Neurips Accept 그리고 zero-shot style transfer에 관하여..?!
0. 시작하며
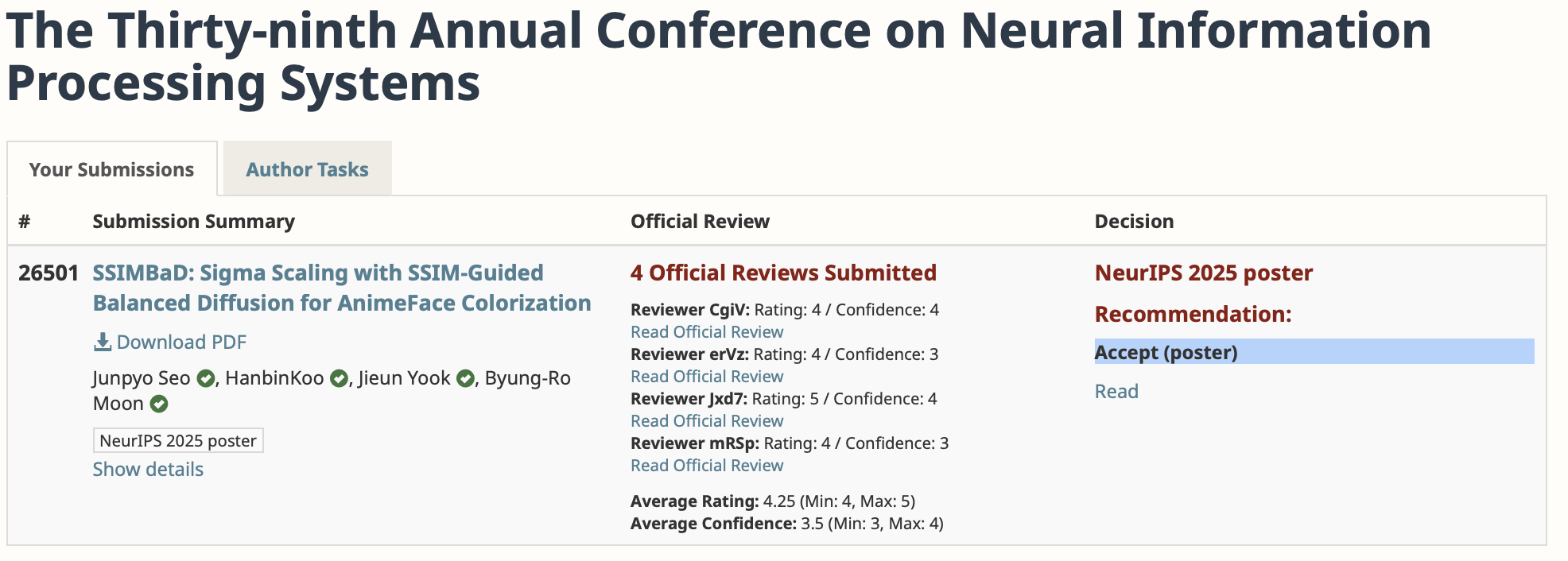
제가 참여한 논문이 세계최고의 AI 학회 Neurips에 Accept 되어 영광입니다.
연구주제는 reference image의 style을 활용해서 sketch image의 내부를 채색하는 task 였습니다. 저희가 제안한 모델이 타-SOTA 모델 대비 우수한 FID, SSIM, PSNR을 기록하여 논문으로서 가치를 인정 받을 수 있게 된 것 같습니다. 아래의 그림을 참고하면 어떤 task를 진행했는지 더 직관적으로 알 수 있습니다. 한마디로, reference image + style image = output image가 되는 network를 디자인한 연구라고 보면 될 것 같습니다.

한편, rebuttal과정에서 아래와 같은 advice를 받아 이를 논문에 반영하고자 합니다.

[1] Alaluf, Yuval, et al. "Cross-image attention for zero-shot appearance transfer." ACM SIGGRAPH 2024 Conference Papers. 2024.
