Codecademy [Learn Natural Language Processing]
GENERATING TEXT WITH DEEP LEARNING
Use Tensorflow’s Keras API to build a seq2seq deep learning network of LSTM cells for machine translation.
article : Long short term memory networks (LSTMs)
-
Neural networks: machine learning framework loosely based on the structure of the human brain
-
early models were not good
Neural Networks
- 퍼셉트론 Perceptron
초기 인공 신경망 모델 중 하나
다수의 신호(Input)을 입력받아서 하나의 신호(Output)을 출력
한계가 있었음.
Deep Neural Networks
- neural network systems that combined many layers of neurons
- many layers of neurons that combine to create a “deep” stack of neurons
deep-learning architectures
- multi-layer perceptrons (MLP)
comprised of layered perceptrons. good at solving simple tasks- convolutional neural networks (CNN)
to process image data,- recurrent neural networks (RNN)
widely adopted within natural language processing
integrate a loop into the connections between neurons, allowing information to persist across a chain of neurons
순환 신경망
딥 러닝에 있어 가장 기본적인 시퀀스 모델
입력과 출력을 시퀀스 단위로 처리하는 모델
Long short term memory networks (LSTMs)
- 장단기 메모리
- LSTM은 은닉 상태(hidden state)를 계산하는 식이 전통적인 RNN보다 조금 더 복잡해졌으며 셀 상태(cell state)라는 값을 추가
- 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정합니다
- popular for building realistic chatbot systems
- chain of repeating neurons at its base
- groups of neurons perform four distinct operations on input data, which are then sequentially combined
- the transformed input data is combined by adding results to state, or cell memory, represented as vectors
기본 RNN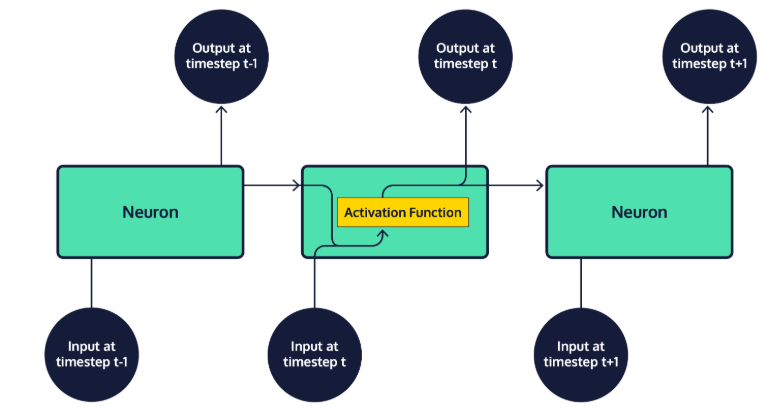
LSTMs 적용
- cell state : carries information through the network as we process a sequence of inputs
- hidden state : final product, which is fed as input to the next neural network layer at the next timestep
- The final output of a neural network is often the result contained in the final hidden state, or an average of the results across all hidden states in the network
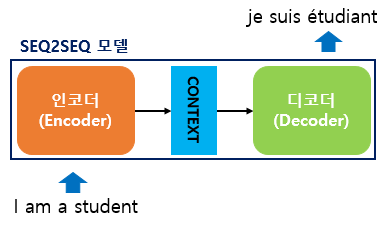
Introduction to seq2seq
시퀀스-투-시퀀스
입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력
ex) 챗봇(Chatbot)과 기계 번역(Machine Translation), 내용 요약(Text Summarization), STT(Speech to Text)
- encoder-decoder model
- uses recurrent neural networks (RNNs) like LSTM in order to generate output, token by token or character by character
크게 두 개로 구성된 아키텍처
-
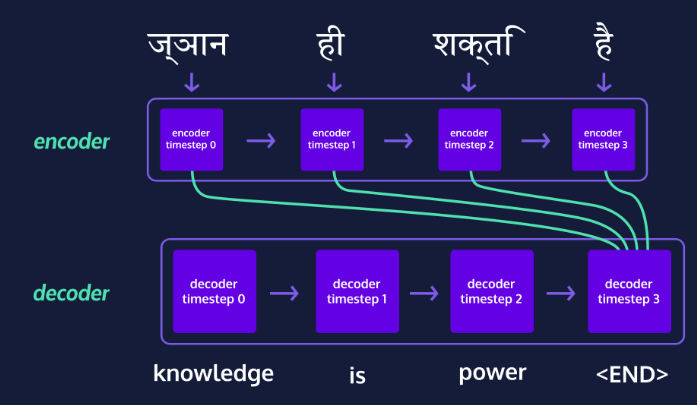
encoder : accepts language input.
