Neurips를 다녀와서 (2)
Neurips 2025

7th International Workshop on Large Scale Holistic Video Understanding: Toward Video Foundation Models에 대한 키노트 세션을 참여했다. 아래의 목차로 세션이 진행되었다. 첫날과 마찬가지로 각 세션은 45분 길이로 진행했다.
[1] VideoLLMs are Lost in Time| Cees Snoek
[2] Generating and Understanding the 3D World | Roozbeh Mottaghi
[3] What Do Large Models Really Know About the World? | Shiry Ginosar
[4] Advances in Multimodal Video Understanding | Hilde Kuehne
1. VideoLLMs are Lost in Time| Cees Snoek

최근 비약적으로 발전한 Video-Language Model(VideoLLM)이 과연 시간(time)을 이해하고 있는가라는 근본적인 질문을 중심으로 전개된다. 기존의 VideoQA 벤치마크에서 VideoLLM들은 매우 인상적인 성능을 보여 왔지만, 저자들은 이러한 성능이 실제 시간적 추론 능력에서 비롯된 것인지에 대해 강한 의문을 제기한다. 겉보기에는 시간 관련 질문처럼 보이지만, 많은 경우 정적인 시각 정보나 언어적 상식만으로도 정답에 도달할 수 있으며, 이는 모델이 시간을 이해하지 못해도 높은 점수를 받을 수 있음을 의미한다.
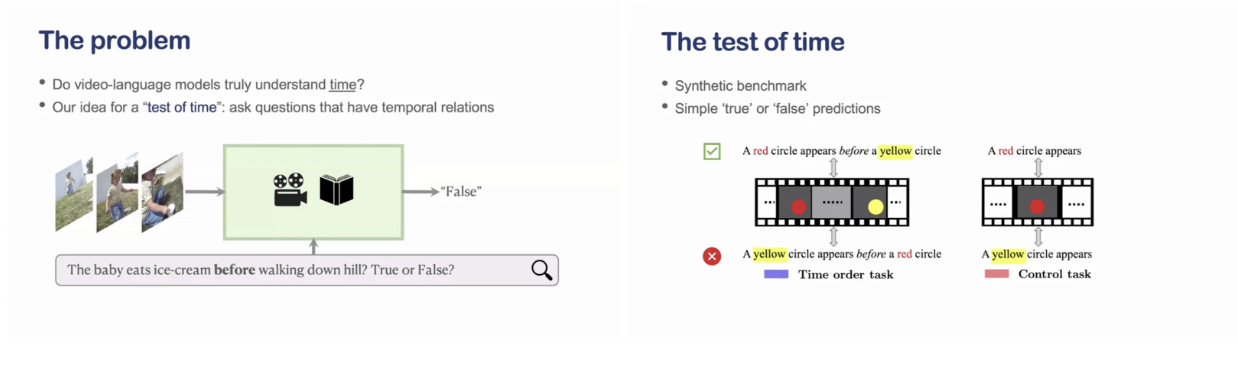
발표에서 지적하는 핵심 문제는 기존 벤치마크들이 시간 정보를 ‘필요로 하지 않는다’는 점이다. 실제로 다수의 VideoQA 데이터셋에서는 단일 프레임 이미지 모델이나 심지어 텍스트 기반 모델조차 경쟁력 있는 성능을 보인다. 이는 모델이 비디오 전체의 시간적 구조를 활용하기보다는, 대표적인 시각 단서나 질문-응답 패턴을 이용해 문제를 푸는 ‘shortcut’을 학습했음을 시사한다. 이러한 상황에서는 VideoLLM의 높은 성능이 곧 시간 이해 능력을 의미한다고 해석하기 어렵다.

이 문제를 명확히 드러내기 위해 제안된 것이 Test of Time이다. Test of Time은 매우 단순한 합성 환경에서 시간 순서 자체를 직접적으로 묻는 질문들로 구성되어 있다. 예를 들어, 두 개의 객체가 등장할 때 어떤 것이 먼저 나타났는지를 묻는 문제는 오직 시간적 정보 없이는 풀 수 없다. 이 벤치마크는 시간 정보가 필요 없는 control task와, 반드시 시간 순서를 추론해야 하는 time-order task를 명확히 분리함으로써 모델의 실제 시간 이해 능력을 평가한다. 실험 결과, 대부분의 최신 VideoLLM은 control task에서는 높은 정확도를 보이지만, time-order task에서는 무작위 추측 수준인 chance accuracy 근처에 머무른다. 이는 모델이 시간 정보를 거의 활용하지 못하고 있음을 명확히 보여준다.

이러한 결과는 단순히 모델이 부족하다는 결론으로 이어지지 않는다. 오히려 저자들은 그동안 사용되어 온 벤치마크 자체가 시간 이해 능력을 검증하지 못했다고 주장한다. 기존의 MVBench와 같은 벤치마크에서는 단일 이미지 모델이나 텍스트 전용 모델도 상당한 성능을 달성할 수 있으며, 이는 ‘시간 이해의 진보’로 해석되던 성능 향상이 사실상 비시간적 단서에 의존한 결과일 가능성을 강하게 시사한다. 즉, 그동안 관측된 발전은 temporal reasoning의 발전이 아니라 benchmark가 허용한 shortcut 활용 능력의 발전이었을 수 있다.
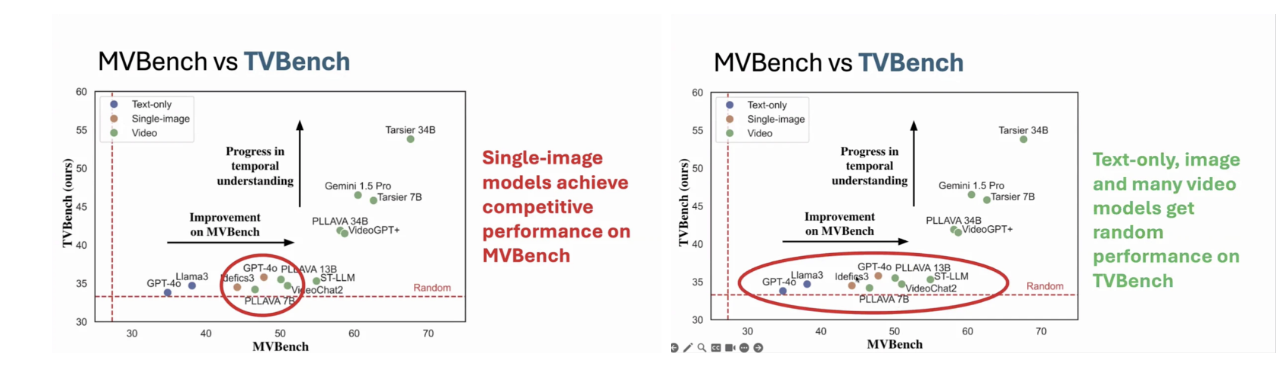
이 문제의식을 바탕으로 제안된 TVBench는 시간 정보를 명시적으로 요구하는 새로운 평가 기준을 제시한다. TVBench의 질문들은 시간적 맥락 없이는 정답을 고를 수 없도록 설계되어 있으며, 시각적으로 그럴듯한 오답들을 제거하기 위해 temporal information을 반드시 활용하도록 강제한다. 실험 결과, MVBench에서는 큰 차이가 없던 모델 간 성능이 TVBench에서는 극명하게 갈린다. 텍스트 전용 모델, 이미지 기반 모델, 그리고 다수의 VideoLLM이 랜덤 수준의 성능을 보이는 반면, 명시적으로 시간적 구조를 모델링하는 일부 비디오 모델만이 chance를 유의미하게 초과하는 성능을 달성한다.

