Review on "IP-Adapter"
IP-Adapter: Text Compatible Image Prompt Adapter for
Text-to-Image Diffusion Models
을 리뷰해보겠습니다.
1. 고전적/기존 방법의 한계
-
텍스트 프롬프트의 한계: 강력한 T2I 확산모델이 있어도 원하는 이미지를 얻으려면 프롬프트 엔지니어링이 까다롭고, 텍스트만으로 복잡한 장면/개념을 정확히 전달하기 어렵다. 그래서 “이미지 프롬프트”가 자연스러운 대안으로 부상.
-
직접 파인튜닝 기반 이미지 프롬프트의 문제: SD Image Variations, unCLIP처럼 텍스트 조건 모델을 이미지 임베딩으로 재학습하면
- 텍스트 생성 능력을 잃기 쉽고,
- 계산비용이 크며,
- 파생 커스텀 모델로의 재사용성이 떨어지고,
- ControlNet 같은 구조 제어 도구와 비호환 문제가 생긴다.
-
간단한 어댑터류의 한계: T2I-Adapter(Style), Uni-ControlNet(Global) 등은 CLIP 이미지 임베딩을 텍스트 임베딩과 단순 결합해 투입하지만, 텍스트에 맞춰 학습된 기존 cross-attention의 K/V 가중치만 사용하면 이미지-특이 정보가 소실되어 거친 스타일 제어 수준에 그치기 쉽다.
2. 핵심 인사이트
- 핵심 인사이트: 문제의 핵심은 cross-attention. 기존 UNet의 cross-attn은 “텍스트” 특징에 맞춰 학습된 K/V 가중치를 가진다. 여기에 이미지 특징을 억지로 합치면 이미지 고유 정보가 약화된다. ⇒ 텍스트와 이미지의 cross-attention을 분리(Decoupled) 해야 한다.