입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터로 (컨텍스트 벡터(context vector)) 만들고 디코더에 전송 -
decoder : takes the encoder’s final state (or memory) as its initial state
컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력
Preprocessing for seq2seq
TensorFlowwith theKeras API
from tensorflow import keras
from tensorflow import keras
import re
# Importing our translations
data_path = "span-eng.txt"
# Defining lines as a list of each line
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.read().split('\n')
# Building empty lists to hold sentences
input_docs = []
target_docs = []
# Building empty vocabulary sets
input_tokens = set()
target_tokens = set()
for line in lines:
# Input and target sentences are separated by tabs
input_doc, target_doc = line.split('\t')
# Appending each input sentence to input_docs
input_docs.append(input_doc)
# Splitting words from punctuation
target_doc = " ".join(re.findall(r"[\w']+|[^\s\w]", target_doc))
# Redefine target_doc below
# and append it to target_docs:
target_doc = '<START> ' + target_doc + ' <END>'
target_docs.append(target_doc)
# Now we split up each sentence into words
# and add each unique word to our vocabulary set
for token in re.findall(r"[\w']+|[^\s\w]", input_doc):
print(token)
# Add your code here:
if token not in input_tokens:
input_tokens.add(token)
for token in target_doc.split():
print(token)
# And here:
if token not in target_tokens:
target_tokens.add(token)
input_tokens = sorted(list(input_tokens))
target_tokens = sorted(list(target_tokens))
# Create num_encoder_tokens and num_decoder_tokens:
num_encoder_tokens = len(input_tokens)
num_decoder_tokens = len(target_tokens)
max_encoder_seq_length = max([len(re.findall(r"[\w']+|[^\s\w]", input_doc)) for input_doc in input_docs])
max_decoder_seq_length = max([len(re.findall(r"[\w']+|[^\s\w]", target_doc)) for target_doc in target_docs])
결과
We'll
see
.
<START>
Después
veremos
.
<END>
We'll
see
.
<START>
Ya
veremos
.
<END>Training Setup (part 1)
- vectorizing the data(features dic) to input into encoder/decoder
import numpy as np
encoder_input_data = np.zeros(
(len(input_docs), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')예시
from tensorflow import keras
import numpy as np
from preprocessing import input_docs, target_docs, input_tokens, target_tokens, num_encoder_tokens, num_decoder_tokens, max_encoder_seq_length, max_decoder_seq_length
print('Number of samples:', len(input_docs))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
input_features_dict = dict(
[(token, i) for i, token in enumerate(input_tokens)])
# Build out target_features_dict:
target_features_dict = dict(
[(token, i) for i, token in enumerate(target_tokens)])
# Reverse-lookup token index to decode sequences back to
# something readable.
reverse_input_features_dict = dict(
(i, token) for token, i in input_features_dict.items())
# Build out reverse_target_features_dict:
reverse_target_features_dict = dict(
(i, token) for token, i in target_features_dict.items())
encoder_input_data = np.zeros(
(len(input_docs), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
print("\nHere's the first item in the encoder input matrix:\n", encoder_input_data[0], "\n\nThe number of columns should match the number of unique input tokens and the number of rows should match the maximum sequence length for input sentences.")
