


오전부터 Workshop on Embodied and Safe-Assured Robotic Systems에 대한 키노트 세션이 있었다. 아래의 목차로 세션이 진행되었다. 각 세션은 30~45분 길이로 진행했다.
[1] The Advantages of Using Scenarios as Part of the Specification in Automated Driving | Dr. techn. Sinan Hasirlioglu
[2] Testing and Evaluation of Autonomous Driving Systems: From Simulated to Real-world Test Environments | Andrea Stocco
[3] Vision-Language-Action (VLA) Models | Sergey Levine
[4] Towards Robust and Efficient Autonomous Driving Systems from the Lens of Software Engineering | Jinqiu Yang
[5] Systematizing the Unusual: A Taxonomy-Driven Dataset for Vision–Language Model Reasoning About Edge Cases in Traffic | Krzysztof Czarnecki
[6] Toward Efficient and Reliable Vision–Language Models for Real-World Autonomous Systems | Mozhgan Nasr
1. The Advantages of Using Scenarios as Part of the Specification in Automated Driving | Dr. techn. Sinan Hasirlioglu

Sinan Hasirlioglu는 아우디(Audi AG)의 Release Engineer로, Scenario-based Development for Automated Driving 분야에서 활동하고 있다. 그는 자율주행 시스템의 검증(verification) 및 검증 체계 설계를 주요 업무로 수행하고 있으며, 본 발표에서는 워크숍 논문 “Scenario as Specification: Structuring the Development and Deployment of Automated Driving”을 중심으로 연구 내용을 소개하였다. 발표에 따르면 아우디는 컨셉카 출시 이후에도 자율주행 기능을 지속적으로 업데이트하며 관련 R&D를 꾸준히 수행하고 있다.

발표는 자율주행이 직면하고 있는 다양하고 복잡한 traffic scenario의 문제를 직관적으로 제시하는 것으로 시작되었다. 실제 도로 환경에서 발생 가능한 시나리오는 매우 다양하기 때문에, 자율주행 시스템의 안전성을 충분히 검증하기 위해서는 이러한 시나리오를 명확히 정의하고 기술(specification)할 수 있어야 하며, 이를 기반으로 한 체계적이고 강도 높은 검증이 필요함을 강조하였다.
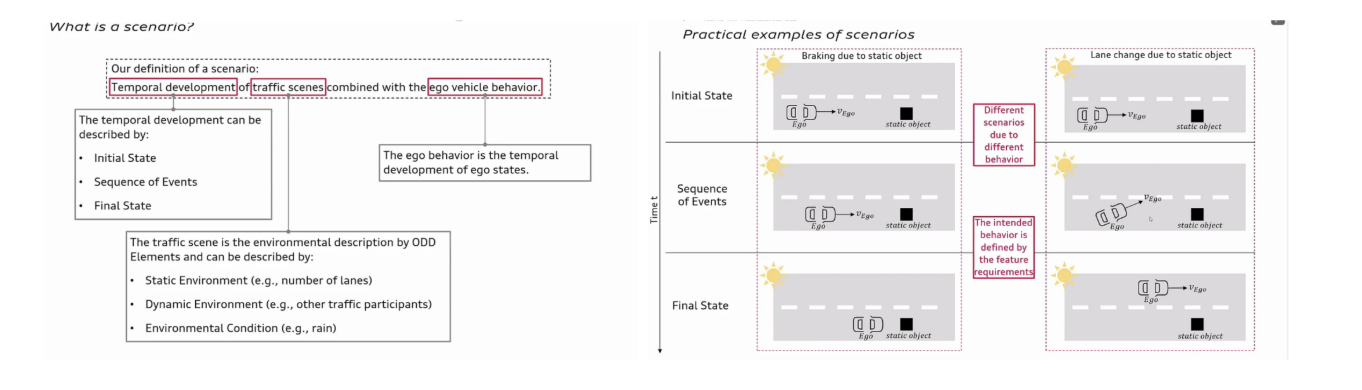
Hasirlioglu는 시나리오를 구성하는 핵심 요소를 세 가지로 정의하였다. 첫째는 시간에 따른 전개를 의미하는 temporal development, 둘째는 주변 환경을 나타내는 traffic scene, 셋째는 자율주행 차량 자체의 반응을 포함하는 ego vehicle behavior이다. 특히 외부 교통 환경뿐만 아니라, ego vehicle의 센서 값이나 시스템 내부 상태가 포함된 상황에서도 안전성이 검증되어야 한다는 점이 인상적으로 제시되었다.
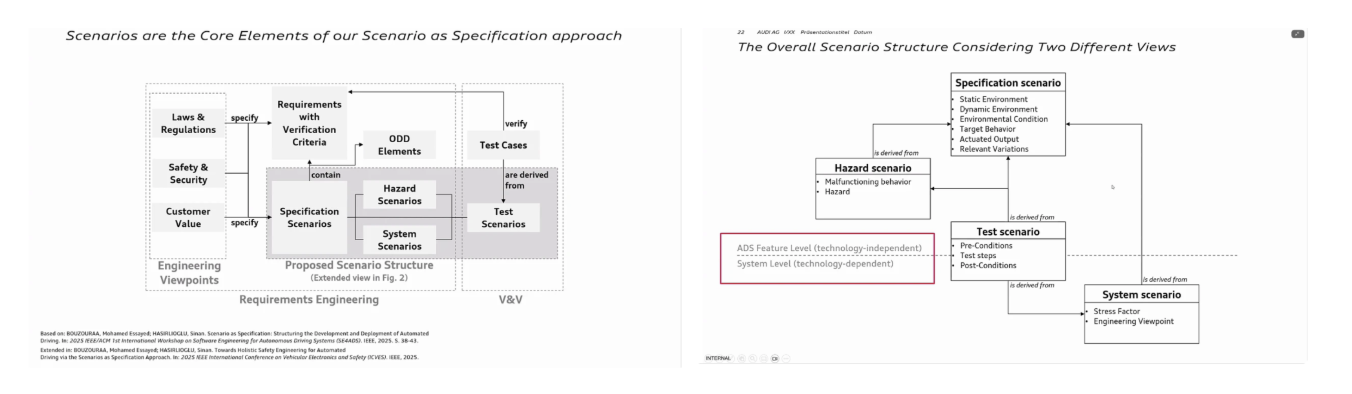
이어 발표에서는 시나리오 기반 검증 파이프라인을 도식화하여 설명하였다. 이는 구체적인 상황을 명시(specify)하고, 이를 바탕으로 scene을 생성한 뒤 요구 사항을 검증하는 일련의 절차를 체계적으로 정리한 것이다. 특히 hazard scenario에 대한 검증을 별도로 강조하며, 요구 사항을 다양한 관점에서 엄밀하게 검증하고 있음을 확인할 수 있었다.
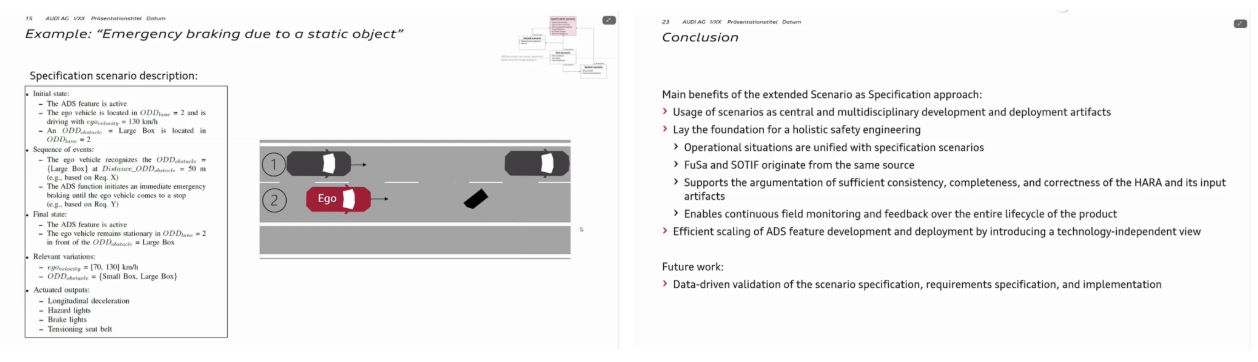
또한 stress factor와 같은 시스템 내부 변수들을 조절하며, 차량 및 기술 스택에 따라 달라질 수 있는 tech-dependent 요소까지 고려한 검증 전략도 소개되었다. 예를 들어, 브레이크를 작동해야 하는 특정 교통 상황에서 자율주행 차량이 어떻게 반응하는지를 테스트하는 사례가 제시되었는데, 이 과정에서 요구 사항과 교통 상황을 자연어로 명시할 수 있다는 점이 핵심적인 특징으로 강조되었다.
결론적으로, 발표를 통해 자율주행 시스템의 검증 단계에서 시나리오 기반 접근이 얼마나 중요한 역할을 하는지를 잘 보여주었다. 비교적 생소할 수 있는 분야이지만, 자율주행의 안전성과 신뢰성을 확보하기 위해 반드시 필요한 연구 영역이라는 점을 분명히 인식하게 되었으며, 전반적으로 매우 흥미롭고 설득력 있는 개괄이었다.
