Codecademy [Learn Natural Language Processing]
WORD EMBEDDINGS
Introduction
-
워드 임베딩(Word Embedding) :컴퓨터가 이해할 수 있도록 자연어를 적절히 변환 / 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환
-
단어의 의미를 벡터화시킬 수 있는 워드투벡터(Word2Vec)와 글로브(Glove)가 많이 사용
-
a representation of a word as a numeric vector, enabling us to compare and contrast how words are used and identify words that occur in similar contexts
-
application: 1.entity recognition in chatbots 2.sentiment analysis 3.syntax parsing
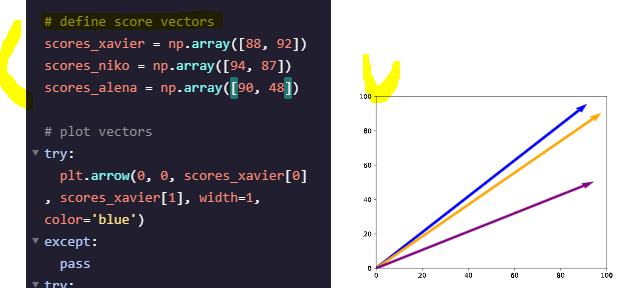
Vectors
- containers of information.
NumPy의arrays()메서드로 파이썬에서 백터 표현odd_vector = np.array([1, 3, 5, 7, 9])
What is a Word Embedding?
-
vector representations of a word
-
English word embedding model
nlp = spacy.load('en')
nlp('love').vector- nlp라는 변수에 spacy 모델 로드하는게 관례
- 단어의 벡터 representation 얻기위해
.vector적용하기
- 단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 워드 임베딩(word embedding).
- 임베딩 벡터(embedding vector) : 이 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과
Distance
3 distance between vectors
-
Manhattan distance = city block distance
: sum of the differences across each individual dimension of the vectors -
Euclidean distance = straight line distance : the square root of the sum of the squares of the differences in each dimension
-
cosine distance : angle between two vectors
functions from
SciPy로 이런 백터 구하기 가능
from scipy.spatial.distance import cityblock, euclidean, cosine
vector_a = np.array([1,2,3])
vector_b = np.array([2,4,6])
# Manhattan distance:
manhattan_d = cityblock(vector_a,vector_b) # 6
# Euclidean distance:
euclidean_d = euclidean(vector_a,vector_b) # 3.74
# Cosine distance:
cosine_d = cosine(vector_a,vector_b) # 0.0Word Embeddings Are All About Distance
- 백터값 자체는 의미가 없음. 이게 서로 얼마나 유사한지 등이 중요함.
- gain value in word embeddings from comparing the different word vectors and seeing how similar or different they are
Word2vec
- statistical learning algorithm that develops word embeddings from a corpus of text
- 단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화 할 수 있는 방법
- Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식 있음
CBOW(Continuous Bag of Words) : 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
Skip-Gram : 중간에 있는 단어로 주변 단어들을 예측하는 방법
CBOW
- 한 문장에서 빈 단어 예측하기. 예측해야하는 단어 = center word, 예측에 사용하는 주변단어 = context word
- 중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정했다면 이 범위를 윈도우(window)
- 윈도우를 계속 움직여서 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터 셋을 만들 수 있는데, 이 방법을 슬라이딩 윈도우(sliding window)
Skip-Gram
- 중심 단어에서 주변 단어를 예측
Gensim
-
파이썬의
gensim패키지에는Word2Vec을 지원 -
With gensim, however, we are able to build our own word embeddings on any corpus of text we like
-
train a word2vec model on our own corpus of text
model = gensim.models.Word2Vec(corpus, size=100, window=5, min_count=1, workers=2, sg=1)- size : how many dimensions our word embeddings will include.
-
To view the entire vocabulary used to train the word embedding model
vocabulary_of_model = list(model.wv.vocab.items())
-
To easily find which vectors gensim placed close together in its word embedding model
model.most_similar("my_word_here", topn=100) -
which term is furthest from the others
model.doesnt_match(["asia", "mars", "pluto"])
example
import gensim
from nltk.corpus import stopwords
from romeo_juliet import romeo_and_juliet
# load stop words
stop_words = stopwords.words('english')
# preprocess text
romeo_and_juliet_processed = [[word for word in romeo_and_juliet.lower().split() if word not in stop_words]]
# view inner list of romeo_and_juliet_processed
print(romeo_and_juliet_processed[0][:20])
# train word embeddings model
model = gensim.models.Word2Vec(romeo_and_juliet_processed , size=100, window=5, min_count=1, workers=2, sg=1)
# view vocabulary
vocabulary = list(model.wv.vocab.items())
print(vocabulary)
# similar to romeo
similar_to_romeo= model.most_similar("romeo", topn=20)
print(similar_to_romeo)
# one is not like the others
not_star_crossed_lover = model.doesnt_match(["romeo", "juliet", "mercutio"])
print(not_star_crossed_lover)
Review
-
Vectors : containers of information,
can have anywhere from 1-dimension to thousands of dimensions -
Word embeddings : are vector representations of a word, where words with similar contexts are represented with vectors that are closer together
-
spaCy is a package to view and use pre-trained word embedding models
-
The distance between vectors can be calculated in many ways, and the best way for measuring the distance between higher dimensional vectors is cosine distance
-
Word2Vec is a shallow neural network model that can build word embeddings using either continuous bag-of-words or continuous skip-grams
-
Gensim is a package that allows us to create and train word embedding models using any corpus of text
import spacy
from scipy.spatial.distance import cosine
# load word embedding model
nlp = spacy.load('en')
# define word embedding vectors
sponge_vec = nlp("sponge").vector
starfish_vec = nlp("starfish").vector
squid_vec = nlp("squid").vector
# compare vectors with cosine distance
dist_sponge_star = cosine(sponge_vec,starfish_vec)
dist_sponge_squid = cosine(sponge_vec,squid_vec)
dist_star_squid = cosine(starfish_vec,squid_vec)
print(dist_sponge_star,
dist_sponge_squid,
dist_star_squid)
오답
- genism 은 나만의 워드 임베딩 만들 수 있음. 어떤 코르푸스를 바탕으로 든. spacy는 이미 준비된 코르푸스 씀.
