SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
오늘은 Stability AI가 제작한 SDXL 모델에 대해 집중적으로 살펴보려 합니다. SDXL은 단순히 모델 규모를 키운 것에 그치지 않고, 세밀한 관찰과 엔지니어링 전략을 결합하여 고해상도 이미지 생성 성능을 획기적으로 끌어올린 모델입니다.
특히, 기존 Stable Diffusion 계열 모델들이 가지던 한계(이미지 크기나 비율, 해상도에 따른 품질 저하) 를 면밀히 분석하고, 이를 해결하기 위한 정교한 conditioning 기법들을 도입한 것이 인상적입니다.
이번 리뷰에서는 SDXL의 아키텍처 개선 외에도 입력 이미지에 대한 해상도 및 크롭 영역 정보를 직접 주입하는 방식, 그리고 다양한 해상도와 비율에 대응하는 multi-aspect 학습 전략에 집중해 보고자 합니다. 이러한 방식은 단순한 업스케일링이나 데이터 증강에 비해 훨씬 더 정교한 이미지 제어력과 표현력을 가능케 하는 핵심 요소입니다.
또한, 본 논문은 SDXL 이후의 발전 방향성에 대한 흥미로운 언급도 포함하고 있습니다. 그중 하나가 바로 EDM(Elucidated Diffusion Models)의 도입입니다. 현재 SDXL은 discrete-time diffusion 방식에 기반하고 있으나, continuous-time 기반의 EDM 프레임워크는 더 유연한 샘플링 경로와 효율적인 노이즈 스케줄링을 가능하게 해줄 것으로 기대됩니다. 이와 함께, distillation, text synthesis, Transformer 기반 구조 확장 등도 앞으로의 주요 발전 방향으로 제시되고 있습니다.
1. SDXL이란 무엇인가?
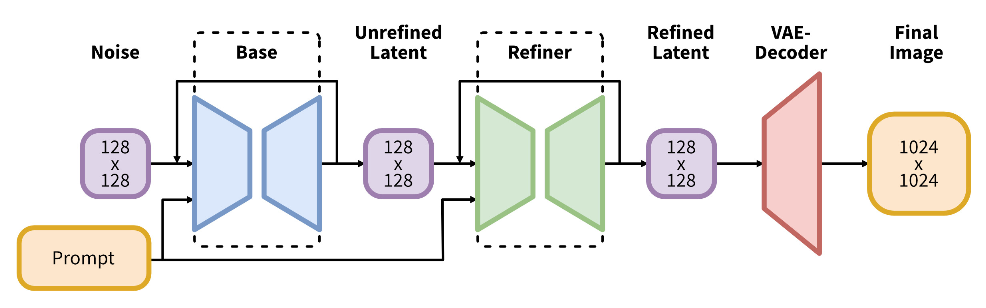
Stable Diffusion은 latent 공간에서의 효율적인 이미지 생성으로 큰 주목을 받았지만, 여전히 고해상도 이미지에서의 품질 저하와 샘플링 속도 한계라는 본질적인 문제를 가지고 있었습니다. 이러한 문제를 해결하기 위해 Stability AI는 SDXL을 설계하며 다음과 같은 핵심 전략을 도입했습니다:
(1) 더 크고 표현력이 풍부한 UNet,
(2) 텍스트 의미 이해를 강화하기 위한 이중 텍스트 인코더 (CLIP ViT-L + OpenCLIP ViT-bigG),
(3) 그리고 고해상도 디테일을 살리기 위한 Refiner 모델의 추가입니다.
전체 구조는 Base – Refiner – VAE Decoder로 구성되며, 이는 Coarse-to-Fine 이미지 생성 전략에 기반합니다. 먼저 Base UNet이 텍스트 조건을 받아 전체 이미지의 윤곽 및 구조를 생성한 후, Refiner UNet이 동일한 latent 공간에서 세부 디테일을 보정하는 방식입니다. 학습도 이 순서에 맞춰 진행되며, Base를 먼저 학습한 후 이를 고정(freeze)하고 Refiner만 별도로 학습합니다.
실제 inference 단계에서도 이러한 분업 구조가 유지됩니다. Base UNet은 많은 sampling step (~50–100)을 통해 의미 있는 구조를 생성하고, Refiner는 적은 step (~10–20)으로 세부 묘사만 빠르게 보완합니다. 이로써 속도와 품질 간 트레이드오프를 절묘하게 조율할 수 있습니다.
SDXL은 cross-attention 기반의 text-to-image diffusion을 기반으로 하되, UNet 내부 구조를 효율적으로 단순화하기 위해 low-level feature block에 transformer block을 집중 배치하는 전략을 채택했습니다. 또한, 텍스트 표현을 풍부하게 하기 위해 CLIP ViT-L과 OpenCLIP ViT-bigG의 중간/pooled feature를 concat하여 UNet에 조건으로 주입합니다. 이로 인해 단순히 큰 UNet을 쓰는 것 이상으로, 텍스트–이미지 정합성(prompt fidelity)과 스타일 표현력이 크게 향상됩니다.