이 연구가 주는 가장 중요한 메시지는 VideoLLM이 전반적으로 뛰어난 능력을 보여주고 있음에도 불구하고, 시간 이해 능력은 여전히 취약하다는 점이다. 더 나아가, 이는 모델 설계의 문제이기도 하지만 동시에 평가 방식의 문제이기도 하다. 시간이 필요 없는 질문으로는 시간 이해를 평가할 수 없으며, 벤치마크가 요구하지 않는 능력은 모델이 학습할 이유도 없다. 따라서 향후 VideoLLM 연구에서는 단순한 성능 향상이나 스케일 확장이 아니라, 시간적 추론을 구조적으로 요구하는 학습 신호와 평가 기준이 필수적이다. 결론적으로, 본 발표는 VideoLLM 연구 커뮤니티에 중요한 경고를 던진다. 지금까지의 벤치마크는 시간 이해 능력을 과대평가해 왔으며, 실제로 모델들은 여전히 ‘시간 속에서 길을 잃고 있다’. Test of Time과 TVBench는 단순한 새로운 데이터셋이 아니라, 비디오 이해 연구에서 무엇을 측정해야 하는지에 대한 기준을 재정의하려는 시도이다. 향후 연구는 비디오를 더 많이 보는 방향이 아니라, 시간이라는 개념을 어떻게 구조적으로 이해하고 추론할 것인가라는 질문으로 이동해야 할 것이다.
2. Generating and Understanding the 3D World | Roozbeh Mottaghi

강연에서 Roozbeh Mottaghi는 비디오 이해와 생성의 궁극적 목표를 “시각적 패턴 인식”이 아니라 물리적 세계에 대한 3차원적 추론(physical AI)으로 재정의한다. 핵심 문제의식은 명확하다. 기존의 2D 이미지, 비디오 중심 학습은 관측된 픽셀 간 상관관계는 잘 포착하지만, 공간 구조, 기하, 가림(occlusion), 이동, 상호작용과 같은 물리적 제약과 인과성을 내재화하지 못한다는 한계가 있다. 이로 인해 모델은 새로운 시점, 장거리 이동, 복잡한 동적 장면에서 일반화에 실패한다. 따라서 “보이지 않는 것을 상상하고, 움직임의 결과를 예측하는 능력”이 차세대 비전 모델의 본질적 요구사항으로 제시된다.
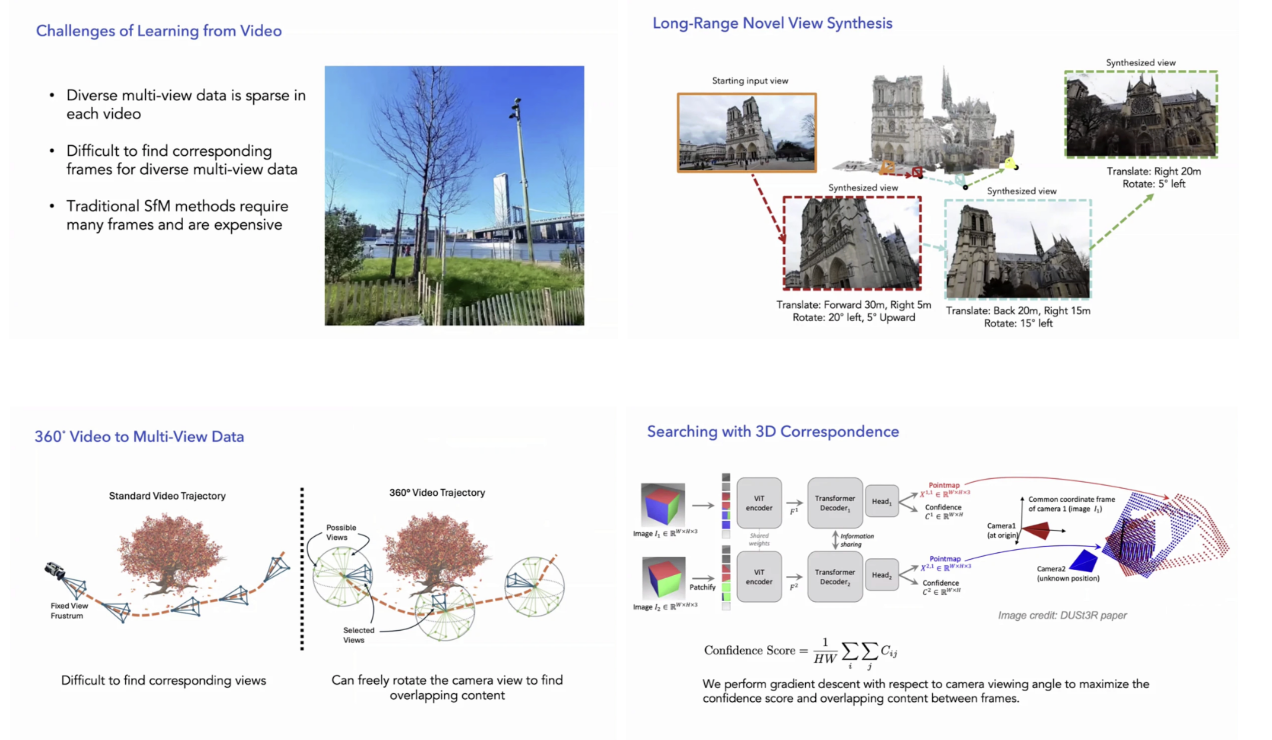
강연은 이러한 문제의식에서 출발해, 비디오 학습의 구조적 난제를 짚는다. 멀티뷰 데이터는 본질적으로 희소하며, 서로 다른 시점 간 정확한 프레임 대응을 찾는 것은 매우 어렵다. 기존의 SfM이나 다중 프레임 기반 접근은 많은 프레임과 계산 비용을 요구하고, 동적 장면에서는 쉽게 붕괴된다. 이 맥락에서 제시되는 핵심 아이디어는 “2D 시퀀스를 억지로 맞추는 대신, 3D에서 대응을 정의하자”는 전환이다. 카메라를 360도로 회전시키거나 가상의 시점을 생성해 겹치는 영역을 찾고, 프레임 간 정합을 3D 공간에서 최적화함으로써 장거리, 대규모 시점 변화 문제를 완화한다. 이는 비디오를 더 이상 시간축의 이미지 묶음이 아니라, 공간적으로 일관된 관측의 집합으로 재해석하는 관점 전환이다.

