[NLP] 1. GETTING STARTED WITH NATURAL LANGUAGE PROCESSING
Codecademy | Natural Language Processing
1. Intro to NLP
- intersection of linguistics, artificial intelligence, and computer science.
- has wide range of applicaton
- python : most extensive NLP libraries (incl. NLTK)
2. Text Preprocessing
- first step. to clean the text (using Regex, NLTK lib)
- common tasks
Noise removal : format text stripping(html tags)
Tokenizaiton : sperating words
Normalization : cleaning text
(stemming, Lemmatization(to the words' root),
lowercasing, stopwords removal, etc.
import re, nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
#텍스트 불러오기
text = looking_glass_text
# re 로 클린하기
cleaned = re.sub('\W+', ' ', text).lower()
#토크나이즈하기
tokenized = word_tokenize(cleaned)
#stoop words filtering
stop_words = stopwords.words('english')
filtered = [word for word in tokenized if word not in stop_words]
#lemmatize 하기. second arg(get_part_of_speech(token)) 주기
normalizer = WordNetLemmatizer()
normalized = [normalizer.lemmatize(token, get_part_of_speech(token)) for token in filtered]
3. Parsing Text
- segmenting text based on syntax
Part-of-speech tagging (POS tagging)
- parts of speech (verbs, nouns, adjectives, etc.)
Named entity recognition (NER)
- identify the proper nouns in text
Dependency grammertree
- relationship between the words in a sentence
- Python library
spaCy
Regex parsing
- Python library
re
4. Language Models - Bag-of-Words Approach
- training a language model on a corpus(example text) to make predcition
language model
- probabilistic computer models of language.
- 단어 시퀀스(문장)에 확률을 할당하는 모델(적절한 단어, 문장을 판단/ 예측)
- 통계 or 인공신경망 이용
bag-of-words
- most common model
- good for making predictions concerning topic or sentiment of a text
- 통계적 언어모델 (SLM)
bag_of_looking_glass_words = Counter(normalizedtext) 단어별로 갯수 볼수 잇음
단어별로 갯수 볼수 잇음
5. Language Models - N-Grams and NLM
N-grams
-
통계적 접근을 사용하고 있으므로 SLM의 일종 + 일부 단어만 고려하는 접근 방법
-
앞 단어 중 임의의 개수만 포함해서 카운트 -> 갖고 있는 코퍼스에서 해당 단어의 시퀀스를 카운트할 확률이 높아짐
-
임의의 개수를 정하기 위한 기준 n-gram (n개의 연속적인 단어 나열)
-
문제점:전체 문장을 고려한 언어 모델보다는 정확도가 떨어짐
looking_glass_bigrams = ngrams(tokenized, 2)
looking_glass_bigrams_frequency = Counter(looking_glass_bigrams)
print(looking_glass_bigrams_frequency.most_common(10))- ngram 메서드 사용. 인자로 n 조절.
- counter로 갯수 세고 most_common 리턴
neural language models (NLM)
- 인공 신경망을 이용한 언어 모델
- 위 모델의 한계를 해결하고자 최근에 많이 씀.
- deep learning approach
6. Topic Models
Topic modeling
토픽 모델링
텍스트 본문의 숨겨진 의미 구조를 발견하기 위해 사용되는 텍스트 마이닝 기법
-
uncovering latent topics within a body of language
-
term frequency-inverse document frequency (tf-idf)
: 너무 많이 반복되는 것은 거르기 ->gensimsklearn라이브러리 활용 -
latent Dirichlet allocation (LDA)
determines which words keep popping up together in the same contexts -
word2vec
map out your topic model results spatially as vectors
= word embedding
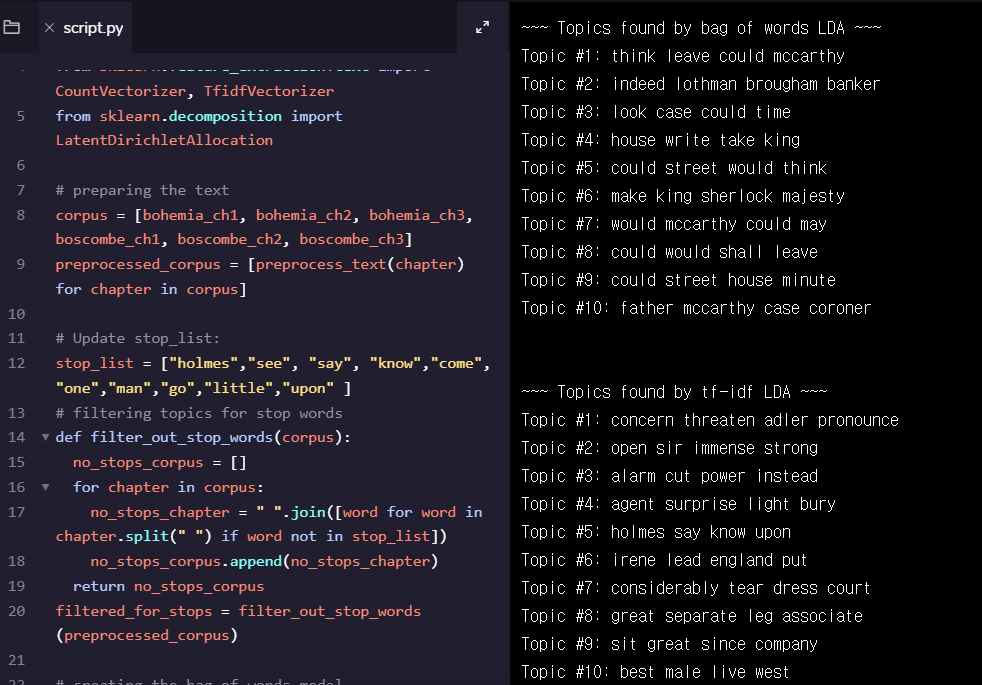 반복되는 무의미한 단어 제외해줌으로써 토픽에 가까워지게
반복되는 무의미한 단어 제외해줌으로써 토픽에 가까워지게
7. Text Similarity
문서 유사도
기계가 계산하는 문서의 유사도의 성능은 각 문서의 단어들을 어떤 방법으로 수치화하여 표현했는지(DTM, Word2Vec 등), 문서 간의 단어들의 차이를 어떤 방법(유클리드 거리, 코사인 유사도 등)으로 계산했는지에 달려있습니다
-
Levenshtein distance : how far between two diff words
-
lexical similarity (the degree to which texts use the same vocabulary and phrases).
-
semantic similarity (the degree to which documents contain similar meaning or topics)
8. Language Prediction & Text Generation
Language prediction
- form: Autosuggest, autocomplete, suggested replies
- choose language model -
9. Advanced NLP Topics
Naive Bayes classifiers
- supervised machine learning algorithms that leverage a probabilistic theorem to make predictions and classifications
- sentiment analysis (negative or positive), spam filtering
machine translation
language accessibility
- for ppl w/ disabillities
10. Challenges and Considerations
- difference based on diff languages
- users’ privacy
11. NLP Review
- NLP는 컴공+언어학+인공지능
- text preprocessing : nlp하기 위해 준비시키기
- Parsing : 신텍스로 text 해집기
- 언어모델: 확률모델 - bag, ngram, 신경언어모델 등
- topic 모델링: 숨은 토픽 확실히하기
- text similarity : 언어의 인스턴스들 사이의 유사성
- lan predition : 선행된 것으로 예측
- 사회적, 도덕적 고려 필요
