일정한 규칙(패턴)을 가진 문자열을 표현하는 방법
복잡한 문자열 속에서 특정한 규칙으로 된 문자열을 검색한 뒤 추출하거나 바꿀 때 사용
문자열 판단
문자열에 특정 문자열이 포함되어 있는지 판단 ( 'Hello, world!'.find('Hello')처럼 문자열 메서드로도 충분히 가능)
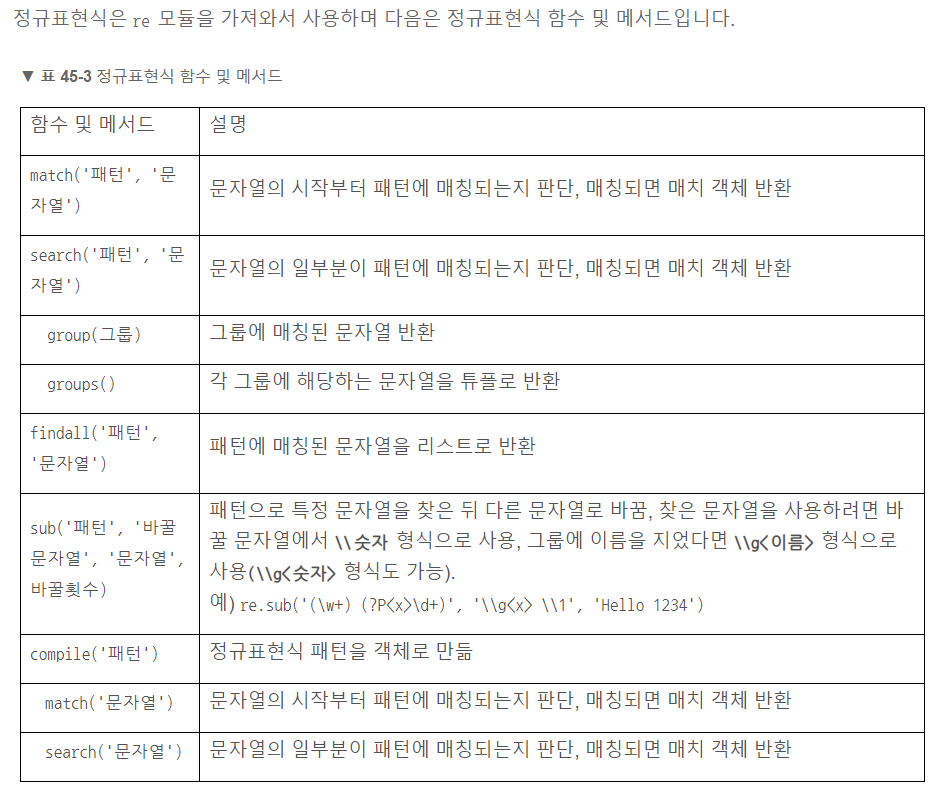
정규표현식은 re 모듈을 가져와서 사용하며 match 함수에 정규표현식 패턴과 판단할 문자열을 넣기
- re.match('패턴', '문자열')
문자열이 있으면 매치(SRE_Match) 객체가 반환되고 없으면 아무것도 반환되지 x
>>> import re
>>> re.match('Hello', 'Hello, world!') # 문자열이 있으므로 정규표현식 매치 객체가 반환됨
<_sre.SRE_Match object; span=(0, 5), match='Hello'>
>>> re.match('Python', 'Hello, world!') # 문자열이 없으므로 아무것도 반환되지 않음특정 문자열이 맨 앞/뒤에 오는지 판단
특정 문자열로 끝나는지
match 대신 search 함수를 사용해 (match 함수는 문자열 처음부터 매칭되는지 판단하지만, search는 문자열 일부분이 매칭되는지 판단)
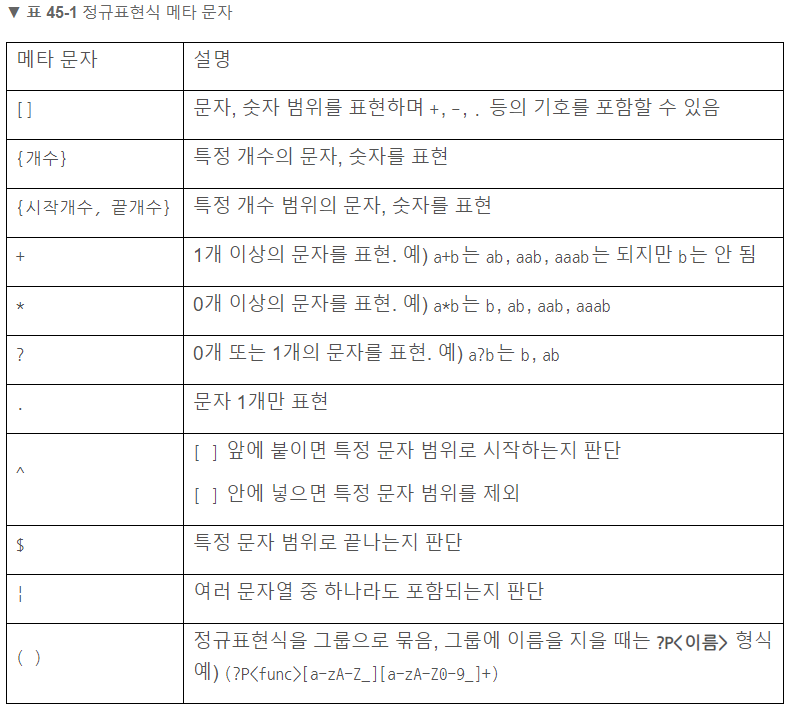
- ^문자열
- 문자열$
- re.search('패턴', '문자열')
>>> re.search('^Hello', 'Hello, world!') # Hello로 시작하므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='Hello'>
>>> re.search('world!$', 'Hello, world!') # world!로 끝나므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(7, 13), match='world!'>지정된 문자열이 하나라도 포함되는지 판단
|는 특정 문자열에서 지정된 문자열(문자)이 하나라도 포함되는지 판단 - OR 연산자와 같음
- 문자열|문자열
- 문자열|문자열|문자열|문자열
>>> re.match('hello|world', 'hello') # hello 또는 world가 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='hello'>범위 판단
문자열이 숫자로 되어있는지 판단
안에 숫자 범위를 넣으며 또는 +를 붙입니다. 숫자 범위는 0-9처럼 표현하며 는 문자(숫자)가 0개 이상 있는지, +는 1개 이상 있는지 판단
- [0-9]*
- [0-9]+
>>> re.match('[0-9]*', '1234') # 1234는 0부터 9까지 숫자가 0개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='1234'>
>>> re.match('[0-9]+', '1234') # 1234는 0부터 9까지 숫자가 1개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='1234'>
>>> re.match('[0-9]+', 'abcd') # abcd는 0부터 9까지 숫자가 1개 이상 없으므로 패턴에 매칭되지 않음>>> re.match('a*b', 'b') # b에는 a가 0개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 1), match='b'>
>>> re.match('a+b', 'b') # b에는 a가 1개 이상 없으므로 패턴에 매칭되지 않음
>>> re.match('a*b', 'aab') # aab에는 a가 0개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='aab'>