이러한 3D 중심 사고는 Novel View Synthesis와 Diffusion 기반 생성으로 확장된다. ODIN과 같은 조건부 확산 모델은 상대적 카메라 변환(회전, 이동)을 조건으로 새로운 시점을 생성함으로써, 단일 혹은 소수의 입력 이미지로부터 연속적인 시점 이동을 가능하게 한다. 중요한 점은 이것이 단순한 시각적 보간이 아니라, 장면 기하와 구조를 암묵적으로 학습한 결과라는 점이다. 특히 실내 장면 생성 사례는, 모델이 단순 텍스처 합성이 아니라 공간 레이아웃과 물체 배치를 유지하며 장면을 “이동 가능하게” 재구성할 수 있음을 보여준다. 이는 향후 로보틱스, 시뮬레이션, embodied AI로의 직접적 연결 가능성을 시사한다.
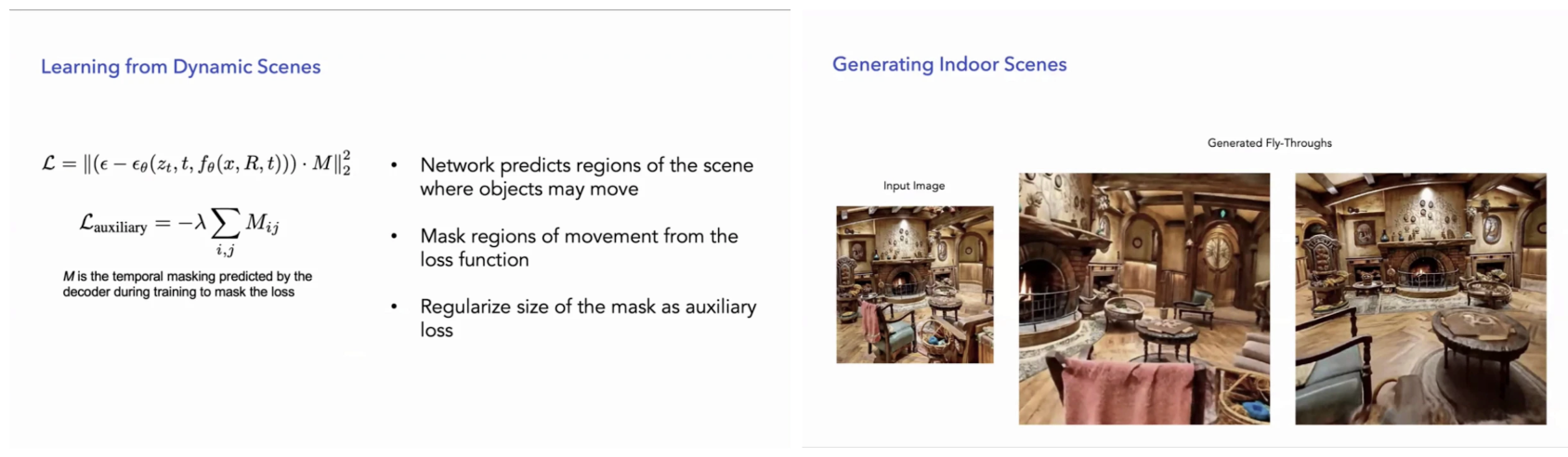
강연의 또 다른 중요한 축은 동적 장면 이해다. 실제 세계는 정적이지 않으며, 모든 픽셀이 동일한 물리 법칙을 따르지도 않는다. 이를 위해 제안되는 접근은 “움직일 수 있는 영역”을 네트워크가 스스로 예측하고, 그 영역을 학습 손실에서 분리하거나 약화시키는 방식이다. 이는 모델이 배경 기하와 객체 움직임을 구분하도록 유도하며, 결과적으로 시간적 일관성과 기하적 안정성을 동시에 확보한다. 이 관점은 비디오 이해를 “모든 것을 설명하려는 문제”에서 “설명 가능한 부분과 그렇지 않은 부분을 구분하는 문제”로 재정의한다는 점에서 중요하다.