[2] Zhou, Yang, et al. "Attention distillation: A unified approach to visual characteristics transfer." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
[3] Hertz, Amir, et al. "Style aligned image generation via shared attention." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
위의 논문을 차례대로 읊어보면서 zero shot으로 feeding했을 때와 저희 모델과 어떤 차이가 발생하는지 추가실험을 진행하려고 합니다. 그리하여 오늘은 위에 명시했던 zero-shot style transfer을 진행한 논문 3개를 살펴보고자 합니다.
1. Cross-image attention for zero-shot appearance transfer

위와 같이 structure와 appearance가 정의 되어있을때 appearance의 스타일을 충분히 반영해서 structure을 재구성하는 task입니다. 이들은 Cross-Image Attention, Appearance Transfer, Attention Map Contrasting, Appearance Guidance, AdaIN 등의 기법을 활용했습니다.
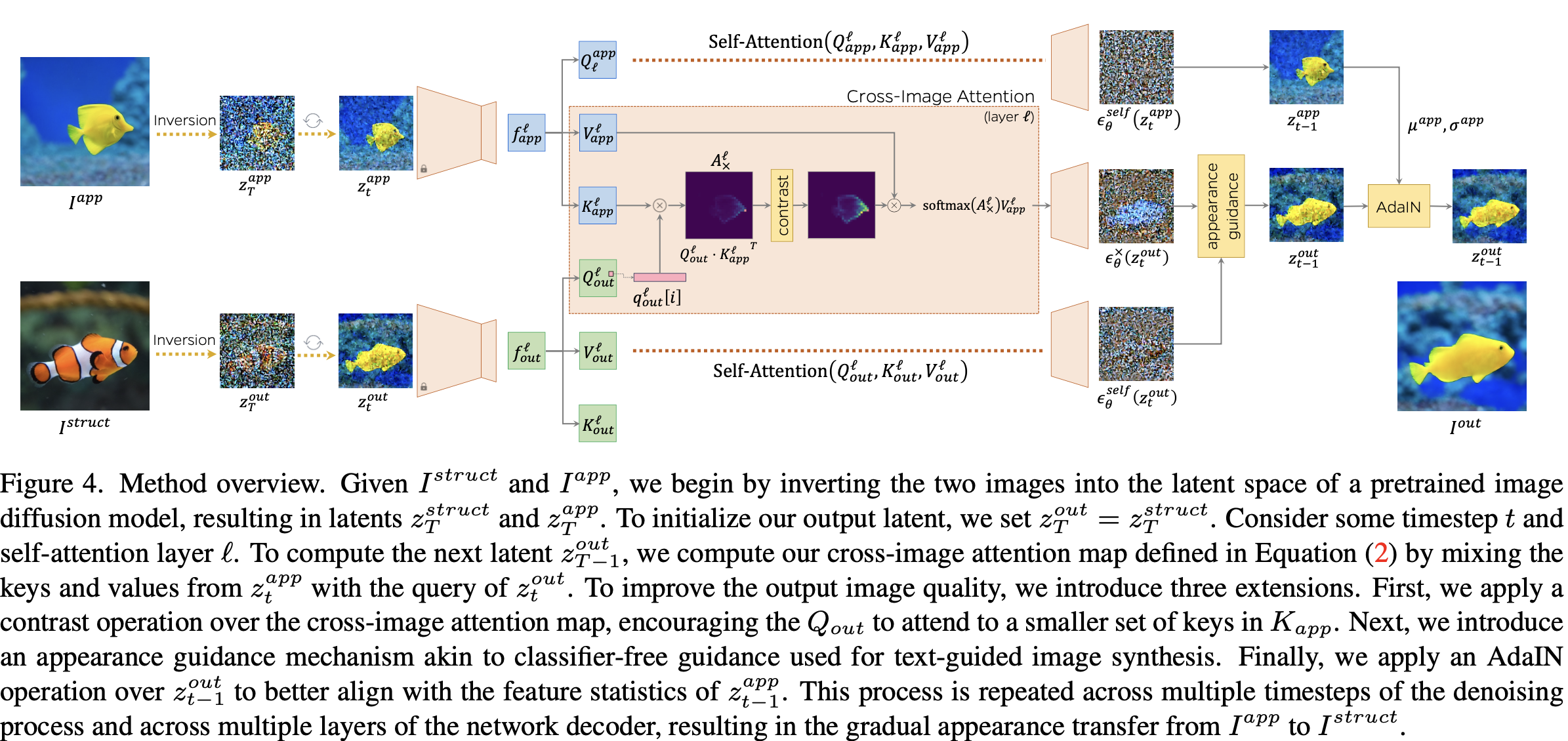
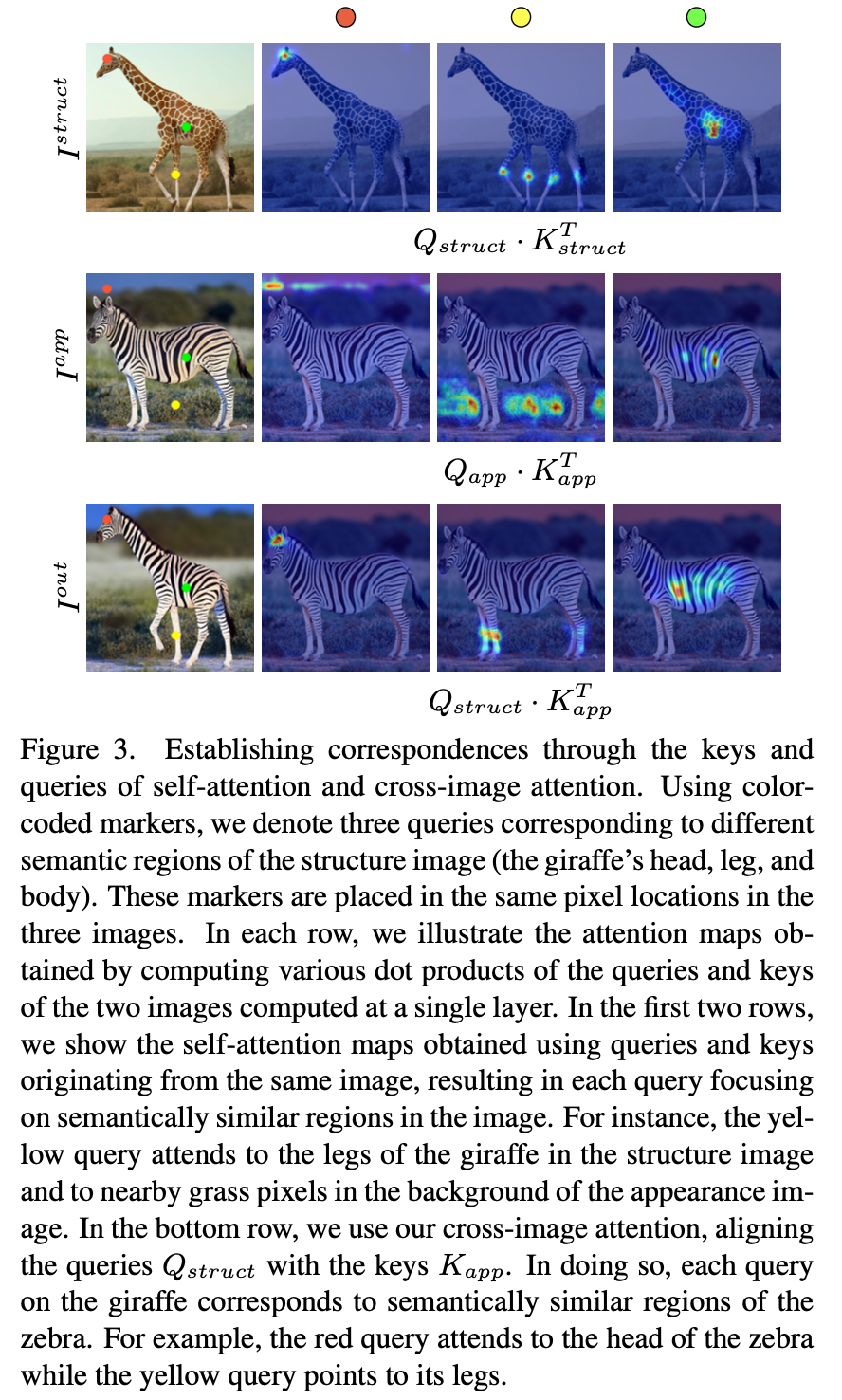
위의 그림과 같이 실제 structure의 포인트에 대한 appearance의 correlation을 계산할 수 있습니다. 바로, structure의 포인트를 query로 하고 appearance를 key, value하여 attention map을 계산하는 것이죠. 해당 attention map에서 query 포인트에 의미론적으로 해당되는 appearance 상의 지점에서 높은 시그널을 보이는 것을 확인할 수 있습니다.