>>> re.match('a+b', 'aab') # aab에는 a가 1개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='aab'>문자가 한개만 있는지 판단
?는 ? 앞의 문자(범위)가 0개 또는 1개인지 판단하고, .은 .이 있는 위치에 아무 문자(숫자)가 1개 있는지 판단
- 문자?
- [0-9]?
- .
>>> re.match('abc?d', 'abd') # abd에서 c 위치에 c가 0개 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='abd'>
>>> re.match('ab[0-9]?c', 'ab3c') # [0-9] 위치에 숫자가 1개 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='ab3c'>
>>> re.match('ab.d', 'abxd') # .이 있는 위치에 문자가 1개 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='abxd'>문자 개수 판단
문자(숫자)가 정확히 몇 개 있는지 판단
- 문자{개수}
- (문자열){개수}
h{3}은 h가 3개 있는지 판단하고, (hello){3}은 hello가 3개 있는지 판단
특정 범위의 문자(숫자)가 몇 개 있는지 판단
- [0-9]{개수}
>>> re.match('[0-9]{3}-[0-9]{4}-[0-9]{4}', '010-1000-1000') # 숫자 3개-4개-4개 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 13), match='010-1000-1000'>문자(숫자)의 개수 범위도 지정
- (문자){시작개수,끝개수}
- (문자열){시작개수,끝개수}
- [0-9]{시작개수,끝개수}
숫자, 영문 조합
영문 문자 범위
- a-z
- A-Z
한글- 가-힣
>>> re.match('[a-zA-Z0-9]+', 'Hello1234') # a부터 z, A부터 Z, 0부터 9까지 1개 이상 있으므로
<_sre.SRE_Match object; span=(0, 9), match='Hello1234'> # 패턴에 매칭됨특정 문자 범위에 포함되지 않는지 판단
문자(숫자) 범위 앞에 ^를 붙이면 해당 범위를 제외
- [^범위]*
- [^범위]+
!! 범위를 제외할 때는 '[^A-Z]+'와 같이 [ ] 안에 넣어주고, 특정 문자 범위로 시작할 때는 '^[A-Z]+'와 같이 [ ] 앞에 붙여줍니다
>>> re.match('[^A-Z]+', 'hello') # 대문자를 제외. 대문자가 없으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='hello'>특수문자 판단
특수 문자를 판단할 때는 특수 문자 앞에 \
- \특수문자
>>> re.match('[$()a-zA-Z0-9]+', '$(document)') # $, (, )와 문자, 숫자가 들어있는지 판단
<_sre.SRE_Match object; span=(0, 11), match='$(document)'>단순 판단
단순히 숫자인지 문자인지 판단할 때는 \d, \D, \w, \W를 사용하면 편리
- \d: [0-9]와 같음. 모든 숫자
- \D: [^0-9]와 같음. 숫자를 제외한 모든 문자
- \w: [a-zA-Z0-9_]와 같음. 영문 대소문자, 숫자, 밑줄 문자
- \W: [^a-zA-Z0-9_]와 같음. 영문 대소문자, 숫자, 밑줄 문자를 제외한 모든 문자
공백 처리
공백은 ' '처럼 공백 문자를 넣어도 되고, \s 또는 \S로 표현
- \s: [ \t\n\r\f\v]와 같음. 공백(스페이스), \t(탭) \n(새 줄, 라인 피드), \r(캐리지 리턴), \f(폼피드), \v(수직 탭)을 포함
- \S: [^ \t\n\r\f\v]와 같음. 공백을 제외하고 \t, \n, \r, \f, \v만 포함
핵심정리
scr: https://dojang.io/mod/page/view.php?id=2454