2. 아키텍처 개선: 크고 똑똑한 UNet

SDXL은 기존 Stable Diffusion 계열과 비교하여 모델 크기, 텍스트 인코딩 전략, attention block 배치에 이르기까지 근본적인 구조 개선이 이루어졌습니다. 우선 UNet 파라미터 수는 약 2.6B로, SD 1.5 (860M), SD 2.1 (865M)에 비해 3배 이상 확대되었으며, 이는 모델의 표현력을 비약적으로 증가시킵니다.
특히 주목할 점은 Transformer block의 비선형 배치 전략입니다. 기존 모델들이 각 해상도 단계마다 [1, 1, 1, 1] 식으로 균일하게 attention block을 배치한 반면, SDXL은 [0, 2, 10]이라는 급진적인 구조를 채택합니다. 이는 고해상도 feature map보다는 저해상도 feature 수준에서 더 깊은 표현 학습을 유도하고, 고차원 추상화 표현을 집중적으로 처리하게 만듭니다.
또한 텍스트 인코딩 측면에서도 이중 인코더 구조가 도입되었습니다.
하나는 CLIP ViT-L (기존과 동일) 다른 하나는 OpenCLIP ViT-bigG로, 매우 큰 context dimension(2048)을 갖는 모델입니다. 이 둘은 단순히 병렬적으로 사용하는 것이 아니라, 중간 계층의 텍스트 feature와 pooled feature를 concat하여 UNet의 cross-attention conditioning에 함께 주입합니다.
이러한 설계는 prompt의 의미적 복잡성을 보다 풍부하게 전달하며, prompt fidelity, 스타일 일관성, 디테일한 컨트롤 성능을 향상시키는 핵심입니다.
시각적으로 표현하자면, 텍스트 인코더 두 개가 병렬로 prompt를 처리한 후, 각각의 출력을 가공하여 UNet의 여러 attention layer에 조건으로 주입하는 구조입니다. 이는 기존 SD 모델 대비 더욱 다양하고 정교한 텍스트–이미지 정합성 조절 능력을 제공합니다.
3. Conditioning 기법 개선: Micro-Conditioning
(1) Size Conditioning
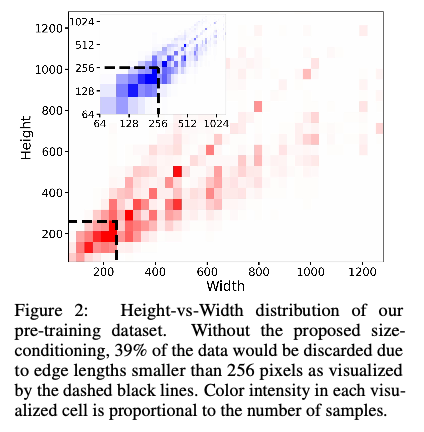
SDXL에서 도입한 Size Conditioning 기법은, 기존 Stable Diffusion이 가진 해상도 제한 문제를 해결하기 위한 구조적 개선 중 하나입니다. 기존 Latent Diffusion Model(LDM)에서는 VAE 인코더와 디코더가 고정된 해상도(예: 512×512)에서만 작동하도록 설계되어 있었기 때문에, 해상도가 낮은 이미지들은 학습에 사용할 수 없었습니다. 특히, 한 변의 길이가 256픽셀 이하인 이미지는 전체의 약 39%에 해당하며, 이들은 훈련 데이터에서 제거되거나 무리하게 업스케일링되어 사용되었습니다. 이러한 방식은 결국 데이터 다양성 저하, 샘플 품질 저하, 혹은 blurry artifact 발생으로 이어질 수 있습니다.

이를 해결하기 위해 SDXL에서는 이미지의 원본 height와 width 정보를 그대로 모델에 주입하는 전략을 사용합니다. 구체적으로는 원본 해상도를 c_size = (h_original, w_original) 형태로 표현하고, 이를 Fourier embedding을 통해 벡터로 변환한 후, timestep embedding과 함께 UNet 내부에 더해주는 방식입니다. 이 조건은 이미지가 어떤 해상도를 가졌는지를 모델이 스스로 인식하게 만들어 주며, 다양한 크기의 이미지에서도 일관된 표현력을 학습할 수 있도록 합니다.
