시작하며,
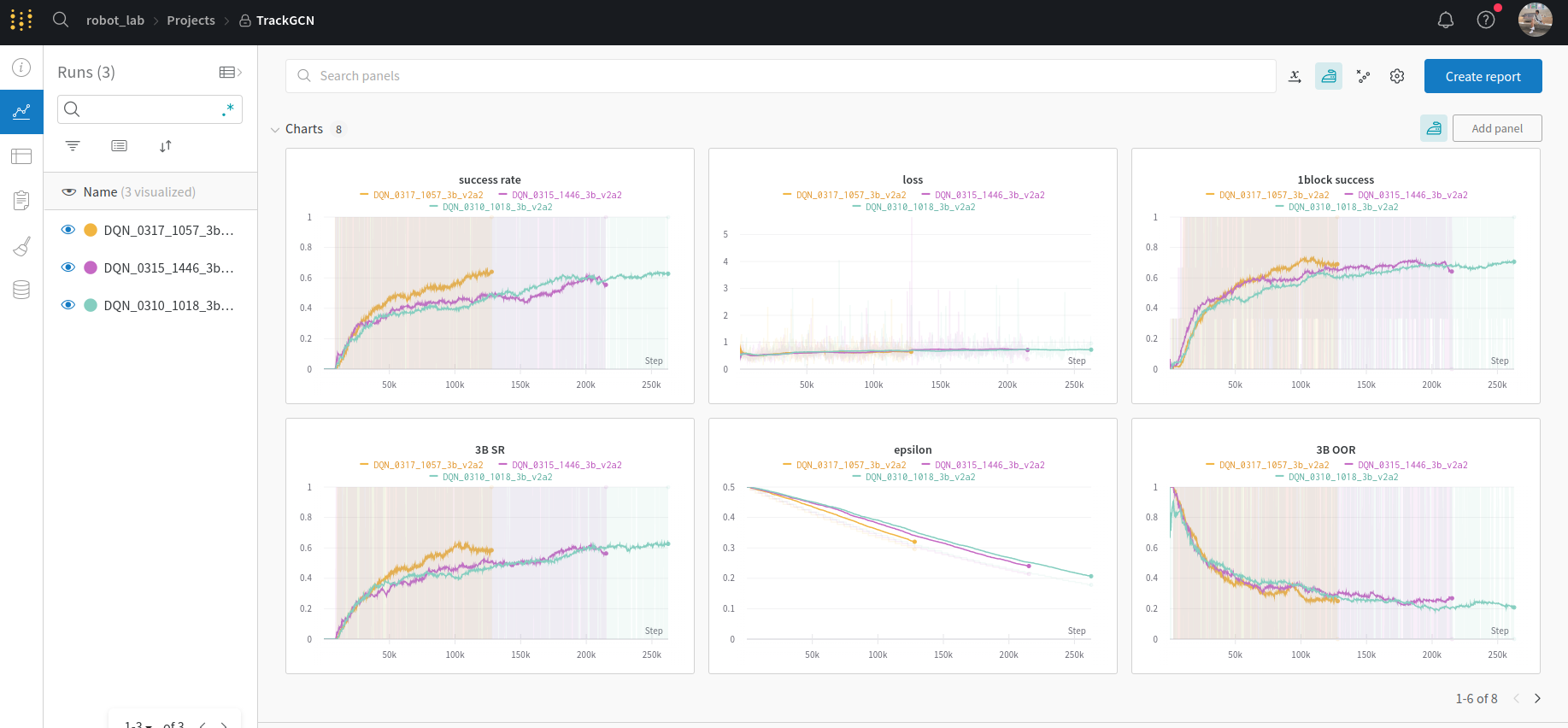
일단 졸업 연구는 꾸준히 진행하고 있습니다! SDFGCN의 front-end인 object matching 부분을 3개로 바꿔서 위와 같이 wandb로 plotting 하고 있습니다. 그 뒤엔 완전히 새로운 architecture인 coherent point drift로 rigid body의 transformation을 찾아 pick-and-place 방식으로 물체를 재배열하려고 합니다. 그렇게 이번엔 Point Set Registration: Coherent Point Drift와 Unsupervised 3D Link Segmentation of Articulated Objects With a Mixture of Coherent Point Drift를 참조하여 앞으로 활용할 개념을 재정비해보려고 합니다. 졸업 연구 기간이 8주밖에 남지 않은 만큼 더욱더 빠르게 hustle 해야겠어요.
EM과 optimal rotation matrix의 closed-form solution을 배경지식으로 활용합니다.