# Build out the decoder_input_data matrix:
decoder_input_data = np.zeros(
(len(input_docs), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
# Build out the decoder_target_data matrix:
decoder_target_data = np.zeros(
(len(input_docs), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')result
Number of samples: 11
Number of unique input tokens: 18
Number of unique output tokens: 27
Max sequence length for inputs: 4
Max sequence length for outputs: 12
Here's the first item in the encoder input matrix:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
The number of columns should match the number of unique input tokens and the number of rows should match the maximum sequence length for input sentences.Training Setup (part 2)
- to fill out the 1s in each vector
matrix_name[line, timestep, features_dict[token]] = 1.
from tensorflow import keras
import numpy as np
import re
from preprocessing import input_docs, target_docs, input_tokens, target_tokens, num_encoder_tokens, num_decoder_tokens, max_encoder_seq_length, max_decoder_seq_length
input_features_dict = dict(
[(token, i) for i, token in enumerate(input_tokens)])
target_features_dict = dict(
[(token, i) for i, token in enumerate(target_tokens)])
reverse_input_features_dict = dict(
(i, token) for token, i in input_features_dict.items())
reverse_target_features_dict = dict(
(i, token) for token, i in target_features_dict.items())
encoder_input_data = np.zeros(
(len(input_docs), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_docs), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_docs), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for line, (input_doc, target_doc) in enumerate(zip(input_docs, target_docs)):
for timestep, token in enumerate(re.findall(r"[\w']+|[^\s\w]", input_doc)):
print("Encoder input timestep & token:", timestep, token)
# Assign 1. for the current line, timestep, & word
# in encoder_input_data:
encoder_input_data[line, timestep, input_features_dict[token]] = 1.
for timestep, token in enumerate(target_doc.split()):
# decoder_target_data is ahead of decoder_input_data by one timestep
print("Decoder input timestep & token:", timestep, token)
# Assign 1. for the current line, timestep, & word
# in decoder_input_data:
decoder_input_data[line, timestep, target_features_dict[token]] = 1.
if timestep > 0:
# decoder_target_data will be ahead by one timestep
# and will not include the start token.
print("Decoder target timestep:", timestep)
# Assign 1. for the current line, timestep, & word
# in decoder_target_data:
decoder_target_data[line, timestep - 1, target_features_dict[token]] = 1.Encoder Training Setup
deep learning
-
requires two layer types from Keras:
input layer : defines a matrix to hold all the one-hot vectors that we’ll feed to the model.
LSTM layer : with some output dimensionality
레이어 & 모델 임포트하기
from keras.layers import Input, LSTM
from keras.models import Model -
input layer :requires some number of dimensions that we’re providing
encoder_inputs = Input(shape=(None, num_encoder_tokens)) -
LSTM layer : select the dimensionality , whether to return the state
encoder_lstm = LSTM(100, return_state=True)
using a dimensionality of 100
so any LSTM output matrix will have
shape [batch_size, 100] -
getting final states : linking our LSTM layer with our input layer:
encoder_outputs, state_hidden, state_cell = encoder_lstm(encoder_inputs) -
save the states
encoder_states = [state_hidden, state_cell]
ex
from prep import num_encoder_tokens
from tensorflow import keras
from keras.layers import Input, LSTM
from keras.models import Model
# Create the input layer:
encoder_inputs = Input(shape=(None, num_encoder_tokens))
# Create the LSTM layer:
encoder_lstm = LSTM(256, return_state=True)
# Retrieve the outputs and states:
encoder_outputs, state_hidden, state_cell = encoder_lstm(encoder_inputs)
# Put the states together in a list:
encoder_states = [state_hidden, state_cell]Decoder Training Setup
-
decoder layer
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_lstm = LSTM(100, return_sequences=True, return_state=True) -
states 말고 output 저장하기
decoder_outputs, decoder_state_hidden, decoder_state_cell = decoder_lstm(decoder_inputs, initial_state=encoder_states)
-
run final actication layer : using the
Softmaxfunction, that will give us the probability distribution -
Build a final Dense layer
from keras.layers import Input, LSTM, Dense
decoder_dense = Dense(num_decoder_tokens, activation='softmax') -
Filter outputs through the Dense layer
decoder_outputs = decoder_dense(decoder_outputs)
Build and Train seq2seq
model-building
- define the seq2seq model using the
Model()function fromKerasmodel = Model([encoder_inputs, decoder_inputs], decoder_outputs)
eed it the encoder and decoder inputs, as well as the decoder output
