[], userTags: string[]): Promise<string[]> {
let responseTags: string[] = [];
for (const tag of autoTags) {
try {
const translatedText = await this.translateTag(tag);
const extractNounTags = await this.extractNouns(translatedText);
responseTags = responseTags.concat(extractNounTags);
} catch (err) {
console.error(err);
}
}
for (const tag of userTags) {
if (!responseTags.includes(tag)) {
responseTags.push(tag);
}
}
return responseTags;
},
translateTag(tag: string): Promise<string> {
return new Promise<string> ((resolve, reject) => {
googleTranslate.translate(tag, 'ko', (err: any, translation: any) => {
if (err) {
reject(err);
} else {
resolve(translation.translatedText);
}
});
})
},
extractNouns(text: string): Promise<string[]> {
return new Promise<string[]> ((resolve, reject) => {
mecab.nouns(text, function (err: any, result: string[]) {
if (err) {
reject(err);
} else {
resolve(result);
}
});
})
},
};
});
export type AutoTagHookService = ReturnType<typeof getAutoTagHookService>;참으로 길다.
4. 태그 성능 개선
그렇게 개발을 하다보니 마감일자가 점점 다가오는데, 개발에 집중한 나머지 여러 url로 테스트를 하지 못했고, 이로인해 자동 태그의 정확도가 생각보다 매우 낮다는 문제점을 발견했다.
태그를 생성하기 위해서 url을 넘기면 ibm api 내부에서 해당 url의 html 페이지의 본문을 추출한다. 그러나 여러 페이지를 테스트하면서 이 html 페이지의 형식 자체가 매우 다양하고, 많은 케이스에서 본문텍스트가 제대로 추출되지 않아서 잘못된 태그가 형성됨을 깨달았다.
따라서 최대한 다양한 형식의 url을 넣어 테스트를 해보았고, 이를 통해 태그가 부정확하게 생성되는 케이스를 정리했다.
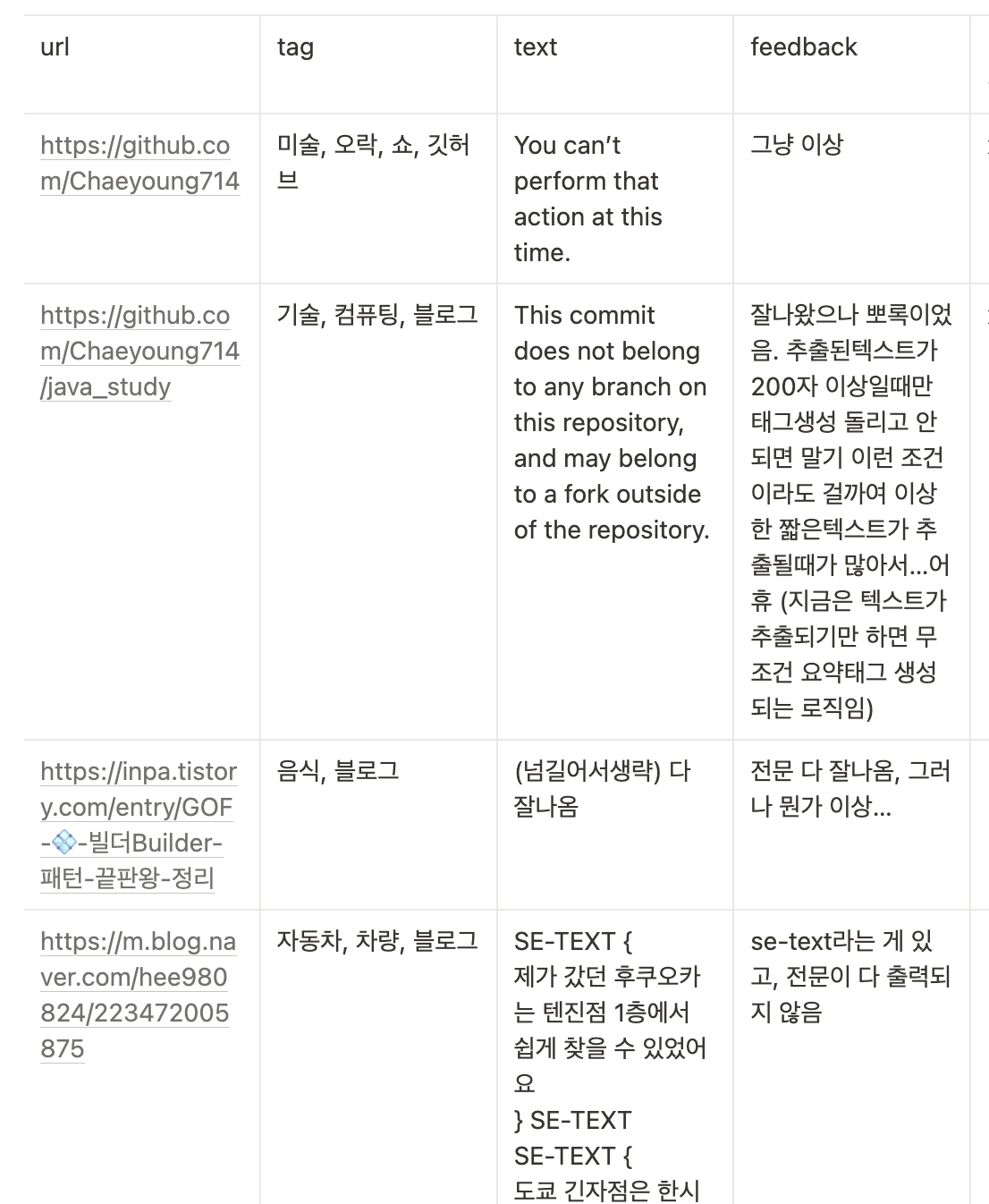
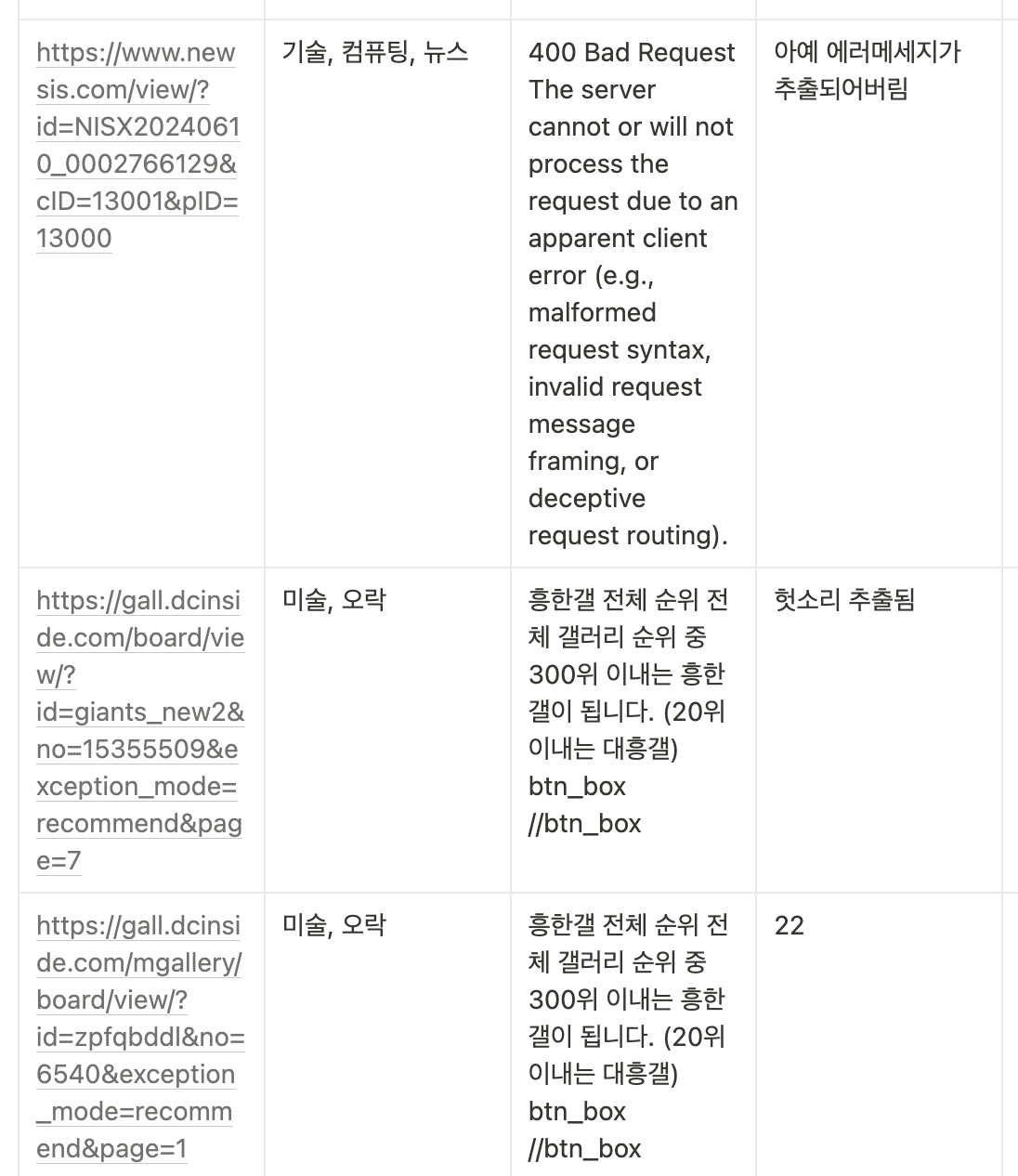
태그가 부정확하게 생성되는 케이스
- 텍스트 추출 이슈
1) 사이트에서 보안상의 이유로 텍스트 추출을 막는 경우 (ex. 해외사이트, 노션, 네이버블로그, 깃허브 등)
2) 너무 많은 일관되지 않은 텍스트(여러가지 글, 광고텍스트 등)가 있어서 페이지의 본문텍스트가 불명확한 경우 (ex. 네이버 뉴스 메인 사이트, 나무위키 사이트 등)
3) html페이지의 body태그 외의 태그가 너무 복잡해 본문텍스트가 오염된 경우 - 부정확한 요약 이슈 (api 성능 문제)
- 어색한 번역, 어색한 명사형 추출 이슈 (nlp라이브러리, translate api 성능 문제)
- 외국어 텍스트 요약 이슈 - 자동태그생성 api가 language: ko로 설정되어 있기에 외국어 텍스트의 분석은 약함
이를 해결하기 위해 html페이지의 본문을 추출하는 로직을 라이브러리를 따로 사용하여 분리하였다. 본문텍스트를 추출하는 라이브러리를 따로 쓴다면 이의 성능 역시 올라갈 수 있기 때문이다. 이를 위해 node-readability 라이브러리를 사용해 텍스트를 추출하고, ibm api에는 추출된 텍스트만 전달하여 카테고리값을 받아오는 방식으로 수정했다.