EM: https://velog.io/@jpseo99/Expectation-Maximization
optimal rotation matrix: https://velog.io/@jpseo99/closed-form-solution-of-the-rotation-matrix
Point Set Registration: Coherent Point Drift (For Rigid Body)
rigid transformation: translation, rotation, scaling
non-rigid transformation: anisotropic scaling, skews
논문에서는 rigid transformation뿐만 아닌 non-rigid transformation까지 범용적으로 다룹니다. 하지만, 저의 연구 object matching은 rigid body만을 input으로 다루기 때문에 non-rigid related part는 생략했습니다. rigid transformation은 위에서 명시한 대로 평행이동, 회전, 스케일링만 가능합니다. non-rigid transformation은 이방성 스케일링, 왜곡까지 포함합니다. 한편, Non-rigid transformation은 real-world에서 굉장히 자주 발생합니다. deformable motion tracking, shape recognition 그리고 medical image registration 등이 그 예시입니다. 여유가 생겼을 때, 차근차근 살펴보면 재밌겠다는 생각이 드네요!
두개 point sets의 alignment를 probability density estimation 문제의 관점으로 바라봅니다. 둘 중 하나의 point set은 Gaussian mixture model centroids로 보고 나머지 하나는 data points로 봅니다. optimum에서 두 point sets가 aligned 되고 correspondence는 주어진 data point에 대한 GMM posterior probability로 구할 수 있습니다. 이 방법론의 핵심은 GMM centroids를 강제하여 일관적으로 (coherently) 움직여 point sets의 topological structure을 유지하는 것에 있습니다.
D: point sets의 차원
N: data points (첫번째 point sets) 의 개수
M: GMM centroids (두번째 point sets) 의 개수
X: data points (첫번째 point sets), N×D matrix
Y: GMM centroids (두번째 point sets), M×D matrix
T(Y,θ) - Y에 Transformation (θ를 매개변수로 가지는) T를 적용 했을 때의 결과입니다. T는 rigid, non-rigid transformation을 전부 포함합니다.
I: identity matrix
1: 1로 가득 찬 column vector (차원은 때에 따라 다릅니다)
d(a) - vector a의 값을 원소로 가지는 diagonal matrix
3. Expectation of the complete negative log-likelihood function (general case rigid body)
우리는 Y를 GMM centroids로 생각하고 X를 이 GMM mixture에 의해 생성된 points라고 생각합니다. 이때, GMM 확률밀도함수를 아래와 같이 표현할 수 있습니다.
p(x)=∑m=1M+1p(m)p(x∣m)
여기서 m=1,2,3,...,M일 때 p(x∣m)은 아래와 같습니다.
p(x∣m)= (2πσ2)D/21exp(−21(σ∣x−ym∣)2)
mixture model의 noise와 outliers를 위해 m=M+1일 때는
p(x∣M+1)=N1
으로 설정했습니다.
우리는 동일한 분산 σ2과 membership probability p(m)=M1,m=1,2,...,M을 활용했습니다.
0과 1사이의 weight w에 대해 mixture model의 확률 밀도 함수는 아래와 같습니다.
p(x)=wN1+(1−w)∑m=1MM1p(x∣m)
EM 알고리즘을 위한 complete negative log-likelihood의 기댓값(objective function)은 아래와 같습니다.
∑n=1N∑m=1M+1Pold(m∣xn) log(pnew(m)pnew(xn∣m))
위의 objective function을 θ,σ2와 관계없는 항을 제거한 뒤에 나타내면 아래와 같습니다. θ,σ에 대한 미분을 통해 M-step을 진행하기 때문에 그 이외의 항은 상수로 해석할 수 있기 때문입니다.
2σ21∑n=1N∑m=1M+1Pold(m∣xn) ∣xn−T(ym,θ)∣2+2NPDlogσ2,Np=∑n=1N∑m=1MP(m∣xn)
여기서 GMM component의 posterior probabilities는 아래와 같습니다.
Pold(m∣xn)=∑m=1Mexp(−21(σold∣x−T(yk,θold)∣)2)+cexp(−21(σold∣x−T(ym,θold)∣)2)
c=(2πσ2)D/21−wwNM
4. E-step and M-step (rigid body)
rigid point set registration problem에서 GMM centroid 위치의 transformation을 아래와 같이 정의합니다.
T(ym;R,t,s)=sRym+t
RD×D는 회전 변환이고 tD×1는 평행이동, s는 scale을 나타냅니다.
아래의 optimal problem을 해결하는 것이 M-step 입니다.