후반부에서 제시되는 장면 메모리와 VLM 기반 업데이트 프레임워크는 단순한 시각 생성, 이해를 넘어, 지속적인 세계 모델링으로 확장된다. 에이전트는 관측을 통해 장면 내 엔티티를 추가, 수정, 삭제하며, 이 과정을 언어-시각 모델이 매개한다. 이는 장면을 정적인 3D 복원 결과가 아니라, 시간에 따라 갱신되는 구조화된 세계 상태로 다룬다는 점에서, SLAM, 로보틱스, 계획(planning) 문제와 직접적으로 연결된다. 실제 계획 성능 개선 결과는, 이러한 3D, 메모리 기반 표현이 단순 인식 성능을 넘어 의사결정 품질로 이어질 수 있음을 보여준다.
종합하면, 이 강연의 핵심 인사이트는 분명하다. 3D 이해와 생성은 더 이상 선택적 기능이 아니라, 물리적 AI로 나아가기 위한 핵심 토대라는 점이다. 2D 파운데이션 모델을 단순히 확장, 재활용하는 접근은 구조적 한계를 갖는다. 대신, 생성과 이해를 분리하지 않고, 공간, 시간, 물리를 함께 모델링하는 통합적 접근이 필요하다. 이는 비디오 이해, 장면 생성, 로보틱스, embodied agent 연구를 하나의 연속선상에 놓으며, 향후 비전 연구의 중심축이 “무엇을 보았는가”에서 “그 세계가 어떻게 작동하는가”로 이동하고 있음을 분명히 보여준다.
3. What Do Large Models Really Know About the World? | Shiry Ginosar

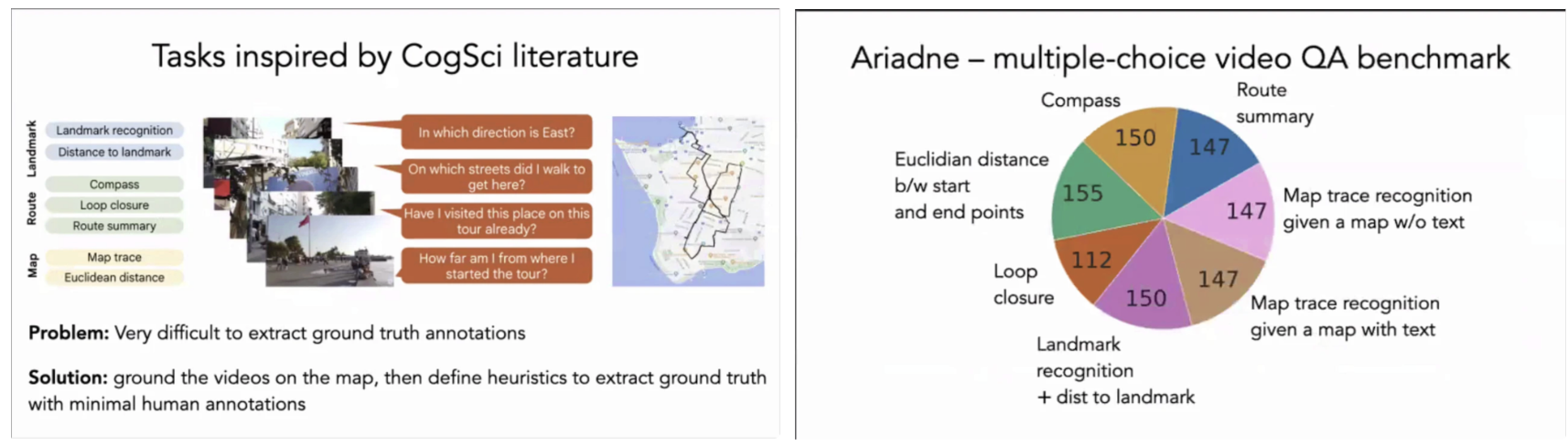
Ariadne’s Thread 벤치마크를 통해 Vision-Language Model(LMM)이 도시 규모 환경에서 이동을 수반하는 시각적 입력을 어떻게 처리하는지를 평가한다. 핵심 질문은 모델이 실제로 경로를 내부적으로 추적(stateful integration) 하는지, 아니면 단순히 프레임 단위의 시각과 언어 단서를 조합해 정답을 추론하는지를 구분하는 데 있다. 이를 위해 저자들은 비디오를 단순한 시각 시퀀스가 아니라, 누적된 공간 상태를 요구하는 입력으로 정의한다.

