[NLP] 6. TERM FREQUENCY–INVERSE DOCUMENT FREQUENCY
Codecademy | Natural Language Processing
Codecademy [Learn Natural Language Processing]
TERM FREQUENCY–INVERSE DOCUMENT FREQUENCY
wikidocs : https://wikidocs.net/31698
Introduction
tf-idf : 단어 빈도-역 문서 빈도
-
단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법
-
DTM : 문서 단어 행렬(Document-Term Matrix
-
주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰임
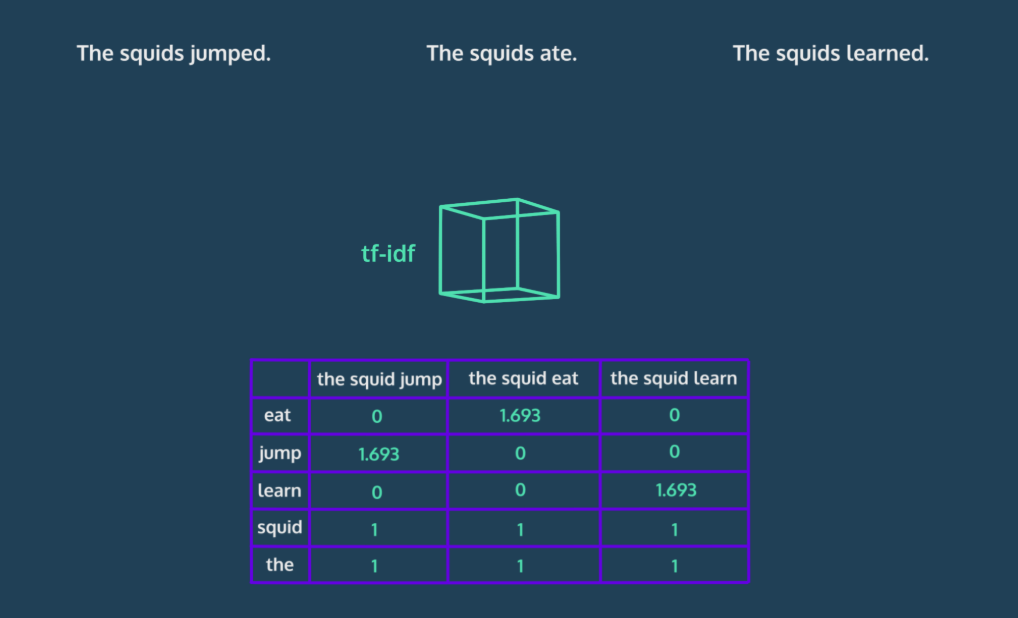
What is Tf-idf?
-
a numerical statistic used to indicate how important a word is to each document in a collection of documents, or a corpus
-
term frequency: how often a word appears in a document -
inverse document frequency: how often a word appears in the overall corpus
Breaking It Down Part I: Term Frequency
-
Term frequency indicates how often each word appears in the document
-
using
scikit-learn’sCountVectorizer
카운트백터라이저의 객체를 만들고 fit transform메서드 사용하기vectorizer = CountVectorizer()
term_frequencies = vectorizer.fit_transform([stanza])- A CountVectorizer object is initialized
- The CountVectorizer object is fit (trained) and transformed (applied) on the corpus of data, returning the term frequencies for each term-document pair
-
CounterVectorizer 의 객체는
.get_feature_names라는 메서드 있음. -> corpus의 unique terms 리턴feature_names = vectorizer.get_feature_names()
Breaking It Down Part II: Inverse Document Frequency
-
score penalizes terms that appear more frequently across a corpus

-
scikit-learn’sTfidfTransformer:transformer = TfidfTransformer(norm=None)
transformer.fit(term_frequencies)
inverse_doc_frequency = transformer.idf_- 객체 시작하기.