2. Testing and Evaluation of Autonomous Driving Systems: From Simulated to Real-world Test Environments | Andrea Stocco

자율주행 시스템(ADS)은 실제 도로 환경에 배포되기 전에 극도로 높은 수준의 신뢰성을 요구받는다. 그러나 현실 세계는 날씨, 조명, 교통 밀도, 도로 구조 등 수많은 요인이 복합적으로 작용하는 비결정적 환경이며, 이러한 모든 경우를 실제 주행 시험만으로 커버하는 것은 사실상 불가능하다. 이로 인해 자율주행 검증은 필연적으로 시뮬레이션 기반 테스트에 의존하게 되지만, 시뮬레이션과 현실 사이에는 여전히 무시할 수 없는 reality gap이 존재한다. 이번 키노트 연설은 바로 이 간극을 체계적으로 다루는 것을 핵심 문제로 설정했다. 자율주행 시스템 테스트를 단일 단계가 아닌 순환적 파이프라인으로 바라본다. 실제 주행에서 수집된 데이터는 모델 학습에 활용되고, 학습된 모델은 시뮬레이션 환경에서 대규모 테스트를 거친 뒤, 다시 제한된 실제 환경(in-field testing)으로 확장된다. 이 과정은 단방향이 아니라 반복적으로 이루어지며, 테스트 결과는 다시 데이터 수집과 시뮬레이션 설계로 순환된다. 이러한 관점에서 테스트는 개발의 말단이 아니라, 시스템 전 생애주기를 관통하는 핵심 요소로 정의되다는 것을 알 수 있었다
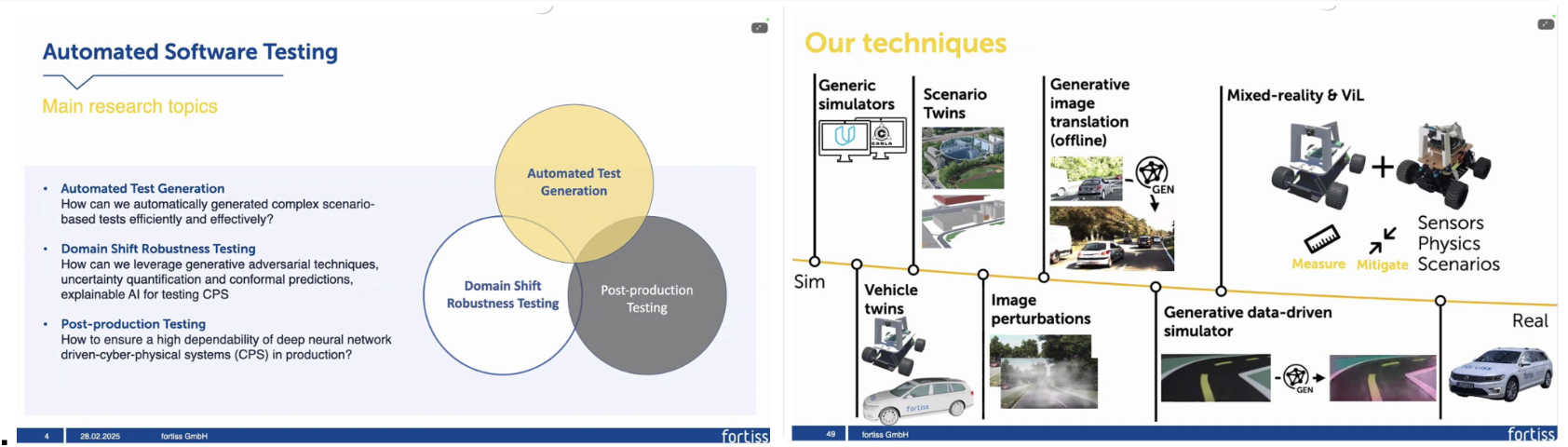
연구실의 연구들을 나열하며 그 개요들을 주로 다뤘는데 크게 세 가지 축으로 정리할 수 있었다. 첫째, Automated Test Generation은 사람이 직접 시나리오를 설계하지 않고도, 복잡하고 드문 실패 상황을 자동으로 생성하는 것을 목표로 한다. 둘째, Domain-shift Robustness Testing은 시뮬레이션과 현실, 혹은 서로 다른 환경 간 분포 차이가 시스템 성능에 미치는 영향을 정량화하고 이를 완화하는 방법을 연구한다. 셋째, Post-production Testing은 시스템이 실제로 배포된 이후에도 지속적으로 동작을 감시하고, 신뢰할 수 없는 상황을 감지해 안전한 대응을 가능하게 하는 것을 목표로 한다. 이 세 축은 독립적이기보다는 서로 긴밀히 연결되어 있다는 인상을 받을 수 있었다.

기존의 디지털 트윈 접근은 하나의 고정된 시뮬레이터가 현실을 최대한 정확히 모사해야 한다는 전제를 둔다. 그러나 연구실은 이 접근의 한계를 지적하며, 여러 개의 상이한 시뮬레이터를 병렬적으로 사용하는 프레임워크를 제안한다. 서로 다른 물리 엔진, 센서 모델, 가정 하에서 동일한 테스트를 수행하고, 그 결과를 교차 검증함으로써 실패 사례의 신뢰도를 높인다. 이 개념을 Digital Siblings라 명명하며, 단일 모델의 정확성보다 다수 모델 간 합의(consensus)를 중시하는 접근을 강조한다. Digital Siblings 프레임워크는 세 가지 중요한 이점을 제공한다. 첫째, 여러 시뮬레이터에서 동일하게 관측되는 실패는 우연이 아니라 구조적 문제일 가능성이 높아진다. 둘째, 서로 다른 물리 가정은 상호 보완적으로 작용해 더 넓은 실패 공간을 탐색할 수 있다. 셋째, 다수 시뮬레이터의 합의를 통해 예측된 실패는 단일 시뮬레이터 기반 결과보다 신뢰도가 높다. 이를 통해 테스트 결과의 “validity” 자체를 향상시키는 것이 핵심 목표다.

자율주행 인식 시스템에서 가장 두드러지는 domain shift는 시각 입력에서 발생한다. 이미지에 대해 단순한 노이즈 추가를 넘어서, 위의 그림과 같이 날씨, 계절, 조명, 지역, 시간대와 같은 의미적 변화를 체계적으로 생성한다. 이미지 perturbation, 키워드 기반 재생성, 생성 모델을 활용한 스타일 변환 등을 통해 하나의 장면으로부터 다수의 변형 데이터를 생성하고, 이를 통해 테스트 데이터셋의 견고함을 확보한다. 이 과정에서 이미지 생성 기술은 단순한 데이터 증강이 아니라, domain shift 자체를 통제하고 분석하는 도구로 활용된다고 한다.
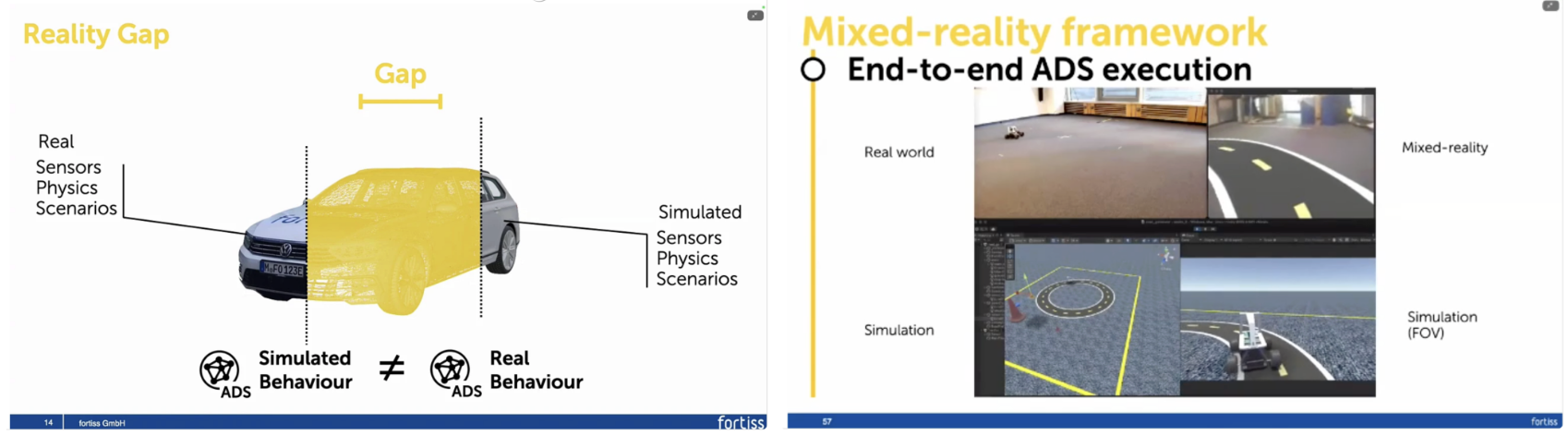
발표에서는 시뮬레이션이 현실을 완전히 대체할 수 없다는 점을 명확히 전제한다. 시뮬레이션에서 잘 동작하는 시스템이 현실에서도 동일하게 동작할 것이라는 가정은 위험하다. 따라서 Simulation, Vehicle Twin 수준의 실험, 제한된 실제 실험으로 이어지는 단계적 검증 전략을 강조한다. 각 단계는 이전 단계의 결과를 검증 및 보완하는 역할을 하며, gap을 “없애는 것”이 아니라 관리하고 드러내는 것을 목표로 한다. Mixed-reality 프레임워크는 시뮬레이션과 현실을 단절된 영역이 아니라 연속선상에 둔다. 실제 차량의 위치와 움직임을 추적하면서, 센서 입력 일부를 시뮬레이션으로 대체하거나 혼합함으로써, 현실성과 통제 가능성을 동시에 확보한다. 이를 통해 자율주행 시스템의 end-to-end 실행을 보다 안전하고 반복 가능하게 검증할 수 있으며, 순수 시뮬레이션이나 순수 실차 실험이 갖는 한계를 동시에 완화한다.