이를 통해 오염된 본문텍스트가 넘어가는 일은 많이 줄어들었고, 태그 자체의 정확도가 엄청나게 개선되지는 않았으나 아예 관련없는 불필요한 태그가 생성되는 일은 어느정도 개선되었다.
남은 문제는 라이브러리를 써서도 본문텍스트 추출이 되지 않는, 즉, html 페이지 자체에 본문텍스트가 제대로 없는 케이스이다. 이런 경우 보통 에러메세지나 다른 태그 등 짧고 무관련한 텍스트가 추출되었다. 일반적인 블로그의 평균 글자수와 뉴스 기사의 평균 글자수가 기본 1000자 이상임을 고려하여, 과하게 짧은 400자 이하의 텍스트가 추출되었다면 비정상적인 텍스트가 추출되었고, 정상적인 텍스트더라도 카테고리를 생성할만큼 충분한 텍스트가 제공되지 않는다고 판단하여 태그 생성을 하지 않도록 분기처리했다.
추가적인 성능 개선을 위해, 뉴스, 블로그 등 url의 메타데이터를 태그로 추가하는 로직을 추가했다. 이런 경우 url을 파싱하고, 미리 자주 사용하는 도메인과 그 도메인의 메타태그를 매핑한 더미데이터와 매칭되는 것이 있는지 비교해서 있다면 메타태그를 추가하도록 했다. 가령 https://velog.io/...의 url을 넣으면, '블로그'라는 태그가 추가되는 것이다.