그럼, 각 기법들을 알아보겠습니다.
Cross-Image Attention
- 핵심 아이디어: 구조 이미지(structure image)의 query와, 스타일/외형 이미지(appearance image)의 key, value를 결합해 attention을 계산.
- 역할: 구조는 유지하면서 appearance의 시각적 특성이 semantic correspondence를 통해 매핑됨.
- 의의: 전통적 style transfer가 전역적(Global) 스타일 변환에 치중한 반면, 이 접근은 semantic region 단위의 appearance 대응을 가능하게 함.
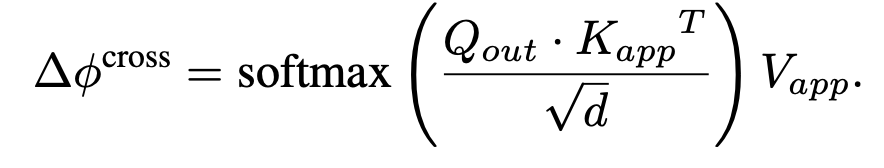
Appearance Transfer
- 방법: Latent space inversion 후, denoising 과정에서 cross-image attention을 적용해 구조와 외형을 통합.
- 특징: 학습이나 최적화 과정 없이 zero-shot으로 동작.
- 효과: 다른 크기·형태의 객체 간에도 appearance transfer 가능 (예: 얼룩말의 무늬를 기린의 몸에 적용).
Attention Map Contrasting
- 문제: cross-image attention만 사용하면 query가 appearance 이미지 전체에 퍼져 artifact 발생.
- 해결: contrast 연산으로 attention map의 분산을 키워 특정 영역에 집중하도록 유도.
- 효과: semantic하게 일치하는 부분만 더 선명히 대응시켜 품질 개선.
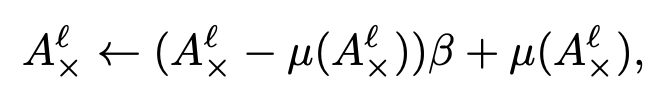
베타의 크기를 조절해가면서 contrast의 강도를 조절하는 것 같습니다. 논문에서도 self attention과 다르게 cross attention은 unfocused attention map인 속성에 대해서 언급을 했었죠. 그래서 constrast 기법을 활용해서 아래의 다섯번째 column에 있는 것처럼 의미있는 point에만 weight를 더 두도록 한 것 입니다.

Appearance Guidance
- 문제: Classifier-free guidance를 appearance transfer에 적용.
- 방법: self-attention 기반 noise 예측과 cross-image attention 기반 noise 예측을 혼합.
- 효과: Output이 target appearance 분포의 더 밀도 높은 영역으로 수렴해 plausibility 상승.
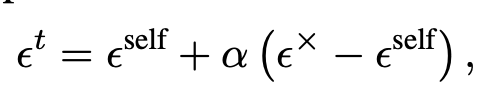
AdaIN (Adaptive Instance Normalization)
- 문제: Output과 appearance image 간 색상 분포 차이 발생.
- 방법: AdaIN으로 latent 통계(평균, 분산)를 맞춰 색감과 texture alignment 수행.
- 보완책: 객체 크기 차이로 인한 효과 감소를 막기 위해 foreground mask 기반 적용.