Q(R,t,s,σ2)=2σ21∑n=1N∑m=1M+1Pold(m∣xn) ∣xn−sRym−t∣2+2NPDlogσ2,Np=∑n=1N∑m=1MP(m∣xn)
minQ(R,t,s,σ2),s.t.RTR=I, det(R)=1
위 문제는 generalized weighted absolute orientation problem 입니다. 아래의 lemma를 활용해서 이 문제에 접근해볼 수 있습니다.

Q를 t에 대해서 편미분해서 0이 되는 값을 찾으면 아래와 같습니다.
t=N1XTPT1−sRN1YTP1=µx−sRµy
Pmn=pold(m∣xn)
µx=NP1XTPT1
µy=NP1YTP1
위의 t에 관한 식을 Q에 대입하면 아래와 같습니다.
Q=2σ21[tr(X^Td(PT1))X^−2s tr(X^PTY^RT)+s2tr(Y^Td(P1))Y^]+2NPDlogσ2
X^=X−1µxT
Y^=Y−1µyT
한편, 위 식을 R에 대해서 최적화하면 −tr(X^PTY^RT)을 최소화하는 문제로 환원되고 이는 곧 tr((X^PTY^)TR)을 최대화 하는 문제입니다.
max tr(ATR),A=X^PTY^, s.t. RTR=I,det(R)=1
R=UCVT, where USSVT=svd(X^TPTY^),C=d(1,..,1,det(UVT))
그 뒤의 Q의 다른 변수들에 대해서 최적화를 진행하면 아래와 같은 알고리즘을 생성할 수 있습니다.

Unsupervised 3D Link Segmentation of Articulated Objects With a Mixture of Coherent Point Drift
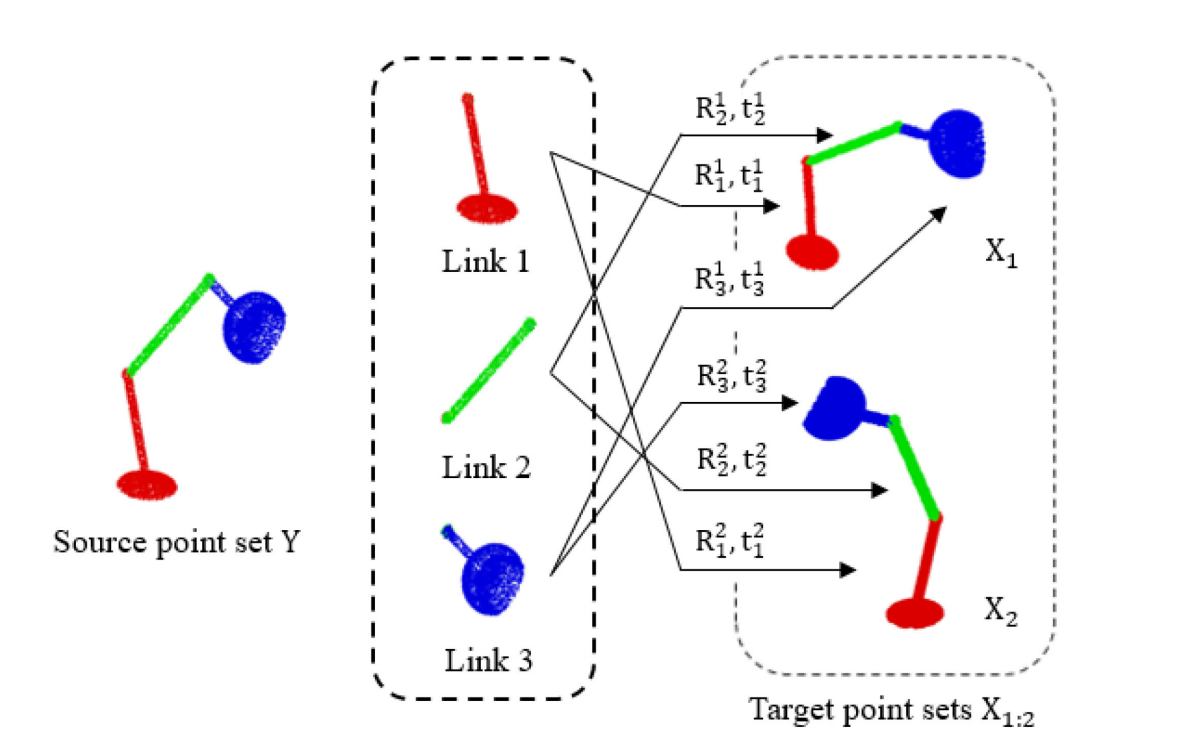
우리의 모델의 목적은 point set의 최적 decomposition과 probability density로 표현되는 transformation을 찾는 것입니다. 위의 그림에서 볼 수 있듯이 CPD에서의 formulation과 비슷하게 Y는 source point set을 나타냅니다. Y의 point set은 K개의 link로 분리가 되어 target point sets X와 매칭이 됩니다. 이때 각 link는 rigid transformation을 통해서 변환되도록 강제합니다.