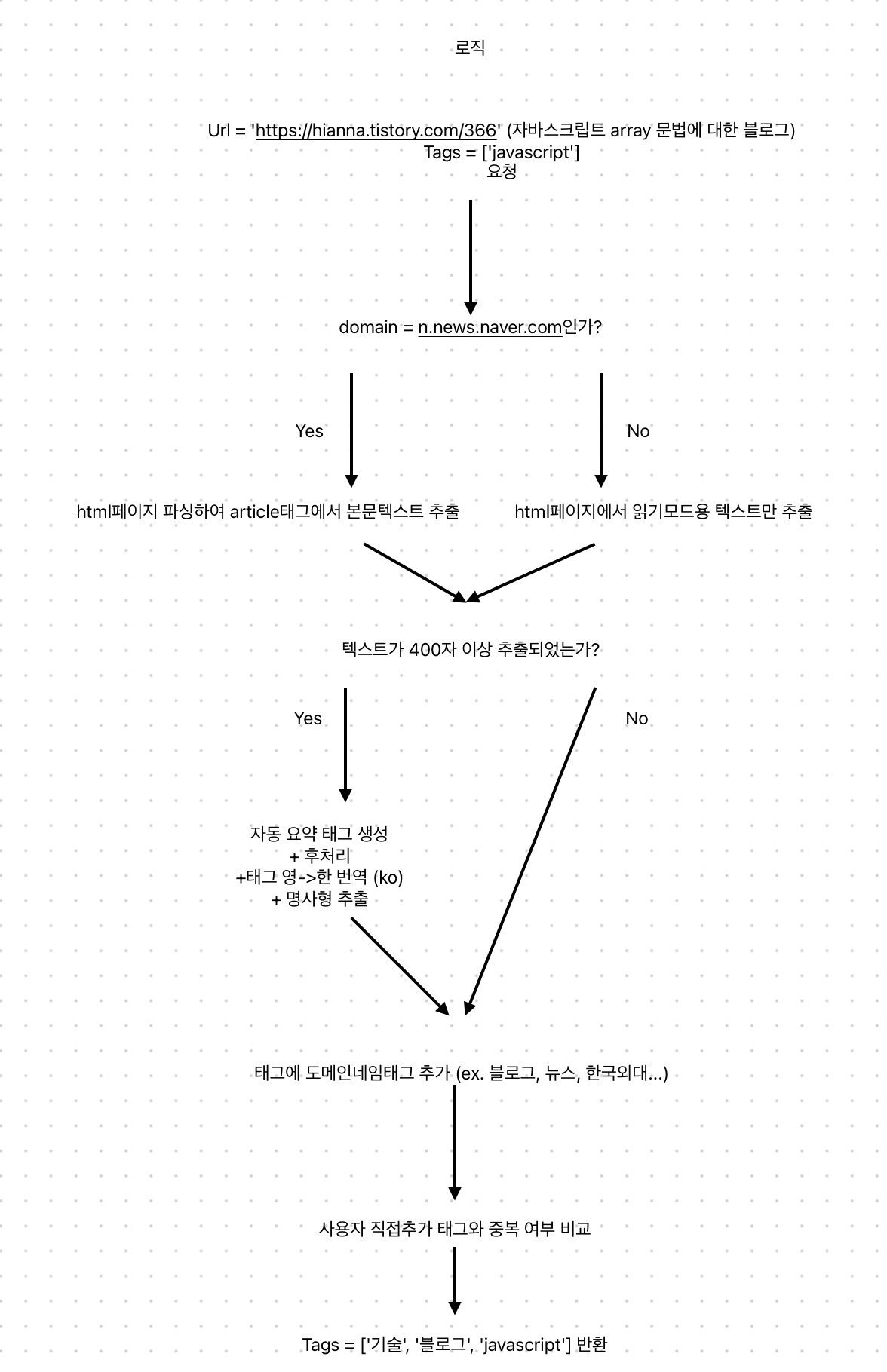
최종적인 태그 생성 로직은 다음과 같다.
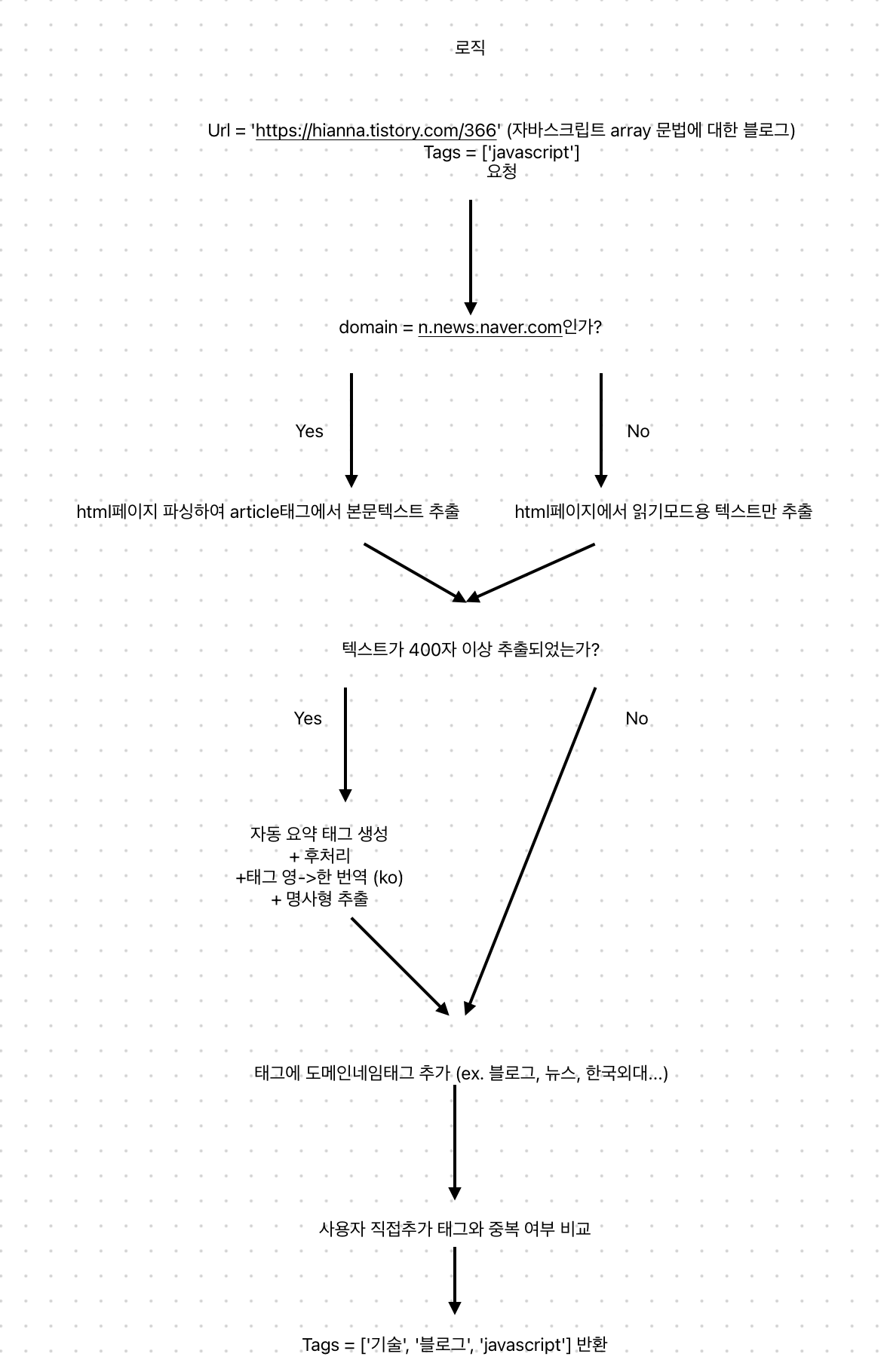

import { CreateHookDTO } from '../hook/hook.dto';
import _ from 'lodash';
import NaturalLanguageUnderstandingV1 from 'ibm-watson/natural-language-understanding/v1';
import { IamAuthenticator } from 'ibm-watson/auth';
const read = require('node-readability');
const urlParse = require('url');
const axios = require('axios');
const cheerio = require('cheerio');
/**
* dto 넘겨주면 자동 태그 생성해서 string[] 형태로 반환합니다.