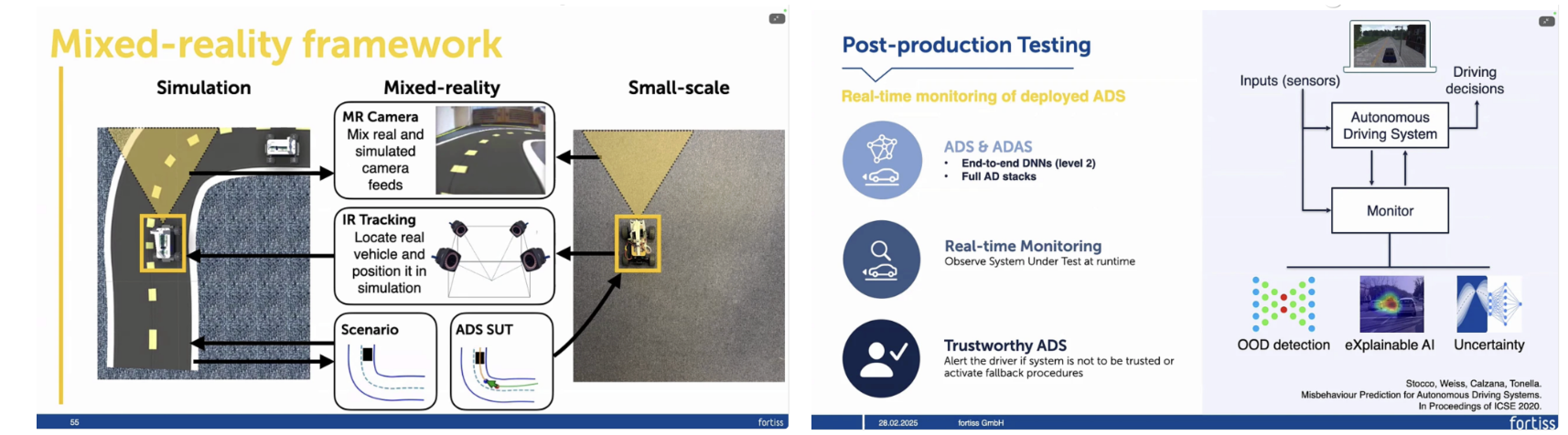
마지막으로 연구는 테스트를 배포 이전(pre-deployment)에 국한하지 않는다. 실제 서비스 중인 ADS를 대상으로 실시간 모니터링을 수행하고, OOD(out-of-distribution) 상황, 불확실성 증가, 설명 가능성 저하 등을 감지해 시스템 신뢰도를 지속적으로 평가한다. 이는 테스트가 “끝나는 단계”가 아니라, 자율주행 시스템이 존재하는 한 계속 수행되어야 할 지속적 검증 과정임을 의미한다. 정리하면, 본 연구실의 접근은 자동화된 테스트 생성, domain shift에 대한 적극적 활용과 대응, 배포 이후까지 이어지는 검증을 하나의 통합된 프레임워크로 묶는다. 단일 디지털 트윈이 아닌 Digital Siblings, 이미지 생성 기반 시각적 변형, mixed-reality 실험을 통해 시뮬레이션과 현실의 간극을 구조적으로 다루는 것이 핵심 철학이다. 이는 “테스트와 시뮬레이션의 경계가 점점 흐려지는 방향”으로 자율주행 검증을 재정의하려는 시도로 볼 수 있다.
3. Vision-Language-Action (VLA) Models | Sergey Levine

전통적인 로봇 제어 시스템은 관측(observation)에서 시작해 상태 추정, 환경 모델링, 경로 계획, 그리고 저수준 제어로 이어지는 모듈형 파이프라인 구조를 중심으로 발전해왔다. 이러한 접근은 각 단계가 명확히 분리되어 있어 해석 가능성과 안정성 면에서 강점을 가지지만, 동시에 모듈 간 오차 전파, 복잡한 시스템 튜닝, 그리고 새로운 환경이나 작업에 대한 일반화 성능의 한계라는 구조적 문제를 내포하고 있다. 특히 실제 환경에서 발생하는 예외적 상황이나 분포 변화(domain shift)에 대해 각 모듈이 독립적으로 설계되었기 때문에 전체 시스템의 강건성이 쉽게 무너질 수 있다. 이러한 한계를 극복하기 위한 대안으로 제시된 것이 end-to-end robotic learning이며, 최근에는 시각과 언어를 함께 활용하는 Vision-Language-Action 모델로 발전하고 있다.
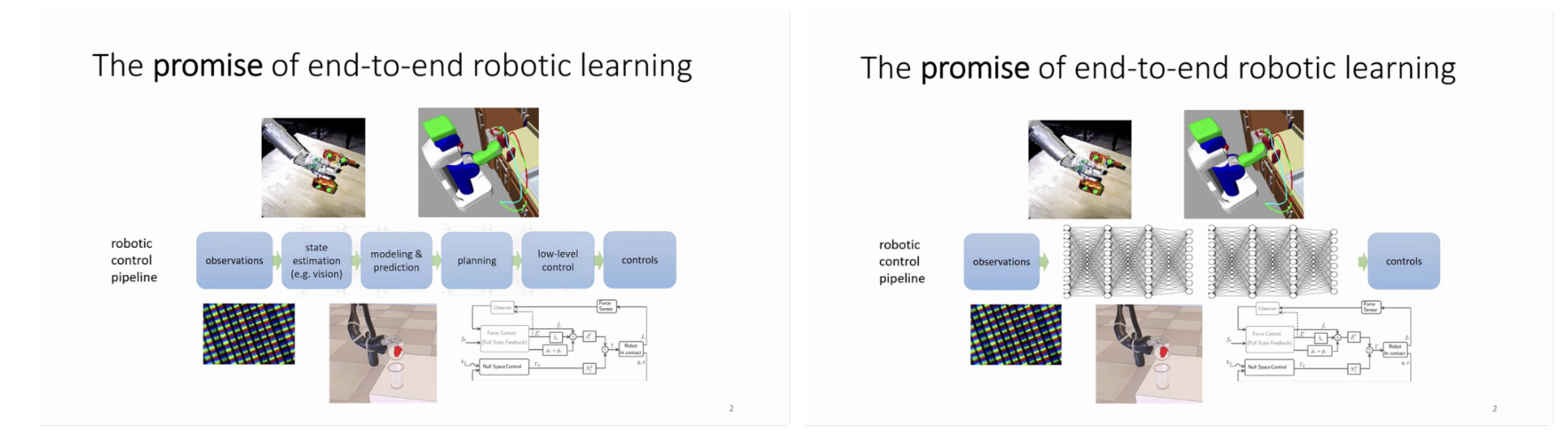
End-to-end 방식의 로봇 학습은 이론적으로 매력적이지만, 실제 적용에 있어 여러 근본적인 어려움에 직면한다. 첫째, 로봇은 조명, 물체 배치, 배경, 환경 구조 등이 지속적으로 변화하는 현실 세계에서 작동해야 하므로, 학습된 정책이 다양한 시나리오에 대해 일반화될 수 있어야 한다. 둘째, 이러한 일반화를 가능하게 할 만큼 충분하고 다양한 로봇 데이터를 수집하는 것은 매우 높은 비용과 시간을 요구한다. 셋째, 실제 로봇 제어는 실시간성과 안정성이 필수적이기 때문에, 단순히 높은 성공률뿐 아니라 빠르고 강건한 반응을 보장해야 한다. 본 발표에서는 이러한 문제들에 대한 해법으로 사전학습된 vision-language 모델의 활용, 대규모 cross-embodiment 데이터셋, 그리고 강화학습 기반 후처리 기법을 제안한다.