model is ready to train
- compile
2 arguments for compiling Kerase models:
-
optimizer : help minimize our error rate
-
loss function : to determine the error rate
For accuracy, we’re adding that into the metrics to pay attention to while training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
- fit the compiled model
: give the.fit()method the encoder and decoder input data, the decoder target data,model.fit([encoder_input_data, decoder_input_data], decoder_target_data, batch_size=10, epochs=100, validation_split=0.2)
Setup for Testing
before testing model, need to redefine the seq2seq architecture in pieces
why? model we used for training our network only works when we already know the target sequence
-
build an encoder model : with our encoder inputs and the placeholders for the encoder’s output states
encoder_model = Model(encoder_inputs, encoder_states) -
Building the two decoder state input layers
placeholders for the decoder’s input stateslatent_dim = 256 decoder_state_input_hidden = Input(shape=(latent_dim,))
decoder_state_input_cell = Input(shape=(latent_dim,)) -
Put the state input layers into a list:
decoder_states_inputs = [decoder_state_input_hidden, decoder_state_input_cell] -
create new decoder states and outputs
by using the decoder LSTM and decoder dense layer -
Call the decoder LSTM
decoder_outputs, state_hidden, state_cell = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs) -
Saving the new LSTM output states:
decoder_states = [state_hidden, state_cell] -
redefine the decoder output
by passing it through the dense layer:decoder_outputs = decoder_dense(decoder_outputs)
- Build the decoder test model:
decoder_model = Model( [decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states)
The Test Function
testing our model
build a function :
to accept a Numpy matrix(representing test EN sentence input) & use the encoder and decoder for ES output
-
takes in new input (as a NumPy matrix) and gives us output states that we can pass on to the decoder
states = encoder.predict(test_input) -
build an empty NumPy array for our Spanish translation, giving it three dimensions
target_sequence = np.zeros((1, 1, num_decoder_tokens))- batch size, number of tokens to start with:, number of tokens in our target vocabulary
-
Populate the first token of target sequence with the start token
target_sequence[0, 0, target_features_dict['<START>']] = 1. -
before decoding, string where can add translation to. word by word
decoded_sentence = '' -
full funtion
def decode_sequence(test_input):
# Encode the input as state vectors:
encoder_states_value = encoder_model.predict(test_input)
# Set decoder states equal to encoder final states
decoder_states_value = encoder_states_value
# Generate empty target sequence of length 1:
target_seq = np.zeros((1, 1, num_decoder_tokens))
# Populate the first token of target sequence with the start token:
target_seq[0, 0, target_features_dict['<START>']] = 1.
decoded_sentence = ''
return decoded_sentenceTest Function (part 2)
trying translation
함수 수정
def decode_sequence(test_input):
encoder_states_value = encoder_model.predict(test_input)
decoder_states_value = encoder_states_value
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, target_features_dict['<START>']] = 1.
decoded_sentence = ''
stop_condition = False
while not stop_condition:
# Run the decoder model to get possible
# output tokens (with probabilities) & states
output_tokens, new_decoder_hidden_state, new_decoder_cell_state = decoder_model.predict(
[target_seq] + decoder_states_value)
# Choose token with highest probability
sampled_token_index = np.argmax(
output_tokens[0, -1, :])
sampled_token = reverse_target_features_dict[
sampled_token_index]
decoded_sentence += " "+ sampled_token
# Exit condition: either hit max length
# or find stop token.
if (sampled_token == '<END>' or len(decoded_sentence) > max_decoder_seq_length):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
decoder_states_value = [
new_decoder_hidden_state,
new_decoder_cell_state]
return decoded_sentenceReview
-
seq2seq : deep learning model. use recurrent neural networks like LSTMs
-
seq2seq(machine translation) : encoder(input languae, output state vectors) & decoder(accepts encoder's final state, outputs translation)
-
teacher forcing : mehtod to train seq2seq decorders
-
marking beginning/end of target sentences -> decoder 가 알 수 있게.
-
one-hot vectors : represent given word in set of words, use 1 to indicate the current word. (else is 0)
-
Timesteps : tracking where we are in a sent.
-
Softmax function : converts the output of the LSTMs into a probability distribution over words in our vocabulary.
- batch-size : number of training examples fed to the model at a time