*/
export const getAutoTagHookService = _.memoize(() => {
// eslint-disable-next-line @typescript-eslint/no-var-requires
const mecab = require('mecab-ya');
// google translate api
const google_key = process.env.GOOGLE_TRANSLATE_KEY;
// eslint-disable-next-line @typescript-eslint/no-var-requires
const googleTranslate = require('google-translate')(google_key);
const naturalLanguageUnderstanding = new NaturalLanguageUnderstandingV1({
version: '2019-07-12',
authenticator: new IamAuthenticator({
apikey: process.env.IBM_CLOUD_API_KEY!,
}),
serviceUrl: process.env.IBM_CLOUD_INSTANCE_URL,
});
return {
async createAutoTag(payload: CreateHookDTO) {
//최상위 도메인이름 추출
const parsedUrl = urlParse.parse(payload.url);
const domain = parsedUrl.hostname; // 'www.example.com'
let url = payload.url;
let htmlText: string;
let autoTagsFinal: string[];
if (domain === "n.news.naver.com") { //네이버뉴스 기사 따로 처리
let index = url.indexOf('article/') + 7;
let modifiedUrl = url.substring(0, index) + '/print' + url.substring(index);
url = modifiedUrl;
htmlText = await this.extractNewsText(url);
} else {
htmlText = await this.extractPlainText(url);
}
if (!htmlText) { //htmlText 추출 실패 시 -> 바로 도메인태그 추가하는 로직으로 이동
autoTagsFinal = await this.createDomainTag([], domain);
}
else { //htmlText 추출 성공 시 -> 자동태그생성 -> 한글번역+명사형추출 -> 도메인태그 추가
const autoTagsEN = await this.createTags(htmlText);
const autoTagsKR = await this.translateToKr(autoTagsEN);
autoTagsFinal = await this.createDomainTag(autoTagsKR, domain);
}
const userTags = payload.tags;
const responseTags = this.organizeResponseTags(autoTagsFinal, userTags);
return responseTags;
},
async extractNewsText(url: string): Promise<string> {
/**
* 네이버뉴스의 htmlText를 불러옵니다. ('article' 태그 추출, cheerio 라이브러리 사용)
*/
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
const articleText = $('article').text();
// console.log("newsText:", articleText); //debug
return articleText;
} catch (error) {
console.error(error);
throw error;
}
},
async extractPlainText(url: string): Promise<string> {
/**
* 네이버뉴스를 제외한 htmlText를 불러옵니다. (node-readability 라이브러리 사용)
*/
const plainText = await new Promise<string> ((resolve, reject) => {
read(url, function(err: any, article: any, meta: any) {
if (err) {
reject(err);
} else {
const text = article.textBody;
// console.log("plainText:", text); //debug
article.close();
resolve(text);
}
});
});
return plainText;
},
async createTags(text: string): Promise<string[]> {
/**
* htmlText를 바탕으로 자동태그를 생성합니다 (watson nlp api 사용)
*/
const analyzeParams = {
text: text,
features: {
categories: {
limit: 2,
},
},
};
try {
const analysisResults = await naturalLanguageUnderstanding.analyze(analyzeParams);
const organizedTags = this.organizeAutoTag(analysisResults);
return organizedTags;
} catch (err) {
console.error(err);
return [];
}
},
organizeAutoTag(analysisResults: any): string[] {
/**
* 태그의 정확도를 위해 후처리합니다.