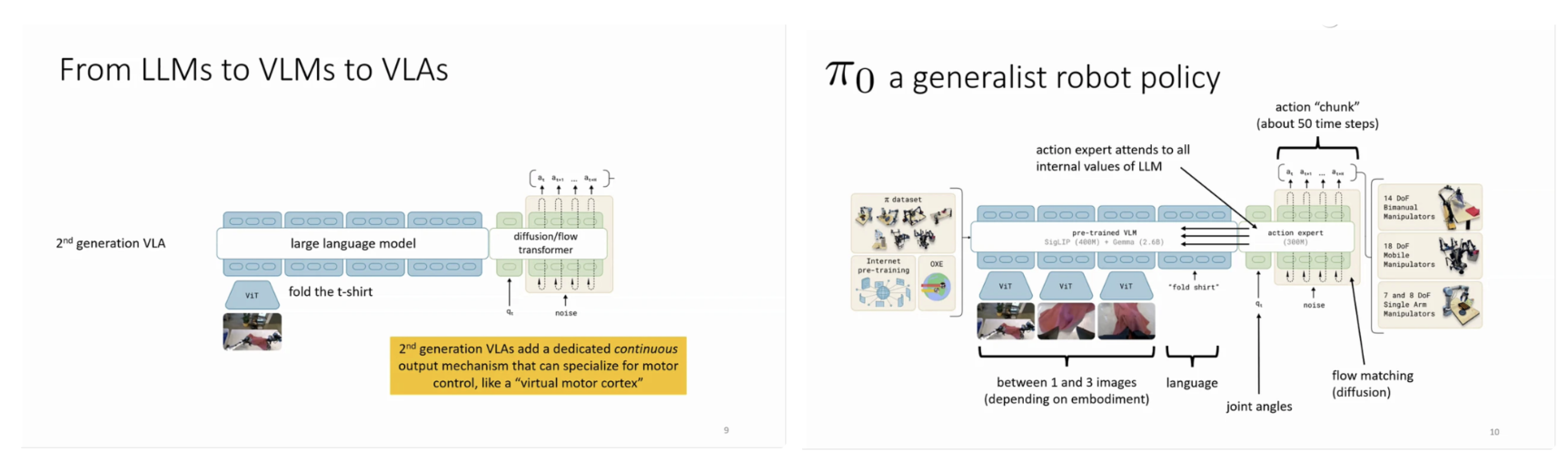
End-to-end 학습의 핵심적인 장점은 기존의 복잡한 로봇 제어 파이프라인을 하나의 학습 가능한 함수로 대체할 수 있다는 점에 있다. 전통적인 방식에서는 각 모듈이 명시적으로 설계되고 조정되어야 하지만, end-to-end 접근에서는 관측 입력으로부터 바로 행동을 출력하도록 신경망을 학습함으로써 중간 표현 설계에 대한 부담을 줄일 수 있다. 이를 통해 작업 목적에 직접 최적화된 행동을 학습할 수 있으며, 복잡한 상호작용이나 비선형 동역학 또한 데이터 기반으로 암묵적으로 모델링할 수 있다. 이러한 특성은 특히 장기 시계열 의사결정이나 복합적인 조작 작업에서 큰 잠재력을 가진다. 최근 로보틱스 분야에서는 대규모 언어 모델(LLM)의 성공을 계기로, 시각과 언어를 결합한 vision-language model(VLM), 그리고 나아가 행동까지 포함하는 vision-language-action(VLA) 모델로의 확장이 이루어지고 있다. VLA는 언어 지시를 이해하고 시각 정보를 해석한 뒤, 이를 실제 로봇의 연속적인 제어 신호로 변환하는 것을 목표로 한다. 특히 2세대 VLA 모델에서는 언어 모델 위에 연속 출력에 특화된 액션 생성 모듈을 추가함으로써, 고수준 추론과 저수준 모터 제어 사이의 간극을 줄이고자 한다. 이는 언어 모델이 단순한 명령 해석기를 넘어, 실제 물리적 행동을 유도하는 중심 역할을 수행하도록 만든다는 점에서 중요한 진전이다.
phi_0는 특정 작업에 국한되지 않고 다양한 조작 과제를 수행할 수 있는 범용 로봇 정책을 목표로 설계되었다. 이 모델은 입력으로 하나 또는 여러 장의 이미지와 자연어 지시를 받아, 사전학습된 vision-language 인코더를 통해 고수준 의미 표현을 생성한다. 이후 action expert 모듈은 언어 모델 내부의 전체 표현을 참조하여 약 수십 타임스텝에 해당하는 연속적인 행동 시퀀스를 생성한다. 이 과정에서 diffusion 또는 flow matching과 같은 확률적 생성 기법을 사용함으로써, 연속 제어 공간에서의 안정적인 행동 샘플링을 가능하게 한다. 결과적으로 phi_zero는 의미 이해와 저수준 제어를 단일 프레임워크 안에서 통합한 구조를 가진다.
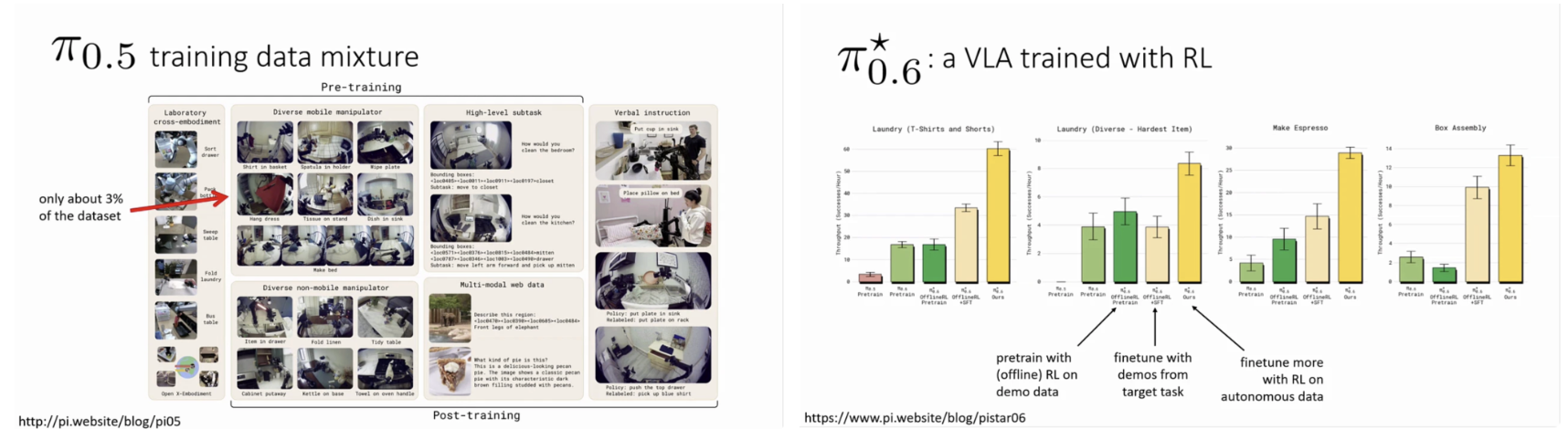
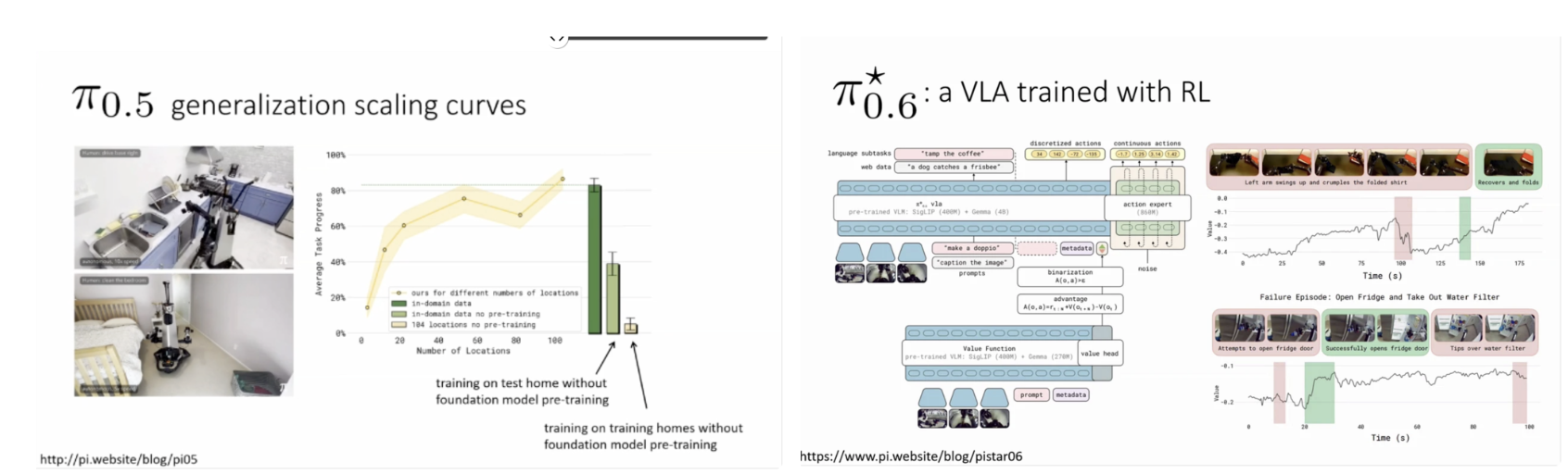
phi_0.5에 대한 실험 결과는 데이터와 환경 다양성이 로봇 정책의 일반화 성능에 얼마나 큰 영향을 미치는지를 명확히 보여준다. 학습에 사용된 로케이션 수와 데이터 규모가 증가함에 따라, 보지 못한 환경에서의 성공률 또한 지속적으로 상승하는 경향을 보였다. 특히 foundation model 수준의 사전학습을 수행한 경우, 동일한 작업을 특정 환경에서만 학습한 모델보다 훨씬 뛰어난 테스트 성능을 나타냈다. 이는 로봇 학습에서도 언어 및 시각 모델에서 관찰된 스케일링 법칙이 유효함을 시사한다. phi_0.6은 사전학습된 VLA 모델을 강화학습을 통해 추가로 미세조정한 버전으로, 로봇의 강건성과 실패 복구 능력을 크게 향상시킨다. 초기에는 데모 데이터 기반의 offline RL을 사용하고, 이후 목표 작업에 특화된 데모 파인튜닝과 자율적 강화학습을 단계적으로 적용한다. 이러한 접근은 특히 긴 시계열을 가지는 작업이나 난이도가 높은 조작 과제에서 효과적이며, 단순 성공률뿐 아니라 실패 이후의 회복 행동에서도 뚜렷한 개선을 보여준다. 이는 RL이 VLA 모델의 약점을 보완하는 핵심 요소임을 의미한다. 흥미로운 점은 phi_0.5의 학습 데이터 중 실제 로봇 조작 데이터가 차지하는 비율이 전체의 극히 일부에 불과하다는 사실이다. 