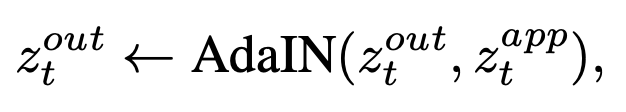
2. Attention distillation: A unified approach to visual characteristics transfer

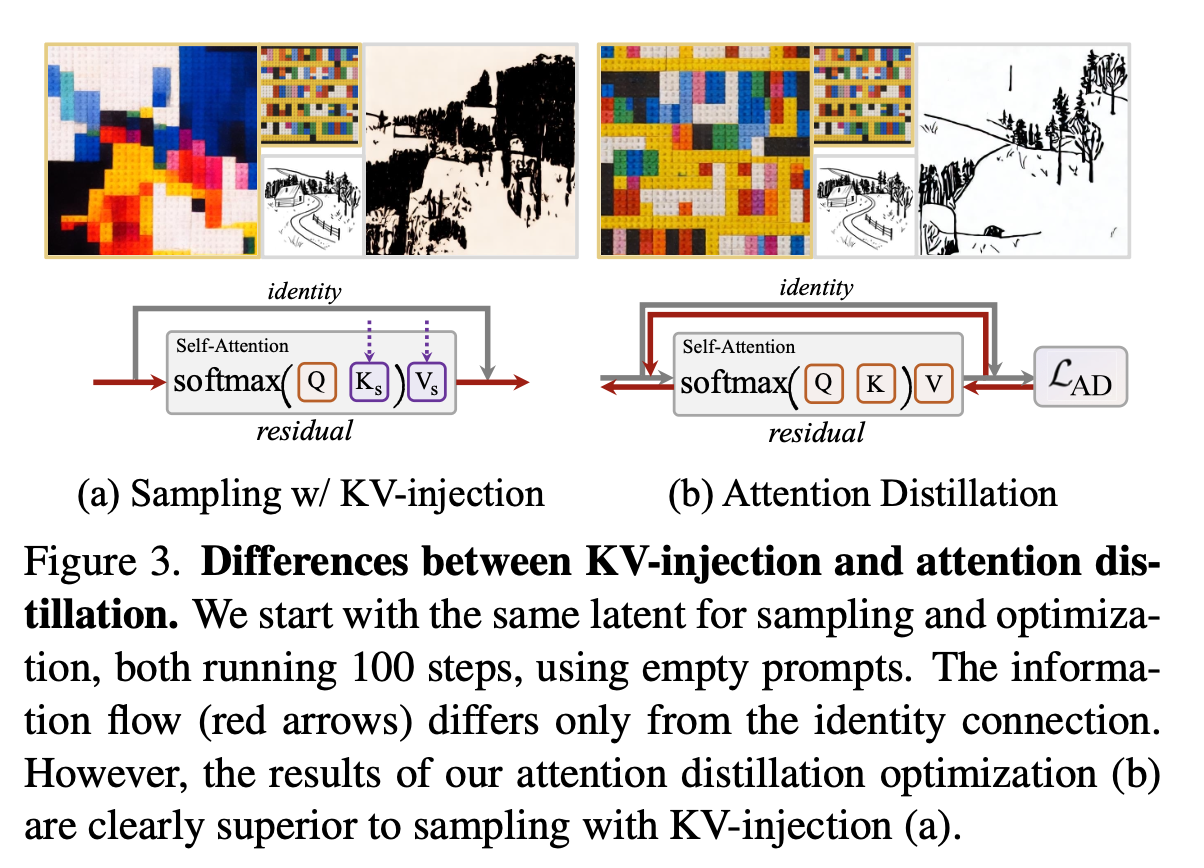
역시 zero-shot (train-free) 모델입니다. 기존 KV-injection 기반 스타일/텍스처 전이는 디테일 손실과 구조 불안정 문제가 발생합니다. 그 이유로는 에러 누적, 도메인 갭, 네트워크 아키텍처 한계를 생각해볼 수 있었죠. 본 논문에서는 이들을 해결하고자, Attention Distillation Loss, Content-preserving Optimization, Attention Distillation Guided Sampling, Improved VAE Decoding을 제안했습니다.
