정규표현식 그룹으로 묶기
정규표현식 그룹은 해당 그룹과 일치하는 문자열을 얻어올 때 사용
- (정규표현식) (정규표현식)
- re.match('(정규표현식1)(표현식2)', '문자열')
공백으로 구분된 숫자를 두 그룹으로 나누어서 찾은 뒤 각 그룹에 해당하는 문자열(숫자)을 가져오기
- 매치객체.group(그룹숫자)
>>> m = re.match('([0-9]+) ([0-9]+)', '10 295')
>>> m.group(1) # 첫 번째 그룹(그룹 1)에 매칭된 문자열을 반환
'10'
>>> m.group(2) # 두 번째 그룹(그룹 2)에 매칭된 문자열을 반환
'295'
>>> m.group() # 매칭된 문자열을 한꺼번에 반환
'10 295'
>>> m.group(0) # 매칭된 문자열을 한꺼번에 반환
'10 295' group 메서드에 숫자를 지정하면 해당 그룹에 매칭된 문자열을 반환
숫자를 지정하지 않거나 0을 지정하면 매칭된 문자열을 한꺼번에 반환
- 매치객체.groups()
groups 메서드는 각 그룹에 해당하는 문자열을 튜플로 반환
>>> m.groups() # 각 그룹에 해당하는 문자열을 튜플 형태로 반환
('10', '295')그룹 개수가 많아지면 그룹에 이름을 지으면 편리
- (?P<이름>정규표현식)
- 매치객체.group('그룹이름')
>>> m = re.match('(?P<func>[a-zA-Z_][a-zA-Z0-9_]+)\((?P<arg>\w+)\)', 'print(1234)')
>>> m.group('func') # 그룹 이름으로 매칭된 문자열 출력
'print'
>>> m.group('arg') # 그룹 이름으로 매칭된 문자열 출력
'1234'(?P)와 (?P)처럼 각 그룹에 이름, m.group('arg')로 매칭된 문자열을 출력
함수 이름은 문자로만 시작해야 하므로 첫글자는 [a-zA-Z_]로 판단
print 뒤에 붙은 (, )는 정규표현식에 사용하는 특수 문자이므로 앞에 \를 붙여
그룹 지정 없이 패턴에 매칭되는 모든 문자열
- re.findall('패턴', '문자열')
findall 함수를 사용하며 매칭된 문자열을 리스트로 반환
예) 문자열에서 숫자만 가져오기
>>> re.findall('[0-9]+', '1 2 Fizz 4 Buzz Fizz 7 8')
['1', '2', '4', '7', '8']
문자열 바꾸기
특정 문자열을 찾은 뒤 다른 문자열로 바꾸는 방법 - sub 함수를 사용
- re.sub('패턴', '바꿀문자열', '문자열', 바꿀횟수)
바꿀 횟수를 넣으면 지정된 횟수만큼 바꾸며 바꿀 횟수를 생략하면 찾은 문자열을 모두
문자열 대신 교체 함수를 지정
- 교체함수(매치객체)
- re.sub('패턴', 교체함수, '문자열', 바꿀횟수)
ex) 'apple' 또는 'orange'를 찾아서 'fruit'
>>> re.sub('apple|orange', 'fruit', 'apple box orange tree') # apple 또는 orange를 fruit로 바꿈
'fruit box fruit tree'ex)mutiple10 함수에서 group 메서드로 매칭된 문자열을 가져와서 정수로 바꿉니다. 그리고 숫자에 10을 곱한 뒤 문자열로 변환해서 반환
>>> def multiple10(m): # 매개변수로 매치 객체를 받음
... n = int(m.group()) # 매칭된 문자열을 가져와서 정수로 변환
... return str(n * 10) # 숫자에 10을 곱한 뒤 문자열로 변환해서 반환
...