대부분의 데이터는 다양한 로봇 환경, 비로봇 조작 영상, 웹 기반 멀티모달 데이터, 그리고 언어 지시 데이터로 구성되어 있다. 이는 대규모 사전학습을 통해 일반적인 시각, 언어 표현을 학습한 뒤, 소량의 실제 로봇 데이터를 활용해 행동으로 연결하는 전략이 매우 효과적임을 보여준다. 즉, 로봇 학습에서도 데이터의 ‘질’과 ‘다양성’이 단순한 물리적 수집량보다 더 중요함을 시사한다. 본 연구는 로봇 제어가 더 이상 전통적인 제어 이론과 학습 기반 접근 사이의 선택 문제가 아니라, foundation model, 강화학습, 그리고 확률적 행동 생성 기법을 통합하는 문제임을 명확히 보여준다. 언어는 로봇에게 작업을 일반화할 수 있는 강력한 추상화 도구를 제공하며, diffusion 기반 행동 생성은 연속 제어 공간에서 안정성과 표현력을 동시에 확보할 수 있게 한다. 또한 강화학습은 이러한 모델이 실제 환경에서 신뢰할 수 있는 행동을 수행하도록 만드는 필수적인 요소로 작용한다. Vision-Language-Action 모델은 로봇을 단일 작업 수행 기계가 아닌 범용 지능 시스템으로 확장하기 위한 현실적인 경로를 제시한다. 이는 단순한 end-to-end 학습을 넘어, 대규모 사전학습, 멀티모달 추론, 강화학습 기반 적응을 결합한 새로운 로보틱스 패러다임이라 할 수 있다. 앞으로의 로봇 연구는 이러한 모델을 중심으로 시뮬레이션 기반 데이터 확장, 도메인 시프트 대응, 그리고 실제 환경 검증을 어떻게 체계화할 것인가에 초점을 맞추게 될 것이다.
4. Towards Robust and Efficient Autonomous Driving Systems from the Lens of Software Engineering | Jinqiu Yang
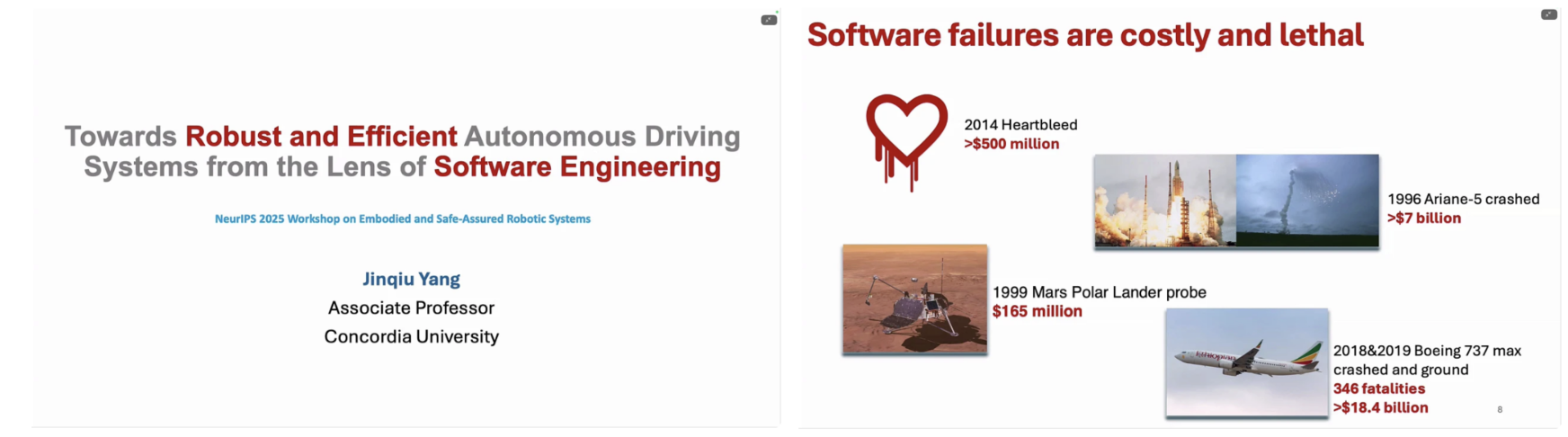
이번 키노트는 소프트웨어 공학 관점에서 자율주행 시스템의 강건성(robustness)과 효율성(efficiency)을 어떻게 확보할 수 있는가라는 문제의식에서 출발한다. 자율주행 시스템은 인지(perception), 예측(prediction), 계획(planning), 제어(control)로 구성된 복합적 파이프라인을 가지며, 이 중 어느 한 구성 요소의 오류라도 전체 시스템 실패로 이어질 수 있다. 특히 자율주행은 물리적 세계와 직접 상호작용하는 안전 중심 시스템(safety-critical system) 이기 때문에, 소프트웨어 결함은 단순한 성능 저하를 넘어 막대한 경제적 손실과 인명 피해로 직결될 수 있다.
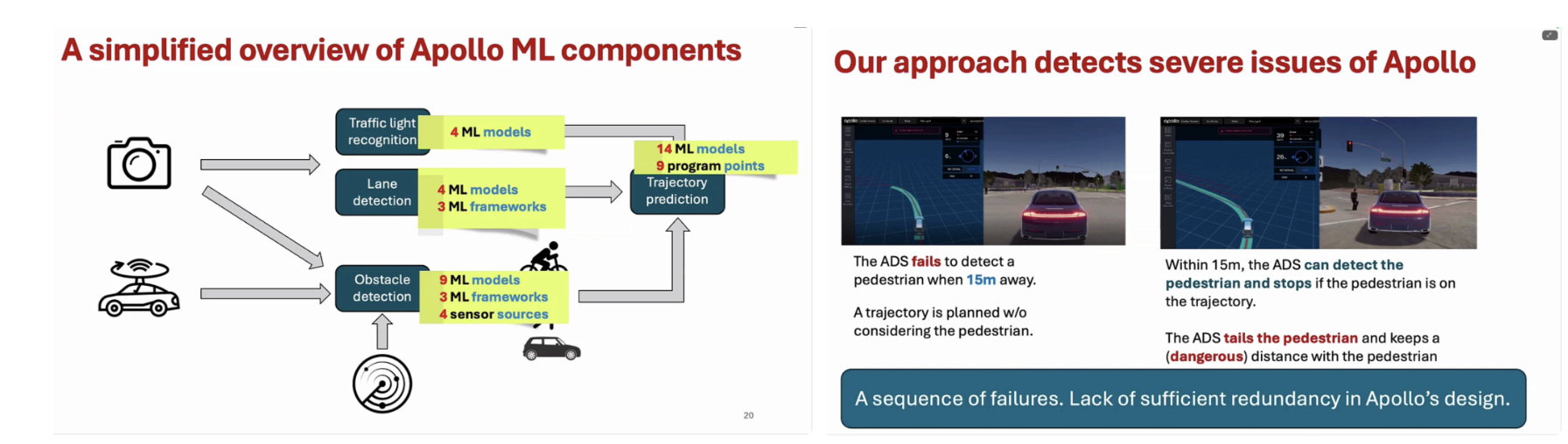
발표에서는 이러한 문제의 심각성을 강조하기 위해, Heartbleed 보안 취약점, Mars Polar Lander 추락, Ariane-5 로켓 폭발, Boeing 737 MAX 사고 등 실제 소프트웨어 실패 사례들을 제시한다. 이 사례들은 공통적으로 복잡한 시스템에서의 소프트웨어 오류가 얼마나 치명적인 결과를 초래할 수 있는지를 보여주며, 자율주행 시스템 역시 동일한 위험에 노출되어 있음을 시사한다. 이후 발표는 Apollo 자율주행 시스템을 사례로 들어, 실제 자율주행 ML 시스템이 얼마나 복잡한 구조를 가지는지를 설명한다. Apollo의 인지 모듈만 하더라도 교통 신호 인식, 차선 인식, 장애물 인식 등 다수의 서브 태스크로 구성되어 있으며, 각각은 여러 개의 머신러닝 모델, 다양한 프레임워크, 그리고 복수의 센서 입력(LiDAR, 카메라 등)에 의존한다. 이러한 구조는 개별 모델의 성능이 우수하더라도 모듈 간 상호작용과 시스템 통합 수준에서 새로운 오류가 발생할 가능성을 내포한다.