이러한 문제 설정은 인지과학에서 정의된 공간 지식 계층 구조를 평가 축으로 삼는다. 특히 landmark–route–survey 구분은 단순 난이도 차이가 아니라, 필요한 내부 표현의 종류가 질적으로 다르다는 점에서 중요하다. Landmark 수준은 장면 간 독립적 판별로 해결 가능하지만, route와 survey 수준은 모델이 시간 축을 따라 상태를 유지하거나 재구성해야만 해결할 수 있다.
Landmark knowledge에 해당하는 태스크에서는 모델이 비디오의 특정 프레임을 정적인 이미지 인식 문제처럼 처리하는 경향이 관찰된다. 랜드마크 인식 정확도는 비교적 높지만, 이는 이동 맥락을 이해했다기보다는 시각적 패턴 매칭과 명칭 연결에 의해 달성되는 경우가 많다. 즉, 이 단계에서는 temporal modeling의 필요성이 거의 드러나지 않는다. 랜드마크까지의 거리 추정 태스크에서는 모델이 실제 이동 거리를 누적하기보다는, 장면 내 시각적 단서(거리 표지판, 건물 크기 변화 등)에 기반해 휴리스틱 추정을 수행하는 경향이 나타난다. 이는 유클리디안 거리 추정이 경로 길이 적분이 아니라 장면 기반 상대 거리 추론으로 대체되고 있음을 시사한다.
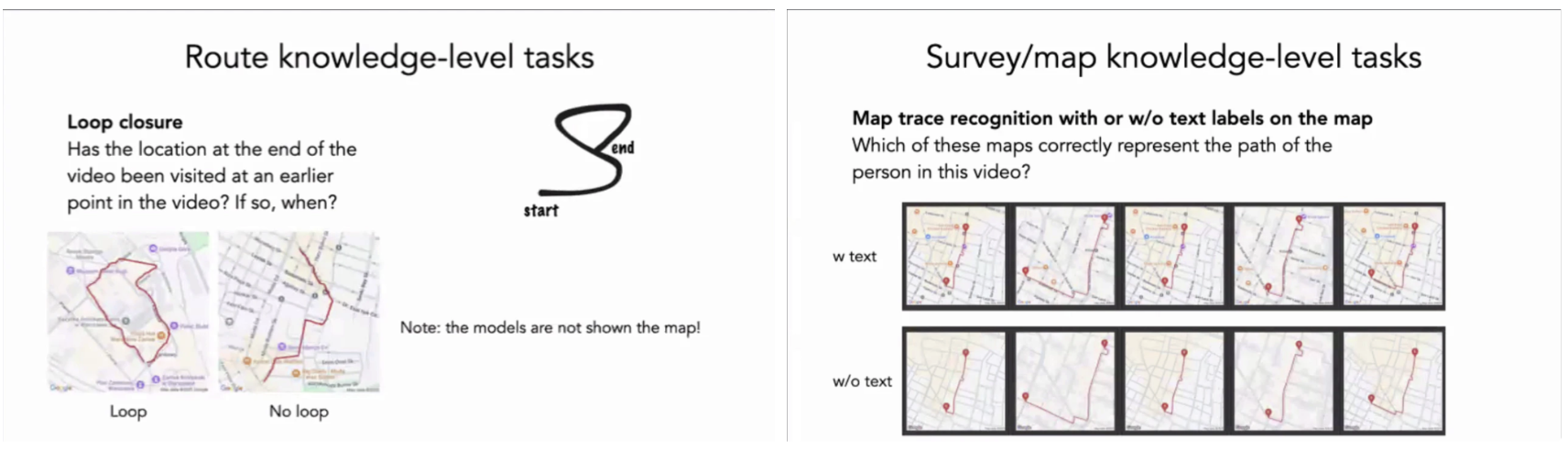
Route-level 태스크로 넘어가면서 이러한 휴리스틱은 한계를 드러낸다. Compass task에서 모델은 방향 변화가 잦은 경로일수록 성능이 급격히 저하되며, 이는 내부적으로 방향 벡터를 누적하지 않고 있음을 암시한다. 특히 중간에 회전이 반복되는 경우, 초기 방향 단서에 과도하게 의존하는 오류 양상이 반복적으로 관찰된다. Compass task의 실패는 모델이 orientation state를 latent variable로 유지하지 않는다는 점을 강하게 시사한다. 만약 내부적으로 방향 상태를 유지했다면, 중간 회전 수와 무관하게 최종 방향을 추론할 수 있어야 하지만, 실제 결과는 그렇지 않다.

Loop closure 태스크는 이러한 한계를 더욱 명확히 드러낸다. 모델은 동일 장소 재방문 여부를 판단할 때, 이동 경로의 구조적 일관성보다는 장면 유사도에 기반해 판단하는 경향을 보인다. 이로 인해 시각적으로 유사하지만 실제로는 다른 위치인 경우 false positive가 빈번히 발생한다. 이는 SLAM에서의 loop closure와 달리, LMM이 경로 그래프나 위상적 표현을 내부적으로 구성하지 않음을 의미한다. 즉, 모델은 돌아왔다는 개념을 경로 수준에서 정의하지 못하고, 장면 수준에서만 판단한다.

Survey-level 태스크에서는 이러한 문제가 누적되어 나타난다. Map trace recognition에서 모델은 지도 전체의 구조를 재구성하기보다는, 비디오 속 텍스트 단서와 지도상의 텍스트 레이블 간 대응 관계를 우선적으로 활용한다. 지도에 텍스트가 포함된 경우 성능이 유의미하게 향상되지만, 텍스트가 제거되면 성능이 급격히 하락하는 현상은 모델이 지도 기하 구조를 직접 활용하지 못함을 보여준다. 이는 지도 이미지가 공간적 제약 조건으로 작동하지 못하고 있음을 의미한다. Ariadne 벤치마크의 다지선다형 구성은 이러한 전략적 편향을 분석하는 데 중요한 역할을 한다. 동일한 정답을 서로 다른 추론 전략으로 도출할 수 있는 구조 덕분에, 모델이 어떤 단서에 의존하는지가 정성적으로 분석 가능해진다.
인간과의 비교 결과는 이러한 관찰을 더욱 분명히 한다. 인간은 텍스트 유무와 무관하게 경로 구조를 비교적 안정적으로 추론하는 반면, LMM은 입력 형식 변화에 극도로 민감하다. 특히 루트 요약과 지도 없는 경로 추론에서의 성능 격차는, 인간이 전역 경로 구조를 추상화하는 반면, LMM은 여전히 국소적 단서 결합에 머물러 있음을 보여준다. 저자들은 루프 클로저 문제에서 Gemini 2.5 Flash가 경로 적분을 수행한다는 증거를 찾지 못했다고 명시적으로 보고한다. 이는 모델 내부에 누적 위치 추정이나 이동 히스토리 표현이 존재하지 않을 가능성을 강하게 시사한다.

지도 활용 분석에서도 LMM은 지도를 시각적 보조 도구라기보다, 텍스트 확장된 컨텍스트로 취급하는 경향을 보인다. 이는 멀티모달 정렬 능력은 강하지만, 공간 추론 능력은 별개의 문제임을 보여주는 사례다. 후반부에서는 이러한 관찰을 비디오 예측 능력과 연결한다. 단기 예측 성능이 높은 모델일수록 국소적 공간 변화에 강하지만, 이는 전역 공간 구조 이해로는 자연스럽게 확장되지 않는다. 확산 기반 비디오 모델 역시 픽셀, 포인트 수준의 변화 예측에는 효과적이지만, 이동 경로 전체를 하나의 구조로 유지하는 데에는 한계를 보인다.
이는 LMM의 route/survey-level 실패와 구조적으로 유사하다. 결국 본 연구의 핵심 기술적 관찰은 명확하다. 현재 LMM은 시공간 입력을 상태 공간(state space)으로 모델링하지 않는다. 대신 장면 단서, 텍스트 상관관계, 국소적 유사성에 기반한 추론을 수행한다.