>>> re.sub('[0-9]+', multiple10, '1 2 Fizz 4 Buzz Fizz 7 8')
'10 20 Fizz 40 Buzz Fizz 70 80'람다표현식으로 교체함수
>>> re.sub('[0-9]+', lambda m: str(int(m.group()) * 10), '1 2 Fizz 4 Buzz Fizz 7 8')
'10 20 Fizz 40 Buzz Fizz 70 80찾은 문자열을 결과에 다시 사용
정규표현식으로 찾은 문자열을 가져와서 결과에 다시 사용
-> 정규표현식을 그룹으로 묶습니다. 그러고 나면 바꿀 문자열에서 \숫자 형식으로 매칭된 문자열을 가져와서 사용
그룹에 이름을 지었다면 \g<이름> 형식으로 매칭된 문자열을 가져오기
- \숫자
- \g<이름>
- \g<숫자>
예) 'hello 1234'에서 hello는 그룹 1, 1234는 그룹 2로 찾은 뒤 그룹 2, 1, 2, 1 순으로 문자열의 순서를 바꿔서 출력
>>> re.sub('([a-z]+) ([0-9]+)', '\\2 \\1 \\2 \\1', 'hello 1234') # 그룹 2, 1, 2, 1 순으로 바꿈
'1234 hello 1234 hello'예2) '{ "name": "james" }'을 'james' 형식으로
>>> re.sub('({\s*)"(\w+)":\s*"(\w+)"(\s*})', '<\\2>\\3</\\2>', '{ "name": "james" }')
'<name>james</name>' 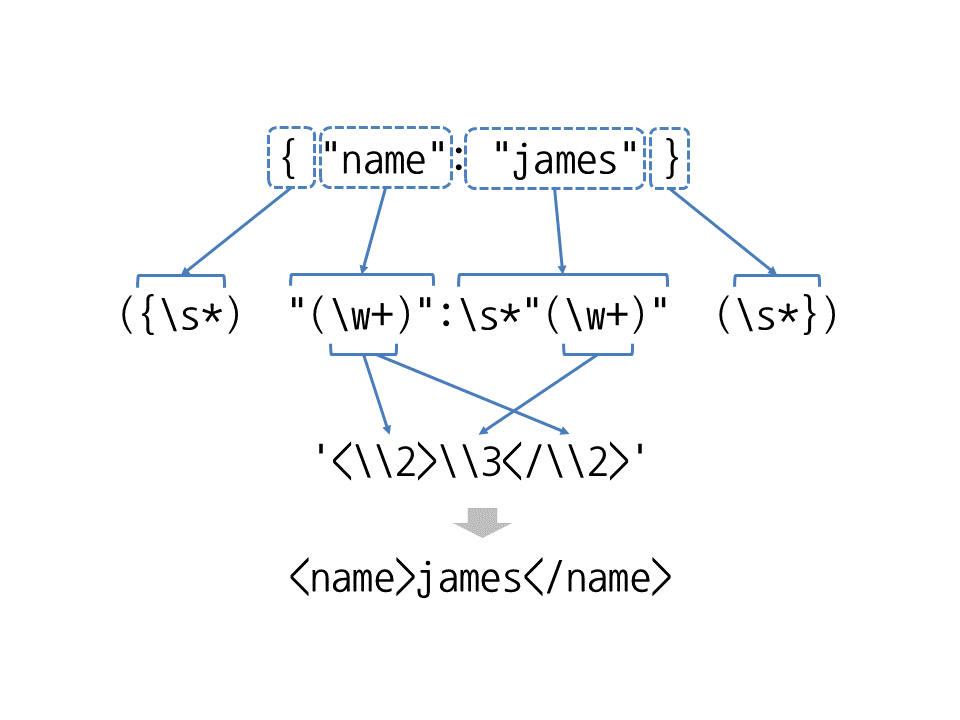
예시문제 : 이메일 주소 검사하기
import re
p = re.compile( '^[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$' )
emails = ['python@mail.example.com', 'python+kr@example.com', # 올바른 형식
'python-dojang@example.co.kr', 'python_10@example.info', # 올바른 형식
'python.dojang@e-xample.com', # 올바른 형식
'@example.com', 'python@example', 'python@example-com'] # 잘못된 형식
for email in emails:
print(p.match(email) != None, end=' ')- re 불러오기
- 이메일 형식 짜기
@ 앞에 는 ^[] 맨 앞에 오는 지, 대소문자 숫자, 특수기호
뒤에는 숫자문자기호
중간에 . 해서 쩜이 있나 판단
[.] .이 있는 위치에 아무 문자(숫자)가 1개 있는지 판단
$로 맨 마지막에 옴.
문제 : URL 검사하기
표준 입력으로 URL 문자열이 입력 입력됩니다. 입력된 URL이 올바르면 True, 잘못되었으면 False를 출력하는 프로그램을 만드세요. 이 심사문제에서 판단해야 할 URL의 규칙은 다음과 같습니다.
http:// 또는 https://로 시작
도메인은 도메인.최상위도메인 형식이며 영문 대소문자, 숫자, -로 되어 있어야 함
도메인 이하 경로는 /로 구분하고, 영문 대소문자, 숫자, -, _, ., ?, =을 사용함
풀이
import re
url = input()
print(re.match('^https?://[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+/[a-zA-Z0-9-_/.?=]', url) != None)-
input으로 입력 값 받고 url 변수에 저장
-
정규식 짜기
시작부분: ^https?://
^로 맨 앞에 오는지, s?는 s가 0 or 1개도메인: [a-zA-Z0-9-]+.[a-zA-Z0-9-.]+/
문자숫자- 범위 이면서 문자 1개이상무조건(+)
온점
그 뒤는 같지만 범위에 .을 추가 왜? 여러 단계일 수 있어서.
/ 는 도메인 이하 경로 구분경로: [a-zA-Z0-9-_/.?=]
문자숫자 범위안에 / : 하위경로 나올 수 있어서. -
re.match 함수로 url 판단. 함수 반환값이 있어면 true 출력 없으면 false 출력
print에 re.match의 결과가 none 이 아닌지 여부