(2) Crop Conditioning

SDXL에서는 학습 시 발생하는 random crop으로 인한 구조 왜곡 문제를 해결하기 위해, Crop Conditioning 기법을 도입합니다. 기존 Latent Diffusion 기반 모델에서는 해상도를 맞추기 위해 이미지를 resize하거나 무작위로 crop하는 과정을 거치게 되는데, 이 과정에서 객체의 일부가 잘려 나가거나, 배경 정보가 지나치게 강조되는 문제가 빈번하게 발생했습니다. 예를 들어 고양이의 얼굴이 잘린 채로 생성되거나, 사람의 팔이 프레임 밖으로 사라지는 등의 부자연스러운 결과가 나타나는 것이 그 대표적인 사례입니다.
이를 해결하기 위해 SDXL은 크롭 좌표 정보를 conditioning signal로 활용합니다. 구체적으로는, 이미지가 얼마나 위쪽에서 잘렸는지(top crop), 얼마나 왼쪽에서 잘렸는지(left crop)를 각각 수치로 표현한 뒤, 이를 Fourier embedding을 통해 벡터화합니다. 이렇게 임베딩된 정보는 기존의 size conditioning, timestep embedding 등과 함께 UNet에 주입되어, 모델이 이미지의 공간적 위치 정보를 인식한 채 학습을 진행할 수 있도록 합니다.
훈련 시에는 다양한 crop 좌표를 랜덤하게 샘플링하여 모델에 학습시키고, inference 시에는 일반적으로 (0, 0)—즉, 이미지가 전혀 잘리지 않았다는 조건을 주어 생성합니다. 이로 인해 SDXL은 중심에 객체가 안정적으로 배치되고, 배경과의 spatial consistency가 잘 유지된 이미지를 생성할 수 있습니다.
(3) Multi-Aspect Ratio 학습

SDXL에서는 다양한 화면 비율(aspect ratio)을 지원하기 위해 Multi-Aspect Ratio 학습 전략을 도입합니다. 일반적으로 text-to-image 모델은 512×512 또는 1024×1024와 같은 정사각형 해상도에서만 학습되기 때문에, 실제 사용자 환경에서 널리 사용되는 16:9, 4:3, 9:16과 같은 다양한 화면 비율을 자연스럽게 다루지 못하는 한계가 존재합니다. 이를 해결하기 위해 SDXL은 bucket-based 학습과 aspect ratio embedding을 결합한 방식을 사용합니다.
훈련 과정에서는 우선 다양한 비율을 가진 이미지들을 미리 정해진 해상도 bucket에 따라 그룹화합니다. 이때 각 bucket은 전체 픽셀 수(예: 약 1024×1024)를 유지하되, height와 width를 비율에 맞게 조정하여 구성됩니다. 예컨대 16:9 bucket은 1152×640, 9:16은 640×1152 등으로 구성됩니다. 학습 시에는 각 training step마다 bucket을 번갈아가며 샘플링하고, 해당 bucket의 해상도로 이미지를 리사이즈한 뒤 size/crop conditioning과 함께 모델에 주입합니다.
전체적인 과정은 알고리즘 1에 요약되어 있듯, 주어진 이미지를 리사이즈한 후, 해상도 비율에 따라 적절한 크롭 좌표를 무작위로 샘플링하고, 이를 Fourier embedding한 c_size와 c_crop으로 변환하여 모델에 함께 주입합니다. 이들을 함께 UNet의 embedding에 추가로 더합니다.
4. Autoencoder 개선
- 기존 SD VAE보다 더 높은 SSIM/LPIPS/PSNR 성능
- 더 많은 배치 크기 + EMA 적용 → reconstruction 품질 향상
Table 3: SSIM = 0.73, LPIPS = 0.88 → 기존 대비 개선
5. Refinement Model
SDXL은 기본적으로 Base UNet만으로 이미지를 생성할 수 있도록 설계되었지만, 생성된 결과물의 디테일, 특히 인물의 얼굴이나 배경, 질감과 같은 고주파 요소에서 품질을 더 높이기 위해 Refinement Model을 추가로 도입합니다. 이 정제 과정은 선택적(optional)으로 적용되며, 필요에 따라 사용 여부를 조절할 수 있는 구조입니다.
Refiner는 일반적인 diffusion 방식처럼 노이즈에서 시작하지 않습니다. 대신, Base UNet이 생성한 latent를 입력으로 받아, 여기에 일정 수준의 노이즈를 인위적으로 다시 추가한 후, 그것을 다시 denoise하는 방식을 사용합니다. 이는 SDEdit(Stochastic Differential Editing) 기법에서 차용된 것으로, 기존 결과에 약간의 노이즈를 섞은 후 이를 복원함으로써 fine detail을 보정하는 전략입니다. 이 때 사용되는 노이즈는 전체 스케줄 중에서도 상위 구간(early noise scale) 일부에만 적용되며, full denoising 과정을 수행하지 않기 때문에 계산 비용도 상대적으로 적습니다.