이는 향후 멀티모달 모델이 진정한 공간 추론을 수행하기 위해서는, 명시적인 상태 유지 메커니즘이나 경로 표현 학습이 필요함을 시사한다. 단순히 컨텍스트 길이를 늘리는 것만으로는 해결되지 않는 구조적 문제다.
4. Advances in Multimodal Video Understanding | Hilde Kuehne

멀티모달 비디오 이해는 더 이상 단순히 비디오와 텍스트를 함께 입력으로 사용하는 문제로 환원되지 않는다. 최근의 연구 흐름은 이 분야가 데이터 구성, 표현 방식, 모달 간 정렬(alignment), 그리고 추론의 근거까지 전반적으로 재설계해야 하는 단계에 도달했음을 분명히 보여준다. 특히 debiasing, localization, audio-visual reasoning으로 대표되는 세 축은 서로 독립된 기술 과제가 아니라, 현재의 비디오 이해 모델들이 공유하는 동일한 병목을 서로 다른 관점에서 드러낸다.
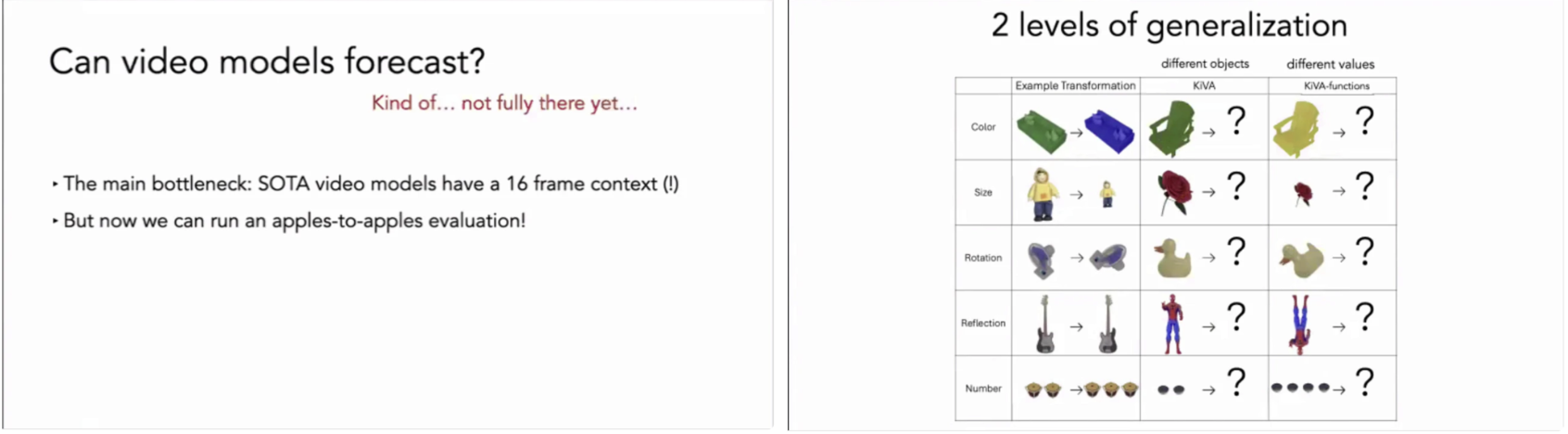
기존 모델들은 표면적인 성능 지표에서는 인상적인 결과를 보이지만, 실제로는 데이터에 내재된 쉬운 단서(easy cues)에 과도하게 의존해 판단을 내리는 경우가 많았고, 그 결과 모델이 무엇을 근거로 “이해했다”고 말할 수 있는지는 여전히 불투명했다. 이는 멀티모달 비디오 이해의 핵심 난점이 모델 규모나 데이터 양이 아니라, 모델의 판단 근거를 통제하고 설명할 수 없는 구조적 한계에 있음을 시사한다.
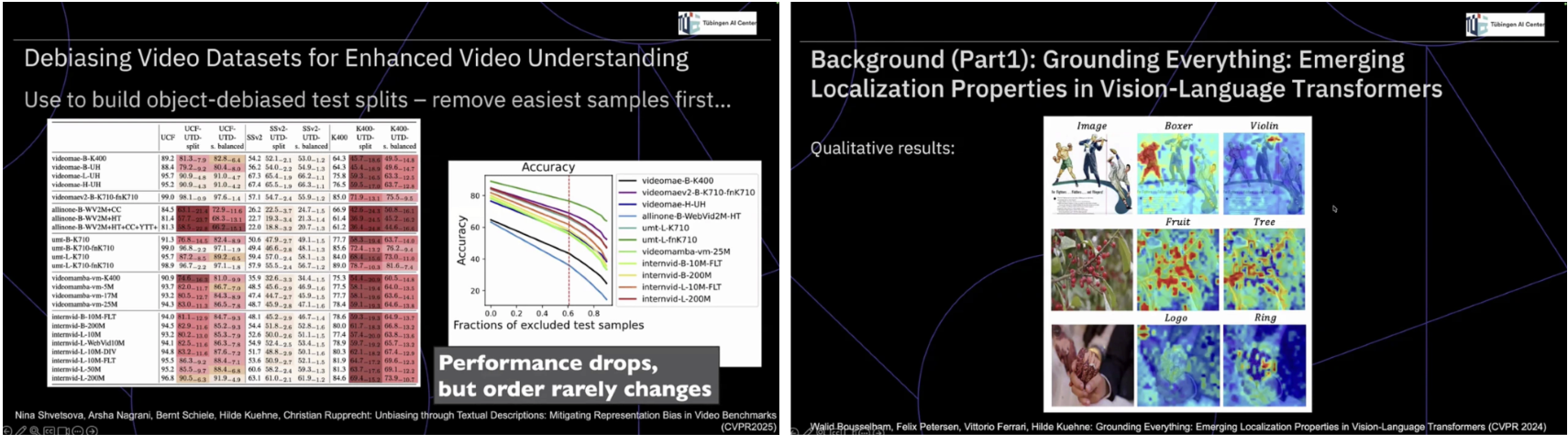