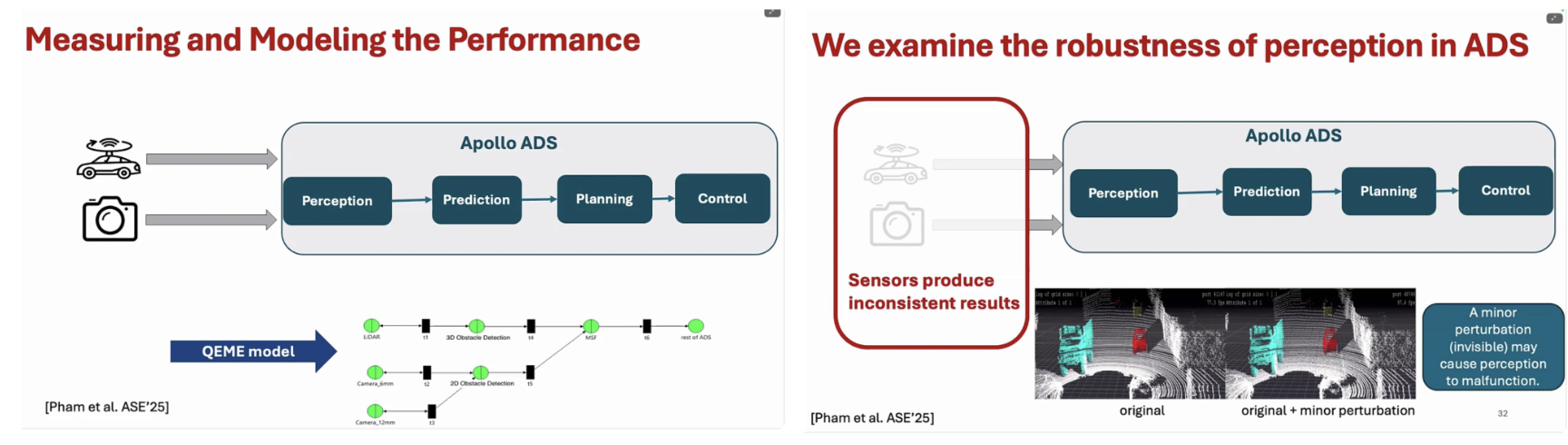
발표자는 실제 실험을 통해, Apollo 시스템이 특정 조건에서 보행자를 인식하지 못하거나, 인식은 했으나 안전하지 않은 거리로 접근하는 등 연쇄적인 실패(sequence of failures) 를 보인다는 점을 보여준다. 이는 단일 인지 오류가 예측과 계획 모듈로 전파되며, 결과적으로 시스템 전반의 안전성을 저해함을 의미한다. 이러한 현상은 Apollo 설계에 충분한 중복성(redundancy)이 부족하다는 점과도 연결된다. 이를 체계적으로 분석하기 위해, 발표에서는 Apollo ADS 전체를 대상으로 한 성능 측정 및 모델링 접근법을 제안한다. 인지, 예측, 계획, 제어로 이어지는 파이프라인을 하나의 시스템으로 보고, 각 단계의 지연(latency)과 성능이 전체 시스템 동작에 어떤 영향을 미치는지를 정량적으로 모델링한다. 특히 센서 입력의 미세한 변화가 인지 결과에 불안정성을 유발하고, 이것이 시스템 전체의 동작 오류로 확대될 수 있음을 실험적으로 보여준다.
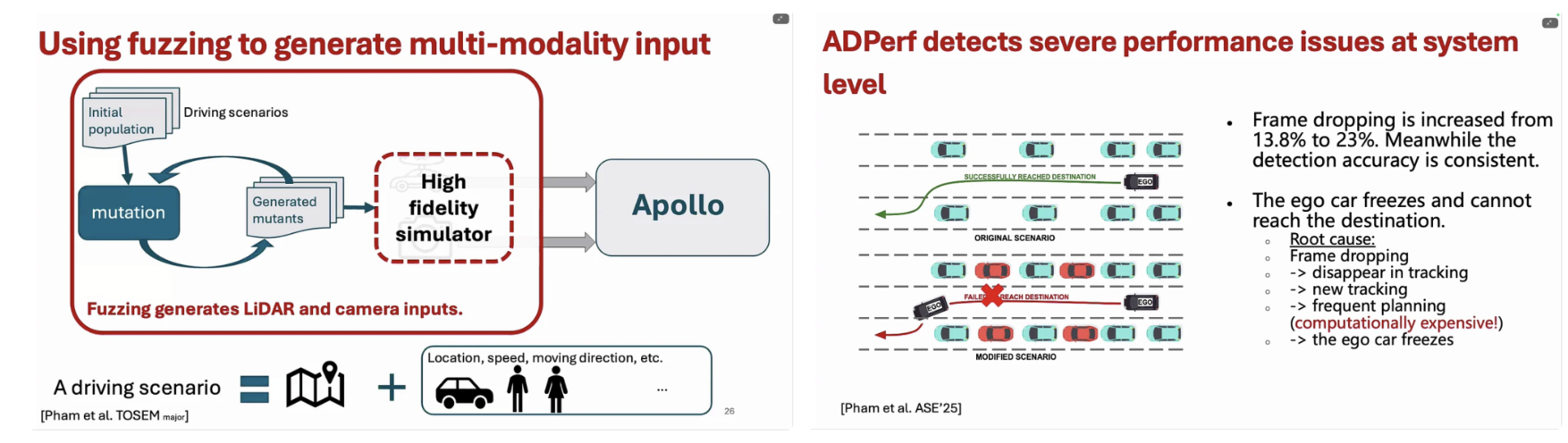
또한, 발표에서는 퍼징(fuzzing) 기법을 활용해 다중 모달 입력(LiDAR + 카메라)을 자동으로 생성하는 방법을 소개한다. 실제 주행 시나리오를 기반으로 입력을 변형하고, 이를 고충실도 시뮬레이터에서 실행함으로써, 현실에서 재현하기 어려운 경계 조건(edge cases)을 효과적으로 탐색한다. 이를 통해 기존 테스트 방식으로는 발견하기 어려웠던 심각한 성능 저하 및 시스템 정지 현상(ego car freeze)을 검출할 수 있음을 보인다. 특히 ADPerf 프레임워크를 통해 시스템 수준에서의 성능 문제를 분석한 결과, 프레임 드롭 증가, 경로 계획 빈도 증가로 인한 계산 부하, 그리고 최종적으로 차량이 목적지에 도달하지 못하는 현상 등이 관찰되었다. 이는 단일 모듈의 정확도가 유지되더라도, 시스템 수준 성능(system-level performance) 이 충분히 고려되지 않으면 자율주행이 실패할 수 있음을 명확히 보여준다.

마지막으로 발표는 실제 AI 기반 물리 시스템을 테스트하며 얻은 교훈을 정리한다. 현실 세계의 AI 시스템은 하드웨어, 센서, 운영체제, 시뮬레이터 등 기술 스택 전반이 끊임없이 변화하며, 복잡한 워크로드로 인해 테스트 자체가 매우 어렵다. 따라서 개별 모델이나 모듈 테스트에만 의존해서는 안 되며, 시스템 전체를 대상으로 한 테스트와 성능 분석을 결코 과소평가해서는 안 된다는 점을 강조하며 발표를 마무리한다.
5. Systematizing the Unusual: A Taxonomy-Driven Dataset for Vision–Language Model Reasoning About Edge Cases in Traffic | Krzysztof Czarnecki

이번 키노트에서도 비슷하게 자율주행 시스템의 안전성 검증과 신뢰성 향상을 목표로 제안된 EdgeScenes 연구를 다룬다. EdgeScenes는 자율주행 환경에서 발생할 수 있는 다양한 도로 위험 상황(edge cases)을 체계적으로 정의하기 위한 도로 위험 온톨로지(road hazard ontology)와, 이를 기반으로 구축된 대규모 영상 데이터셋을 함께 제공하는 벤치마킹 프레임워크이다. 본 연구는 캐나다 워털루대학교 Waterloo Intelligent Systems Engineering(WISE) Lab에서 수행되었으며, 실제 도로 환경에서 발생하는 예외적이고 위험한 상황을 정량적, 구조적으로 다루는 것을 목표로 한다.