- fit 으로 train하기 term doc metrix에
- idf는 인버스 df 를 줌. numpy array로
Putting It All Together: Tf-idf

- 계산법:
scikit-learn’sTfidfVectorizervectorizer = TfidfVectorizer(norm=None)
tfidf_vectorizer = vectorizer.fit_transform(corpus)- the TfidfVectorizer object is fit and transformed on the corpus of data, returning the tf-idf scores for each term-document pair
Converting Bag-of-Words to Tf-idf
-Scikit-learn’s TfidfTransformer
tf_idf_transformer = TfidfTransformer(norm=False)
tf_idf_scores = tfidf_transformer.fit_transform(count_matrix)
PRoject
import codecademylib3_seaborn
import pandas as pd
import numpy as np
from articles import articles
from preprocessing import preprocess_text
# import CountVectorizer, TfidfTransformer, TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer, TfidfVectorizer
# view article
print(articles [7])
# preprocess articles
processed_articles = [preprocess_text(document) for document in articles ]
# initialize and fit CountVectorizer
vectorizer = CountVectorizer()
counts = vectorizer.fit_transform(processed_articles )
# convert counts to tf-idf
transformer = TfidfTransformer (norm = None)
tfidf_scores_transformed = transformer.fit_transform(counts)
# initialize and fit TfidfVectorizer
vectorizer = TfidfVectorizer(norm=None)
tfidf_scores = vectorizer.fit_transform(processed_articles)
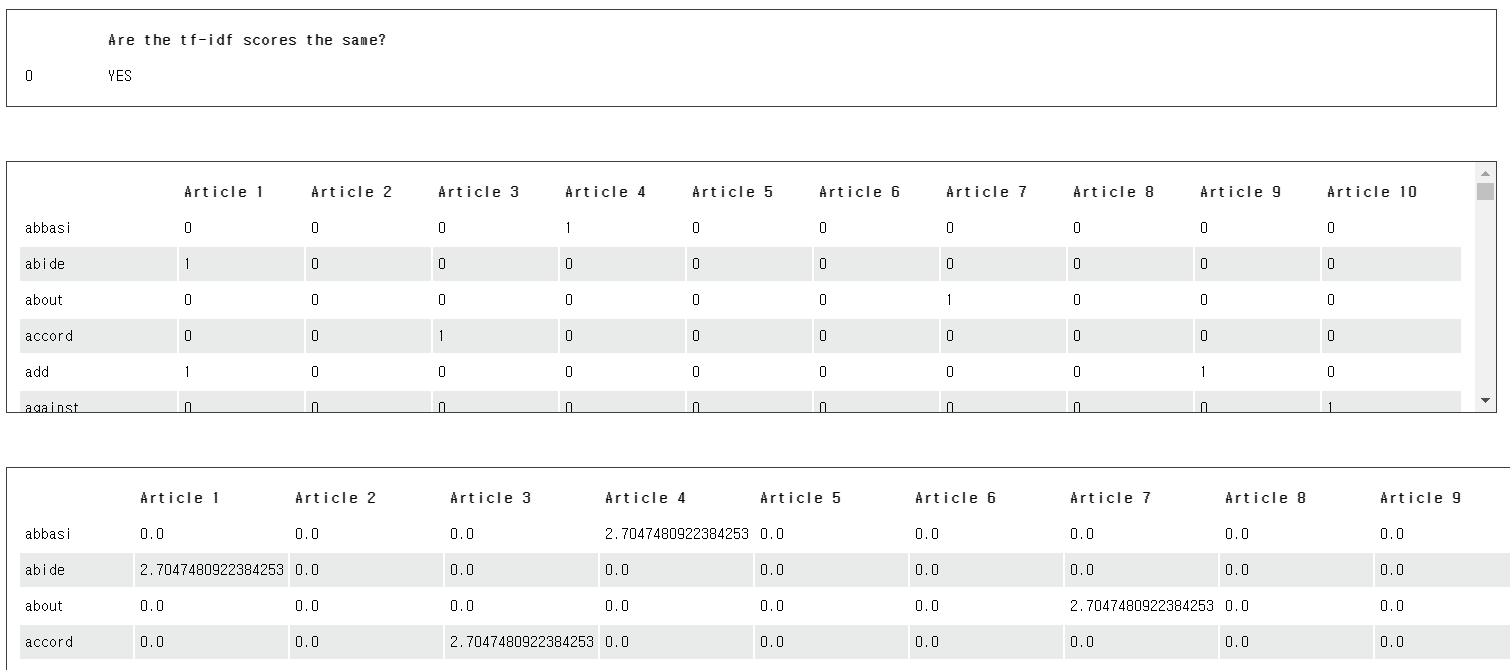
# check if tf-idf scores are equal
if np.allclose(tfidf_scores_transformed.todense(), tfidf_scores.todense()):
print(pd.DataFrame({'Are the tf-idf scores the same?':['YES']}))
else:
print(pd.DataFrame({'Are the tf-idf scores the same?':['No, something is wrong :(']}))
# get vocabulary of terms
try:
feature_names = vectorizer.get_feature_names()
except:
pass
# get article index
try:
article_index = [f"Article {i+1}" for i in range(len(articles))]
except:
pass
# create pandas DataFrame with word counts
try:
df_word_counts = pd.DataFrame(counts.T.todense(), index=feature_names, columns=article_index)
print(df_word_counts)
except:
pass
# create pandas DataFrame(s) with tf-idf scores
try:
df_tf_idf = pd.DataFrame(tfidf_scores_transformed.T.todense(), index=feature_names, columns=article_index)
print(df_tf_idf)
except:
pass
try:
df_tf_idf = pd.DataFrame(tfidf_scores.T.todense(), index=feature_names, columns=article_index)
print(df_tf_idf)
except:
pass
# get highest scoring tf-idf term for each article
for i in range(1,11):
print(df_tf_idf[[f'Article {i}']].idxmax())
Article 1 fare
dtype: object
Article 2 hong
dtype: object
Article 3 sugar
dtype: object
Article 4 petrol
dtype: object
Article 5 engine
dtype: object
Article 6 australia
dtype: object
Article 7 car
dtype: object
Article 8 railway
dtype: object
Article 9 cabinet
dtype: object
Article 10 china
dtype: object