오늘부터 Stable Diffusion 관련 논문을 체계적으로 리뷰하고, 이를 기반으로 한 응용 연구 및 어플리케이션 개발을 본격적으로 시작한다. 석사 졸업 전까지, 될 때까지 밀어붙일 예정이다. 끝까지 파고들어 실질적인 성과로 이어지는 것을 목표로 한다.
처음으로, "High-Resolution Image Synthesis with Latent Diffusion Models"라는 Stable Diffusion의 근간이 된 논문을 리뷰한다. Diffusion 모델의 강력한 샘플링 성능은 인정받고 있지만, 픽셀 공간에서 작동한다는 점은 막대한 계산량과 느린 추론 속도라는 현실적인 한계를 초래한다. 이 논문은 이러한 문제를 해결하기 위해 diffusion 모델을 학습된 latent 공간에서 훈련시키는 Latent Diffusion Models (LDM)을 제안한다.
핵심 기여로는, Autoencoder를 통해 perceptual compression을 수행하고, 그 뒤 latent 공간에서 semantic compression을 진행함으로써 계산 비용을 크게 줄이면서도 높은 품질을 유지하는 트레이드오프를 성공적으로 달성한 점이 있다.
1. 주요 아이디어
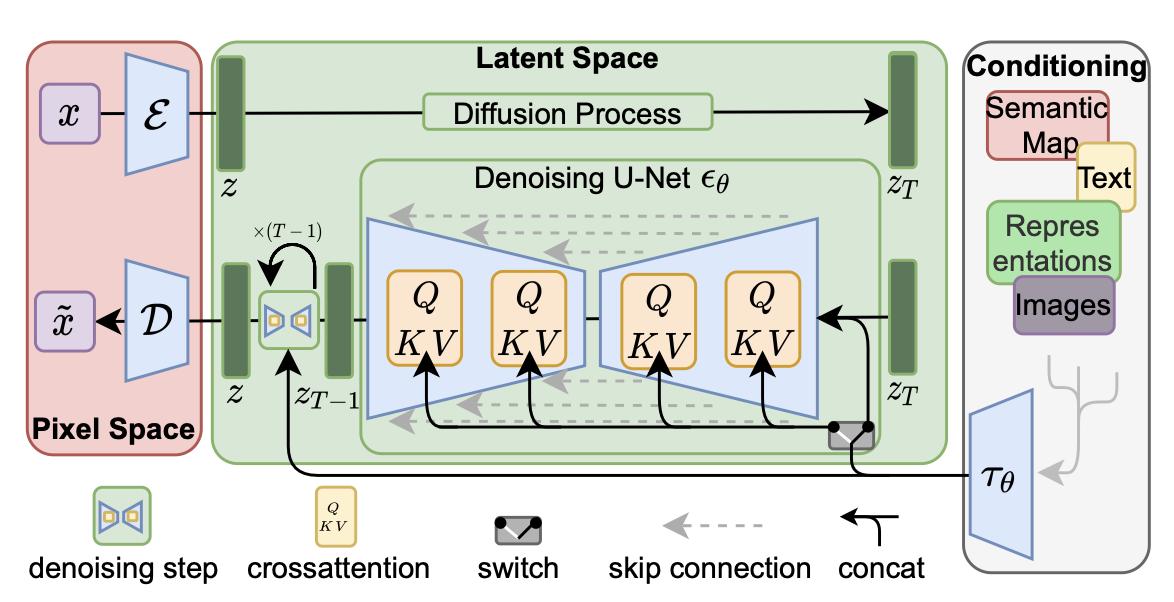
[두 단계 접근 방식]:
- ① 고성능 Autoencoder를 사용해 이미지 → latent로 압축
- ② 해당 latent에 대해 diffusion model을 훈련
- Latent space는 semantic fidelity는 유지하면서도 dimension은 줄어들기 때문에 학습이 훨씬 효율적이다.
- latent representation 위에서 noise prediction loss를 계산.
[Cross-Attention 기반 Conditioning]:
-
UNet에 cross-attention 모듈을 삽입해 텍스트, semantic layout 등 다양한 modality에 대응 가능.
-
이를 통해 Text-to-Image, Layout-to-Image, Super-Resolution, Inpainting 등 다양한 task를 단일 프레임워크 내에서 수행한다.