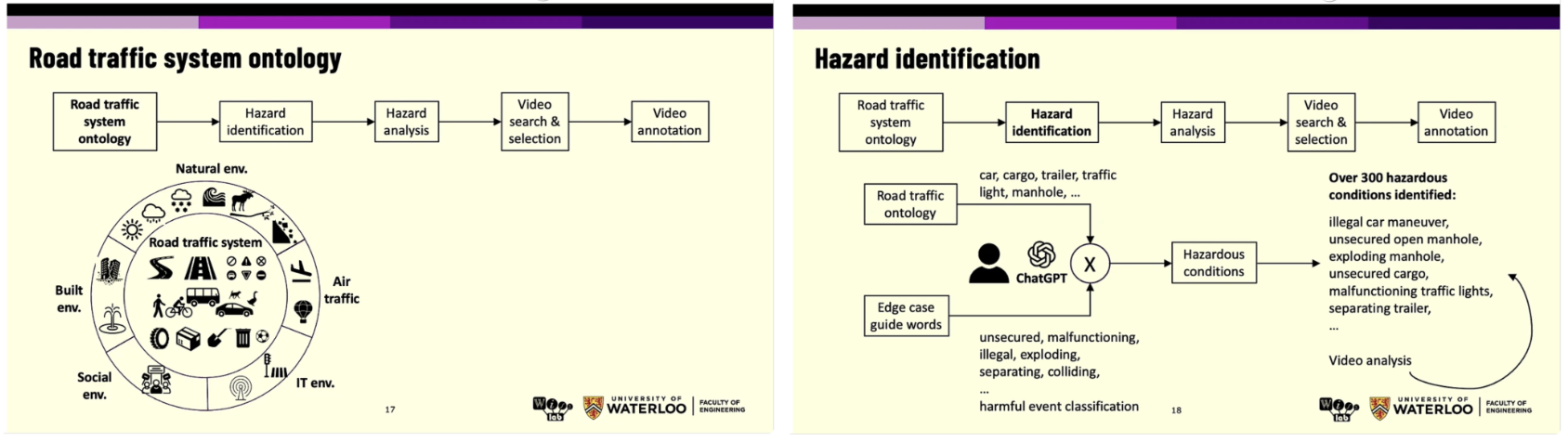
자율주행 기술은 일반적인 주행 상황에서는 높은 성능을 보이지만, 드물고 복합적인 위험 상황에서는 여전히 취약하다. 특히 교통 시스템은 자연환경, 인공환경, 사회적 요인, 정보기술 환경이 복합적으로 얽혀 있는 복잡계로, 단순한 주행 데이터만으로는 안전성을 충분히 검증하기 어렵다. 이에 본 연구는 “edge case”를 단순한 예외가 아닌, 체계적으로 정의, 분류, 분석 가능한 객체로 다루고자 하였다. 이를 위해 연구진은 먼저 도로 교통 시스템 온톨로지를 설계하였다. 이 온톨로지는 도로 환경을 자연 환경, 구축 환경, 사회적 환경, 공기, 교통 요소, IT 환경 등으로 구분하고, 차량, 보행자, 도로 구조물, 교통 신호, 날씨, 사고 유발 요인 등을 포괄적으로 포함한다. 이러한 구조 위에서 위험 상황(hazard)을 식별하고, 각 위험이 어떤 조건에서 어떻게 발생하는지를 분석할 수 있도록 개념적 틀을 제공한다. 다음 단계로는 위험 식별(hazard identification) 과정이 수행되었다. 이 과정에서는 교통 신호 오작동, 열려 있는 맨홀, 적재 불량 화물, 분리되는 트레일러, 보행자와의 충돌, 불법 주행 등 실제 도로에서 발생 가능한 300개 이상의 위험 조건이 정의되었다. 이때 ChatGPT와 같은 대규모 언어 모델을 보조 도구로 활용하여, 위험 상황을 설명하는 키워드(예: unsecured, malfunctioning, exploding, colliding 등)를 확장하고, 이를 통해 위험 이벤트를 체계적으로 분류하였다. 이러한 접근은 단순 사고 나열이 아닌, 의미 기반 위험 분류를 가능하게 한다는 점에서 특징적이다.

정의된 위험 조건을 실제 데이터로 연결하기 위해, 연구진은 영상 검색 및 선별(video search and selection) 단계를 거쳤다. Google Images, Bing Images, Reddit, YouTube 등 공개 소스를 활용하여 위험 상황이 명확히 드러난 영상과 이미지를 수집하였으며, 최종적으로 총 1,230개의 장면(scene)을 확보하였다. 이 중 890개는 영상, 340개는 이미지로 구성되어 있으며, 모두 실제 도로에서 촬영된 현실 데이터라는 점에서 높은 현실성을 갖는다. 수집된 데이터는 장면 주석(Scene Annotation) 단계를 통해 정밀하게 구조화되었다. 각 장면은 YAML 기반의 포맷으로 정리되었으며, 메타데이터, 도로 및 환경 조건, 위험 조건, 그리고 영상의 경우 시간에 따른 이벤트(event) 정보가 포함된다. 이를 통해 단순한 시각적 데이터가 아니라, 위험 발생의 맥락과 조건을 함께 분석할 수 있는 데이터셋이 완성되었다. 본 연구는 단순히 데이터셋을 구축하는 데 그치지 않고, 자율주행 안전성 검증을 위한 엔지니어링 및 벤치마킹 도구로서의 활용 가능성을 강조한다. EdgeScenes는 위험 상황 인식, 이상 상황 탐지, 시나리오 기반 테스트, 그리고 자율주행 AI의 취약성 분석에 활용될 수 있으며, 특히 기존 데이터셋에서 충분히 다뤄지지 않았던 희귀, 복합 위험 상황을 체계적으로 제공한다는 점에서 의의가 크다.
6. Toward Efficient and Reliable Vision–Language Models for Real-World Autonomous Systems | Mozhgan Nasr

이번 발표는 실세계 자율 시스템에서 Vision-Language Model(VLM)을 실제로 활용하기 위해 반드시 해결해야 하는 핵심 과제로서, 효율성과 신뢰성의 문제를 정면으로 다룬다. 최근 VLM은 이미지와 언어를 결합한 강력한 추론 능력을 바탕으로 로보틱스, 자율주행, embodied AI 등 다양한 분야에서 활용 가능성이 논의되고 있으나, 실제 환경에 적용하기에는 계산 비용과 지연 시간, 메모리 사용 측면에서 심각한 병목을 안고 있다. 특히 다중 시점, 다중 프레임, 다양한 센서 입력을 동시에 처리해야 하는 자율 시스템 환경에서는 시각 정보의 양이 폭발적으로 증가하며, 이로 인해 VLM의 핵심 구성 요소인 LLM이 감당해야 하는 시각 토큰 수가 급격히 늘어난다. 이러한 토큰 폭증 현상은 단순한 계산량 증가를 넘어, LLM의 컨텍스트 길이 한계를 빠르게 소진시키고, 추론 지연(latency)과 메모리 사용량 증가를 초래하며, 결과적으로 실시간성이 요구되는 자율 시스템에서는 치명적인 제약으로 작용한다.

발표에서는 이러한 문제의 본질을 시각 정보 자체의 양이 아니라, LLM 관점에서 불필요하거나 중복적인 시각 토큰이 무차별적으로 입력된다는 점으로 규정한다. 기존 VLM 구조에서는 각 시각 인코더가 생성한 토큰들이 별다른 선택 과정 없이 LLM으로 전달되며, 이 과정에서 실제 추론에 거의 기여하지 않는 토큰들까지 동일한 비용으로 처리된다. 이에 따라 시각 토큰을 줄이기 위한 기존 접근으로 self-attention 기반 선택이나 비모수적 토큰 프루닝 기법들이 제안되어 왔으나, 이러한 방법들은 언어 조건을 명시적으로 반영하지 못한다는 구조적 한계를 가진다. 즉, 어떤 시각 정보가 중요한지는 결국 언어 질의와 추론 목표에 의해 결정되는데, 기존 방식은 이를 충분히 반영하지 못한 채 시각 도메인 내부의 중요도만을 기준으로 토큰을 제거한다는 문제가 있다.
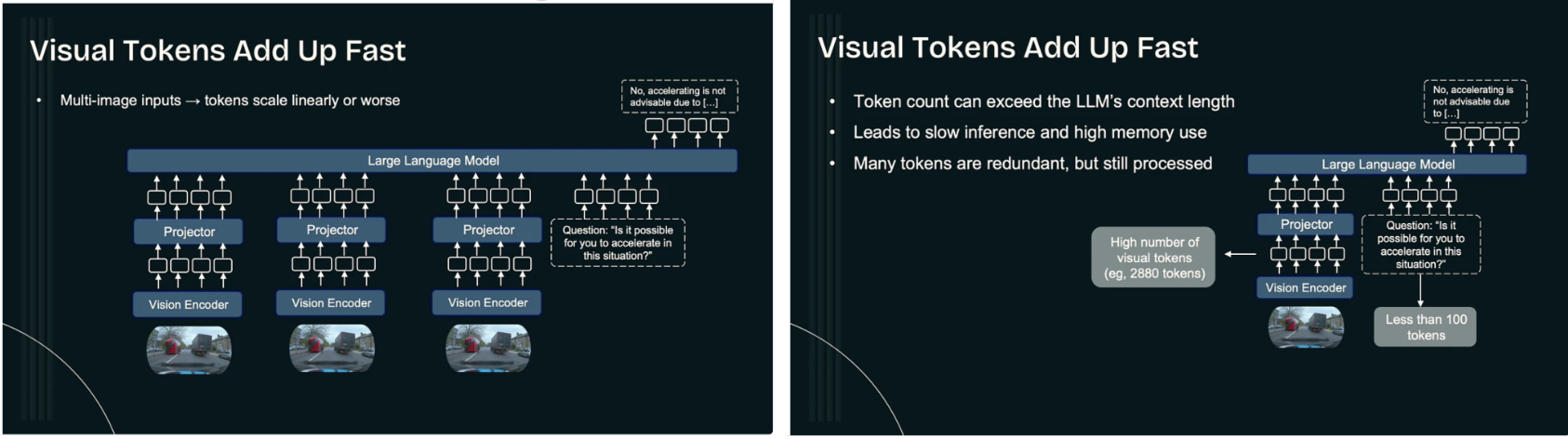
이러한 한계를 해결하기 위해 제안된 것이 LEO(Language-Embedded Optimization)이다. LEO의 핵심 아이디어는 최종 추론을 수행하는 주체가 LLM인 이상, 시각 토큰의 중요도 역시 LLM의 관점에서 정의되어야 한다는 점에 있다. LEO는 시각 인코더에서 생성된 토큰을 LLM 임베딩 공간으로 투영한 뒤, 언어 토큰과 시각 토큰 간의 상호작용을 통해 어떤 시각 정보가 현재 언어 질의와 추론 목적에 실제로 중요한지를 평가한다. 이 과정에서 LLM의 attention map이 핵심적인 신호로 활용되며, 언어 토큰이 강하게 주목하는 시각 토큰만을 선택하거나 통합함으로써, 불필요한 시각 토큰을 효과적으로 제거한다. 이를 통해 LEO는 단순한 토큰 수 감소를 넘어, 언어와 정렬된 시각 표현을 유지하면서도 LLM의 계산 부담을 크게 줄이는 구조를 제시한다.