- IP-Adapter 설계:
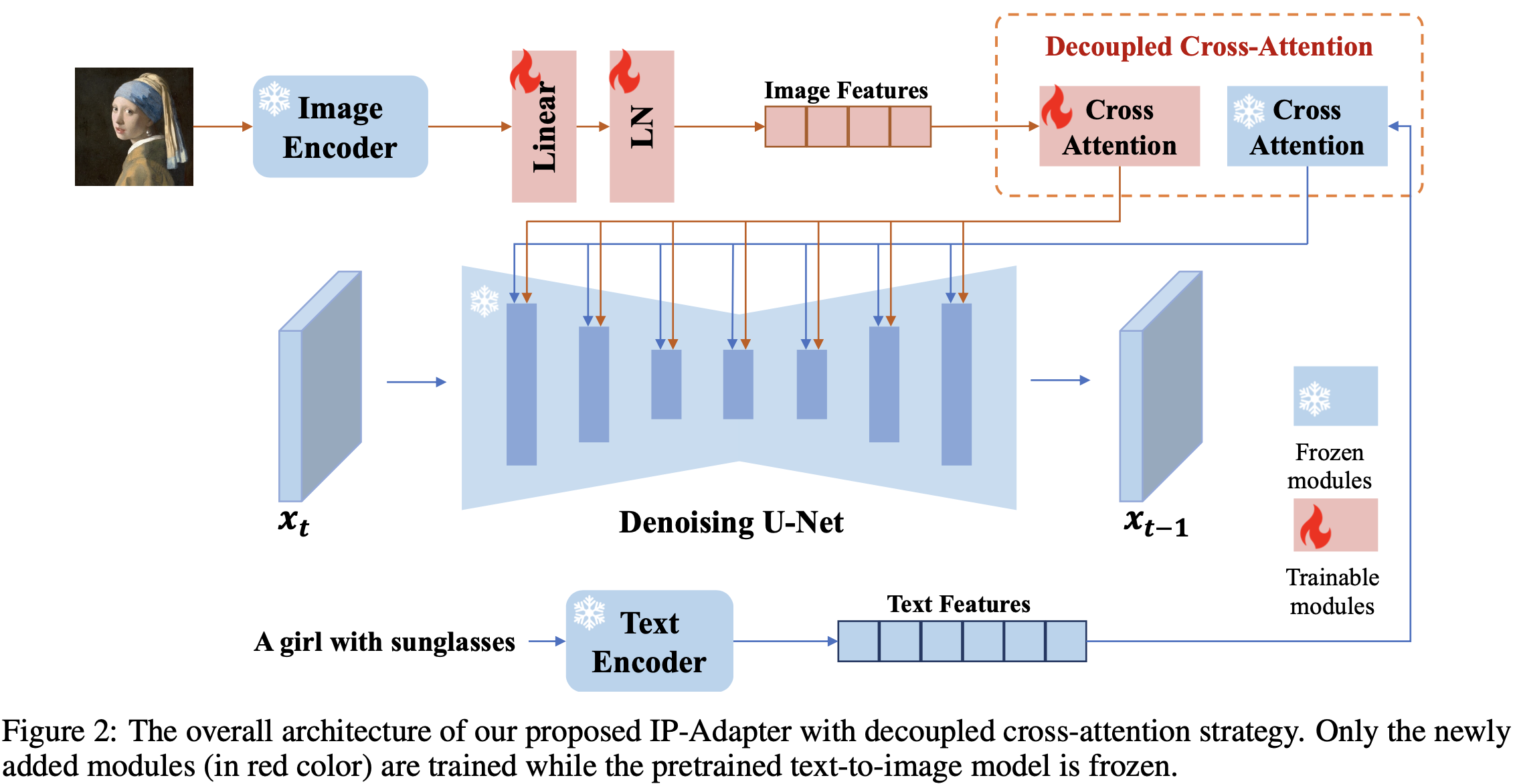
-
CLIP 이미지 인코더(동결)에서 글로벌 이미지 임베딩을 뽑고, 작은 프로젝션 네트워크(Linear+LN) 로 N(=4)개의 토큰 시퀀스로 변환.
-
SD v1.5의 모든 cross-attn 층마다 이미지 전용 cross-attn을 하나씩 추가. 쿼리 는 공유하고, 이미지용 만 추가로 학습(초기값은 텍스트용 로부터 초기화). 최종 출력은 텍스트-attn + 이미지-attn의 합. 기존 UNet은 완전 동결. 파라미터 증가는 약 22M로 경량.
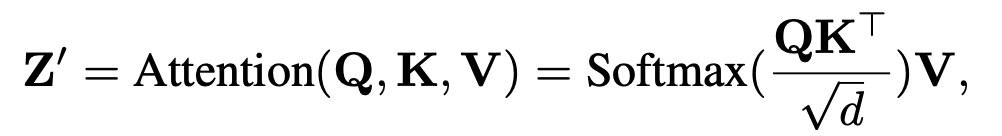
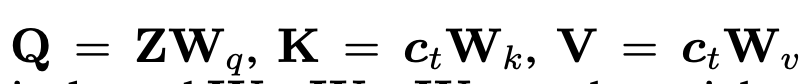
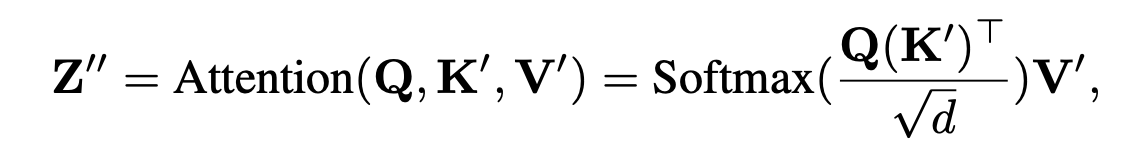
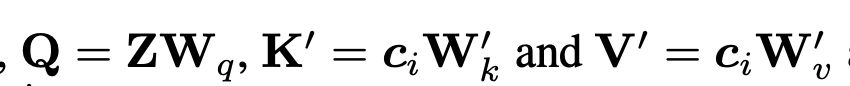
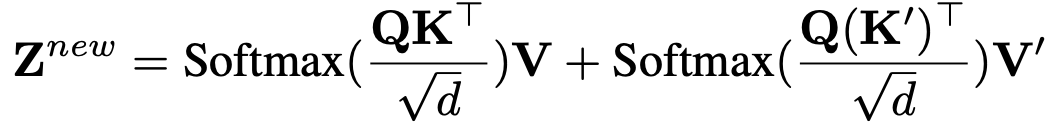
- Classifier-free guidance를 이미지 조건에도 적용할 수 있도록 학습 시 이미지/텍스트 조건을 확률적으로 드롭. 추론 시에는 이미지 기여도를 조절하는 λ 스케일을 제공(식 (8)) → 텍스트/이미지 멀티모달 프롬프트의 가중 조절이 가능.