-
Conditioning 정보는 transformer encoder 를 통해 유입됨.
[Perceptual Loss + Adversarial Patch Loss]:
- L2 loss 기반 pixel reconstruction 대신 VGG 기반 perceptual loss와 PatchGAN 기반 adversarial loss를 사용하여 latent space의 realism 확보.
2. 실험 및 결과 요약
[ImageNet / CelebA-HQ / FFHQ / LSUN]:
- LDM-4, LDM-8 구성에서 기존 pixel 기반 diffusion보다 빠른 수렴과 더 낮은 FID를 기록.
- 예: ImageNet에서 LDM-4-G는 ADM보다 더 적은 파라미터로 더 낮은 FID와 더 높은 IS를 달성.
[Text-to-Image (LAION 400M 기반)]:
- LDM-KL-8 모델은 1.45B 파라미터로 GLIDE, Make-A-Scene 등에 필적하는 성능을 보이며, classifier-free guidance 활용 시 SOTA 수준의 품질 달성.
[Inpainting]:
- Places 데이터셋 기준으로 LDM은 LaMa보다 낮은 FID를 달성하며, object removal과 자연스러운 채움 영역 생성에서 우수한 성능.
[Super-Resolution]:
- Bicubic 및 Real-world degradation scenario(LDM-BSR)를 비교하며 LDM이 더 현실적인 고해상도 복원 결과를 생성함을 시각적으로 입증.
3. 비판
[장점]
- 압축률 vs 정보 손실 사이 최적 균형: 기존 GAN/VQ-Transformer 대비 더 낮은 압축률로도 높은 fidelity 확보.
- 범용성: cross-attention 하나로 다양한 conditional task 커버.
- 개방형 연구: pretrained 모델 및 코드 공개로 reproducibility에 기여.
[한계]
- Sampling 속도는 여전히 GAN보다 느림.
- 재구성 fidelity는 완벽하지 않아, pixel-level 정밀도가 필요한 downstream task엔 부적합할 수 있음.
- 사용된 autoencoder의 bias나 정보 손실은 diffusion 단계의 성능 ceiling으로 작용할 수 있음.
4. 마무리하며...
Latent Diffusion Models(LDM)은 기존의 픽셀 공간에서 작동하던 diffusion 모델이 가지는 막대한 계산 비용과 느린 추론 속도라는 한계를 극복하기 위해, 2단계 압축 전략을 제안한다. 첫 번째 단계는 perceptual compression으로, 이는 단순히 해상도를 낮추는 방식이 아니라, 인간의 시각적 지각(perception)에 기반하여 이미지에서 중요한 의미적 구조만을 유지한 채 나머지 정보를 제거하는 압축 방식이다. 이를 위해 LDM은 사전 학습된 오토인코더(autoencoder)를 활용하여 고해상도 이미지를 latent 표현으로 변환한다. 이 표현은 원래 이미지보다 훨씬 작은 차원을 가지며, 시각적으로 중요한 정보는 유지하면서 계산 효율성을 높이는 특징을 갖는다.
두 번째 단계는 이렇게 얻은 latent 표현 위에서 수행되는 semantic compression, 즉 diffusion 과정을 latent space 상에서 수행하는 것이다. 기존 diffusion 모델들이 고차원 픽셀 공간에서 노이즈를 추가하고 제거하는 과정을 반복했던 반면, LDM은 더 간결하고 정보 밀도가 높은 latent 공간에서 같은 과정을 수행함으로써 연산 자원을 크게 절감한다. 예를 들어, 기존의 DDPM 기반 모델은 고해상도 이미지를 생성할 때 수십 GB 이상의 GPU 메모리와 수십 초의 시간이 필요한 반면, LDM은 1~2GB의 메모리로도 충분히 학습 및 샘플링을 수행하며, 시간 또한 수 초 내외로 단축된다.
이러한 구조는 diffusion 모델의 표현력을 유지하면서도 연산 비용과 시간 측면에서 우수한 트레이드오프를 달성한다는 점에서 큰 의의를 가진다. 결국 LDM은 고해상도 이미지 생성 문제를 실질적인 수준에서 다룰 수 있게 만들며, diffusion 기반 생성 모델의 현실적인 활용 가능성을 획기적으로 확장하는 데 기여한다.