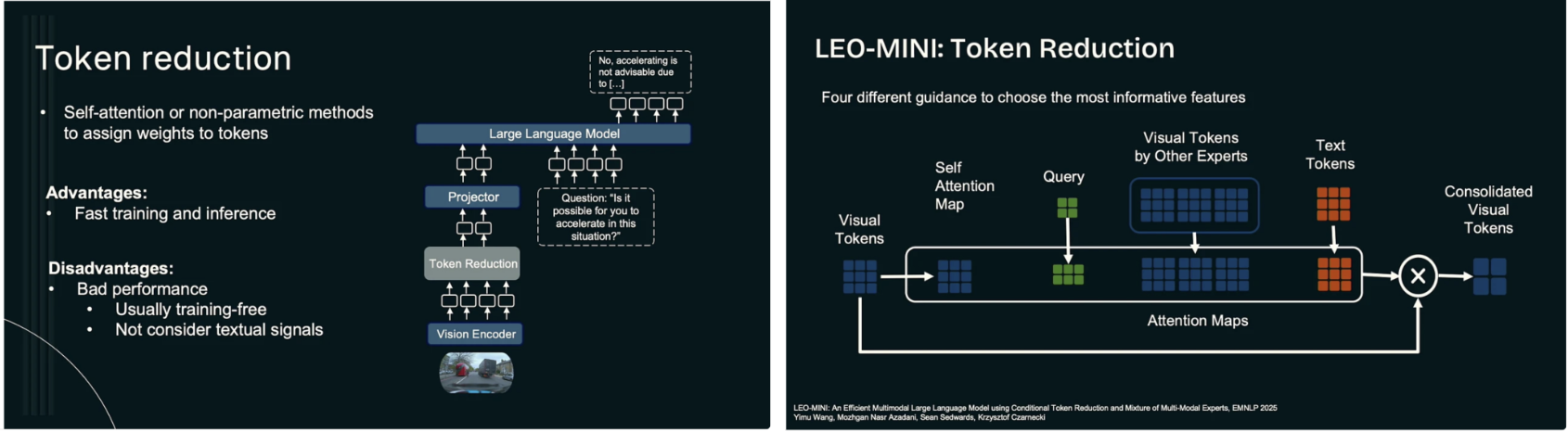
LEO의 실용적 확장으로 제안된 LEO-MINI는 이러한 언어 기반 토큰 선택을 보다 공격적으로 적용하여 실제 추론 환경에서 의미 있는 수준의 토큰 감소를 달성한다. LEO-MINI에서는 텍스트 토큰에서 시각 토큰으로의 attention 분포를 기반으로 중요도가 낮은 시각 토큰을 제거하고, 남은 토큰들을 통합된 형태의 consolidated visual tokens로 압축한다. 이 과정은 LLM의 추론 성능을 유지하면서도 컨텍스트 길이와 메모리 사용량을 크게 줄일 수 있음을 보여준다. 중요한 점은 이 토큰 감소 과정이 단순한 휴리스틱이 아니라, 언어 조건에 의해 동적으로 결정된다는 점이며, 이는 다양한 질의와 상황에 대해 유연하게 대응할 수 있는 장점을 제공한다.
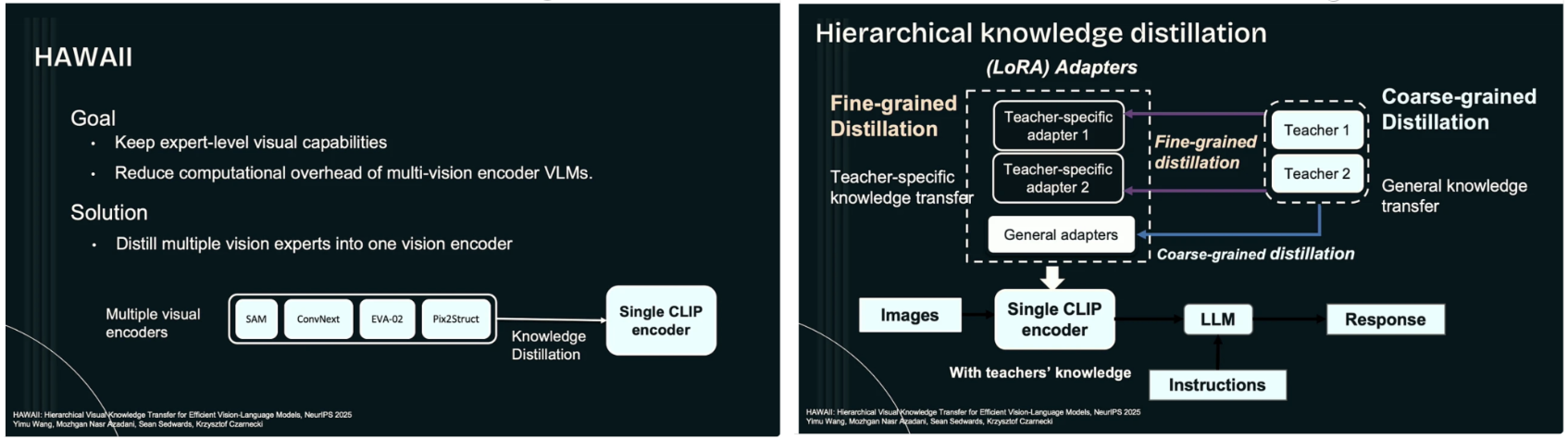
한편, 발표의 후반부에서는 토큰 수 문제를 넘어 시각 인코더 자체의 계산 비용을 줄이기 위한 접근으로 HAWAII를 제안한다. HAWAII의 목표는 다중 시각 인코더를 사용하는 전문가 수준의 VLM이 갖는 시각적 이해 능력을 유지하면서도, 이를 단일 경량 인코더 구조로 압축하는 것이다. 이를 위해 HAWAII는 계층적 지식 증류(hierarchical knowledge distillation)를 활용한다. 먼저 fine-grained distillation 단계에서는 다중 인코더를 사용하는 teacher 모델의 세밀한 시각 표현을 단일 CLIP 기반 student 인코더로 전달하여, 패치 수준의 시각 지식을 보존한다. 이후 coarse-grained distillation 단계에서는 장면 수준이나 개념 수준의 고차 의미 정보를 전달함으로써, 전체적인 시각 이해 능력을 유지한다. 마지막으로 instruction-level alignment를 통해, 동일한 입력과 지시에 대해 student 모델의 응답이 teacher 모델과 정렬되도록 학습함으로써, 실제 VLM 추론 성능의 일관성을 확보한다. 이러한 과정을 통해 HAWAII는 복잡한 다중 시각 인코더 구조를 제거하고도, 전문가 수준의 시각 추론 능력을 단일 인코더 구조에 내재화하는 데 성공한다. 이는 구조적으로 무거운 모델을 유지하는 대신, 학습을 통해 지식을 압축하는 방향이 자율 시스템 환경에서 훨씬 현실적임을 보여준다. 결과적으로 LEO와 HAWAII는 각각 시각 토큰 수준과 시각 인코더 수준에서의 병목을 해결하며, 상호 보완적으로 VLM의 효율성과 실용성을 크게 향상시킨다. 종합하면, 본 발표는 VLM 연구의 방향을 단순한 성능 향상이나 모델 규모 확장이 아니라, 실제 시스템 제약을 고려한 구조적 재설계로 전환시킨다는 점에서 중요한 의미를 갖는다. 특히 언어 모델을 시각 정보의 수동적 소비자가 아니라, 어떤 시각 정보가 필요한지를 결정하는 능동적 주체로 재정의한 LEO의 관점은 향후 VLM 설계 전반에 큰 영향을 미칠 가능성이 있다. 이는 VLM이 연구 데모를 넘어, 실제 자율 시스템의 핵심 인지 모듈로 자리 잡기 위해 반드시 필요한 방향성을 명확히 제시한 연구라 할 수 있다.