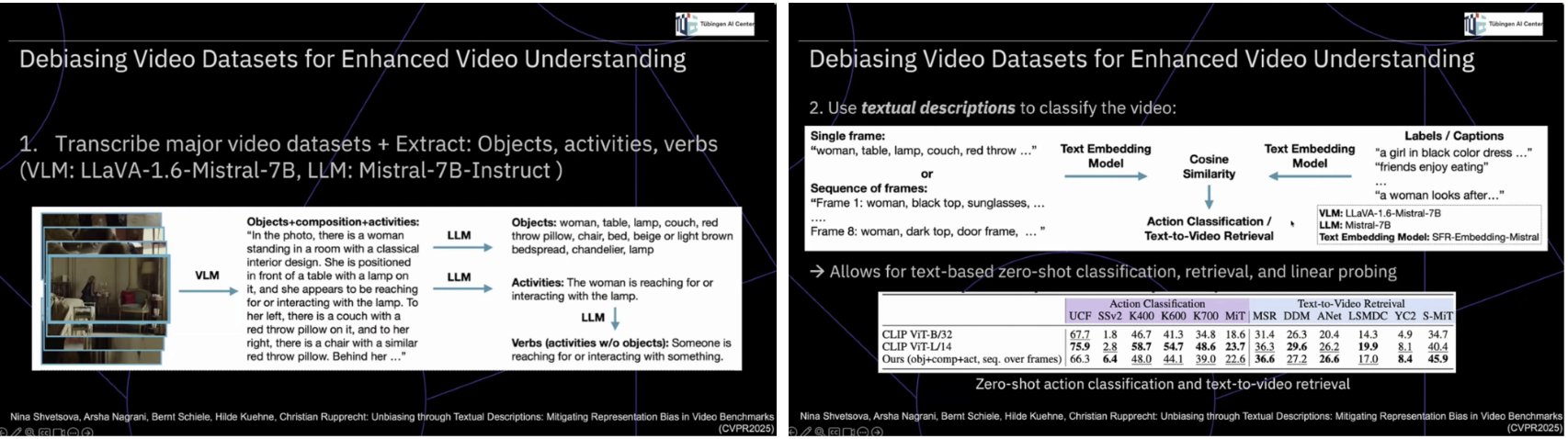
이 문제의식은 비디오 데이터셋 디바이싱 연구에서 더욱 명확하게 드러난다. 객체, 행동, 동사를 텍스트로 명시적으로 추출하고, 가장 쉬운 샘플부터 점진적으로 제거해 나가면 모델의 절대 성능은 일관되게 하락한다. 그러나 흥미롭게도 모델 간 상대적 순위는 거의 변하지 않는다. 이는 현재의 벤치마크가 실제 이해 능력의 차이를 가려내기보다는, 동일한 지름길을 얼마나 효율적으로 활용했는지를 측정하고 있었음을 암시한다. 이러한 관찰은 디바이싱이 단순한 공정성 문제를 넘어서, 평가 자체의 의미론적 타당성을 회복하는 도구임을 보여준다. 성능 저하는 실패가 아니라, 모델이 그동안 무엇에 의존해 왔는지를 드러내는 신호이며, 텍스트 기반 분해는 비디오 이해를 다시 설명 가능한 문제 공간으로 되돌리는 역할을 한다.
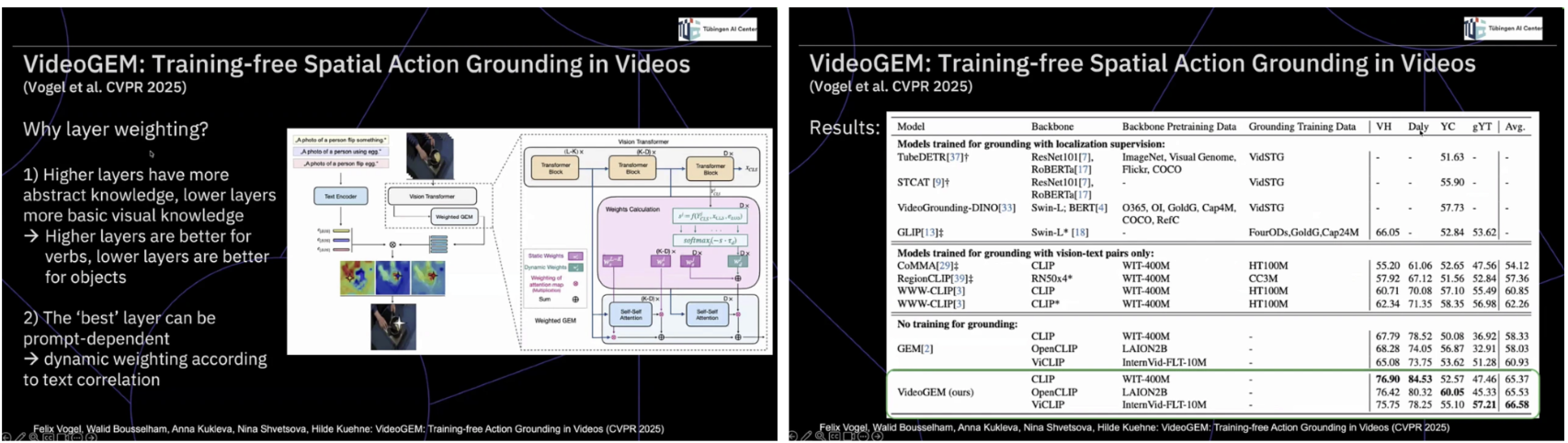
이러한 흐름은 공간적 액션 그라운딩 연구로 자연스럽게 이어진다. VideoGEM은 별도의 추가 학습 없이도 레이어 가중치 조정과 프롬프트 분해만으로 공간적 액션 그라운딩이 가능함을 보이며, “행동을 어디에서 보고 있는가”라는 질문을 정면으로 다룬다.
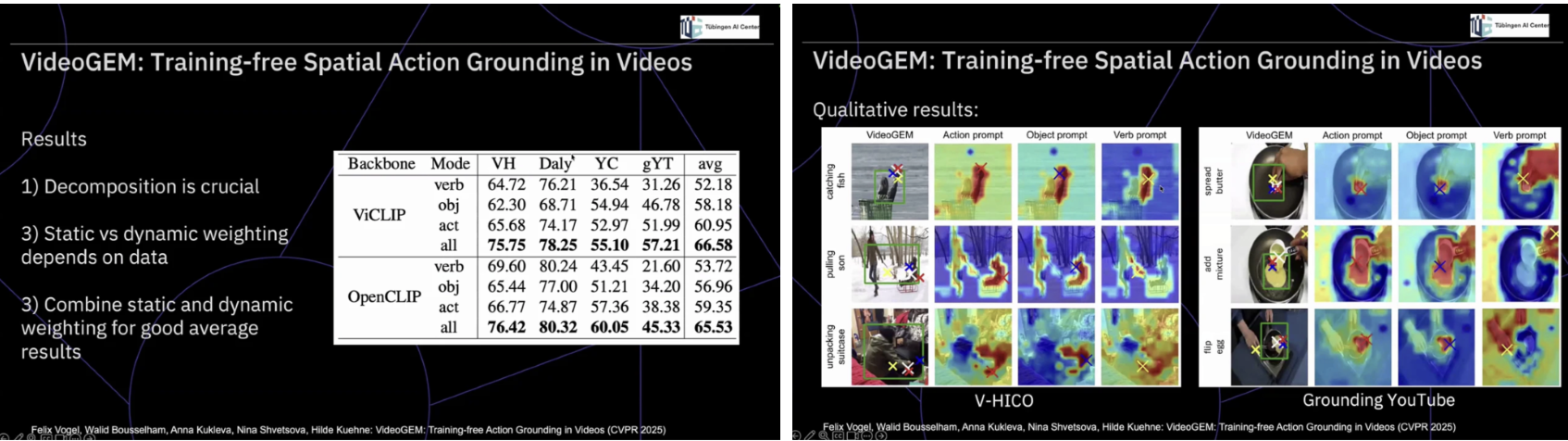
여기서 핵심적인 통찰은 행동이 단일한 표현이 아니라 객체, 동사, 그리고 이들 간의 상호작용으로 구성된 복합 개념이라는 점이다. 이 분해가 실패하면 localization 역시 필연적으로 붕괴된다. 