Refiner 역시 동일한 텍스트 프롬프트 조건과 autoencoder를 공유하며, latent 공간 내에서 고품질 표현을 정제하는 역할을 수행합니다. 결과적으로, Refiner는 Base 모델이 만들어낸 구조 위에 고주파적 디테일을 덧입히는 보정층으로 기능합니다.

실제 논문에서도 Refiner의 효과는 시각적으로 명확하게 제시됩니다. Figure 6을 보면, 같은 프롬프트와 latent에서 시작했더라도 Refiner를 거친 결과는 배경의 질감, 얼굴의 명암, 주변 객체의 정합성에서 훨씬 자연스럽고 깔끔한 출력을 보여줍니다. 특히 Zoom-in 비교를 통해 그 차이는 더욱 두드러지며, 이미지 품질을 한 단계 끌어올리는 데 실질적인 효과를 발휘합니다.
6. 실험 및 성능 비교
-
✅ 사용자 선호도 조사 (17,153회 비교)
- SDXL (with refiner) 48.4%, SDXL base 36.9% → 총 85.3% 압도적 우세
-
📉 FID/CLIP은 오히려 SDXL이 낮음 → 인간 평가와 지표 불일치
Fig. 9~12 참조: Midjourney, DALL-E2, Bing Creator 비교
7. 한계 및 향후 과제
우선, 현재 SDXL은 Base UNet과 Refiner로 구성된 two-stage 구조를 기반으로 최상의 결과를 생성합니다. 하지만 이는 추론 시 두 개의 대형 모델을 동시에 메모리에 로드해야 하므로 접근성과 샘플링 속도 측면에서 비효율적이라는 단점이 있습니다. 향후 연구에서는 Refiner 없이도 유사하거나 더 나은 품질을 낼 수 있는 단일 단계(single-stage) 모델 설계를 목표로 삼고 있다고 합니다.
또한, 텍스트 렌더링 성능 향상 역시 중요한 과제로 언급됩니다. 현재 OpenCLIP ViT-bigG와 같은 대형 텍스트 인코더를 사용하여 기존보다 나은 성능을 보이지만, 여전히 긴 문자열이나 글자 단위 표현(text rendering)은 부족합니다. 이를 보완하기 위한 방안으로는 byte-level tokenizer의 도입, 혹은 단순히 모델 스케일을 더 키우는 방식이 제안됩니다.
모델 아키텍처 측면에서는, 본 연구 초기에는 UViT나 DiT와 같은 Transformer 기반 UNet 구조 실험도 이루어졌으나 즉각적인 이점을 얻지는 못했습니다. 다만, 하이퍼파라미터를 조정하거나, 스케일을 확장하면 향후에는 Transformer-dominant 구조로도 성능 향상을 이끌 수 있을 것으로 보고 있습니다.
또한, SDXL은 기존 모델 대비 품질은 향상되었지만, 추론 비용(VRAM, 시간)이 증가한 문제가 있습니다. 이를 해결하기 위해, 향후 연구에서는 distillation 기반 경량화 및 샘플링 가속화 기법에 집중할 예정이라고 합니다. 예로는 guidance 기반 경량화, knowledge distillation, progressive distillation 등이 제시됩니다.
마지막으로, SDXL은 현재 discrete-time diffusion 기반으로 학습되며, 고품질 출력을 위해 offset noise 기법을 필요로 합니다. 이에 따라 향후에는 EDM(Elucidated Diffusion Models)과 같은 continuous-time 기반 diffusion으로 전환하는 것도 유망한 대안으로 제시됩니다. 이러한 방식은 더 유연한 noise scheduling과 빠른 샘플링을 가능하게 하며, 모델 구조를 간결하게 만드는 데에도 기여할 수 있습니다.
결론적으로, SDXL은 현재 성능에 만족하지 않고, 단일 스테이지 구조, 텍스트 렌더링 개선, Transformer 구조 실험, distillation 최적화, continuous-time 모델로의 전환 등 다양한 방향으로 후속 연구를 명확하게 제시하고 있다는 점에서, 연구적 확장성과 산업적 실용성을 동시에 겨냥한 프레임워크라 할 수 있습니다!
Stability AI의 연구를 보며 상업화 팀들이 실제 어떤 문제를 해결하려 하는지 엿볼 수 있어서 좋았습니다. 특히 다양한 관점에서 문제를 정성적으로 인식하고, 그걸 input을 control하는 방식으로 풀어내는 걸 보면서 여러모로 인사이트를 많이 얻었습니다. EDM 얘기가 나오는 것도 괜히 반가웠는데, 최근 연구에 제가 썼던 방식이기도 해서 (arXiv:2506.04283) 잠깐 반가운 지점이 있었네요. 아무튼 앞으로 Stable Diffusion 쪽은 좀 더 팔로업해볼 생각입니다!