*/
const labels: string[] = [];
const organizedLabels: string[] = [];
for (const category of analysisResults.result.categories) {
const label = category.label;
// 자동생성된 라벨들 중 불필요한 것 처리, 2번 이상 반복된 단어만 포함시키기
let word = '';
for (const c of label) {
if (
label.indexOf(c) === label.length - 1 ||
c == ' ' ||
c.charCodeAt(0) < 97 ||
c.charCodeAt(0) > 122
) {
if (word === 'and' || word === 'C') {
word = '';
continue;
} else if (word === '') {
continue;
} else if (labels.includes(word)) {
if (!organizedLabels.includes(word)) {
organizedLabels.push(word);
}
} else {
labels.push(word);
}
word = '';
} else {
word += c;
}
}
}
if (organizedLabels.length === 0) {
organizedLabels.push(labels[0]); // 2개 이상 겹치는 게 하나도 없으면 가장 score가 높은 label 저장
}
return organizedLabels;
},
async translateToKr(autoTags: string[]): Promise<string[]> {
/**
* 자동생성된 영문 태그들을 한글로 번역하고 명사형만 추출합니다.
*/
let finalTags: string[] = [];
for (const tag of autoTags) {
try {
const translatedTags = await this.translate(tag);
const nounTagsArray = await this.extractNouns(translatedTags);
const nounTags = nounTagsArray.join('');
finalTags.push(nounTags);
} catch (err) {
console.error(err);
}
}
return finalTags;
},
translate(tag: string): Promise<string> {
return new Promise<string>((resolve, reject) => {
googleTranslate.translate(tag, 'ko', (err: any, translation: any) => {
if (err) {
reject(err);
} else {
resolve(translation.translatedText);
}
});
});
},
extractNouns(text: string): Promise<string[]> {
return new Promise<string[]>((resolve, reject) => {
mecab.nouns(text, function (err: any, result: string[]) {
if (err) {
reject(err);
} else {
resolve(result);
}
});
});
},
async createDomainTag(
autoTags: string[],
domain: string,
): Promise<string[]> {
/**
* 특정 도메인의 경우 아래 리스트에 해당하는 태그를 추가합니다.
*/
const domainTagList: string[][] = [
['blog', 'tistory', 'velog', 'medium', '블로그'],
['news', 'chosun', 'mk', 'joongang', 'hankyung', 'khan', 'yonhapnewstv', 'hani', 'donga', 'kyeonggi', 'kmib', 'biz.sbs', 'fnnews', 'newsis', 'sisajournal', 'bizwatch', 'sedaily', 'imaeil', 'edaily', 'biz.chosun', 'biz.heraldcorp', 'koreaherald', 'm.sports', 'bbc', 'cnn', 'nytimes', 'guardian', 'reuters', '뉴스'],
['github', 'gitlab', 'bitbucket', '깃허브'],
['youtube', 'vimeo', 'dailymotion', '유튜브'],
['namu.wiki', 'wikipedia', 'baike', '위키'],
['chatgpt', 'gemini', 'bard', 'claude', '인공지능검색'],
['cafe', '카페'],
['comic', 'webtoons', '웹툰'],
['finance', 'bloomberg', 'marketwatch', '증권'],
['shopping', 'amazon', 'ebay', 'gmarket', '11st', 'coupang', 'wemakeprice', 'auction', 'interpark', '쇼핑'],
['novel', '웹소설'],
['dict', 'papago', '사전'],
['kyobobook', 'aladin', 'yes24', '도서'],
['postman', '포스트맨'],
['dbpia', 'schloar', 'jstor', 'scholar.google', '논문'],
['mail', 'outlook', '메일'],
['band', '밴드'],
['acmicpc', 'codetree', 'programmers', 'leetcode', 'codeforces', 'hackerrank', '코딩'],
['stackoverflow', 'nodejs', 'dev.to', 'hashnode', '프로그래밍'],
['inflearn', 'coursera', 'udemy', 'edx', 'fastcampus', 'goorm', '프로그래밍강의'],
['tech', 'techcrunch', 'wired', 'theverge', 'zdnet', '개발'],
['linkedin', '링크드인'],
['lib', '도서관'],
['everytime', '에브리타임'],
['kosis', 'statista', '국가통계'],
['consensus.hankyung', '한경컨센서스'],
['dart', '공시'],
['opentutorials', '오픈튜토리얼스'],
['brunch', '브런치'],
['contents.premium', '프리미엄컨텐츠'],
['oliveyoung', '올리브영'],
['sports', '스포츠'],
['hufs', '한국외대'],
];
for (const i in domainTagList) {
let lgth = domainTagList[i].length-1;
for (let j=0; j<lgth; j++) {
let tag = domainTagList[i][j];
if (domain.includes(tag)) {
autoTags.push(domainTagList[i][lgth]);
break;
}
}
};
return autoTags;
},
organizeResponseTags(
autoTags: string[],
userTags: string[],
) {
/**
* 사용자 직접 추가 태그들과 중복 검사 후 최종 태그리스트를 반환합니다.