3. 실험 결과
-
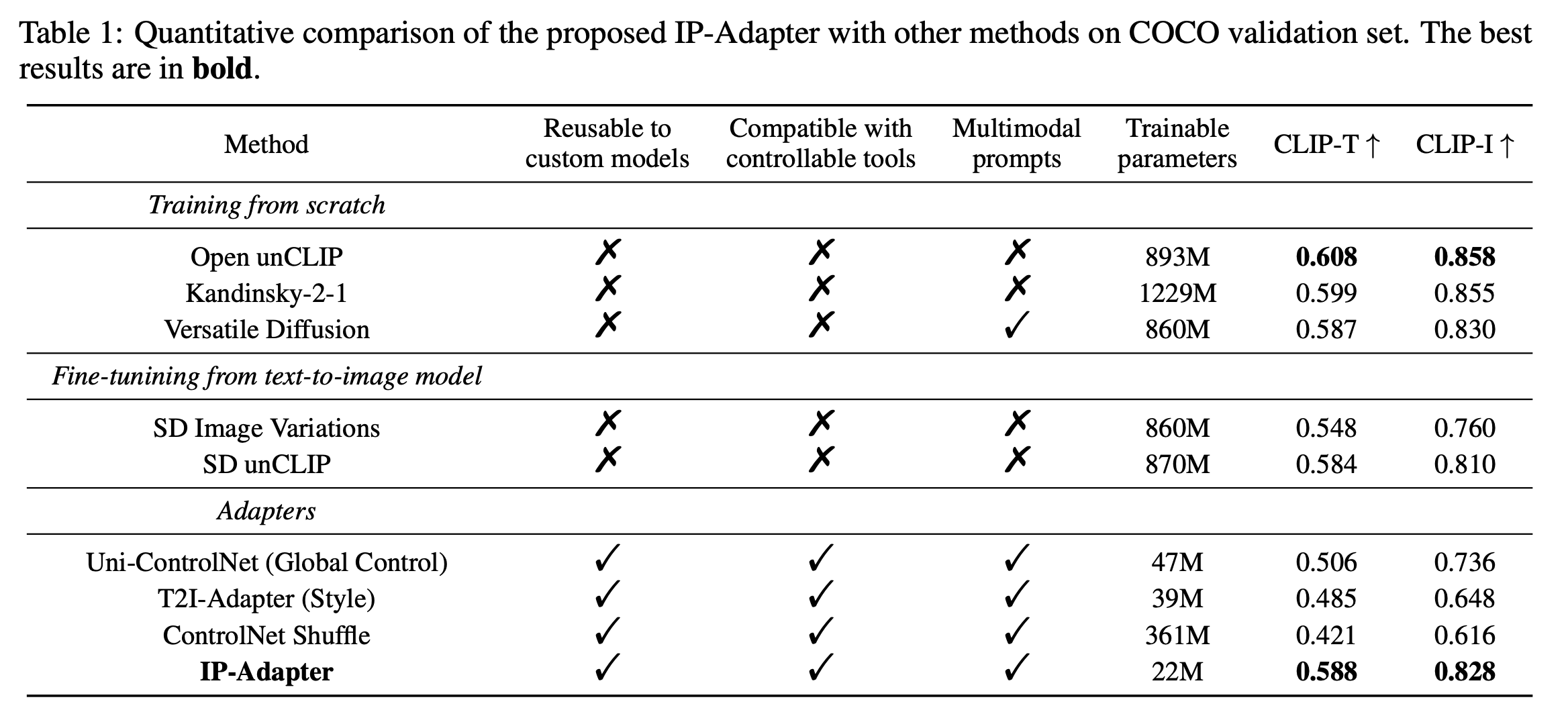
정량 지표(COCO val): CLIP-T/CLIP-I 기준으로,
- IP-Adapter(22M) 는 T2I-Adapter(39M), Uni-ControlNet(47M) 같은 다른 어댑터류보다 우수,
- SD Image Variations/SD unCLIP 같은 대규모 파인튜닝 모델(∼860–870M) 과도 비슷하거나 더 좋음.
