Accurate Compression of Text-to-Image Diffusion Models via Vector Quantization
대규모 텍스트-이미지 diffusion 모델(SDXL, SDXL-Turbo)을 3~4비트로 압축하면서도 품질 손실 없이 추론 성능을 유지하는 vector quantization 기반 PTQ(post-training quantization) 방법인 VQDM 제안했습니다.
SDXL, DALL·E 3 등 최신 T2I 모델은 수십억 개의 파라미터로 인해 추론 속도 및 메모리 사용량이 크다는 걸림돌이 있죠. 기존 PTQ 방식들은 대부분 uniform scalar quantization을 기반으로 하며 4비트 수준(codewords는 16개)에서 한계가 존재합니다. 반면, 본 논문은 Vector Quantization(VQ)을 적용하여 더 낮은 비트수로(average around 3 bits)도 고품질 유지 가능함을 보였습니다. 이 방법은 기존 scalar 방식의 한계를 극복하고, vector quantization 기반의 다중 codebook 구조(AQ: Additive Quantization)를 통해 3–4bit로 압축하면서도 기존 성능을 유지합니다.
구성은 다음 세 단계로 이뤄집니다:
1. Vector Quantization of U-Net
Diffusion 모델의 U-Net은 다양한 해상도의 convolution & transformer block으로 구성된 이질적 구조입니다. GPT 같은 LLM과 달리 동일한 hidden size를 공유하지 않기 때문에 기존 LLM VQ 기법은 그대로 사용 불가합니다.
따라서, SDXL U-Net 구조에 맞게 다음 전략을 적용합니다:
-
압축 대상: SDXL의 2.6B 파라미터 중 U-Net의 convolution & linear layer
-
비압축 대상:
- 입력/출력 layer (채널 수 작고 효과 미미)
- timestep embedding (시간정보 유지 중요)
- Text encoder, VAE 등 (추론 비용에서 비중 적음)
-
Vector Quantization 구조:
- 기존 scalar 방식: 각 weight를 1D 격자에 투영 (단순하지만 데이터 분포 무시)
- 본 논문 방식: 다중 codebook 기반 VQ (Additive Quantization, AQ) 사용, weight group을 벡터로 보고, M개의 codebook에서 벡터 조합으로 표현
- 각 group은 code index와 scale을 통해 압축
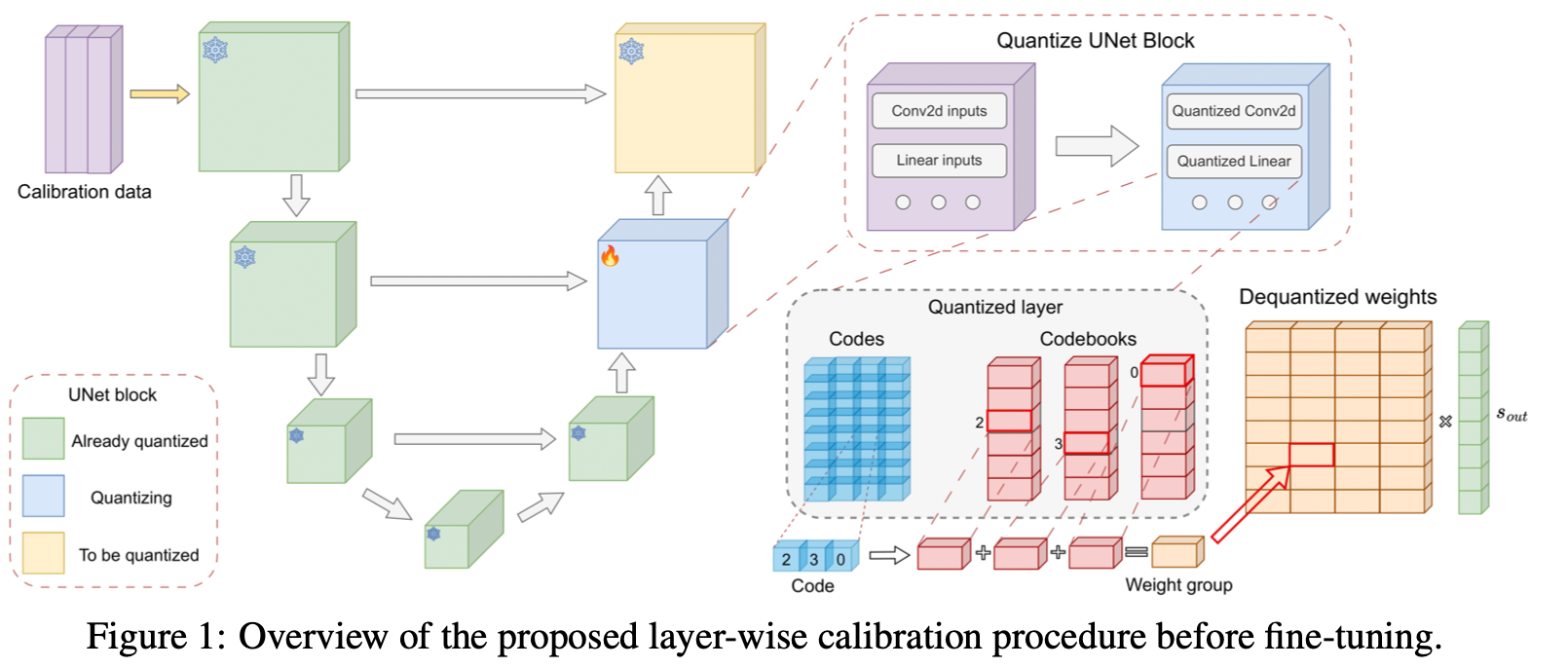
2. Calibration of Quantized Layers
양자화된 weight 가 원래 weight 와 비슷한 출력을 만들도록 오차(MSE)를 최소화합니다:
여기서 는 해당 레이어의 입력 행렬입니다. 이 작업은 각 레이어 또는 block 단위로 수행됩니다.