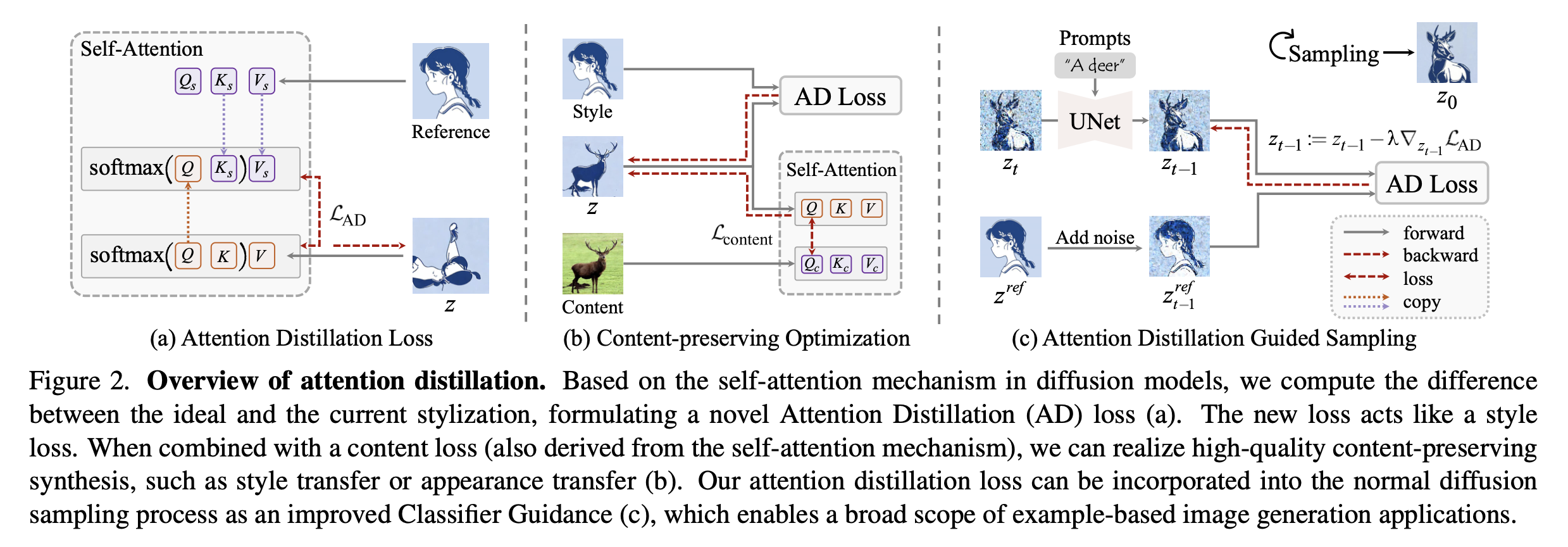
Attention Distillation Loss
문제:
- 기존 KV-injection 기반 방법은 residual branch에서만 작동 → 정보가 identity connection에 묻혀 스타일 디테일 전이가 불완전함.
- 결과적으로 reference의 질감·스타일을 충분히 재현하지 못함.
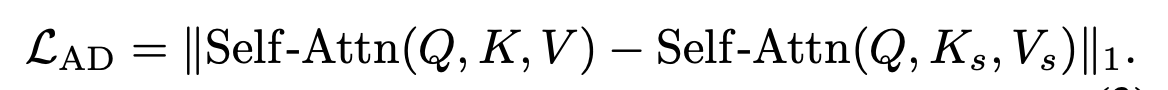
방법:
- 참조 이미지의 KV 특징을 target의 Q에 재집계하여 ideal stylization output을 계산.
- Target branch의 실제 attention output과의 L1 차이를 Attention Distillation(AD) loss로 정의.
- Backpropagation을 통해 latent를 직접 최적화 → 정보 흐름이 residual뿐 아니라 identity connection까지 반영.
효과:
- Target Q와 참조 Ks 간의 차이가 점점 줄어들어 attention 매칭 정확도 개선.
- Reference의 스타일과 텍스처가 더 선명하고 충실하게 재현됨.
Content-preserving Optimization
문제:
- 단순히 스타일 전이만 하면 원본 콘텐츠 구조(content structure)가 왜곡되는 문제 발생.
방법:
- AD loss로 스타일/텍스처 전이를 유도하면서,
- 추가로 Content loss를 도입: target Q와 content reference Qc의 L1 차이를 최소화.
- 최종 목적 함수:
효과:
-
스타일과 텍스처를 유지하면서도, 콘텐츠 구조가 보존됨.
-
즉, 사람 얼굴이나 사물 형태가 유지된 채로 원하는 스타일로 전환 가능.
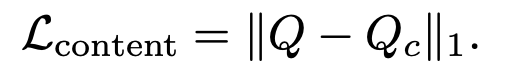
Attention Distillation Guided Sampling
문제:
- Backpropagation 기반 최적화는 시간이 오래 걸림.