*/
for (const tag of userTags) {
if (!autoTags.includes(tag)) {
autoTags.push(tag);
}
}
return autoTags;
}
};
});
export type AutoTagHookService = ReturnType<typeof getAutoTagHookService>;이렇게 몇주간의 험난한 과정을 통해 태그 자동생성 기능을 만들었다.
🪝 도전과제
비록 이번 종설을 통해 구현한 기능이 많진 않았지만, 개인적으로 여러 도전과제들과 느낀 점들이 있었다.
(내기준)시니어 개발자와의 소통
예상치 못하게 실력이 뛰어난 선배와 함께 서버를 만들면서, 간접적으로나마 회사에서 시니어개발자와 일을 할때를 연상해볼 수 있었다.
일단 시니어던 아니던간에 협업하는 사람과 서로의 말을 명확하게 이해하기란 참 쉬운 일이 아니다. 멋사에서도, 돔토리에서도, 협업하며 얘기를 하면 꼭 한번씩 무슨뜻인지 되묻고, 한참을 돌아 이해를 할 때도 많았다.
이번 프로젝트에서 선배 팀원분에게 물어보거나 팀원분이 나한테 무언가를 해달라고 말해주는 일이 많았는데, 그럴때마다 어떤걸 요구하는지 정확하게 파악이 안돼서 애를 먹었다.
특히 배포와 관련해서 거의 아무것도 모르던 당시, 선배가 구축해놓은 서버에 배포를 했어야 했다. ci/cd로 무중단 배포를 구축해주셨지만 가벼운 서버를 사용하다보니 거의 매번 서버를 정리하고 배포를 했어야 했고, 그 과정에서 애를 많이 먹었다. 그와중에 질문이나 pr을 올리면 한번에 이해할 수 없는 답변이 왔다- "러너 띄워주세요", "파인튜닝이 필요해요", "로컬에 도커 띄워서 테스트해주세요" 등등... 잘 모르는 과제에 설상가상으로 모르는 문제가 자꾸만 추가되는 상황에 고생을 많이했다. (결국 배포쪽에선 해결을 도저히 못하겠는데 시간에 쫓겨서 구조요청을 했던 적이.. 몇번..)
시간이 지나고 중간발표가 지나서부터는 조금씩 구축해놓은 서버에 대한 이해가 갔고, 여전히 팀원분의 말을 잘 이해하진 못했지만 하나하나 검색해보며 질문을 이해하는 시간을 오래 가졌다. 또 조금은 시간이 걸리더라도 최대한 내가 해결하려 했다. 가령 도커에 대한 이해가 부족한채 외부 라이브러리를 올리다가 도커 이미지에서 문제가 생겨 거의 일주일을 해결에 매달렸다.
팀원분이 나보다 훨씬 잘하고 서버팀에서 팀장과 같은 역할을 맡아주셨지만, 어쨌든 나와 같은 프로젝트 팀원이기에 선뜻 물어보거나 일을 부탁하기 어려웠고, 그래서 나혼자 끙끙 앓고 해결한 적이 많았다. (그렇다고 안물어본건 아니다. 프로젝트 후반에는 카톡을 너무 많이했다.)
어찌저찌 프로젝트를 끝내고보니, 신입사원으로 들어가서도 (조금 과장을 보태) 비슷한 문제를 겪지 않을까하는 생각이 들었다. 잘 구축되어있는 서버와 숙련된 시니어들 사이에 들어가면, 당연히 모든 일은 시니어들 위주로 돌아가고, 나는 시니어들이 하는 아주 어려운 말들을 꾸역꾸역 이해해야 할 것이다. 때문에 내가 맡은 일이 완벽히 이해되기 힘든 상황에서, 동시에 절대 사고치지도 않아야하니 얼마나 고생을 하겠는가.. 또 항상 질문하고 도움을 요청해야하지만 그게 어려운 상황이 충분히 있을 수도 있다.
이런 여러가지 일들에서 오는 부담과 스트레스를 이번 프로젝트에서 맛보기했던 것 같다. 벌써부터 만반의 준비를 해야겠다는 생각이 든다.
새로운 언어와 새로운 프레임워크
 겨울방학동안 부족한 실력을 키우고 종설에서 1인분을 해낼 준비를 하기 위해 내가 선택한 방법은 장고 책을 읽는 것이었다.
겨울방학동안 부족한 실력을 키우고 종설에서 1인분을 해낼 준비를 하기 위해 내가 선택한 방법은 장고 책을 읽는 것이었다.
물론 좋은 방법이지만, 당시의 나로서는 많이 아쉬운 공부방법이었다. 물론 기본기를 다지려고 했던 공부지만, 기본기가 부족했기에 결국에는 프레임워크에 의존해 공부를 했던 것 같다.