S: target point sets의 개수
K: decompose 될 link의 개수
N: target point set를 구성하는 point의 개수
M: source point set를 구성하는 point의 개수
X1:S: target point sets
Y: source point set (GMM centroids)
Rsk,R1:S,1:K: k번째 link가 s번째 link로 matching 되는 rotation
tsk,t1:S,1:K: k번째 link가 s번째 link로 matching 되는 translation
Π (M×K matrix) , πij: πij는 i번째 source point가 j번째 link에 속할 확률입니다.
πij=p(Zi=j∣yi): Zi는 latent variable
2. Expectation of the complete negative log-likelihood function
ym과 Zm=k가 주어졌을 때, GMM centroid에 기반한 분포에 의해서 xsn이 생성될 확률은 아래와 같습니다.
p(xsn∣ym,Zm=k,θ)=(2πσ2)D/21exp(−21(σ∣xsn−Rskym−tsk∣)2)=g(ssn,Rskym+tsk,σ2)
여기서, 우리가 최적화 해야 할 objective(Expectation of the complete negative log-likelihood) function은 아래와 같이 표현 될 수 있습니다.
Q(θ∣θ^)=EZ∣X1:S,Y,θ^[logp(X1:S,Y,Z∣θ)]
3. E-step and M-step
(1) E-step
아래는 xsn,ym이 주어졌을 때, Zm=k일 responsibility를 나타냅니다.
T^snmk=p(Zm=k∣xsn,ym;θ^)=∑j=1Kπ^mjg(ssn,R^sjym+tsj,σ^2)π^mjg(ssn,R^skym+tsk,σ^2)
위를 활용해 objective function을 재정리하면 아래와 같습니다.
Q(θ∣θ^)=∑snmkT^snmk[log(M1)+logπmk−2Dlog(2πσ2)−21(σ∣xsn−Rskym−tsk∣)2]
(2) M-step
objective function을 tsk에 대해서 최적화를 진행해주면 아래의 식을 얻을 수 있습니다.
tsk=μskx−R−skμsky
μskx=∑nmT^snmk∑nmT^snmkxsn
μsky=∑nmT^snmk∑nmT^snmkym
위의 식을 objective function에 대입해 tsk에 대한 dependency를 없애주고 각 variables에 대해서 최적화를 진행해줍니다.
이때 σ는 아래와 같은 해를 얻을 수 있습니다.
σ2=∑snmkT^snmkD∑snmkT^snmk(xsn−Rskym−tsk)2
또, Rsk에 대해서는 아래의 optimal problem을 얻을 수 있습니다.
Rsk=argmaxRsktr(AskTRsk),Ask=XskTT^skTYsk
Xsk=Xs−1μskx
Ysk=Y−1μsky
마지막으로 πmk에 대해서 아래의 식을 얻을 수 있습니다.
π=argmaxπ∑snmkT^snmklogπmk s.t.∑kπmk=1
더 나아가, objective function에 아래의 regularization term을 더해줍니다. 우리는 KL divergence를 활용해서 가까운 point 끼기의 π가 비슷해질 수 있도록 규제합니다. 이때, 추가된 항은 π만 영향을 줍니다.
R(Π)=−∑i,j=1MwijDKL(πi∣∣πj)≈−2∑i=1,i=mMwimπiklog(πmkπik)
위의 모든 최적화 작업을 취합해서 알고리즘을 형성하면 아래의 pipeline으로 정리할 수 있습니다.

마치며,
non-rigid transformation에 대해서는 아직 살펴보지 않았지만 당장 필요한 rigid transformation에 대한 학습은 적당히 마무리했습니다. EM과 몇몇 선형대수학, 확률론의 지식을 되짚어가며 의미 있는 시간을 보냈습니다. 앞으로는 이와 관련된 code review를 진행하고 어떻게 하면 저의 연구에 쓸모 있게 변형해낼 수 있을지 고민하고 또 고민하는 것입니다. 번뜩이는 아이디어가 떠오르면 좋겠네요. 다음에 더 fancy 한 생각들로 찾아뵙겠습니다!