더 나아가 상위 레이어는 추상적 개념에, 하위 레이어는 시각적 디테일에 더 적합하다는 분석은, 트랜스포머 내부가 단순한 블랙박스가 아니라 기능적으로 분화된 추론 공간임을 보여준다. 이는 멀티모달 비디오 이해에서 중요한 것이 더 많은 학습이나 파라미터가 아니라, 모델 내부 표현을 어떻게 읽고 조합할 것인가에 대한 설계 철학임을 분명히 한다.
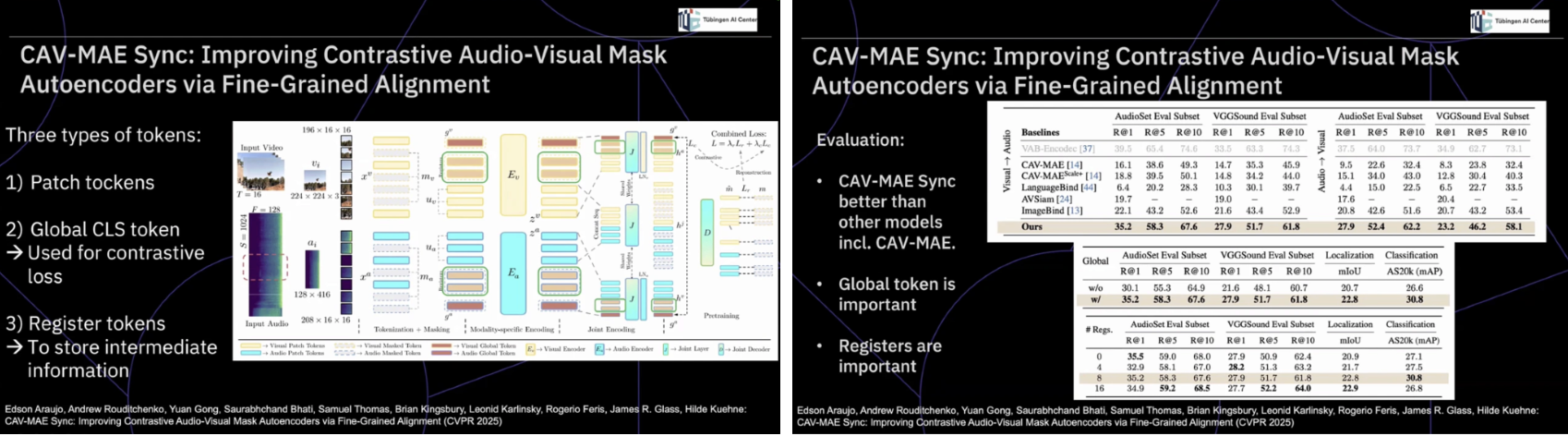
이러한 설계 관점은 오디오-비주얼 정렬을 다루는 CAV-MAE Sync 연구에서 한 단계 더 확장된다. 이 접근은 단순한 contrastive learning을 넘어, 토큰 단위의 미세 정렬(fine-grained alignment)이 성능을 결정짓는 핵심 요소임을 보여준다. 특히 global CLS 토큰과 register 토큰의 역할 분석은, 멀티모달 모델이 장면 전체를 요약하면서도 국소적 정보를 유지하기 위해 어떤 구조적 장치를 필요로 하는지를 구체적으로 드러낸다. 여기서 중요한 인사이트는 오디오가 비디오 이해의 보조 신호가 아니라, 시간적, 공간적 해석을 강제하는 구조적 제약으로 작동한다는 점이다. 즉, 소리는 단순히 “무엇이 중요한지”를 암시하는 힌트가 아니라, 모델이 장면을 해석하는 방식 자체를 재구성하는 요소로 기능한다. 결국 이 일련의 연구들은 멀티모달 비디오 이해가 더 큰 모델이나 더 많은 데이터로 해결될 문제가 아니라, 어떤 근거로 이해를 수행하고 있는지를 드러내고 통제하는 문제로 수렴하고 있음을 보여준다. 성능 향상 이전에 이해의 구조를 정제하려는 이러한 시도들은, 비디오 이해 연구가 양적 확장에서 질적 해석으로 전환되고 있음을 명확히 시사한다.