- 기존 Classifier Guidance는 텍스트 조건부 생성에는 유용하지만 appearance transfer와의 결합은 부족함.
방법:
- Diffusion sampling 단계에서 AD loss 기반 에너지 함수를 추가하여 샘플링 방향을 조정.
- DDIM 업데이트식에 gradient 항을 삽입, Adam optimizer로 guidance strength를 자동 관리.
- Content loss도 추가 가능하여 구조 보존 강화.
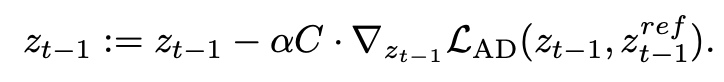
효과:
- 샘플링 속도 가속화 (최적화보다 빠름).
- 다양한 조건(ControlNet, T2I 프롬프트 등)과 결합 가능.
- Output이 reference appearance에 더 일관되게 수렴.
Improved VAE Decoding
문제:
- Stable Diffusion의 VAE는 고주파(high-frequency) 디테일을 손실 → 텍스처 합성 시 뚜렷한 디테일 부족.
방법:
- 참조 이미지를 이용해 VAE 디코더를 L1 loss로 몇 스텝 파인튜닝.
- Reconstruction 품질을 개선하여 디코딩 단계의 손실을 줄임.
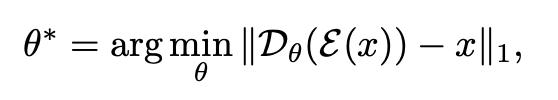
효과:
- 복원 이미지에서 디테일 선명도 향상.
- 텍스처 합성이나 초고해상도 작업에서 더 자연스럽고 정밀한 출력 확보.
3. Style aligned image generation via shared attention
본 논문에서는 Shared Self-Attention, Adaptive Instance
Normalization (AdaIN) 기반 쿼리/키 정규화, Partial Attention Sharing, Diffusion Inversion 기반 참조 이미지 활용 을 진행했습니다.

Shared Self-Attention
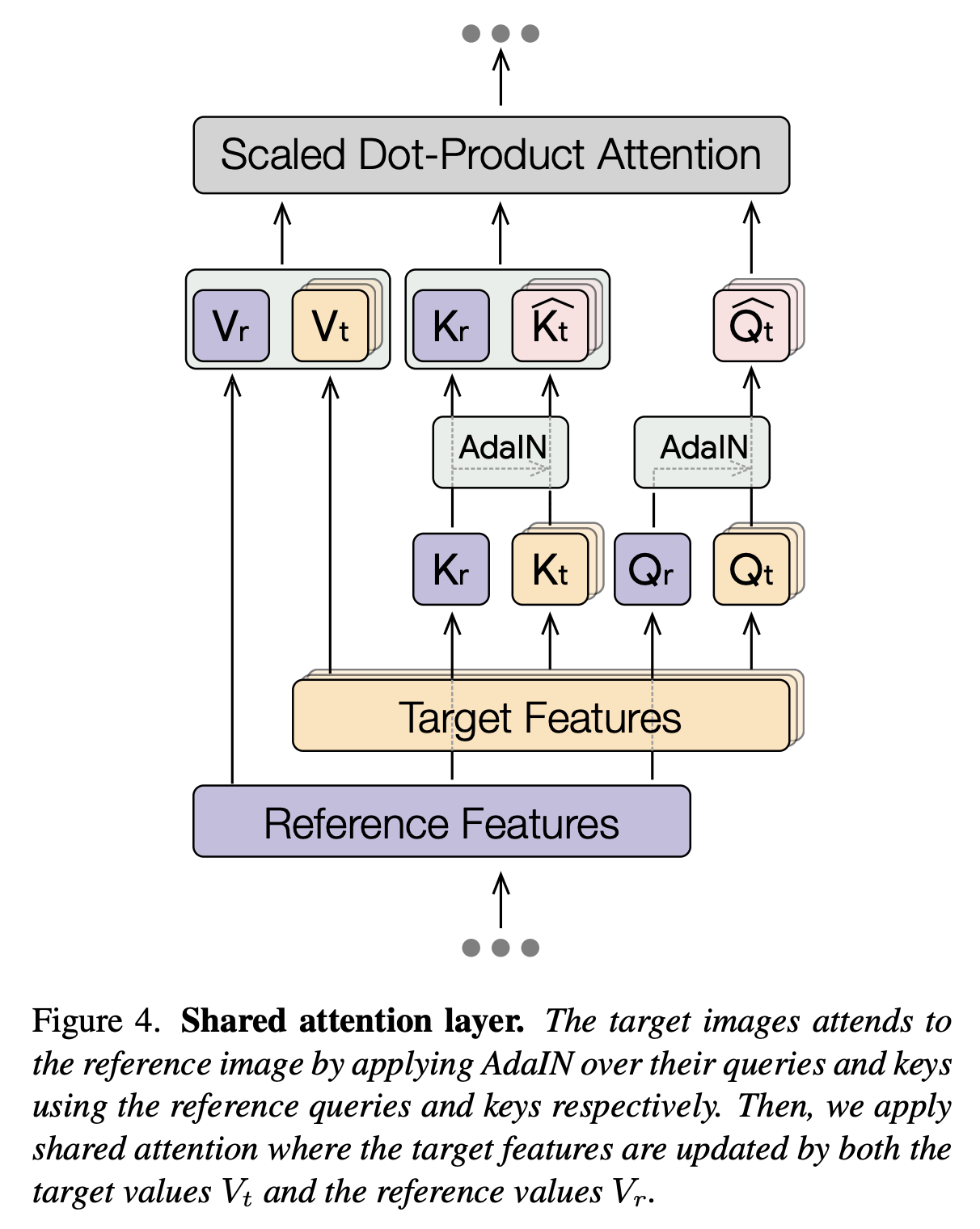
문제:
- 기존 T2I 모델은 동일한 스타일 프롬프트를 사용해도 이미지마다 스타일 해석이 달라져 일관성이 무너짐.
방법:
- 생성 과정의 Self-Attention을 공유하여, 각 이미지가 하나의 참조(reference) 이미지의 스타일 정보를 참조하도록 설계.
- Target 이미지의 Query/Key를 Reference 이미지의 Query/Key로 AdaIN(Adaptive Instance Normalization) 으로 정규화 후, 공유 Attention을 적용.
효과:
- 이미지 세트 전반에 걸쳐 스타일 일관성 확보.
- 프롬프트와 구조는 다양하지만 동일한 스타일 속성을 반영.
Adaptive Instance Normalization (AdaIN) 기반 쿼리/키 정규화
문제:
- 단순히 Attention을 공유하면 콘텐츠 누출(content leakage) 과 스타일 붕괴(collapse) 문제가 발생.
방법:
- Target 이미지의 Query/Key를 Reference 이미지의 Query/Key와 AdaIN으로 맞춤.
- 즉, Target Query/Key의 통계량을 Reference의 분포에 맞게 정규화.
효과:
- 콘텐츠 혼입 방지 및 다양성 유지.
- Reference 스타일은 강하게 전달되지만, 개별 Target은 독립된 콘텐츠를 유지.

Partial Attention Sharing
문제:
- 모든 Self-Attention 레이어를 공유하면 스타일은 강하지만, 다양성이 부족하고 이미지 간에 색상/콘텐츠가 섞이는 현상 발생.
방법:
- 전체 레이어 중 일부에만 Attention 공유를 적용 → 제어 가능한 스타일 일관성 확보.
효과:

- 공유 레이어 수를 조정하여 스타일-다양성 트레이드오프 조절 가능.
- 더 적게 공유할수록 다양성이 커지고, 많이 공유할수록 스타일 일관성이 커짐.
Diffusion Inversion 기반 참조 이미지 활용
문제:
- 단순 텍스트 프롬프트만으로는 특정 스타일을 정확히 재현하기 어려움.
방법:
- DDIM Inversion으로 참조 이미지를 잠재공간으로 투영한 뒤, 새로운 프롬프트와 함께 Attention Sharing을 적용.
효과:
- 단일 참조 이미지로부터 제로샷 스타일 전이 가능.
- 다양한 새로운 콘텐츠도 동일한 스타일로 생성.