- 더 나아가 Open-unCLIP/Kandinsky/Versatile Diffusion 등 처음부터 학습한 대형 모델(∼0.9–1.2B) 과도 근접한 성능을 보인다. 경량+경쟁력이 포인트.
- 정성 비교:

-
다양한 스타일/도메인에서 이미지 정합성과 품질이 우수.
-
ControlNet/T2I-Adapter 등 구조 조건과 그대로 호환되어 스케치/포즈/에지 등과 동시 제어 가능.
-
멀티모달 프롬프트(이미지+텍스트)에서 텍스트로 속성/배경/장면을 세밀하게 수정 가능.
-
Inpainting / image-to-image 도 이미지 프롬프트로 자연스럽게 수행.

-
재사용성: 한 번 학습한 IP-Adapter를 SD v1.5 파생 커스텀 모델(Realistic Vision, Anything v4, ReV Animated 등) 에 그대로 꽂아 사용 가능. SD v1.4에도 작동. → 생태계 호환성이 매우 높음.
-
요약된 이점: (i) 경량(22M), (ii) 원본 모델 동결 → 안전/안정, (iii) 텍스트 기능 보존 + 멀티모달 가능, (iv) ControlNet 등과 조합 가능, (v) 커스텀 파생모델에 재사용 용이.
4. Ablation 검증
-
Decoupled Cross-Attention의 필요성(그림 10):
단순 결합(이미지+텍스트 특징을 합쳐 기존 cross-attn에 투입) 대비, 분리형(decoupled) 이 품질/참조 정합성 모두 크게 향상. 즉, 이미지 전용 K/V를 따로 두는 설계가 핵심 기여임을 입증. -
글로벌 vs 세밀(파인-그레인드) 특징:
CLIP 글로벌 임베딩 기반은 다양성/유연성이 좋지만 세밀 정보가 일부 부족할 수 있음. 반대로 세밀 특징(그리드 feature + 16 learnable query 토큰) 을 쓰면 참조 일치도가 더 높아지나 공간적 구조를 더 강하게 모사해 다양성이 줄 수 있음. 필요 시 텍스트나 구조 조건과 함께 다양성 보완 가능.
5. 한계
- 정체성 일치(subject fidelity)의 한계: 본 방법은 콘텐츠/스타일 유사 이미지는 잘 만들지만, DreamBooth / Textual Inversion처럼 특정 주체를 강하게 고정하는 수준의 일관성에는 미치지 못한다(결론 섹션).
- CLIP 의존성: 이미지 조건은 CLIP 임베딩 정렬 품질에 의존. 레어 도메인/분포 밖 데이터에서는 표현 손실 가능. (본문 전반의 설정에서 암시)
- 전역 특징 기본 설계: 기본형은 글로벌 임베딩 중심이라 세밀한 레이아웃/구조 복제는 제한—필요 시 세밀 특징 변형이나 ControlNet 등 구조 조건 병용이 사실상 필수.
- 학습 비용은 ‘풀 파인튜닝 대비’ 작지만: 22M만 학습해도 100만 스텝/8×V100로 학습(ZeRO-2). 재현을 위한 리소스는 여전히 필요.