효율적 MSE 계산을 위한
- 는 보통 수천~수만 개의 샘플 입력을 포함하므로 저장 비용이 큽니다.
- 이를 해결하기 위해, 를 다음과 같이 변형합니다:
- 즉, 입력 대신 만 저장하면 계산이 가능합니다.
- 이는 GPTQ, AQLM 등 최신 LLM quantization에서도 사용되는 방식입니다.
Calibration Procedure
- Full-precision 모델로 diffusion trajectory를 수집해 각 레이어의 입력 를 추출
- 각 resolution block (down1, down2, ..., up3 등)을 한 번에 묶어 calibration 수행 (총 7개 subset)
- 기반으로 codebook 및 scale factor 최적화 (Adam + beam search 기반 AQ)
- output 방향의 scaling vector 까지 함께 학습하여 출력을 정교하게 보정
3. Global Fine-Tuning with Teacher-Student Distillation
각 레이어 단위 양자화는 독립적으로 이루어지기 때문에 전체 모델의 출력에는 누적 오차가 생깁니다. 이를 보정하기 위해 fine-tuning 단계에서는 전체 U-Net을 대상으로 teacher-student 학습을 수행합니다.
- Teacher: Full-precision U-Net
- Student: Quantized U-Net (AQ codebooks 포함)
- Loss: 각 diffusion timestep에서의 예측 간 MSE
- Mixed precision 학습 (AMP), gradient checkpointing으로 메모리 절감
- 학습 데이터: 단 몇천 개의 prompt로 생성한 샘플로 충분 (약 2048개)
- 전체 fine-tuning은 수 시간 내에 완료 가능 (A100 기준)
[Experiments] SDXL

| 방법 | 평균 비트 | Pickscore↑ | CLIP↑ | FID↓ |
|---|---|---|---|---|
| 원본 | 32 | 0.226 | 0.357 | 18.99 |
| VQDM 4bit | 4.15 | 0.226 | 0.356 | 19.11 |
| VQDM 3bit | 3.15 | 0.225 | 0.355 | 19.18 |
- VQDM 3bit는 기존 4bit 방식(Q-Diffusion, PTQ4DM)과 유사하거나 더 나은 성능을 보임.
- Human Evaluation에서도 VQDM 4bit는 거의 구분 불가능한 수준.
[Experiments] SDXL-Turbo
- Distilled 모델인 SDXL-Turbo에도 3~4비트 압축이 가능.
- 다양한 샘플링 스텝 (1, 2, 4)에 대해 성능 저하 없이 적용됨.
GPU (A100) 기준으론 3~4bit 압축 시 최대 5배 메모리 절감, 약 50% 추론 속도 저하 되었습니다. CPU 기준으론 최대 9.7배 메모리 절감, 23~26% 추론 속도 저하 되었습니다. 소프트웨어 기반 VQ lookup의 연산 효율이 낮은 점이 병목임 이지만 이들은 FPGA 등에서 해결 가능하다고 합니다.
Future work와 연계하자면, Transformer 기반 diffusion 모델에는 아직 적용되지 않았고 Activation quantization은 다루지 않았다는 한계가 존재합니다. 또, LUT 기반 연산 속도 문제는 향후 하드웨어 개선 필요합니다.
VQDM은 대규모 텍스트-이미지 diffusion 모델의 3비트 압축을 실현하며, 기존 4비트 PTQ 방식 대비 더 나은 품질-압축률 균형을 보여줬습니다.
