정규 표현식 문법
1. Intro
-
regex : special sequence of characters that describe a pattern of text that should be found, or matched, in a string or document
-
use cases: HTML input, verifying and parsing text in files, keyword in web pages
2. Literals
- The simplest text we can match with regular expressions (alphabetical characters & digits)
3. Alternation |
- match either the characters preceding the | OR the characters after the |
4. Character Sets []
- match one character from a series of characters, allowing for matches with incorrect or different spellings.
[ ]안에 문자들 중 한 개의 문자와 매치
5. Wild for Wildcards .
- 한 개의 임의의 문자
- \n 은 escape character
6. Ranges -
- [0-9][a-z] [A-Z]
- [a-zA-Z]는 알파벳 전체를 의미. 문자열에 알파벳이 존재하면 매치
7. Shorthand Character Classes

8. Grouping ()
- I love (baboons|gorillas)
9. Quantifiers - Fixed {}
- indicate the exact quantity of a character we wish to match, or allow us to provide a quantity range to match on.
squea{3,5}k: a가 3~5번 반복

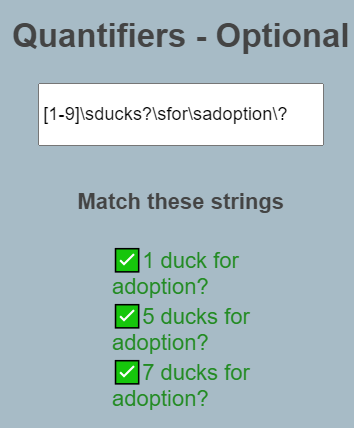
10. Quantifiers - Optional ?

11. Quantifiers - 0 or More, 1 or More

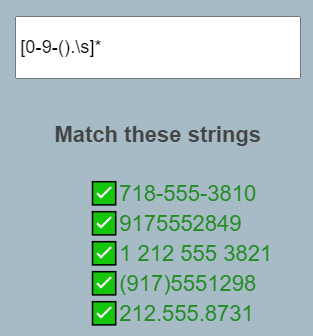
-ex : [] 범위 안에 숫자와 문자, 공백 넣고 *표시로 0개 이상 조건 달아줌
12. Anchors


참고
https://wikidocs.net/21703
정규 표현식 모듈 re 이 있음. 메서드 사용 가능

roundy