때문에 이번 프로젝트에서 난생 처음 보는 프레임워크를 쓰기로 결정한 후, 많은 방황을 했다. 팀원분과의 상의 끝에 타입스크립트를 쓰는 nest.js를 사용하기로 했었다. 자바스크립트도 모르는 나에게 너무 낯선 프레임워크였고, 이를 쓰기 위해 4월 중순정도까지는 자바스크립트와 네스트js 강의를 들으며 공부를 했다. 프레임워크가 바뀌자 겨울방학동안 했던 공부가 무색하게 새로 공부를 해야했고, 그마저도 시간에 쫓겨서 얕게 공부하다보니 말그대로 '쓰는 법'에 대해서만 공부했다는 생각이 든다. 자바스크립트의 기본인 동기비동기도 잘 이해를 못해서 이 문제가 생겼을땐 지피티의 힘을 많이 빌렸다.
이렇게 되니 한학기를 쏟은 프로젝트이지만 nestjs를 쓸줄 안다고 자신있게 말하긴 좀 어려운 듯하다. 프레임워크가 바뀌고 언어가 바뀌어도 자신있게 할 수 있는, 또 프레임워크에 흔들리지 않고 조금의 서치만으로 서버를 구현할 수 있을만큼 서버의 기본기가 갖춰져있는 상태가 돼야겠다고 생각했다.
(그래도 이후 여름방학부터 자바와 스프링을 공부할땐 1학기 프로젝트를 떠올리며 훨씬 쉽게 공부할 수 있었고, 스프링을 공부한지 거의 얼마 안 돼서 시작한 해커톤 스프링 프로젝트에서도 좀 더 완성도있게 스프링을 쓸 수 있었다. 도커와 깃헙액션에 대한 이해도도 늘었다. 이정도면 그래도 한학기를 쏟아 프로젝트한 게 헛되진 않은 거겠지?)
api와 라이브러리에 의존하지 않기
이번 내가 맡은 파트는 애초부터 '인공지능api를 사용해 태그를 자동으로 생성하는' 파트였다. 그렇기에 난 단순히 외부api를 사용하면 끝날 일이라고 생각했고, 새로운 프레임워크와 새로운 서버아키텍처 아래 처음으로 외부 api를 불러오는 일을 하는 것만으로 내겐 충분히 챌린징했기 때문에 구체적인 기능 구현 알고리즘은 깊게 생각하지 않았다.
그러나 생각보다 기본 모델(심지어 프리티어도 아님)로 쓸수있는 인공지능api는 성능이 낮았고, 언어 차이 등을 생각 못했기에 추가적으로 발생하는 이슈가 너무 많았다. 그러나 이미 api를 사용한 이상 이를 구체적으로 커스텀하긴 어려웠고, 결국 발생하는 이슈를 또다른 라이브러리로 막고 또다른 라이브러리로 막고... 하는 비효율적인 코드가 탄생했다.
어떤 팀은 비슷한 기능을 위해 모델을 만들고 머신러닝까지 학기 내내 시켰는데, 이를 다소 가볍게 보고 구현했다는 점이 상당히 아쉬웠다. 심지어 부가기능도 아닌 나름 이프로젝트의 차별점이자 메인기능임에도 완벽하지 못했다는 점이 참 아쉽게 남는다.
1px만 옮겨주세요 는 프론트에만 해당하는 트롤짓이 아니다. 겉으로 보기엔 요렇게 코드 한줄만 추가하지... 또는 이건 그냥 라이브러리 써서 해결하지.. 싶었던 것도 막상 구현하면 발생하는 문제가 한두개가 아니다. 어떤 기능도 얕게 보고 대충 구현하지 않아야 하고, 외부 api와 라이브러리에 의존해서 기능을 만드는 일은 없어야 할듯하다.
소통
거의 처음으로 PM과 백과 프론트가 모두 존재하는 프로젝트는 처음이다. 또 이렇게 모르는 사람들과 팀으로 뭉쳐 프로젝트를 한 것도 처음이다. 그렇다보니 PM이 주로 얘기를 하고, 백-클라이언트 사이에서 소통을 담당하기도 했다. 학교 프로젝트가 그렇듯 다들 말을 잘 안하는 건(나포함) 맞긴 하지만, 이래서 클라랑 서버가 연동이 잘 될까? 싶을 정도로 소통이 많이 없었다.
PM이 나서서 소통을 적극적으로 해준 건 정말 고마웠지만, 아무래도 개발에 대한 이해도가 떨어지다보니 중간에 요구사항이 잘못 전달되기도 하고, 기획의도와 실제 구현이 안 맞아 충돌이 있었던 적도 있다. 또한 발표할 때도 개발의도를 PM이 전달하다보니 다소 두루뭉술하거나 또는 과도하게 구체적으로 소개된 적도 있었다.
답은 적극적인 소통일듯하다. 그래도 나름 우리 팀 안에서는 PM 다음으로 말을 많이 하려고 했던 것 같다. 그치만 나도 말하다보면 지치거나 에라 모르겠다 하고 외면한 적이 많은데, 그때 더 끝까지 소통할껄 하는 생각을 한다. 또 모두가 책임감을 갖고 소통에 참여해줘야 말하는 사람도 더 책임감을 갖지 않을까 싶다.
